DevOps Moscow meetup: *aaS (as a service), 27-02-2019
Антон Косарев (Severstal)
Расскажу немного про наш стек, в двух словах почему мы выбрали его, далее про то, как мы работаем с данными, про онлайн и оффлайн составляющие (про etl по сути) и потом про то, как Confluent-стек нам помог прийти к концепту data as a service и на что в нашем понимании стоит обращать внимание.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
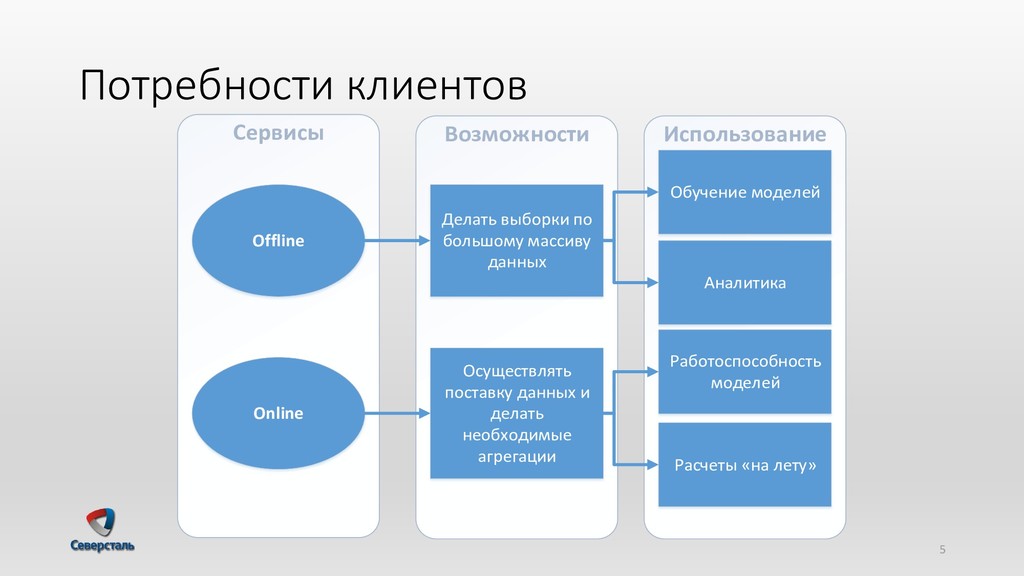{kind=link}
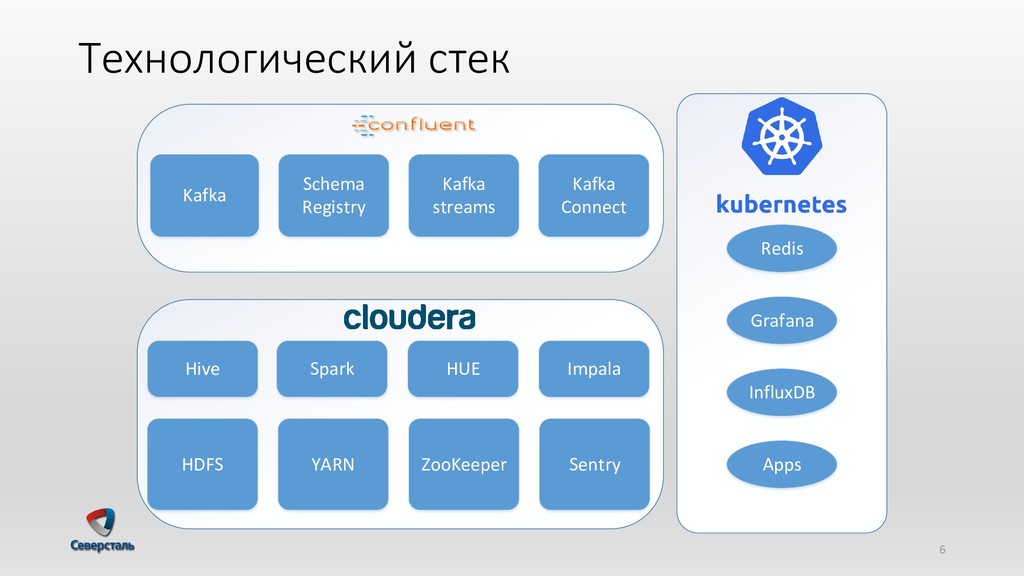{kind=link}
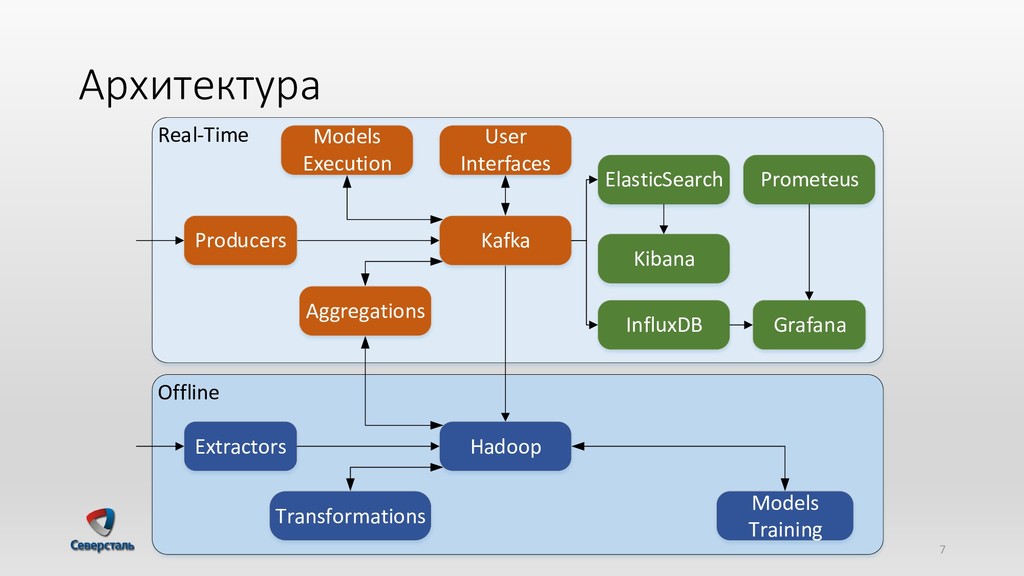{kind=link}
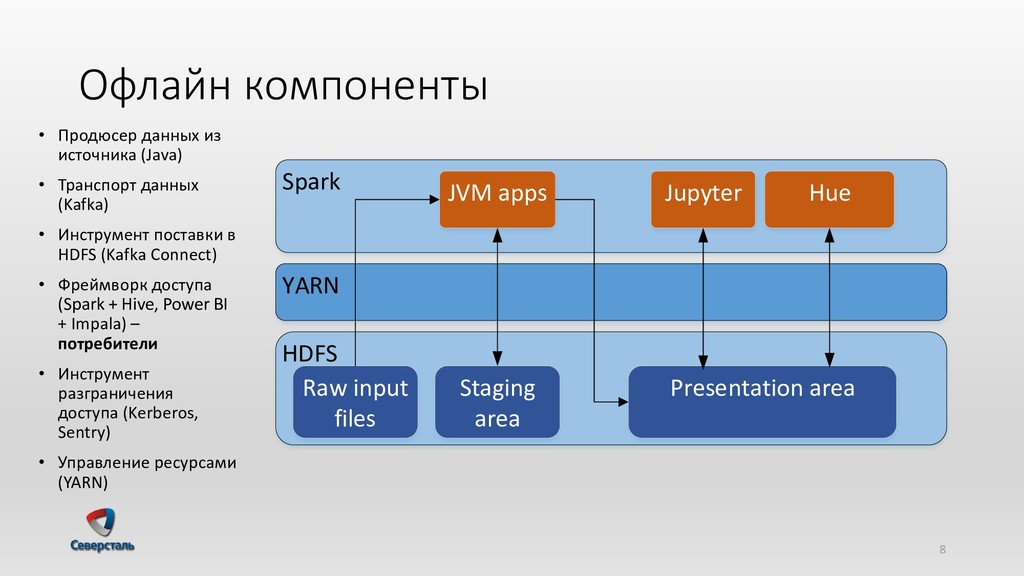{kind=link}
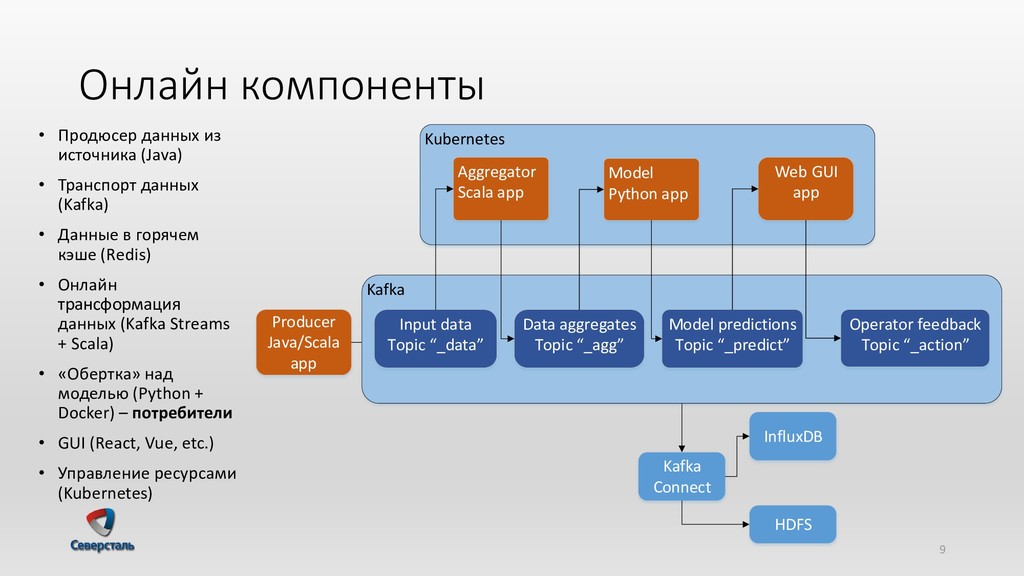{kind=link}
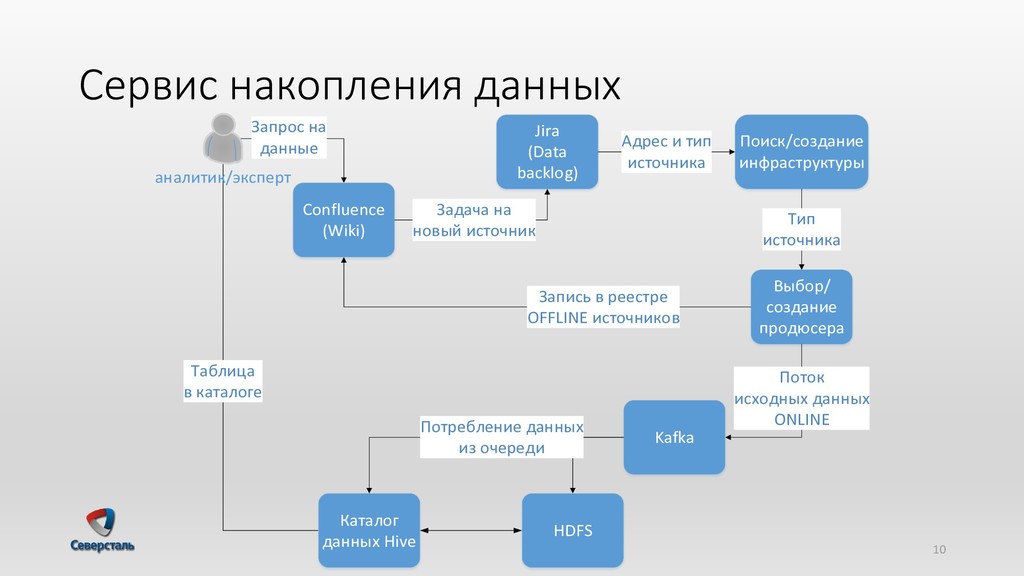{kind=link}
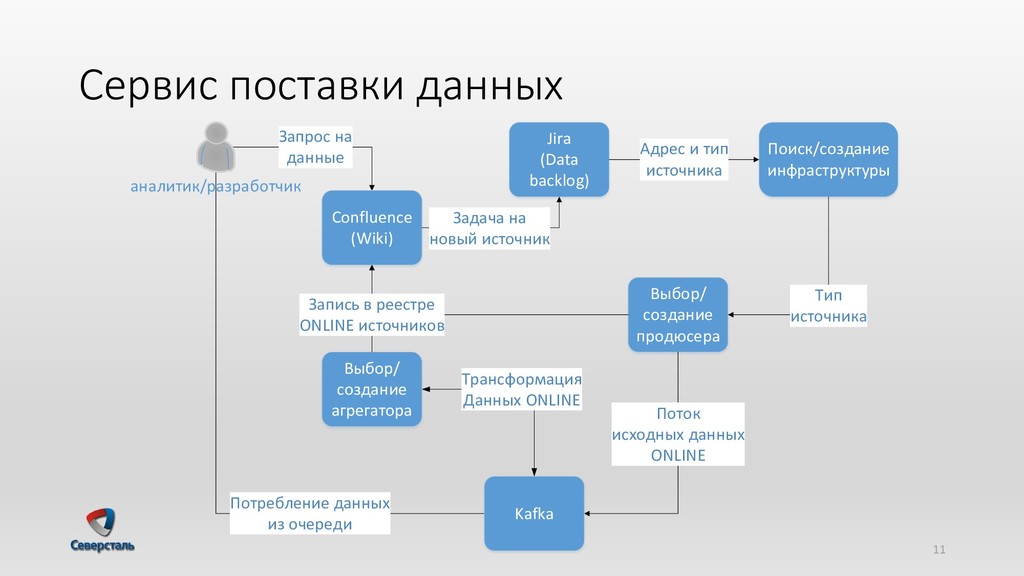{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}