Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMローカル動作方法(NvidiaGPU使用)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
dassimen
March 23, 2025
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMローカル動作方法(NvidiaGPU使用)
前回はCPUのみで動作させていたLLMをNvidiaのGPUを使用して動かしてみました。
PCのファンがうるさくなることなくLLMが動いていて感動しました。
dassimen
March 23, 2025
More Decks by dassimen
See All by dassimen
LLMとは(超概要)
dassimen001
0
130
RAGとは(超概要)
dassimen001
0
100
LangChain × Ollamaで学ぶLLM & RAG超入門
dassimen001
1
370
まるでChatGTP!?
dassimen001
0
64
🎭Playwright 超入門
dassimen001
0
74
LLMローカル動作方法
dassimen001
1
96
ベクトル変換について
dassimen001
1
64
Featured
See All Featured
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
The Curious Case for Waylosing
cassininazir
1
420
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Fireside Chat
paigeccino
42
4k
Mobile First: as difficult as doing things right
swwweet
225
10k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
Documentation Writing (for coders)
carmenintech
77
5.4k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Transcript
LLMローカル動作方法 超入門 (NvidiaGPU使用) 1
使用ツール WSL2 : Windows上でLinuxを手軽に動かす環境 Docker : コンテナ実行環境 Ollama : LLMをローカルで動かすツール(https://ollama.com)
NVIDIA Container Toolkit(Dockerで使用する) 2
Ollamaとは 大規模言語モデル(LLM)をローカル環境で簡単に実行・管理する ためのオープンソースツール コマンドの感覚的にはDockerに近いイメージを持った。 元OpenAIの人が作ったそう。世界中の協力の元プロジェクトが 大きくなっている。 動かせるLLMは、リポジトリのようなホストサイトがありそこから ダウンロードする Llamaやdeepseek-R1などが使える 3
動作検証方法 1. ローカルPCで動かす 2. ローカルだけで動いてるのか確認するためにネットワークを切断す る 前提 WSL2でUbuntuディストリビューションインストール済み Dockerを動かせる環境を構築済み 今回はGPUで動作確認する(CPUのみでの動作も可能)
4
Nvida Container Toolkitの設定1 1. Ubuntu(WSL2)環境にNvidaContainerToolKitをインストール 1. NvidiaのリポジトリをUbuntuに追加 aptでインストールできるようにする 2. 以下コマンドでツールのインストール
$ sudo apt-get install -y nvidia-container-toolkit インストール詳細は以下を参照(NVIDIA公式Doc) https://docs.nvidia.com/datacenter/cloud-native/container- toolkit/latest/install-guide.html#installation “ “ 5
Nvida Container Toolkitの設定2 2. Dockerの設定をする 1. Nvidiaのツールキットを使用するように設定ファイルを更新 $ sudo nvidia-ctk
runtime configure --runtime=docker 2. Dockerの再起動 Docker Desktop for Windowsの場合はGUIから再起動する GPUをDockerで使用する詳細は以下を参照(Docker公式Doc) https://docs.docker.com/desktop/features/gpu/ “ “ 6
実行 1. まずOllamaコンテナを立ち上げる(モデルを実行するツール) $ docker run -d --gpus=all -v ollama:/root/.ollama
-p 11434:11434 --name ollama ollama/ollama 2. 好きなモデルを以下から選び実行する 今回は Llama3.2の1bパラメータ の物を選んだ。 比較的容量が1.1GBと少なめ。 DeepSeek-R1も使ったが今回は省略する。 $ docker exec -it ollama ollama run llama3.2:1b 7
実行結果 >>> 日本語で対応してください。 我々は、以下のような方法でオプションをご提供しています。 1.質問を簡単な言葉で説明する 2.長い文書の部分についての詳細な説明 3.特定の問題に答えを調べるためのシナリオを提示します。 4.関連する情報と関連している情報をご紹介します。 5.複雑な概念を簡単に理解できるように、分解したリストを提供します。 >>>
日本の首都はどこですか。 日本の首都は東京です。 Tokyo (, Tokyō) は、日本の人口の約半分の市民が住んでいる都市で、東京 metropolitan area の中心部である。 >>> が自分で入力した文章。その下がLLMの回答。 サイズが小さなモデルなので日本語での精度は少し落ちる。 精度を上げる場合は、容量の大きなモデルを使用するとよい。 ネットワークを切った状態でも問題なく動作した。 8
わかったことと今後 ローカルで手軽にLLMが動作させられることが分かった。 Docker環境でGPU連携は、簡単。 LangChainを試している最中なのでそれと連携したい。 AIを使う敷居がかなり下がっているのを感じた。 Ollamaリポジトリを見ると画面も簡単につけられそうなので試した い。 9
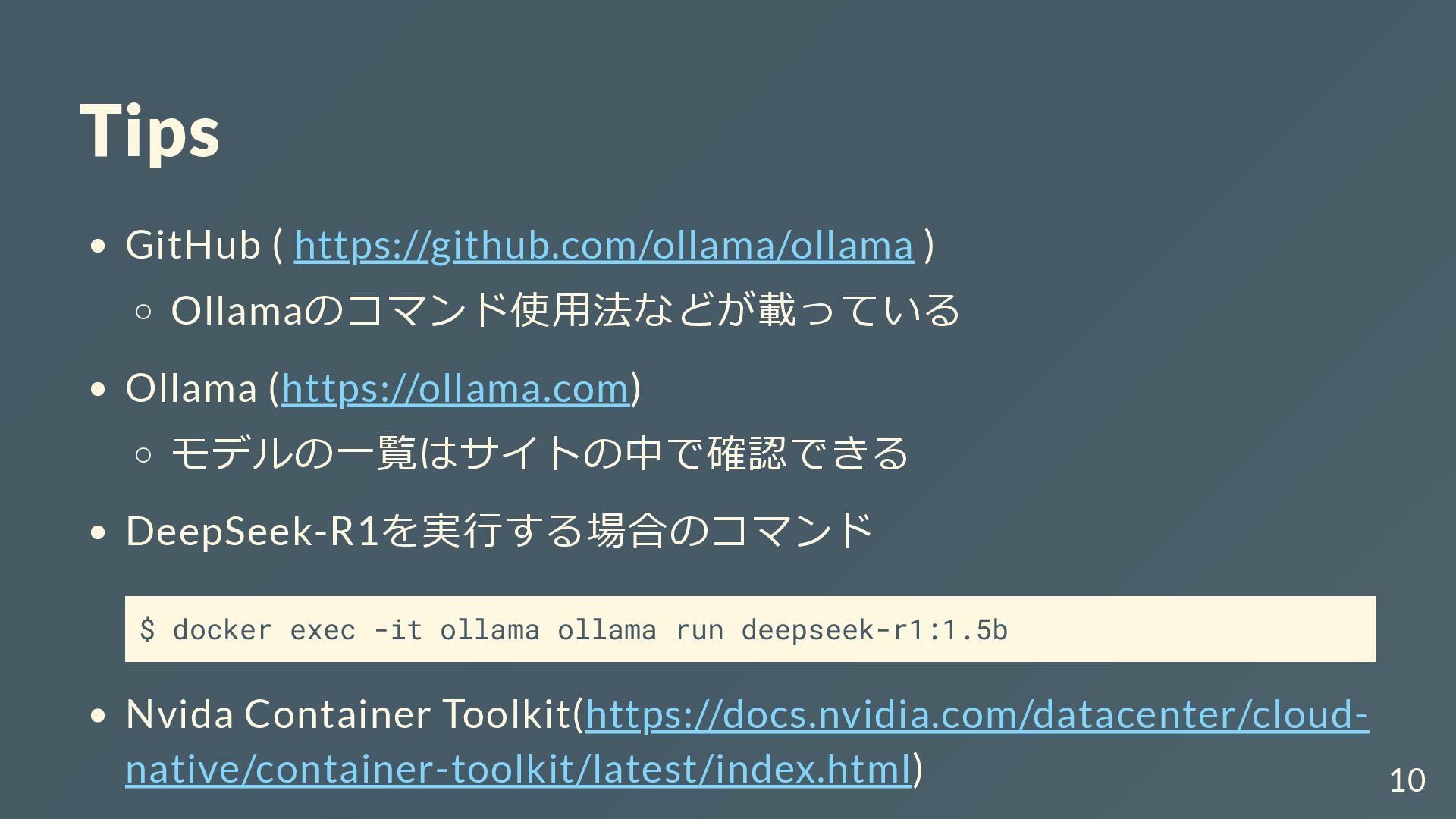
Tips GitHub ( https://github.com/ollama/ollama ) Ollamaのコマンド使用法などが載っている Ollama (https://ollama.com) モデルの一覧はサイトの中で確認できる DeepSeek-R1を実行する場合のコマンド
$ docker exec -it ollama ollama run deepseek-r1:1.5b Nvida Container Toolkit(https://docs.nvidia.com/datacenter/cloud- native/container-toolkit/latest/index.html) 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}