Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Databricksについて.pdf
Search
ディップ株式会社
PRO
February 10, 2026
380
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Databricksについて.pdf
ディップ株式会社
PRO
February 10, 2026
More Decks by ディップ株式会社
See All by ディップ株式会社
_型ガードしたのにnullable_から卒業する.pdf
dip_tech
PRO
0
50
はじめての環境構築!デプロイ〜Docker基礎を学べるワークショップ!
dip_tech
PRO
0
47
【TSKaigi2026登壇資料】決定論的な型チェックへ Go 製コンパイラによる10倍速の裏側で stableTypeOrdering から見える並列化への挑戦
dip_tech
PRO
2
450
【TSKaigi2026登壇資料】バイトル」のTypeScriptリニューアル — 積み上がったレガシーとパフォーマンスに挑む現在地
dip_tech
PRO
1
810
【新卒研修】ライブデモ + compose.yaml読解_講義資料
dip_tech
PRO
0
350
【ディップ|26年新卒研修資料】OpenAPI/Swagger REST API研修
dip_tech
PRO
0
500
【ディップ|26年新卒研修資料】Docker_ハンズオン研修
dip_tech
PRO
0
470
【ディップ|26年新卒研修資料】TDD実装演習
dip_tech
PRO
0
520
ハッカソンや個人開発で何作る? テーマ発見〜アイデア発想ハンズオン! 技育CAMPアカデミア
dip_tech
PRO
0
100
Featured
See All Featured
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Leo the Paperboy
mayatellez
8
1.9k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
Designing for humans not robots
tammielis
254
26k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
My Coaching Mixtape
mlcsv
0
180
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Mobile First: as difficult as doing things right
swwweet
225
10k
Music & Morning Musume
bryan
47
7.3k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
390
Transcript
None
自己紹介 / 本日の背景 プロフィール: 氏名: 木村 優子 (プラットフォーム部 データ基盤課) 業務:
BigQueryを中心とした社内分析データ基盤の運用・開発 今回の背景 : 1. DX事業(スポバ・トーク・コボット等 ) のAWSデータ基盤を当課へ移管。 2. 現状課題 : 仕様変更対応等の「運用工数」が肥大化しており、リソースを圧迫。 3. 目的: 運用負荷を最小化するため、 Databricks Lakeflowによる刷新を検討。
背景:データ活用における「2つの世界」の分断 これまでのデータ基盤には、大きな「壁」がありました。 1. データレイク(Data Lake): - AI/機械学習エンジニアが使う「ファイル置き場」。安価だが管理が難しい。 2. データウェアハウス( Data
Warehouse): - アナリストが使う「綺麗なデータベース」。管理は楽だが高価で柔軟性がない。 課題: データが分断され、移動やコピーの管理コストが肥大化していた。
解決策:Databricksの「レイクハウス」 「レイク」の柔軟性と「ハウス」の管理機能を統合 Databricksとは?: - 世界標準の分散処理「 Apache Spark」の開発者たちが創業。 - 世界中のデータ先進企業で採用される「データ・インテリジェンス」基盤。 Unity
Catalog(ユニティ・カタログ) : - データの置き場所は 1つ。AIもBIも、全データを一元管理できる。
なぜ我々のチームに合うのか? 高度なスキルセット不要で、最新技術を導入可能 1. SQL中心の実装 (SQL First): - 難しいプログラミング( Scala/Python)は必須ではない。 -
チーム全員が使い慣れた SQLだけで、 AI基盤レベルの処理が可能。 2. サーバーレス (Serverless): - インフラ構築やバージョン管理が不要。 - 「使った分だけ課金」で、スモールスタートに最適。
直面している課題: 開発スピードへの「追従コスト」 活発な仕様変更(例: スポットバイトル等)への対応が限界 現状の運用( Human Middleware): - 開発チームの Slackを目視監視し、仕様変更を検知。
- 変更があれば、手動で RedshiftにDDLを適用(見落とすと停止)。 → 課題: 「Slack張り付き」による認知負荷が高く、本来の業務を圧迫。
解決策:Lakeflow SDP (宣言的パイプライン) 仕様変更に依存しない「疎結合」なパイプラインへ Lakeflow SDPのアプローチ: - 複雑な取り込み手順ではなく、「必要なデータ(結果)」のみを SQLで定義。 -
Auto Loaderがファイルを監視し、差分を自動検知。 - 上流でカラムが増えても、定義外のものは「無視」して稼働継続。
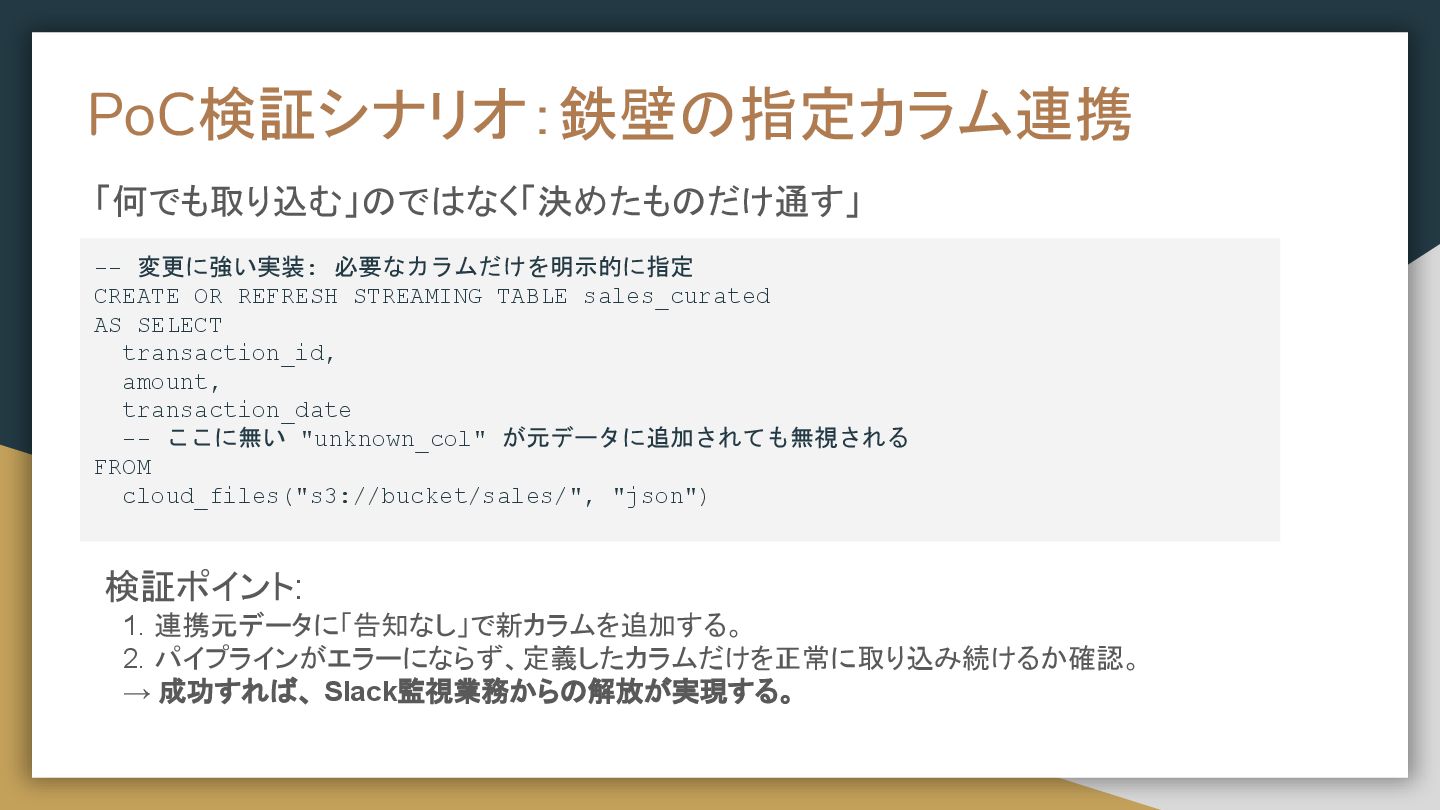
PoC検証シナリオ:鉄壁の指定カラム連携 「何でも取り込む」のではなく「決めたものだけ通す」 -- 変更に強い実装: 必要なカラムだけを明示的に指定 CREATE OR REFRESH STREAMING TABLE
sales_curated AS SELECT transaction_id, amount, transaction_date -- ここに無い "unknown_col" が元データに追加されても無視される FROM cloud_files("s3://bucket/sales/", "json") 検証ポイント: 1. 連携元データに「告知なし」で新カラムを追加する。 2. パイプラインがエラーにならず、定義したカラムだけを正常に取り込み続けるか確認。 → 成功すれば、 Slack監視業務からの解放が実現する。 「何でも取り込む」のではなく「決めたものだけ通す」
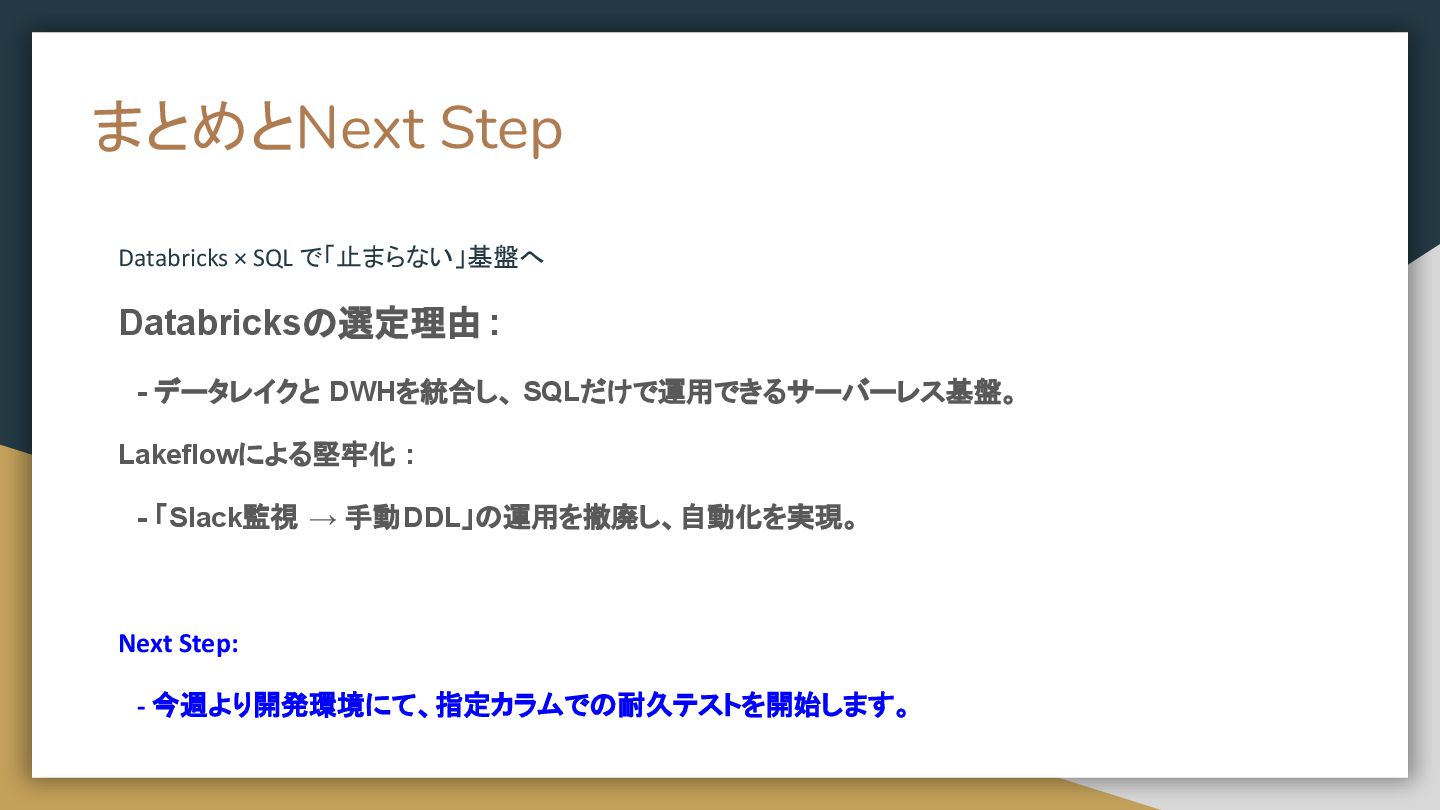
まとめとNext Step Databricks × SQL で「止まらない」基盤へ Databricksの選定理由 : - データレイクと
DWHを統合し、 SQLだけで運用できるサーバーレス基盤。 Lakeflowによる堅牢化 : - 「Slack監視 → 手動DDL」の運用を撤廃し、自動化を実現。 Next Step: - 今週より開発環境にて、指定カラムでの耐久テストを開始します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}