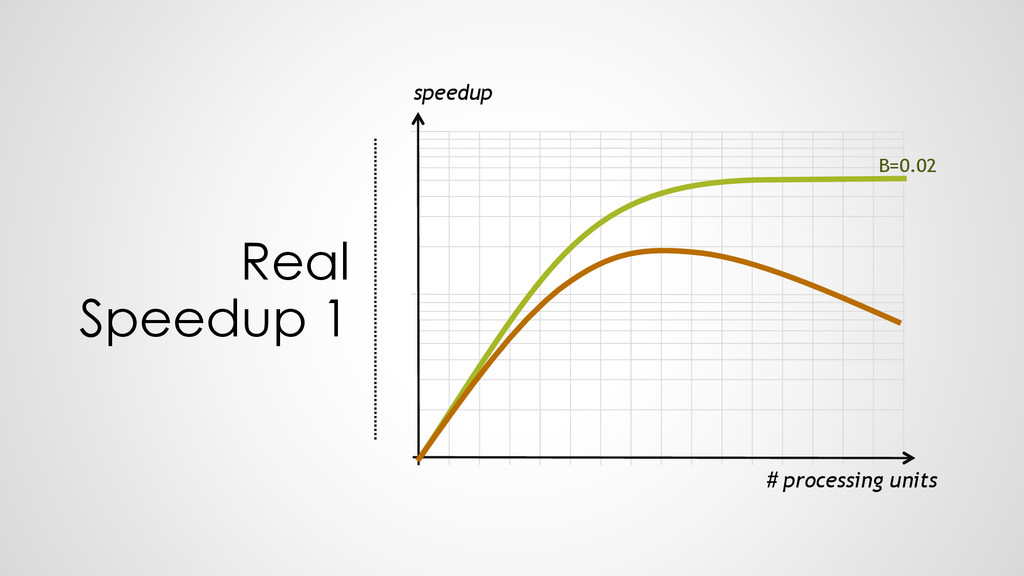
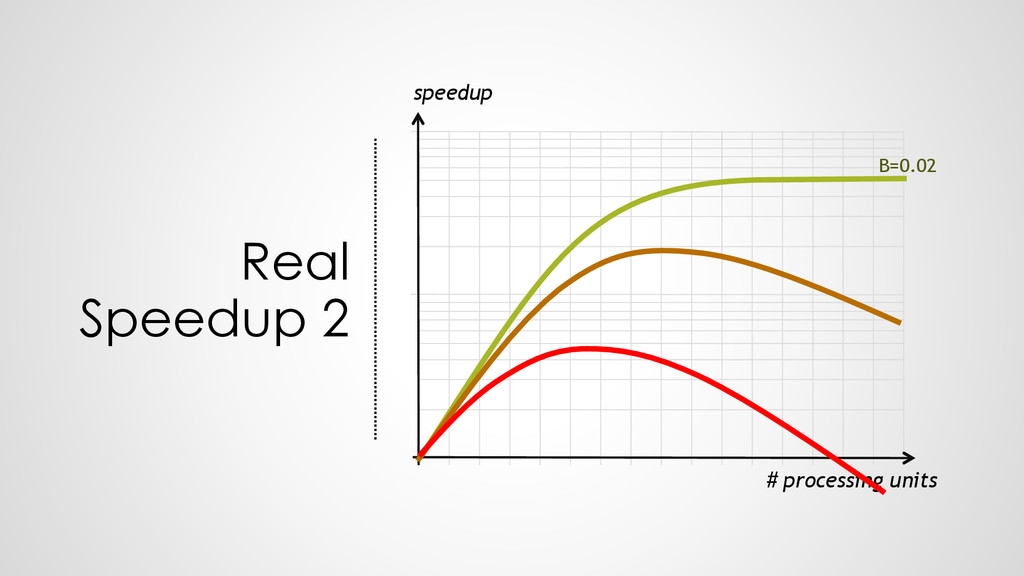
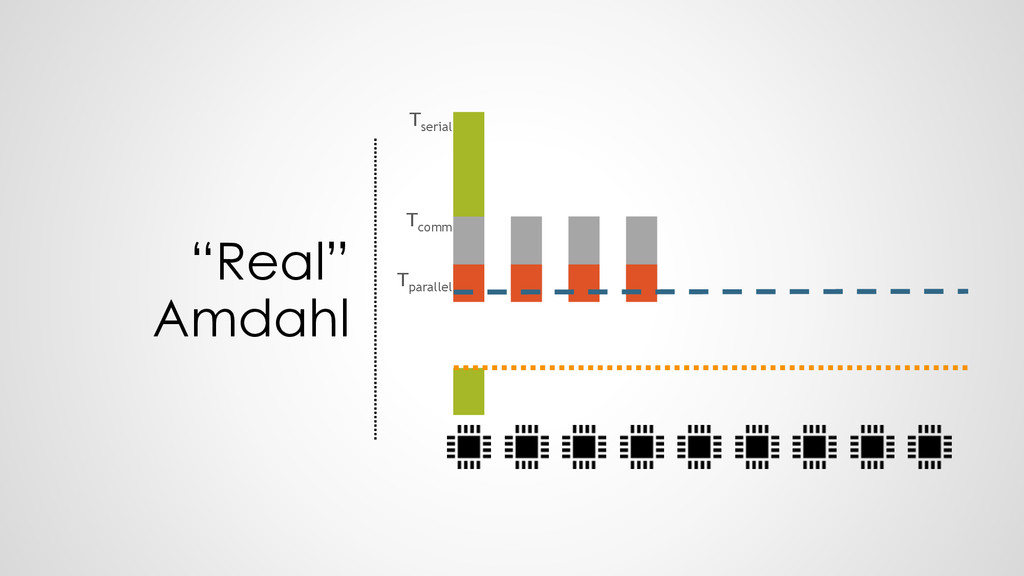
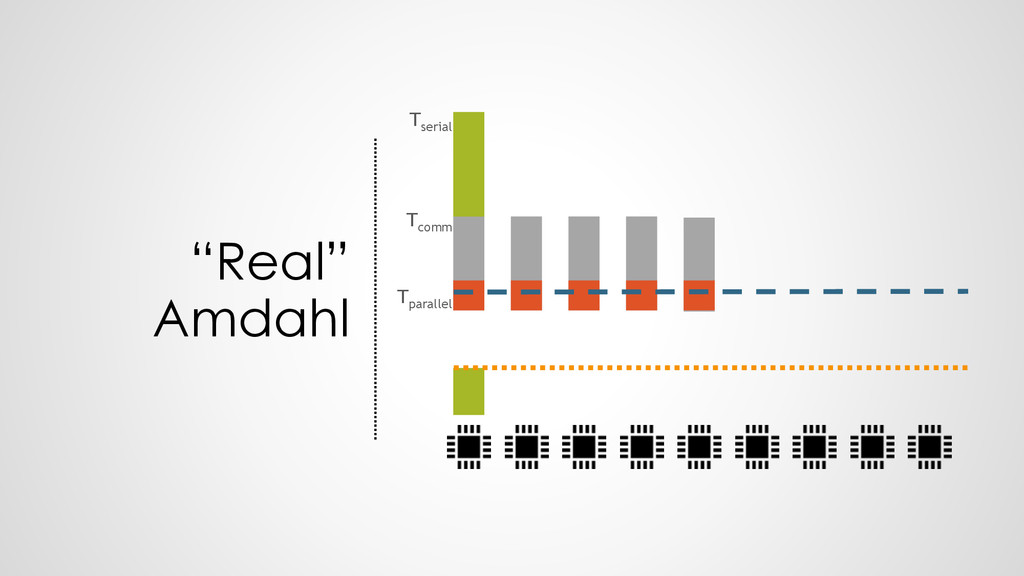
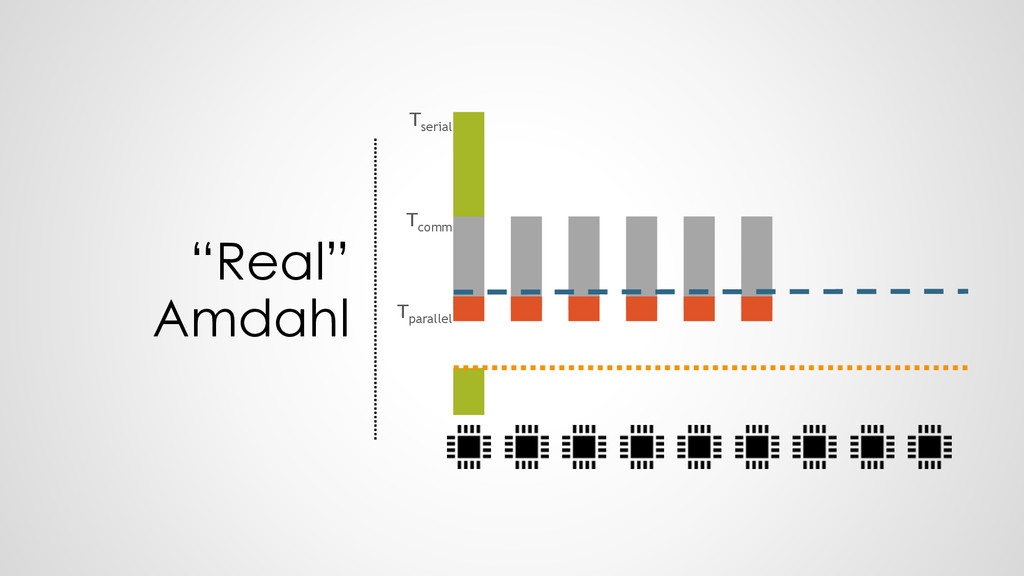
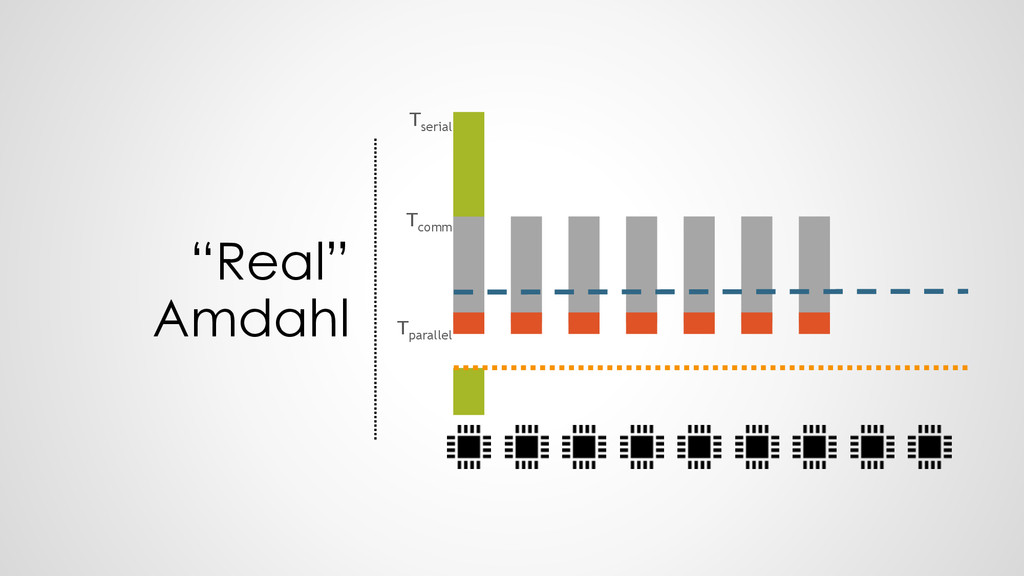
100 Hz executes 100 operations per second • 1 processor at 200 Hz executes 200 operations per second • HENCE: 2 processors at 100 Hz execute 200 operations per second ➢Everything is fine?
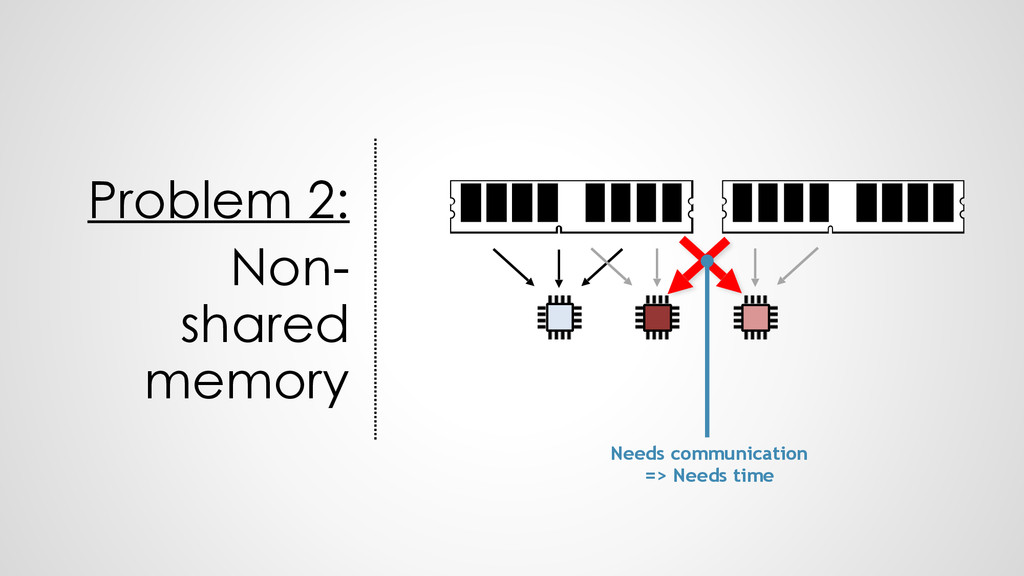
All dependencies known • Break down easiest : each core only one task • Communication & memory allocation not controllable • Need load to compute ratio
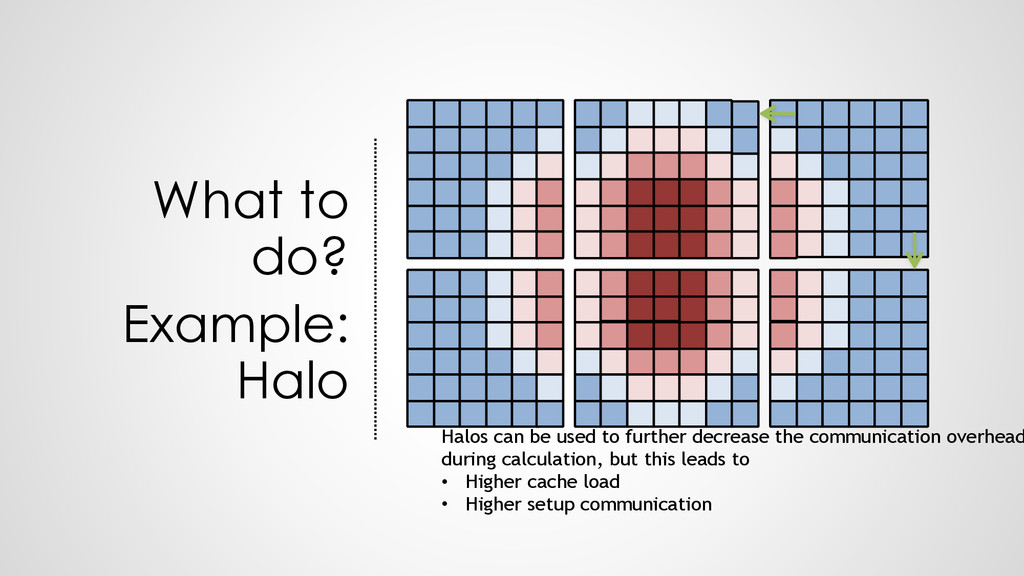
know how to interpret the communication • Workload vs. communication load is unknown • Same segmentation and intelligence missing as in C • A “legal” segmentation would have every function on an individual core ! ➢can we combine the performance information with the communication knowledge?
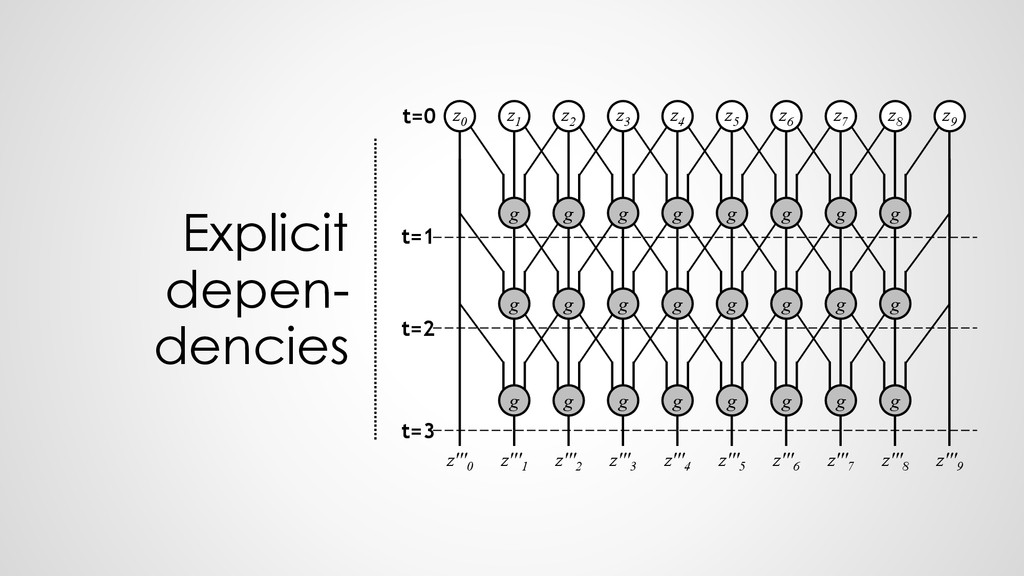
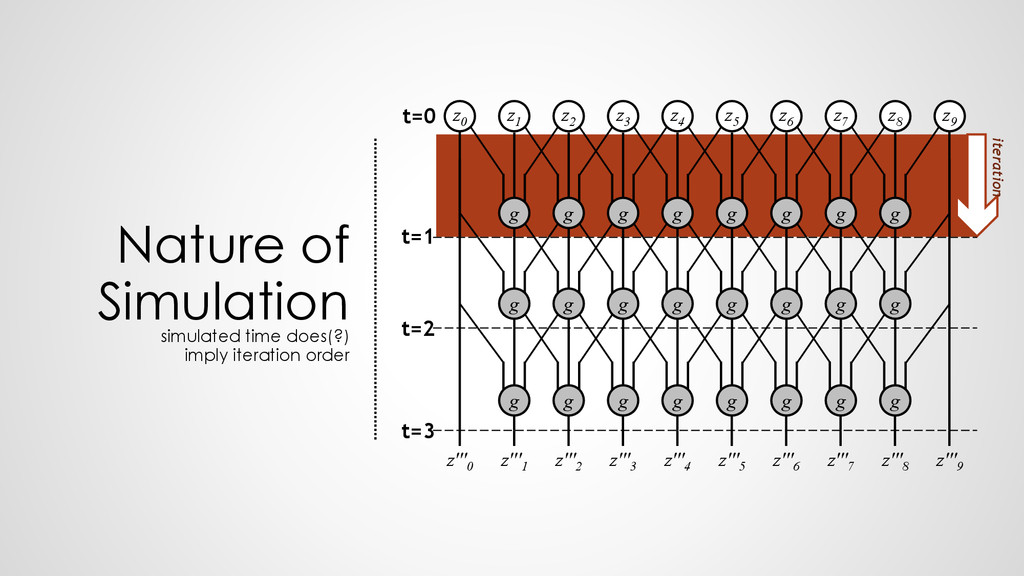
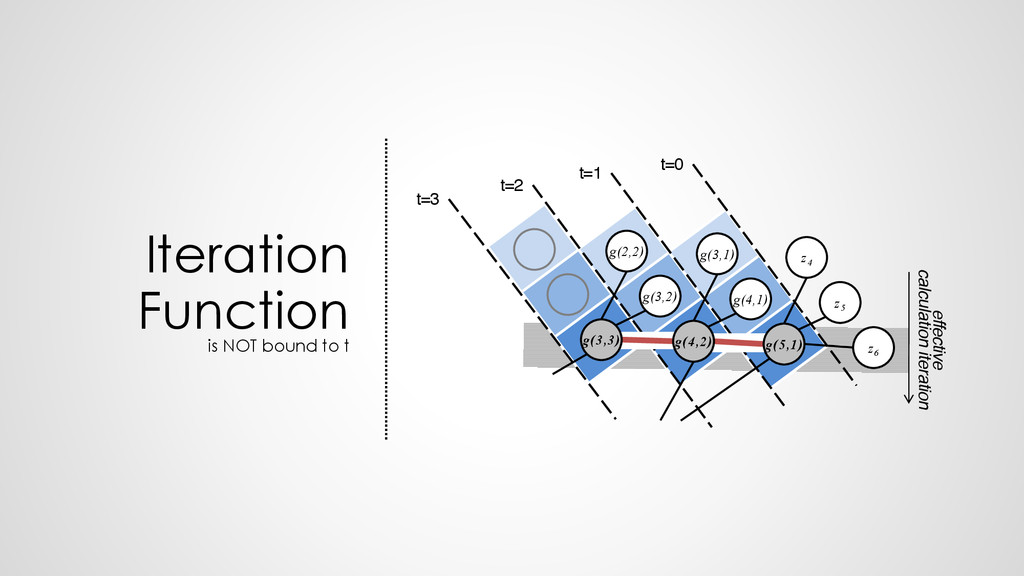
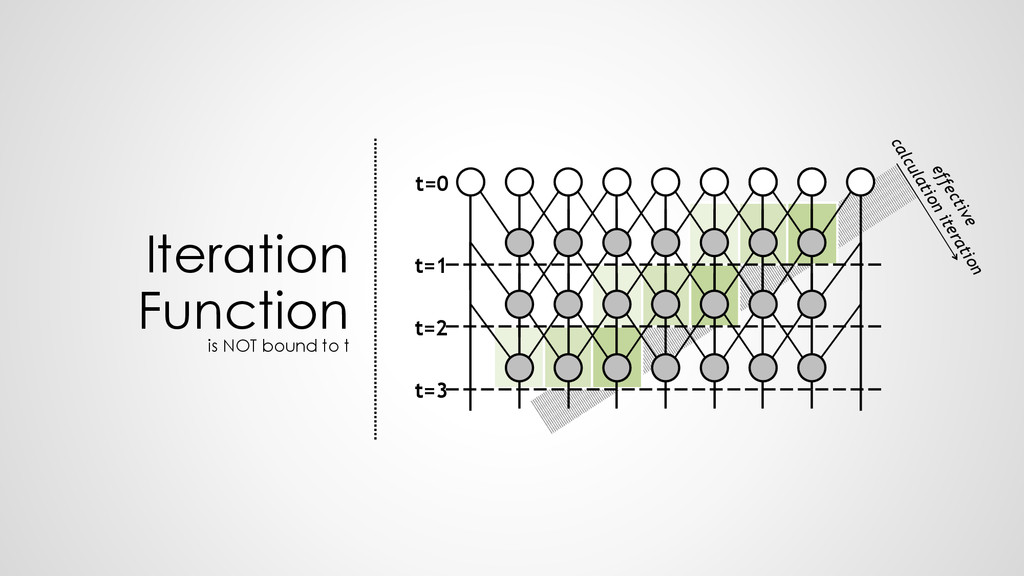
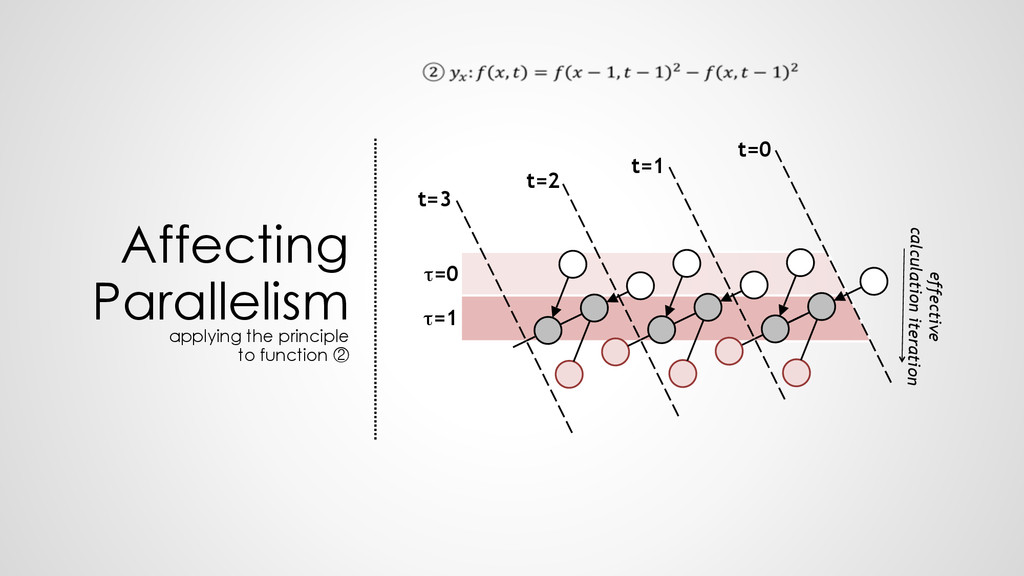
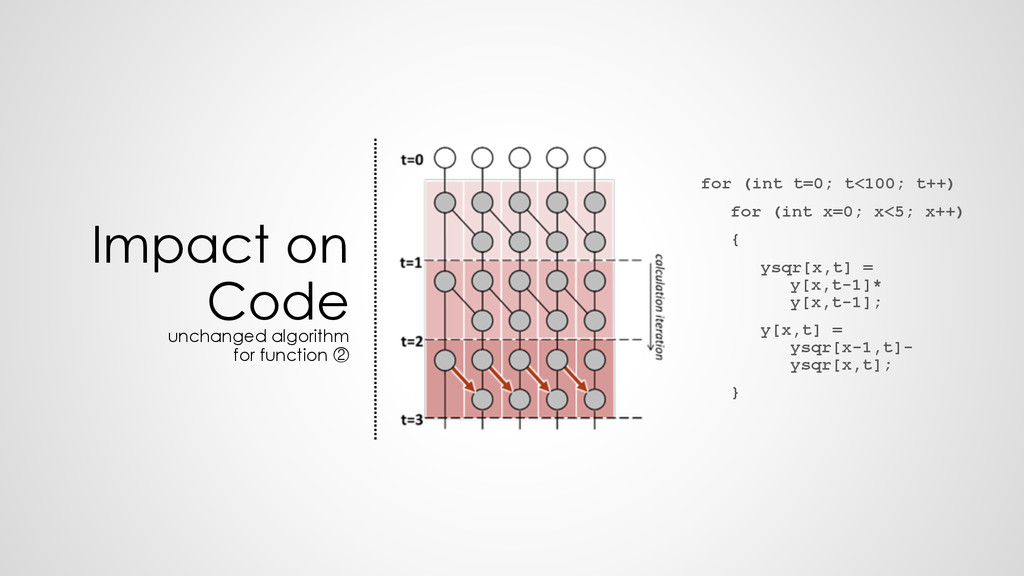
z0 z1 z2 z3 z4 z5 z6 z7 z8 z9 z'''0 z'''1 z'''2 z'''3 z'''4 z'''5 z'''6 z'''7 z'''8 z'''9 t=1 t=2 t=3 g g g g g g g g t=0 g g g g g g g g g g g g g g g g
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
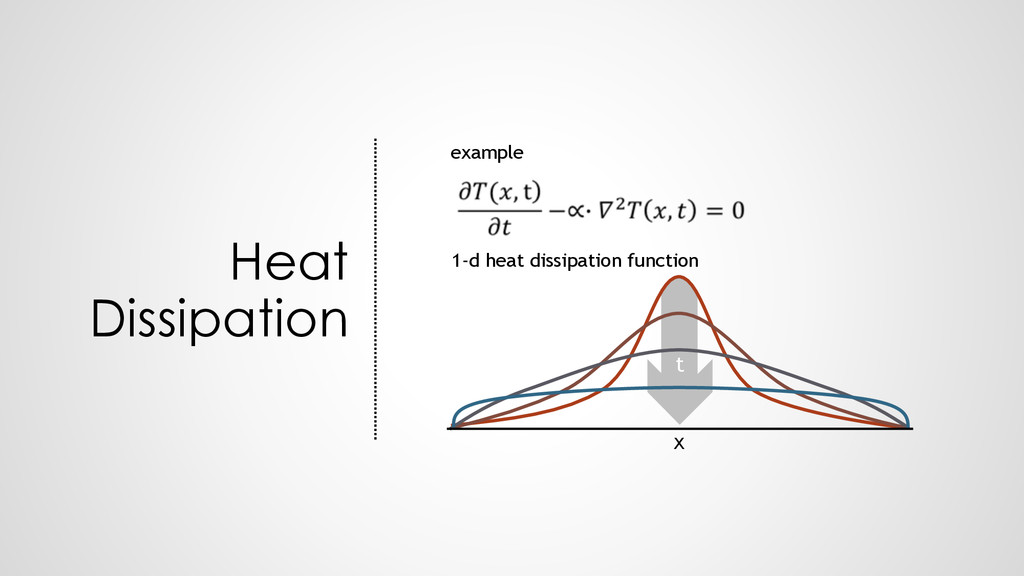{kind=link}
{kind=link}
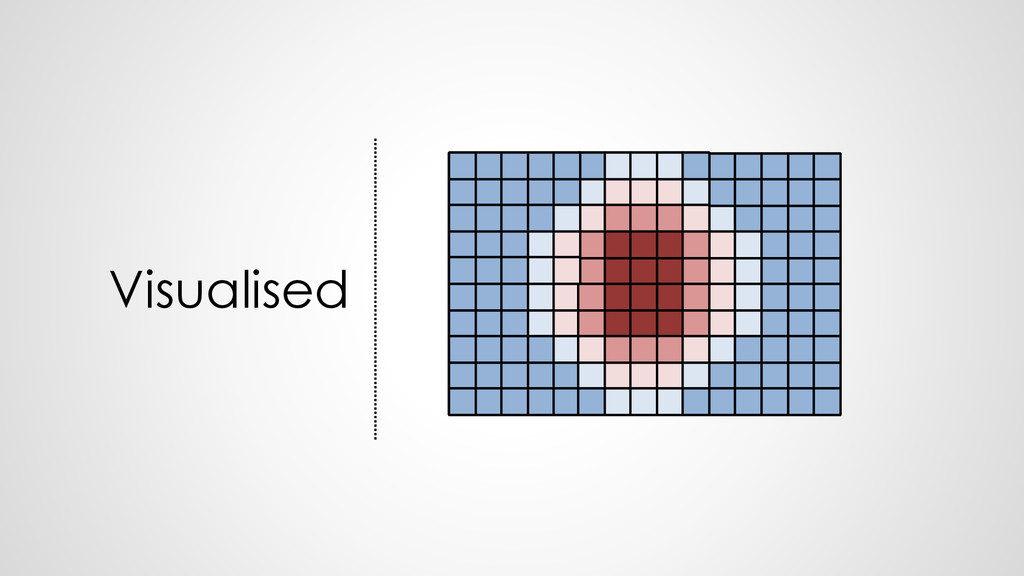{kind=link}
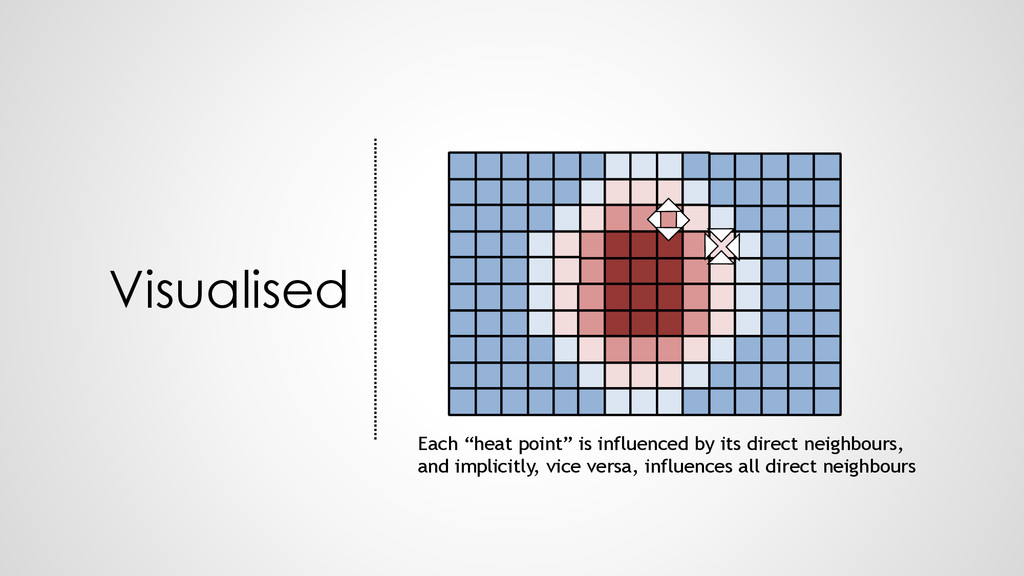{kind=link}
{kind=link}
{kind=link}
![Let’s think about this h[x,y] htmp[x,y ] That‘s fine, isn‘t](https://files.speakerdeck.com/presentations/25486660a7dc0131f452524187cb86b1/slide_25.jpg){kind=link}
{kind=link}
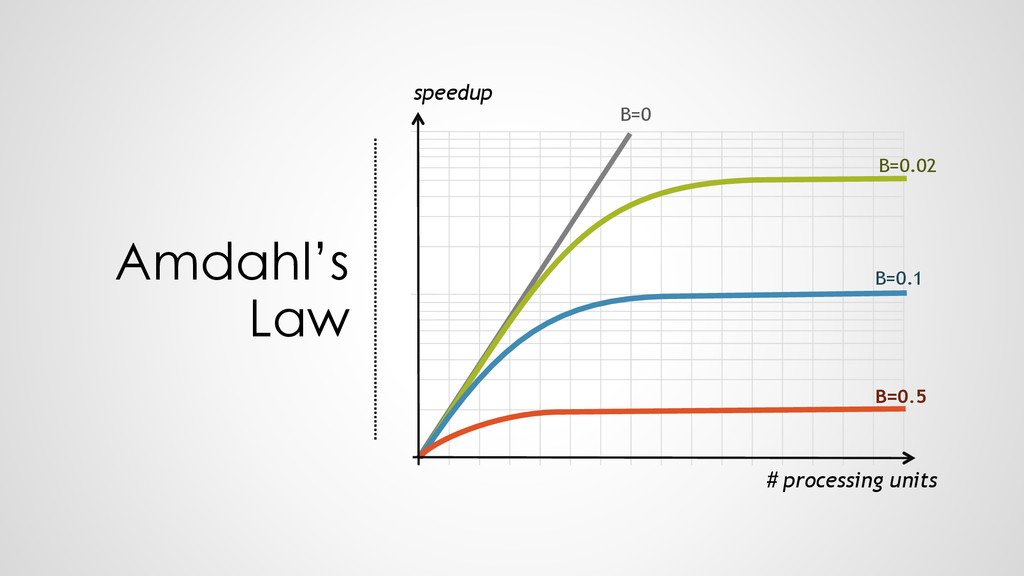{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
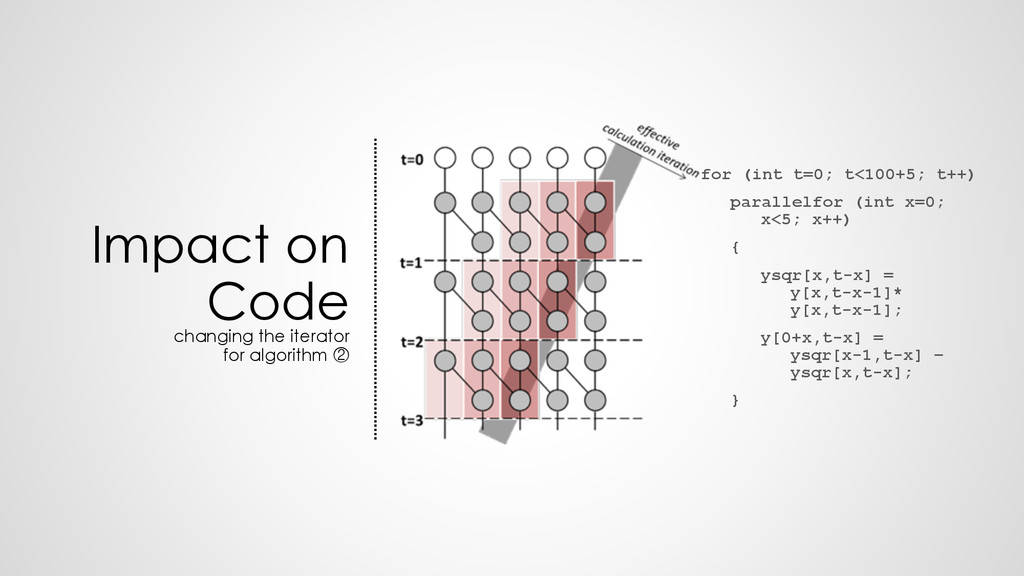{kind=link}
![!! :!!,!= !!−1,!−1+!(!,!−1)∗!!−1,!−1−!!,!−1 Lutz Schubert University of Ulm [email protected] Please](https://files.speakerdeck.com/presentations/25486660a7dc0131f452524187cb86b1/slide_58.jpg){kind=link}
{kind=link}
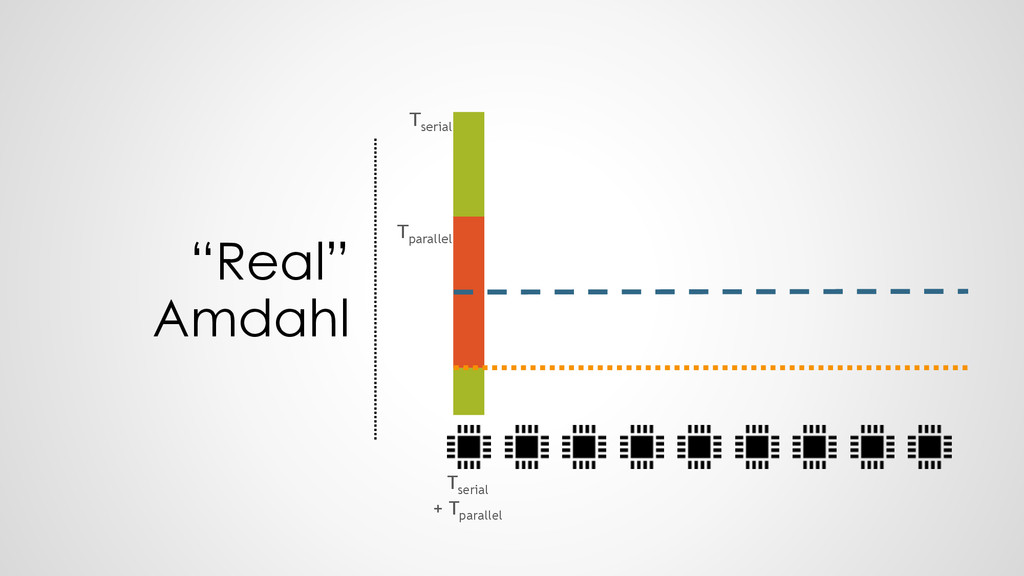{kind=link}
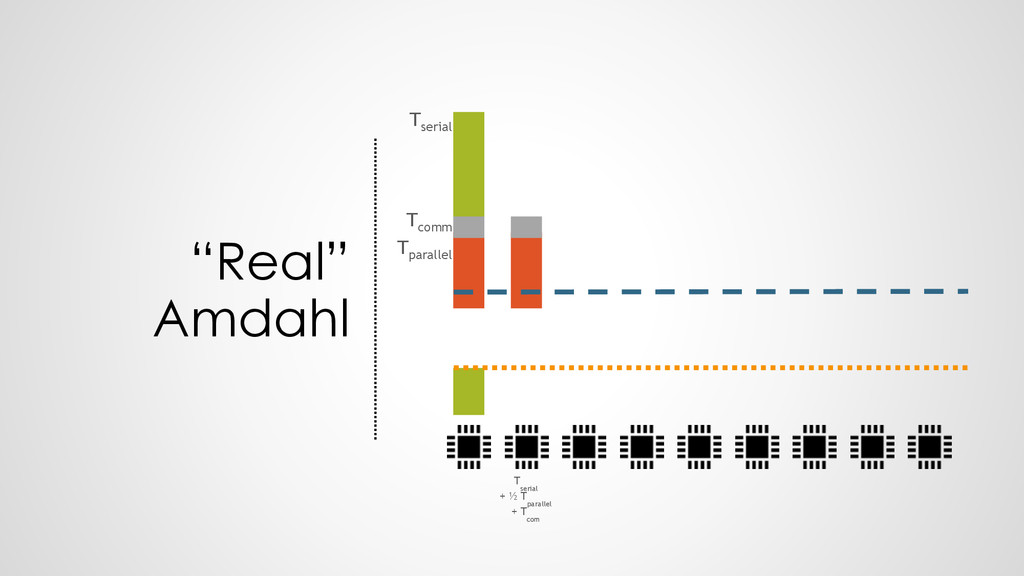{kind=link}
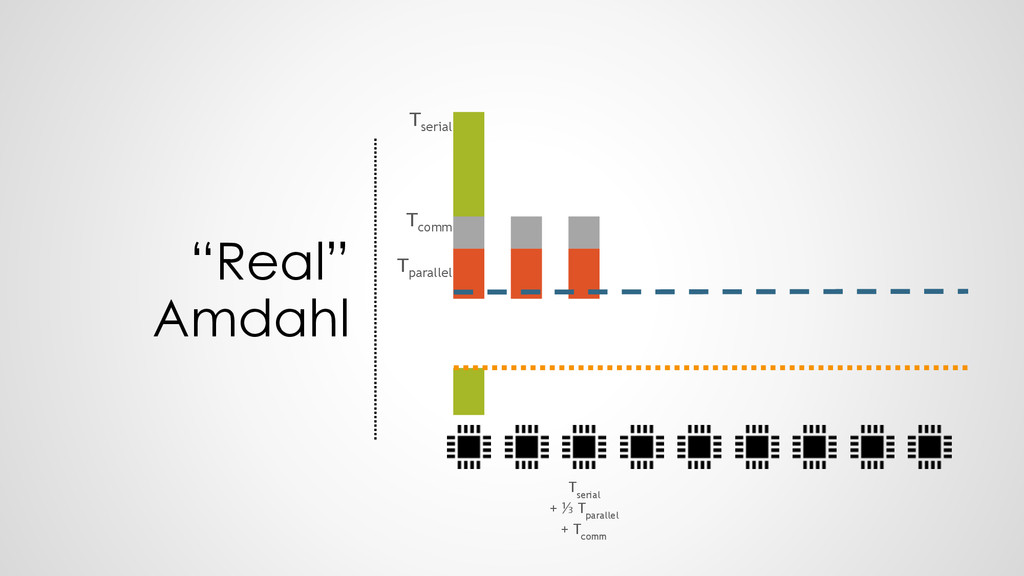{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}