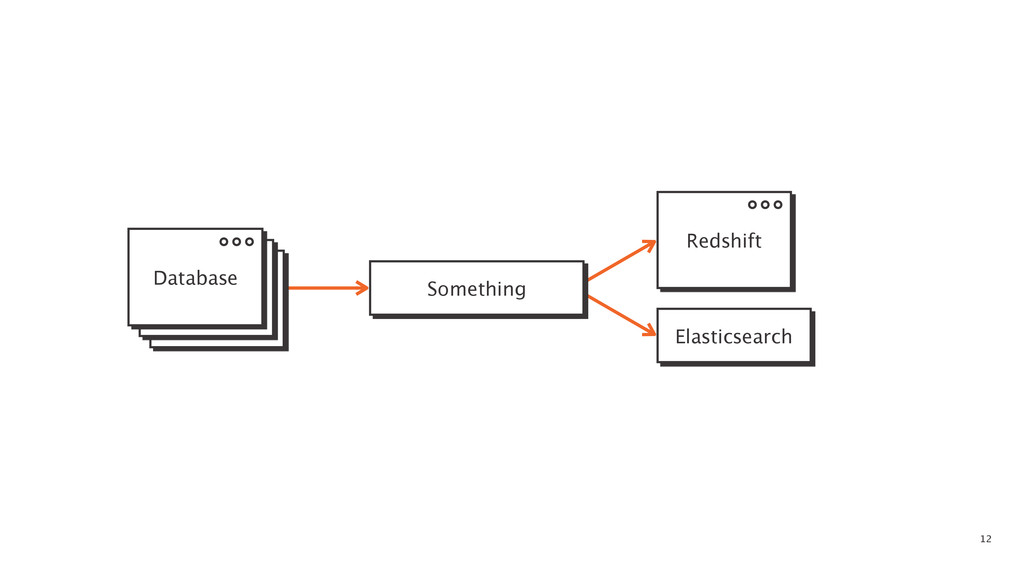
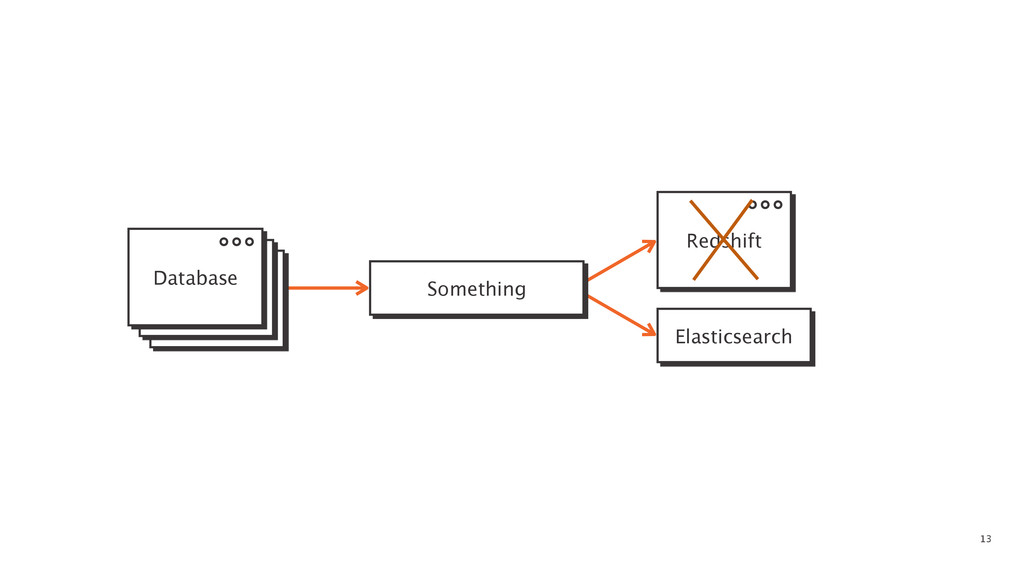
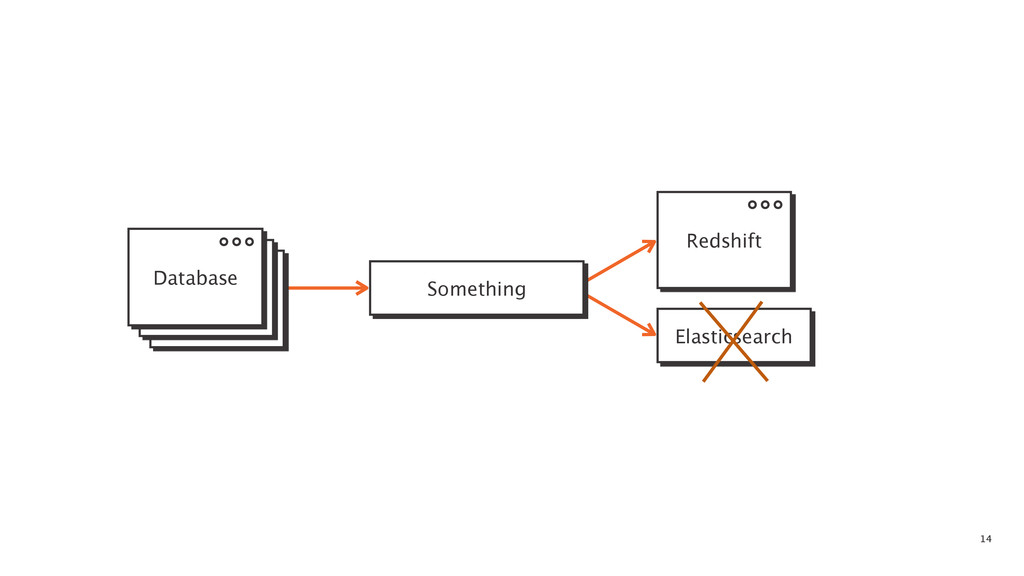
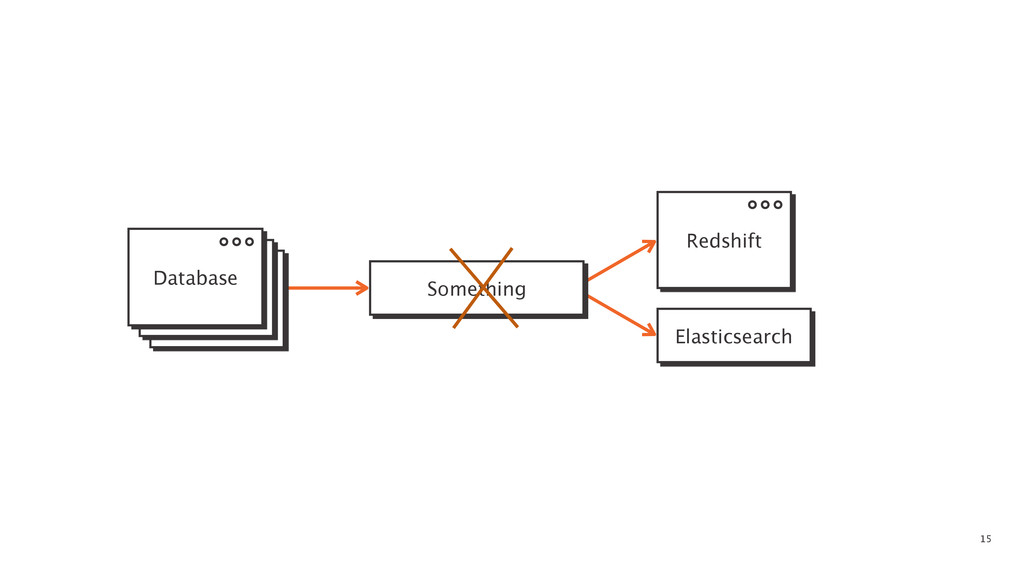
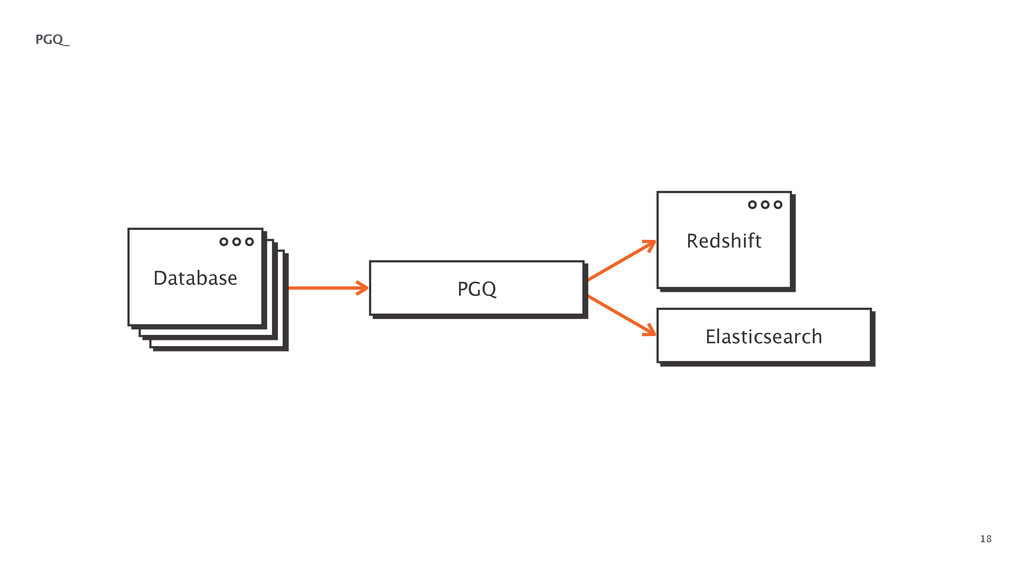
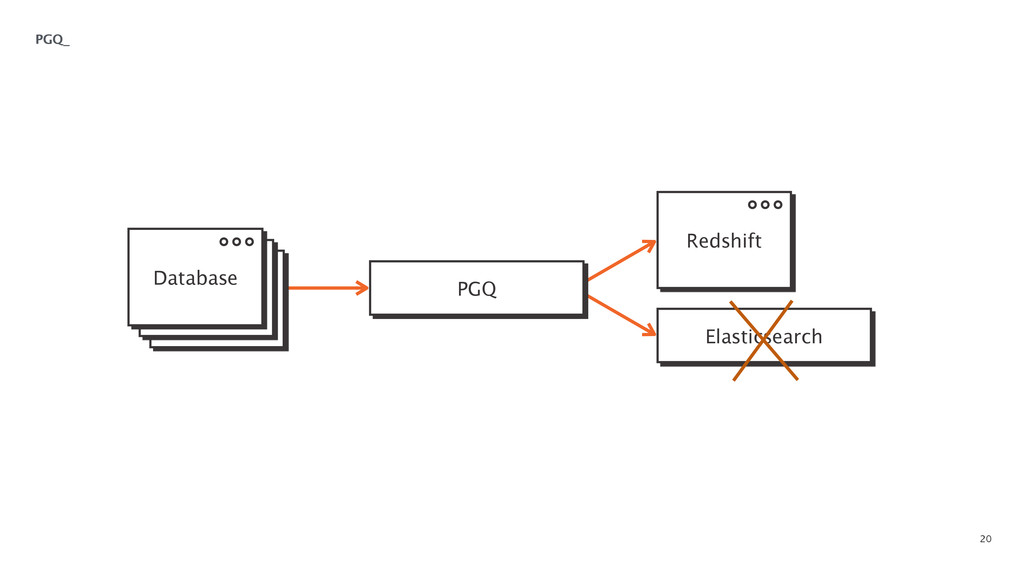
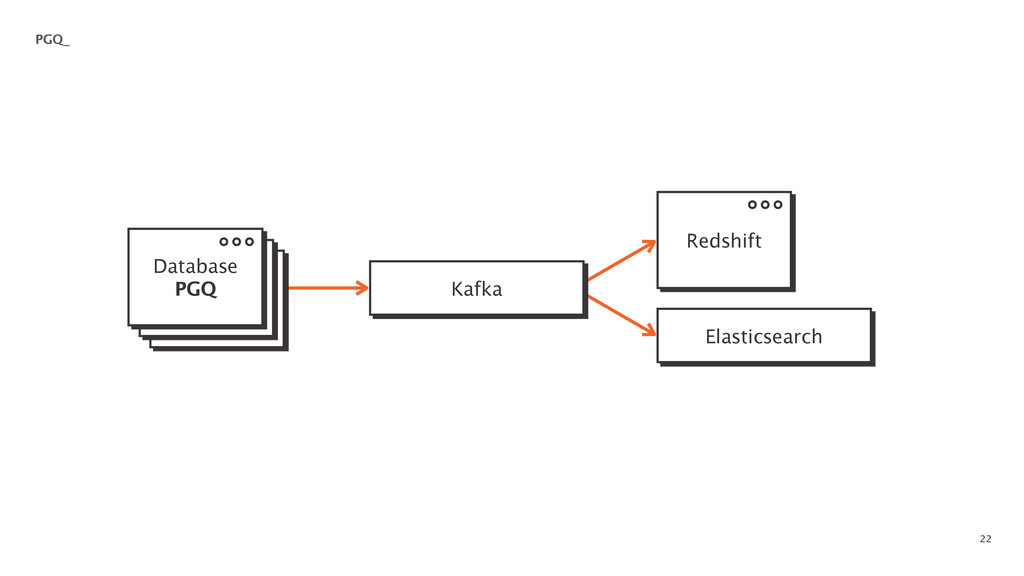
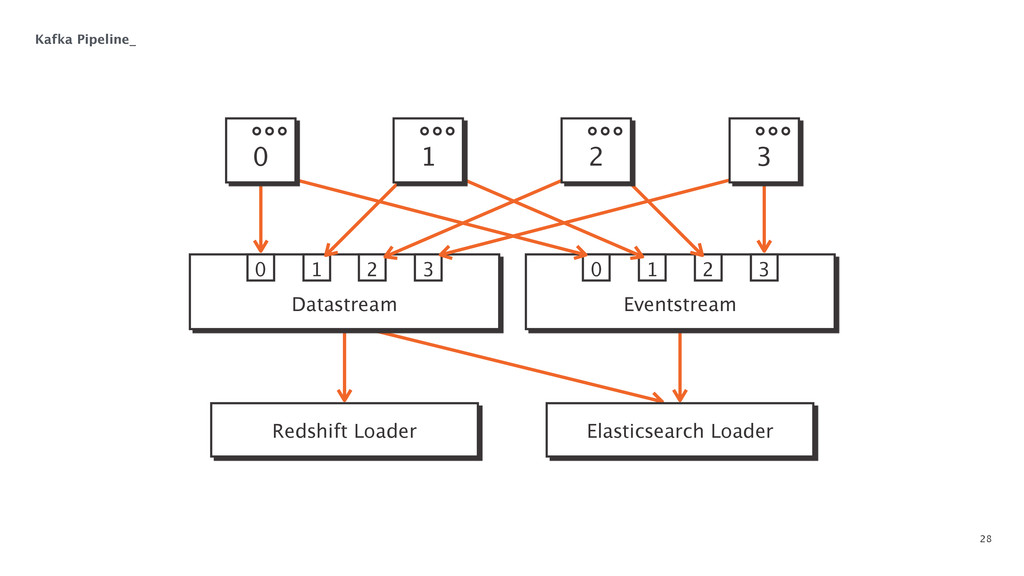
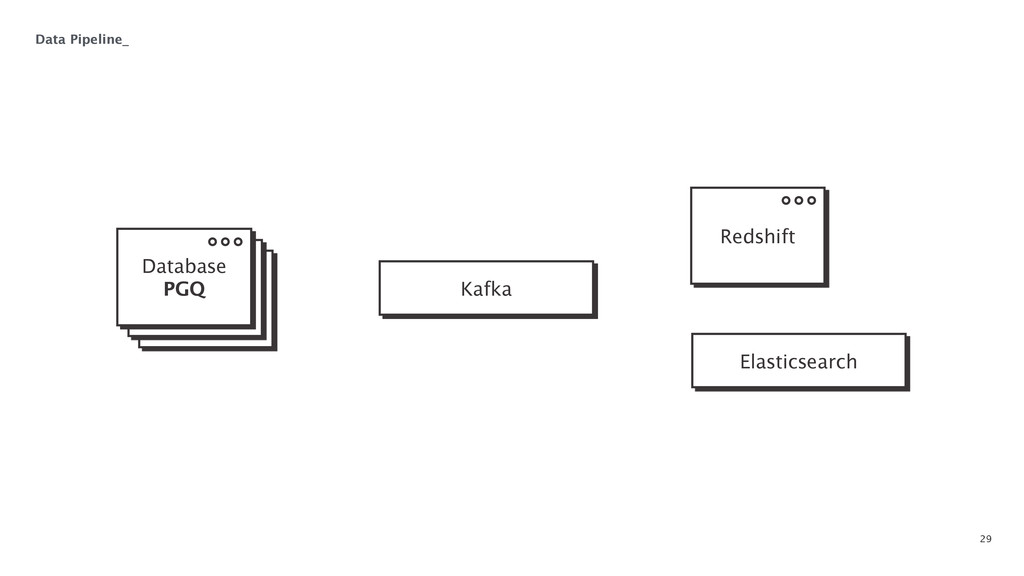
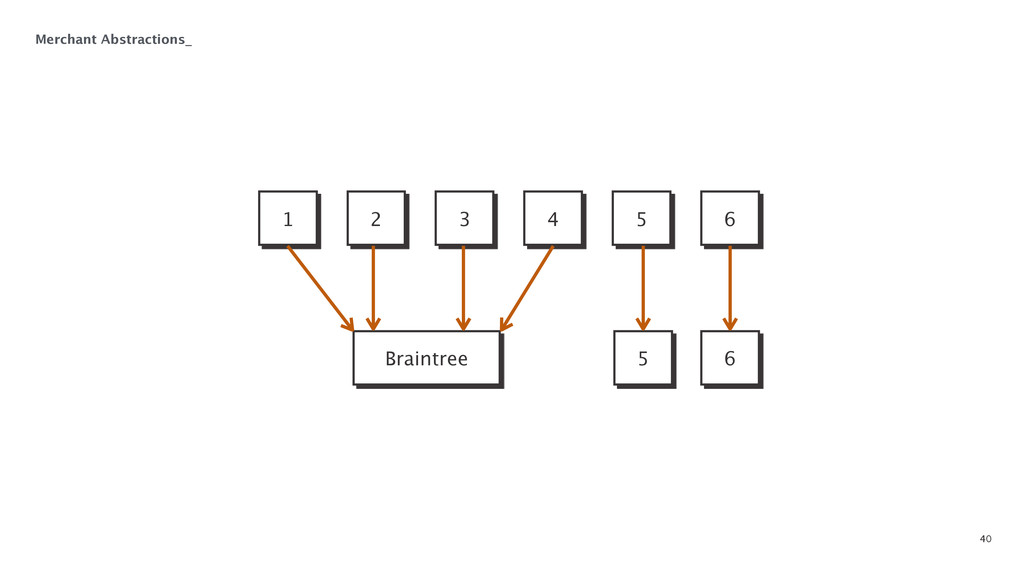
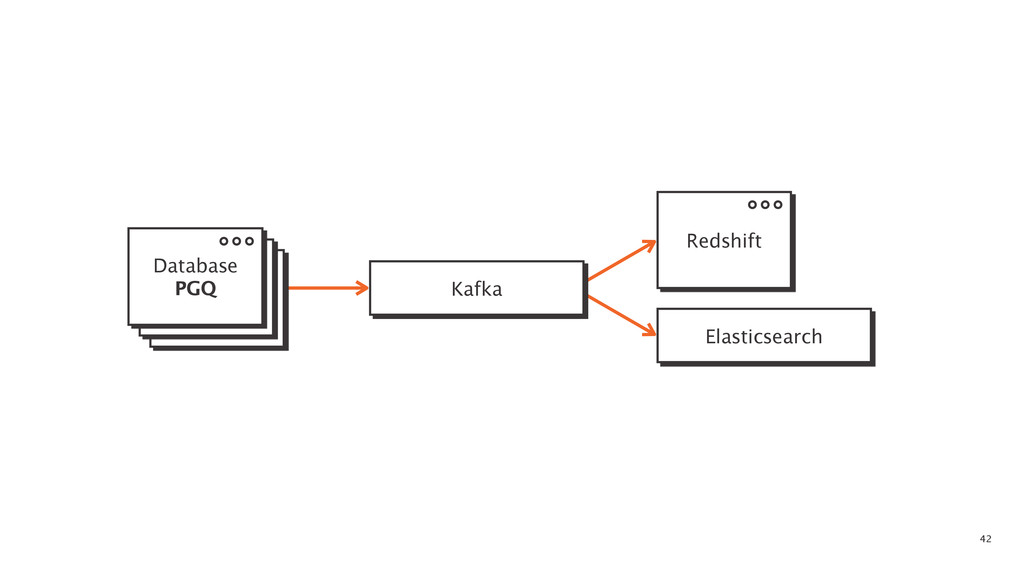
At some point in every large software application's lifetime, it must turn to service-oriented architecture to deal with complexity. This often involves separating data between applications and creating a way for those applications to talk to each other. Inevitably, pieces of the system end up needing to know more about the shape of the data in the main application (e.g. a data warehouse and search) than a separate piece of architecture should. In order to combat this issue, Braintree developed a data pipeline built on PGQ, Kafka, Zookeeper, and Clojure. In this talk, David Pick will give an in-depth review of how the data pipeline functions and talk through some of the issues encountered along the way.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
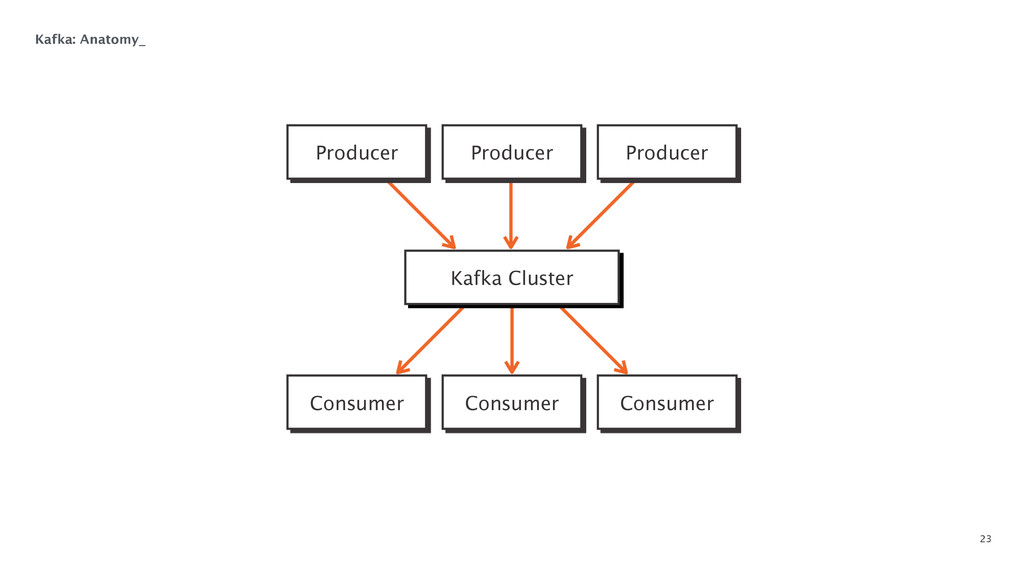{kind=link}
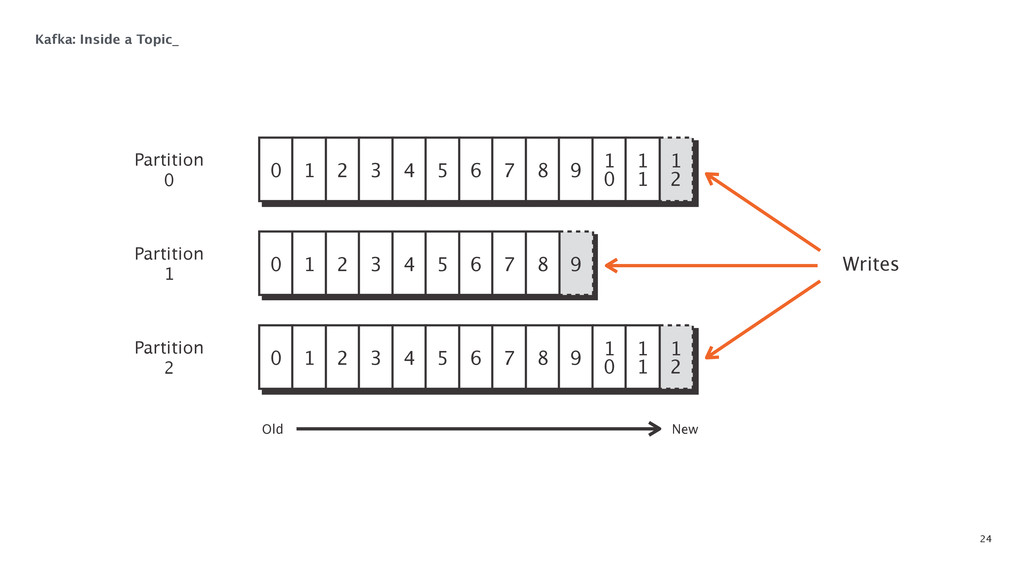{kind=link}
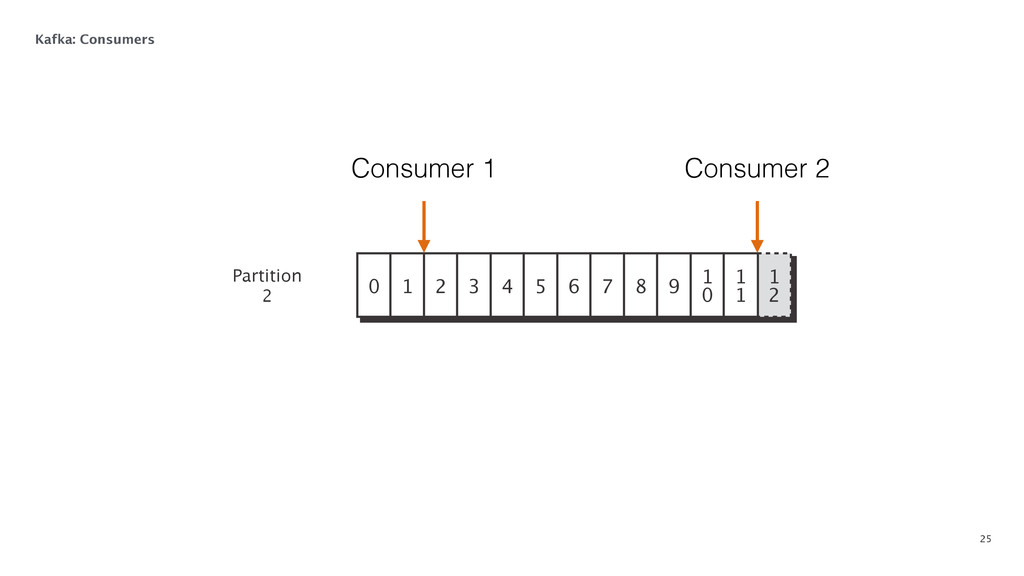{kind=link}
{kind=link}
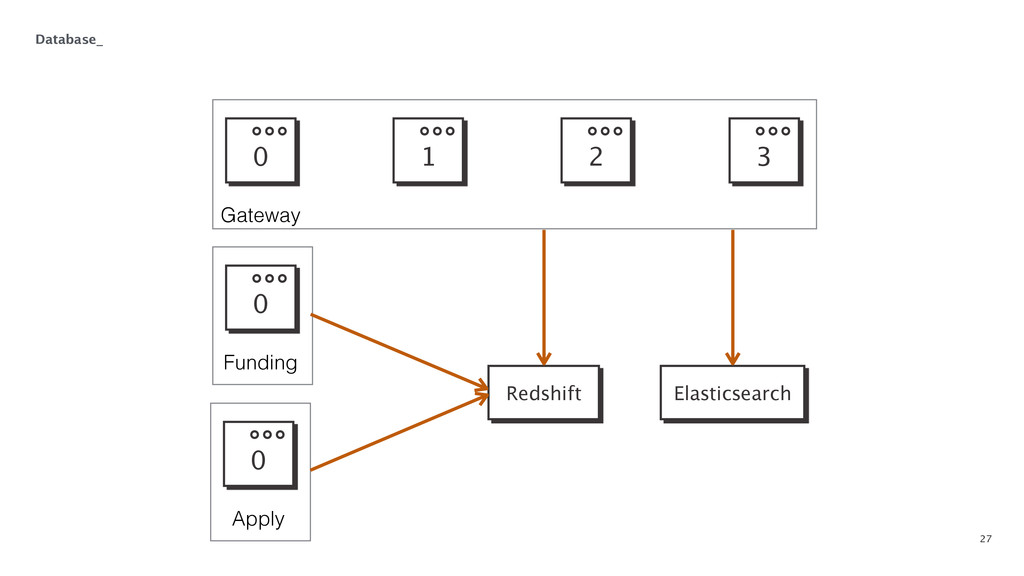{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![33 Laziness_ (with-resource [c (consumer config)] shutdown (doseq [message (messages](https://files.speakerdeck.com/presentations/92d5b5b040f9013242c936dddb3f194a/slide_32.jpg){kind=link}
![34 Laziness_ (let [c (consumer config)] (try (doseq [message (messages](https://files.speakerdeck.com/presentations/92d5b5b040f9013242c936dddb3f194a/slide_33.jpg){kind=link}
![35 Laziness_ (defn process-messages [messages] (doseq [message messages] (process-message message)))](https://files.speakerdeck.com/presentations/92d5b5b040f9013242c936dddb3f194a/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}