with local error signals. arXiv, 1901.06656. 2. Bengio Y, Lee D, Bornschein J, Mesnard T, and Lin Z. Towards biologically plausible deep learning. CoRR, abs/1407.7906, 2014. URL http://arxiv.org/abs/1812.11446. 3. Lillicrap TP, Cownden D, Tweed DB, and Akerman CJ. Random synaptic feedback weights support error backpropagation for deep learning. Nature Communications, 7:13276, 2016. 4. Sacramento J, Costa RP, Bengio Y, and Senn W. Dendritic cortical microcircuits approximate the backpropagation algorithm. CoRR, abs/1810.11393, 2018. URL http://dblp.uni- trier.de/db/journals/corr/corr1810.html #abs-1810-11393. 5. Gadagkar V, Puzerey PA, Chen R, Baird-Daniel E, Farhang AR, and Goldberg JH. Science, 354:1278-1282, 2016. 6. Moskovitz TH, Litwin-Kumar A, and Abbott L. Feedback alignment in deep convolutional networks. CoRR, 12 2018.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
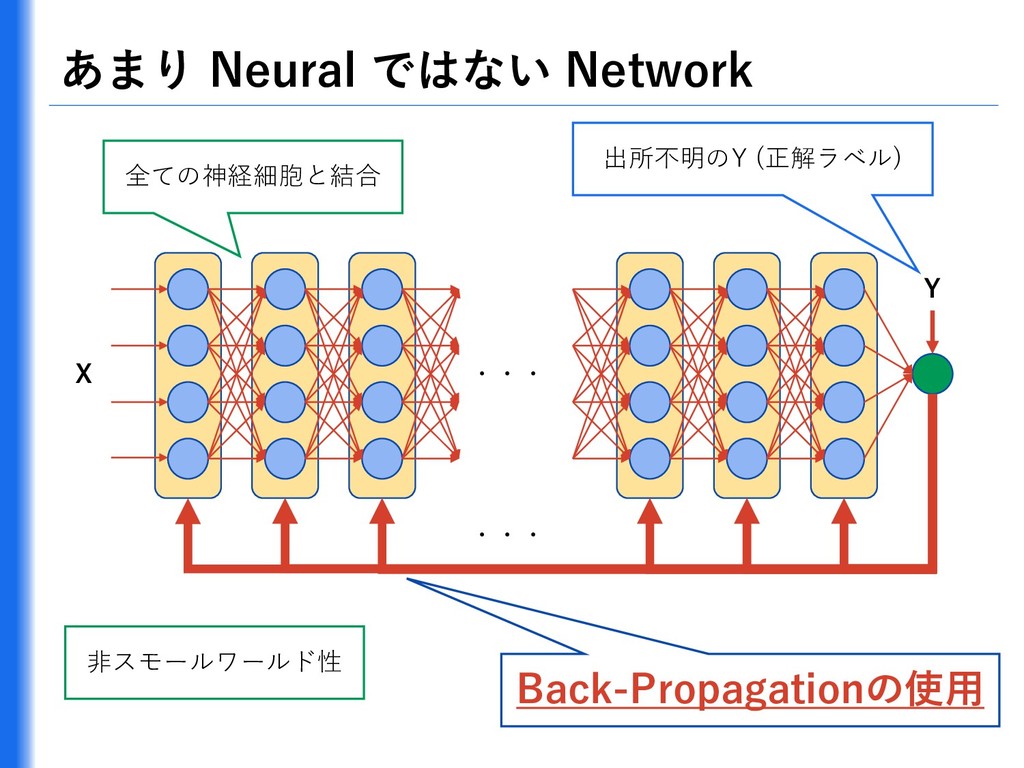{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
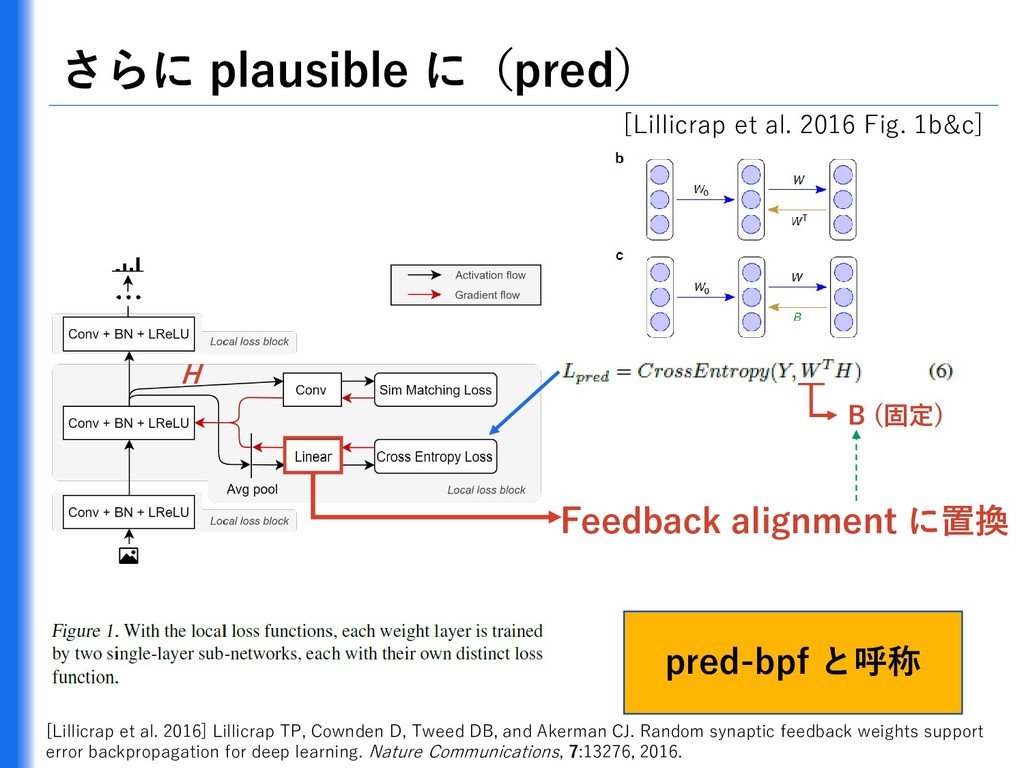
![逆行路は、順行路と同じ重みを保持する必要はない 「3. 同様に、対応する重みも保持する必要がある」 [Lillicrap et al. 2016] Lillicrap TP, Cownden](https://files.speakerdeck.com/presentations/f29e00d67c0f4edb814802cd7da2bd1d/slide_9.jpg){kind=link}
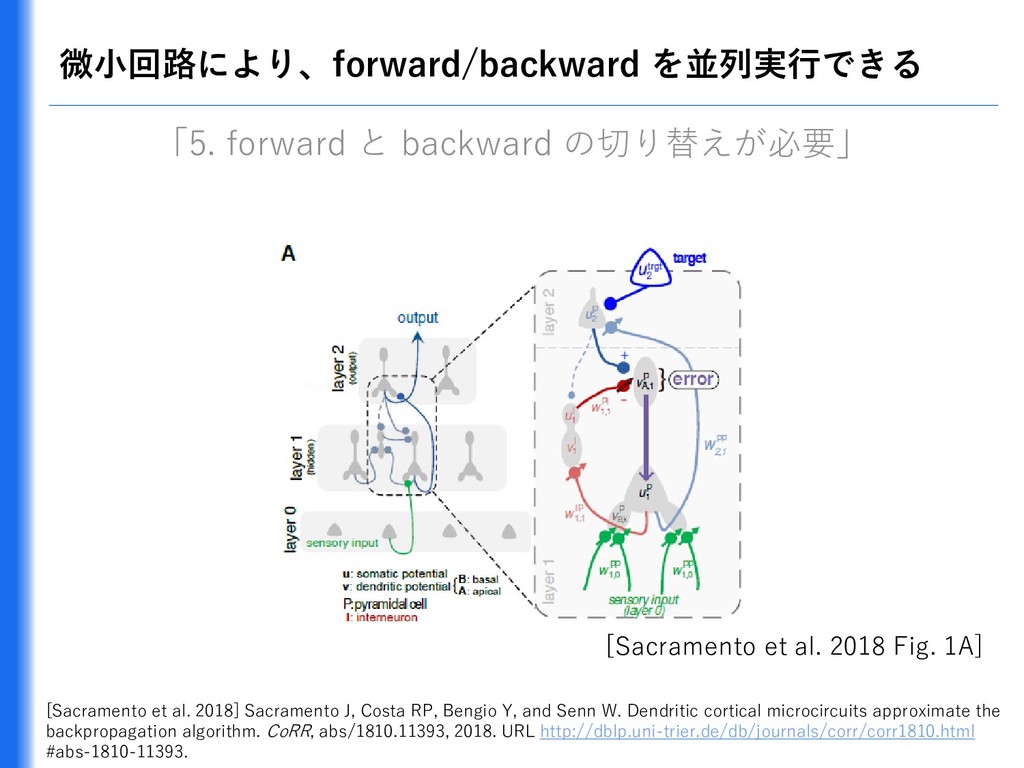{kind=link}
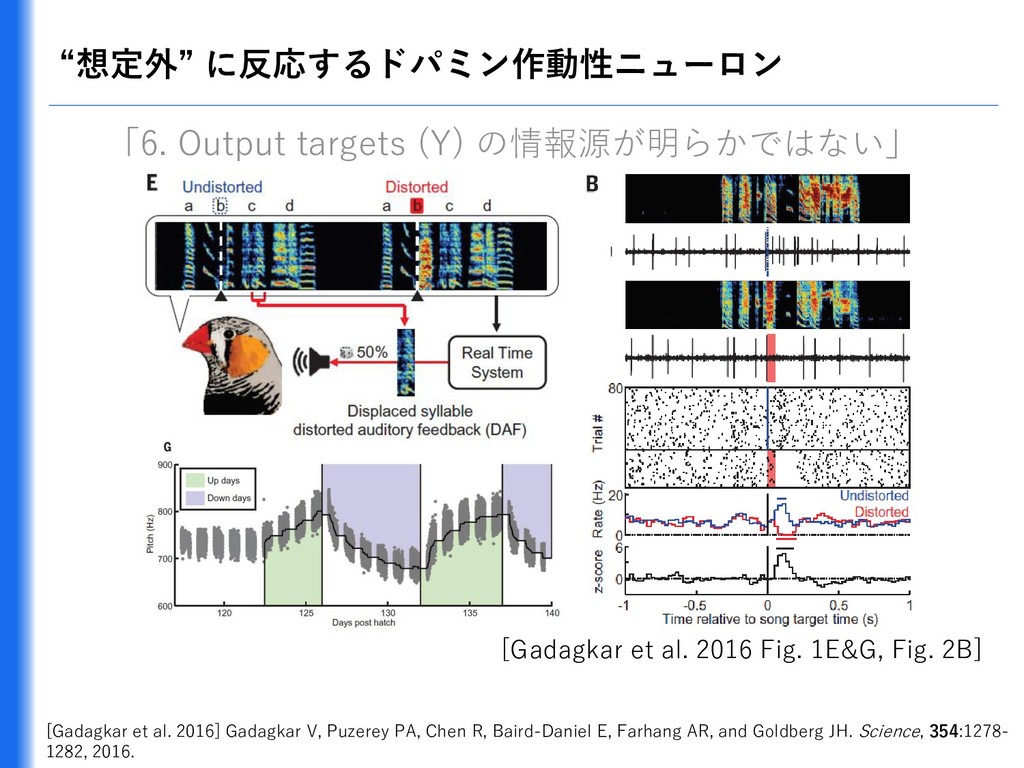{kind=link}
{kind=link}
{kind=link}
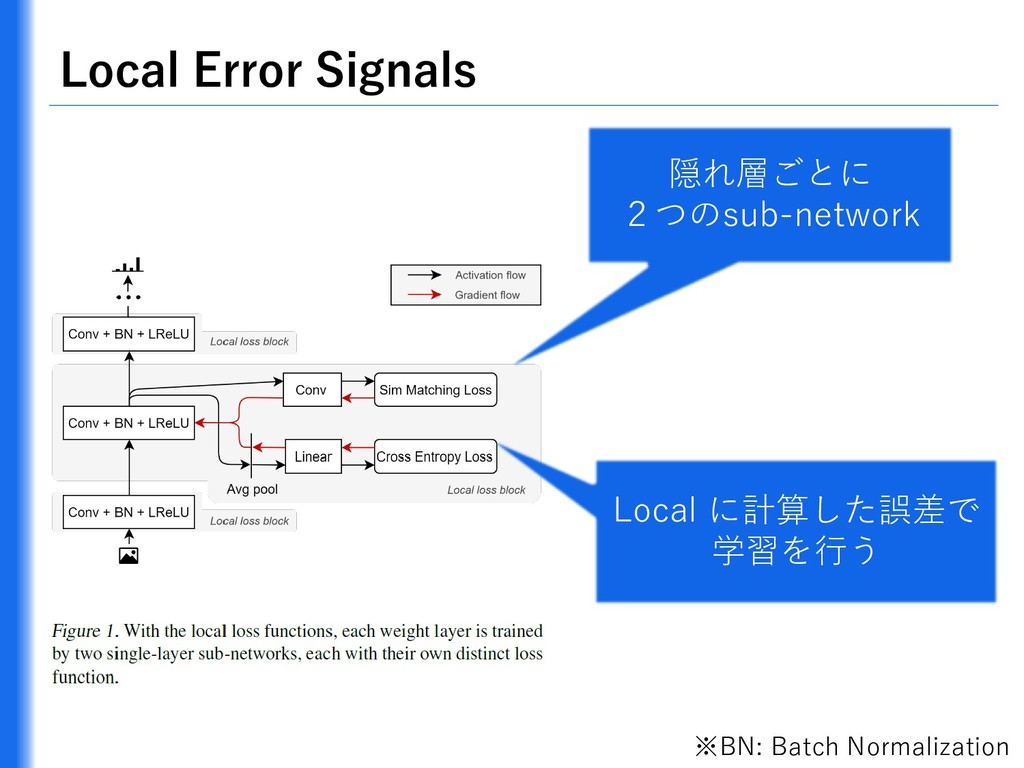{kind=link}
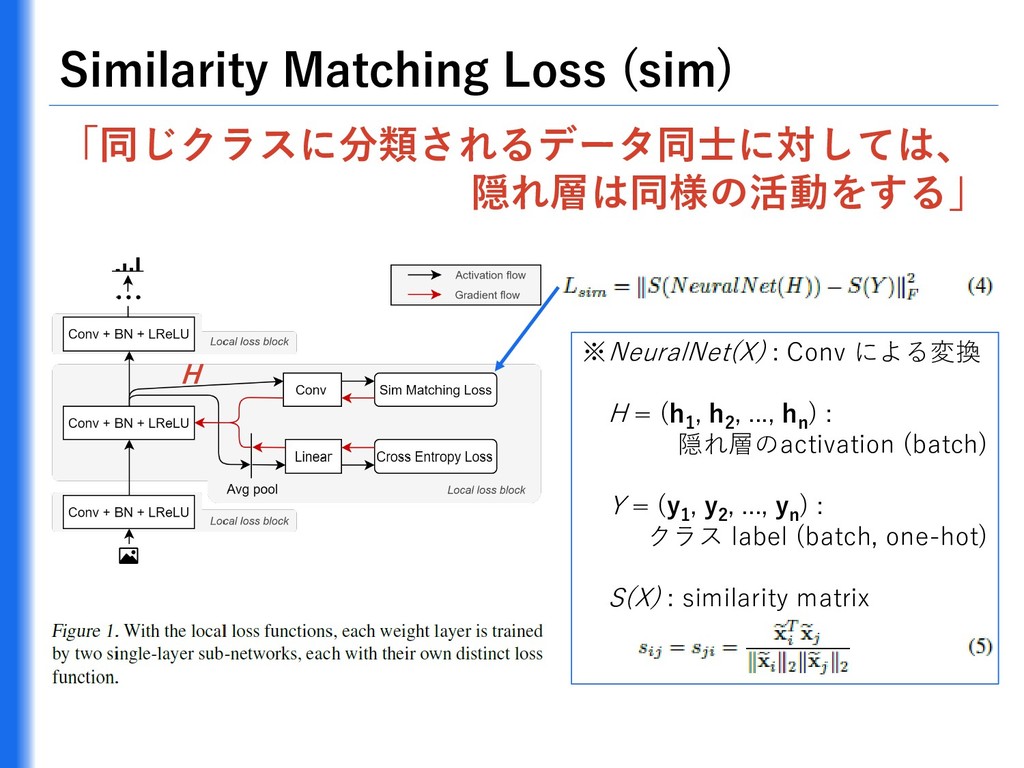{kind=link}
{kind=link}
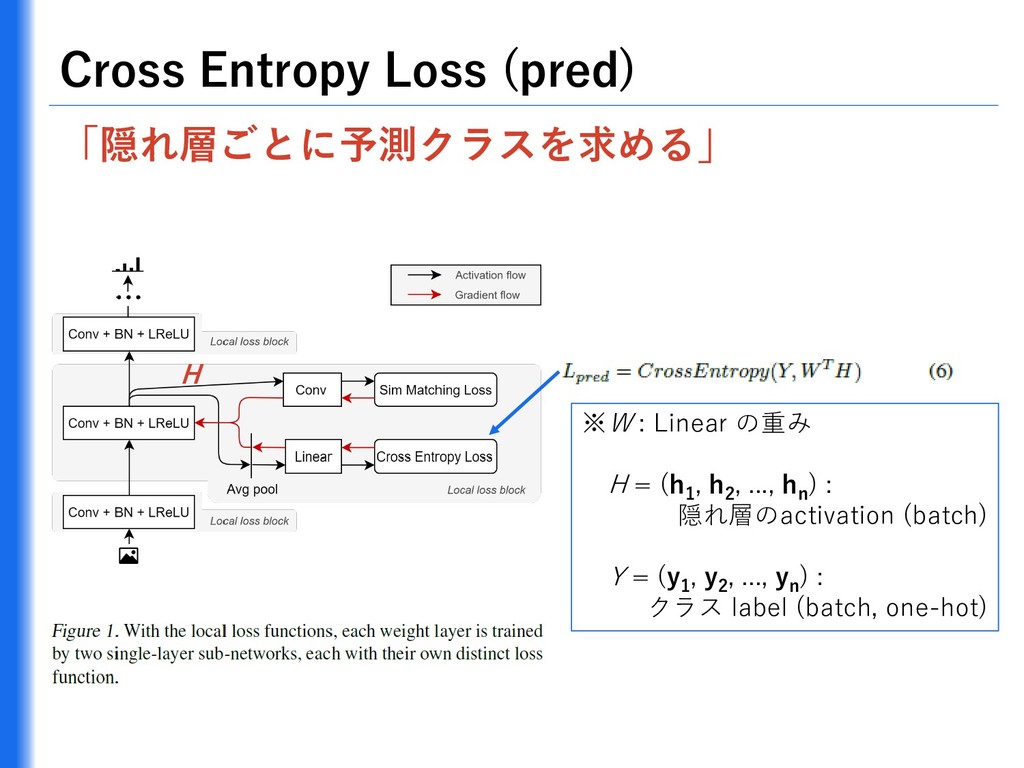{kind=link}
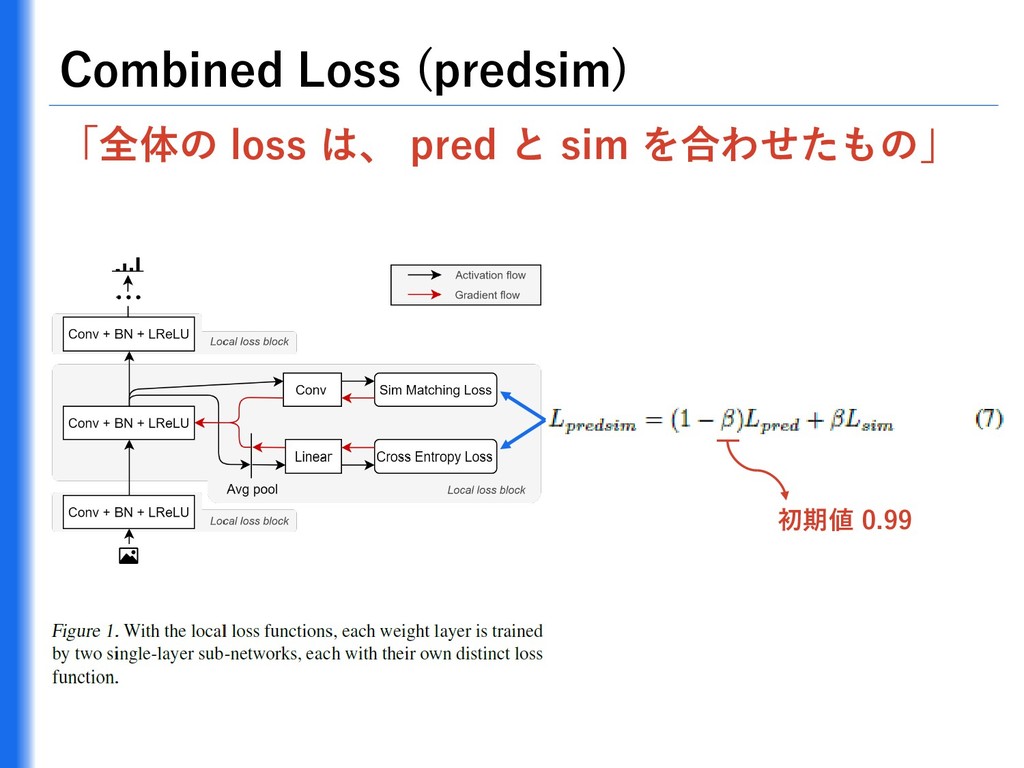{kind=link}
{kind=link}
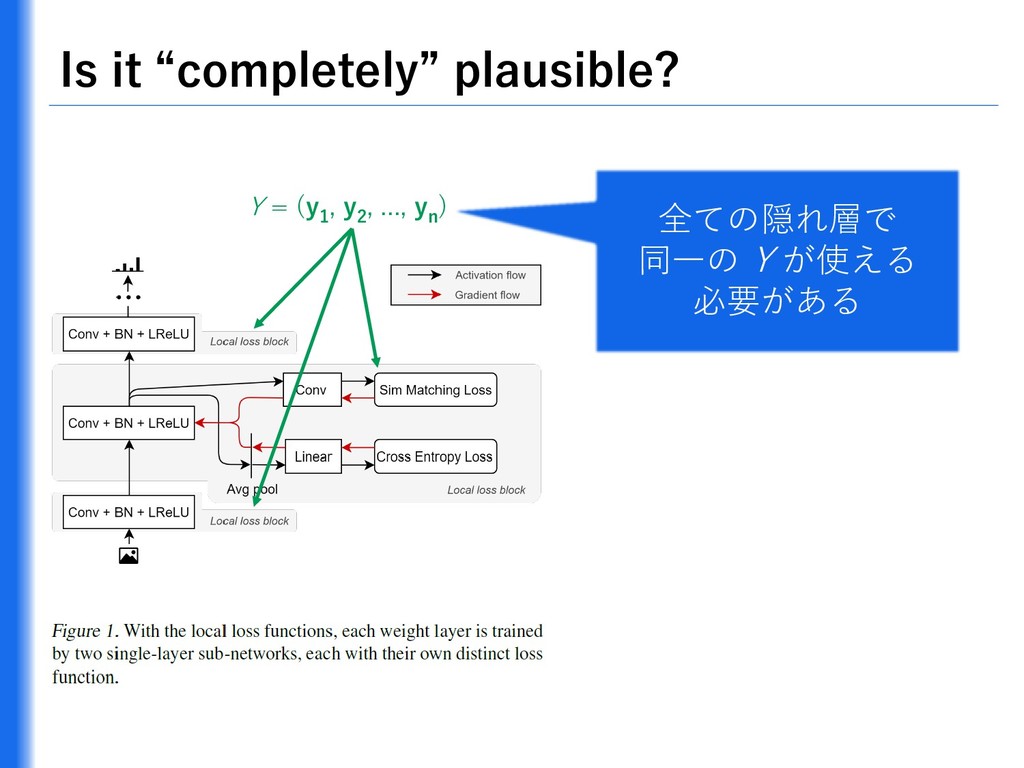{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
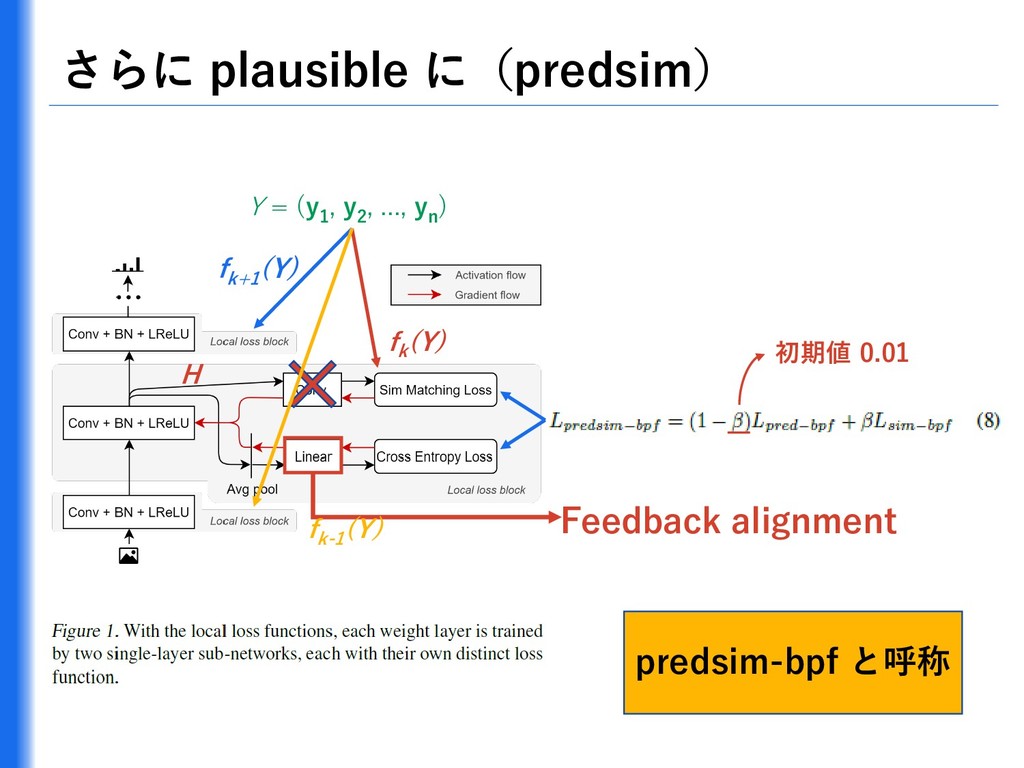{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
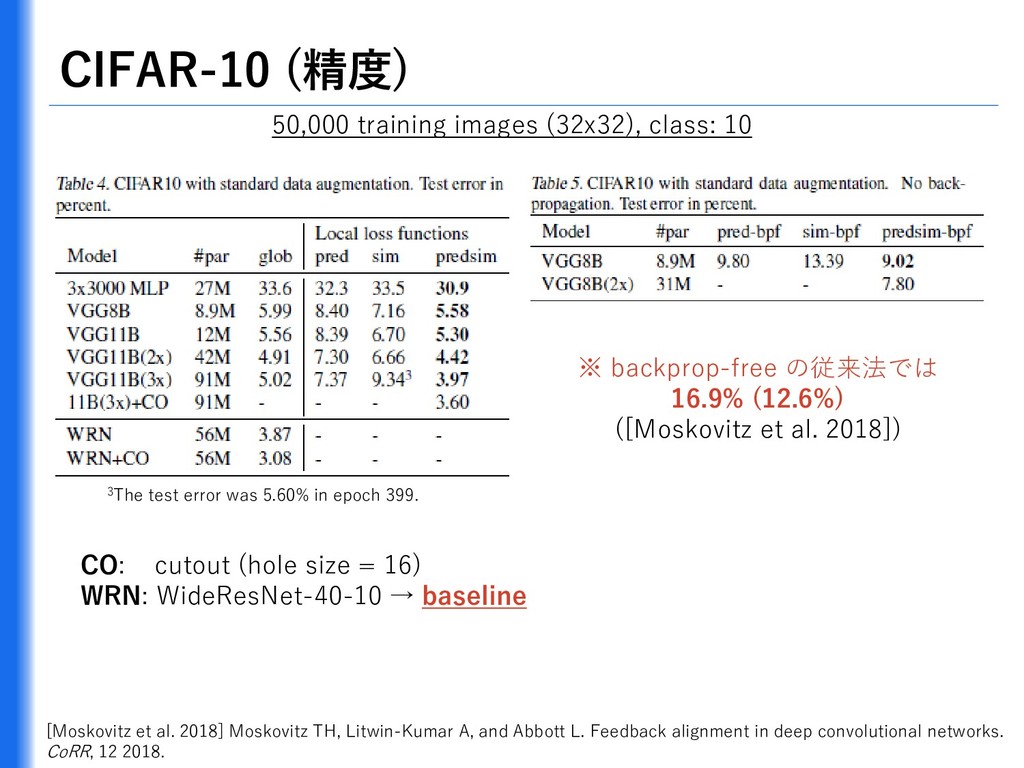{kind=link}
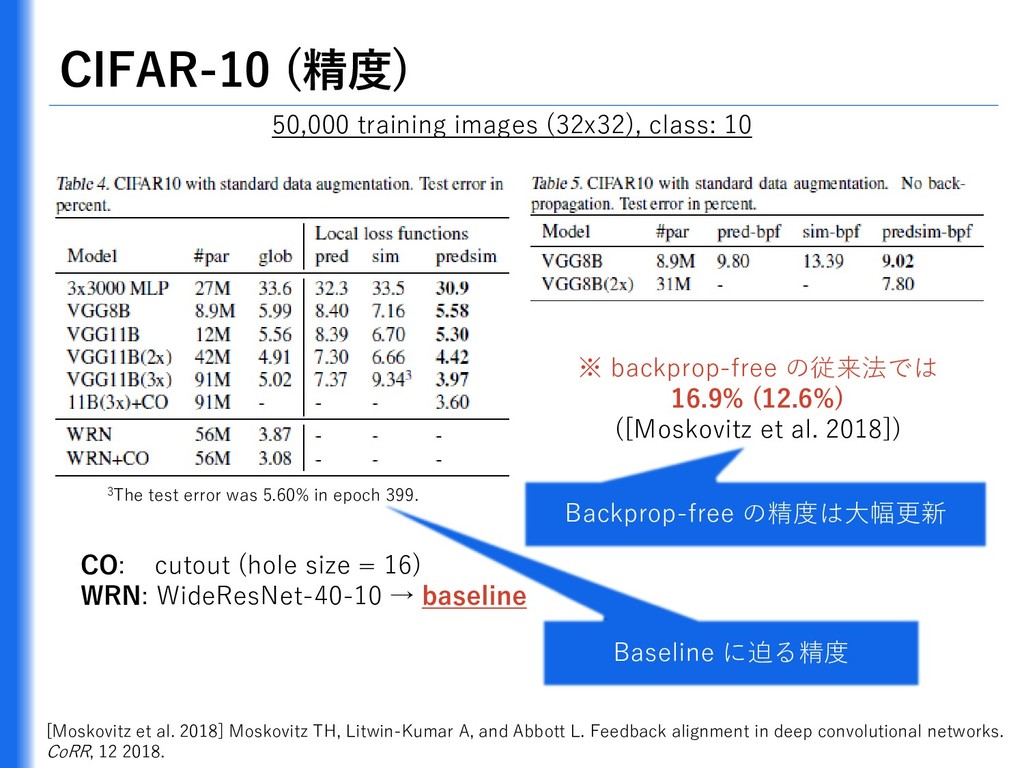{kind=link}
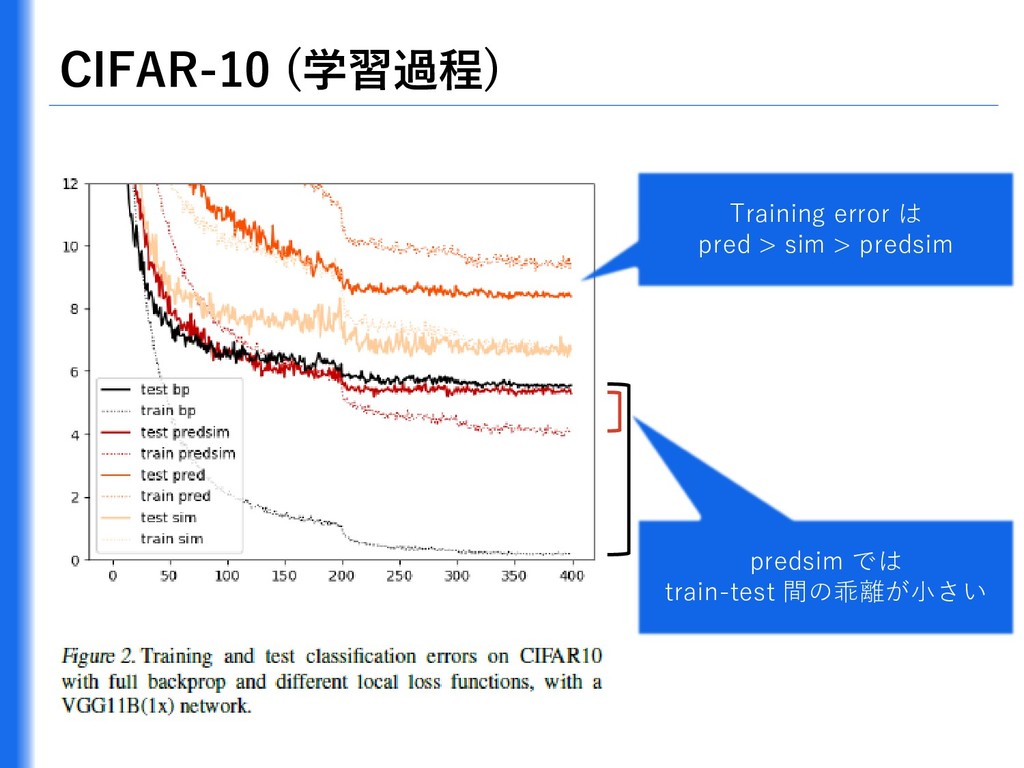{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
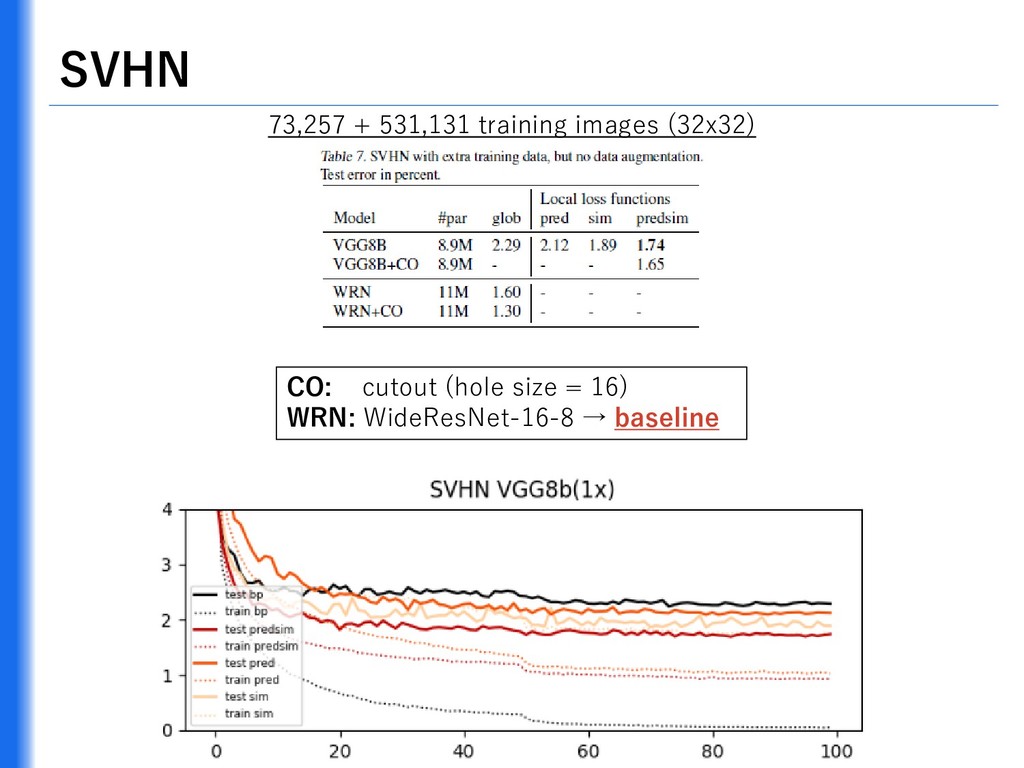{kind=link}
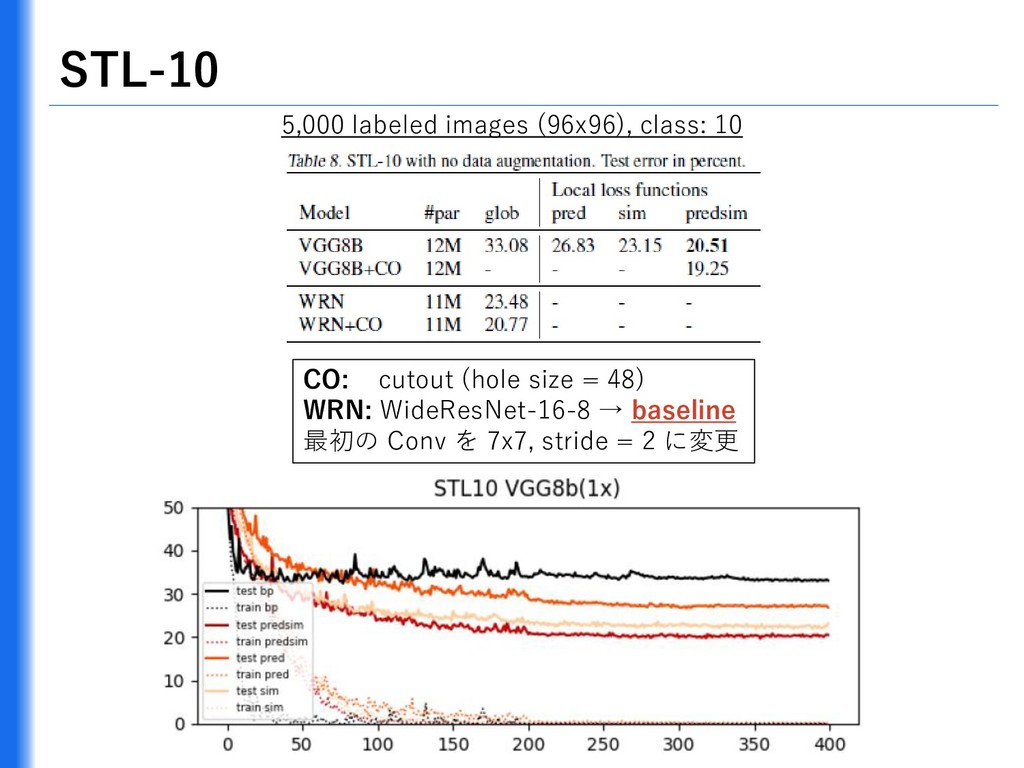{kind=link}
{kind=link}
{kind=link}
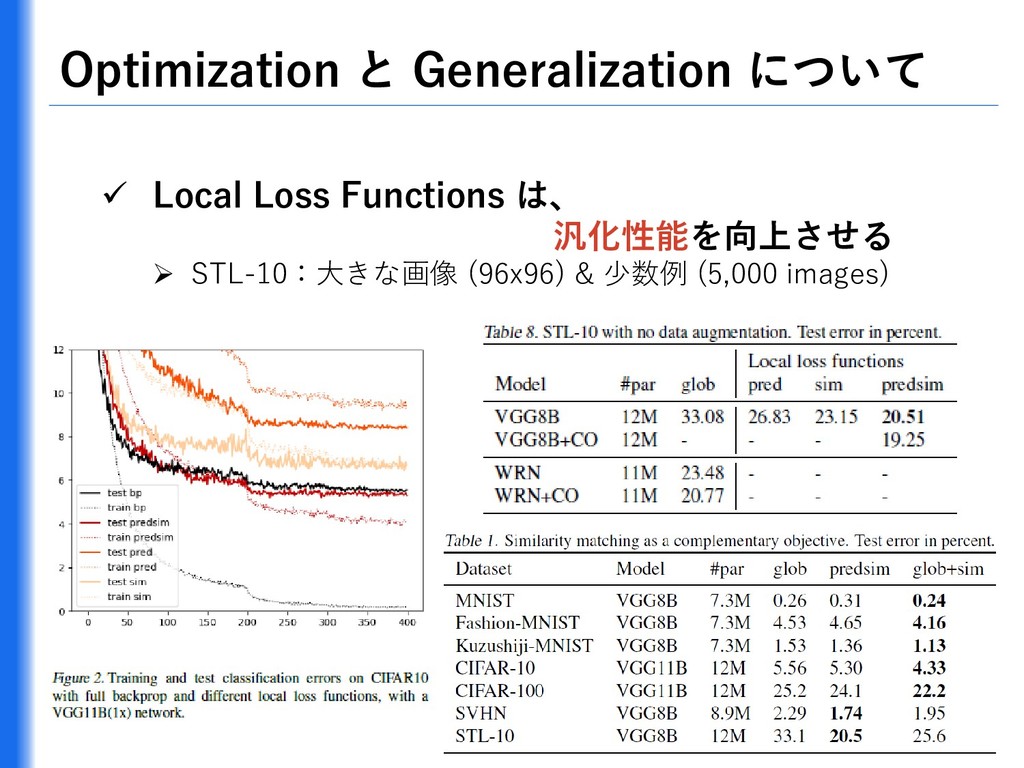{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}