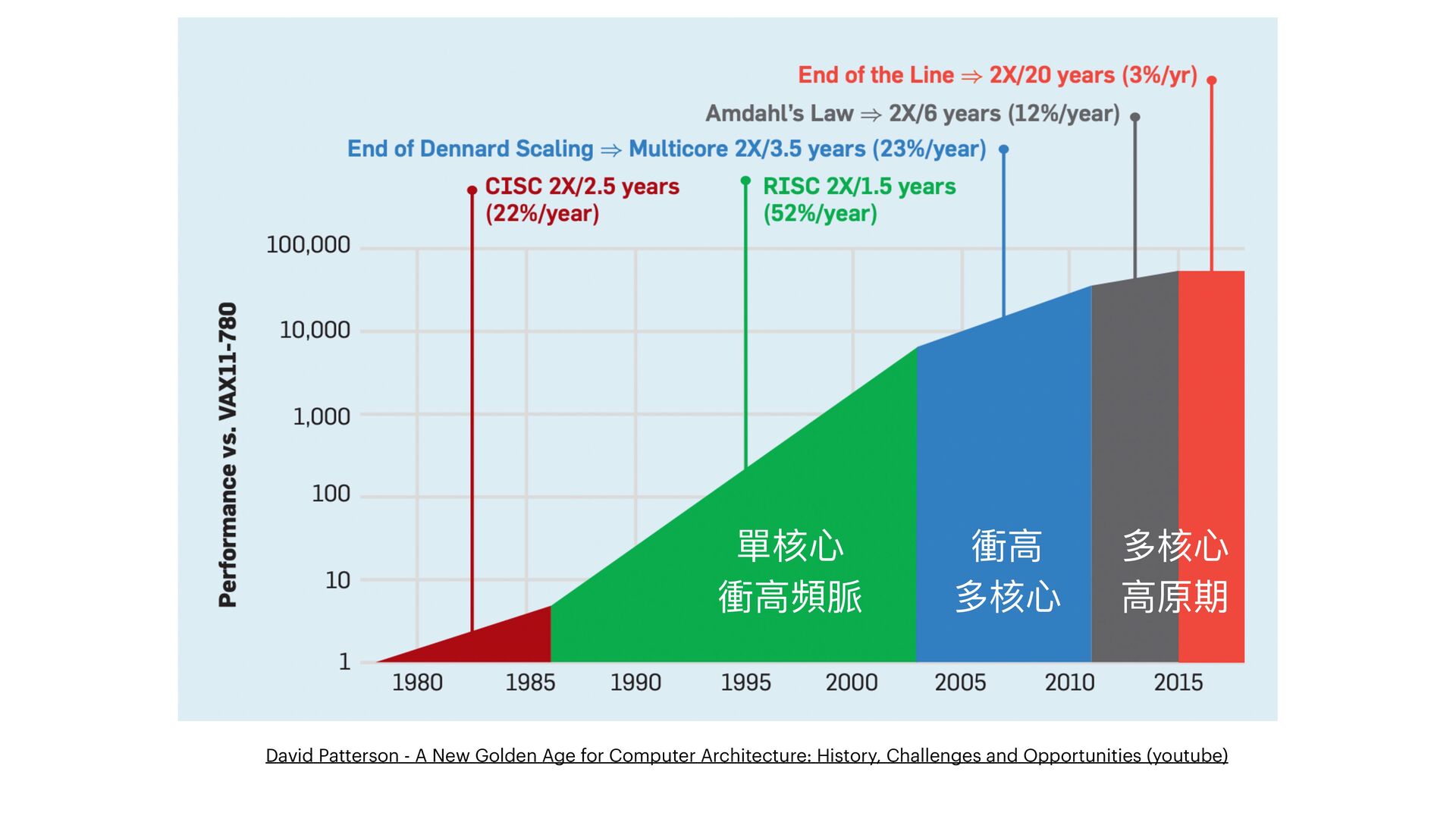
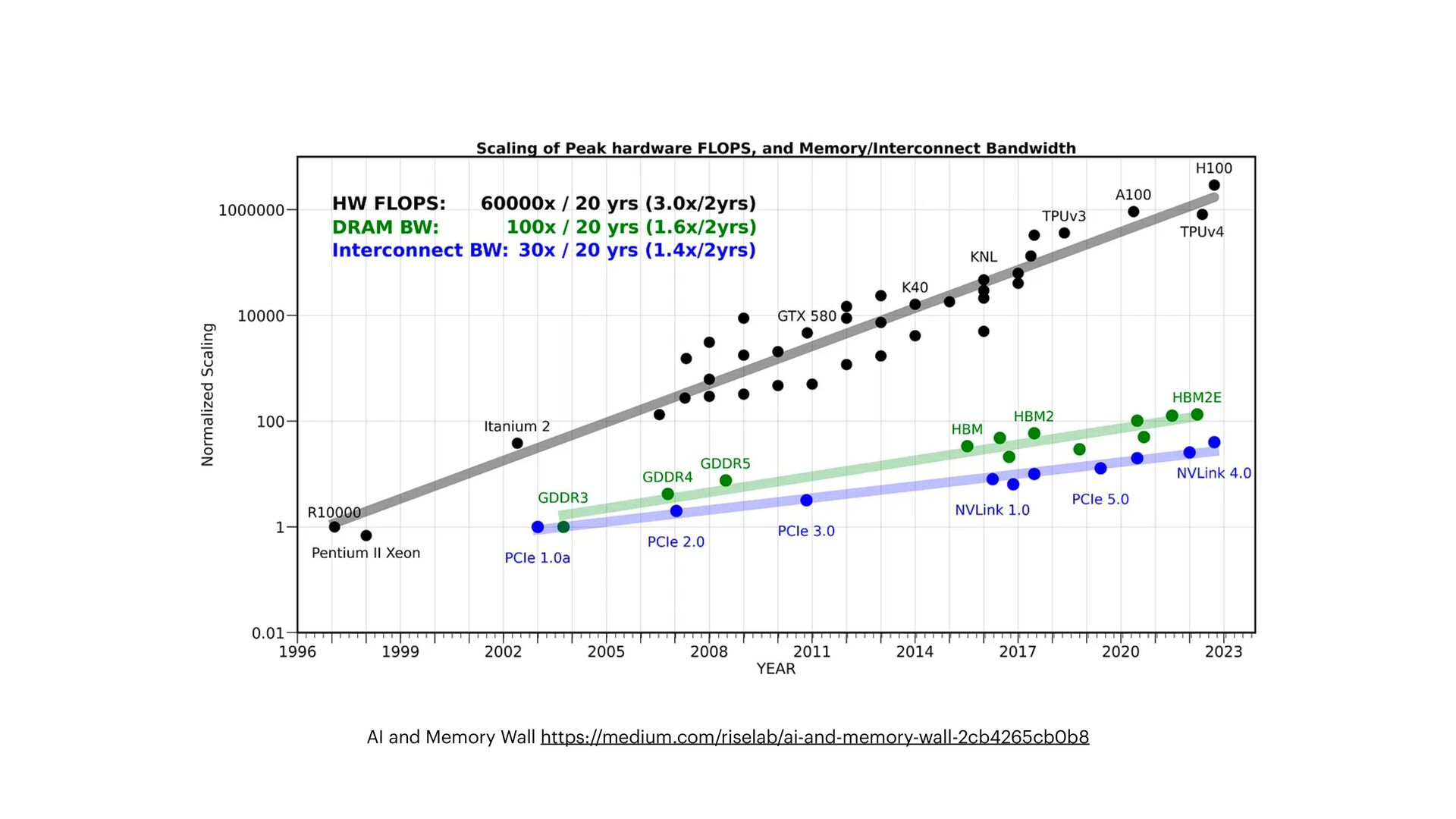
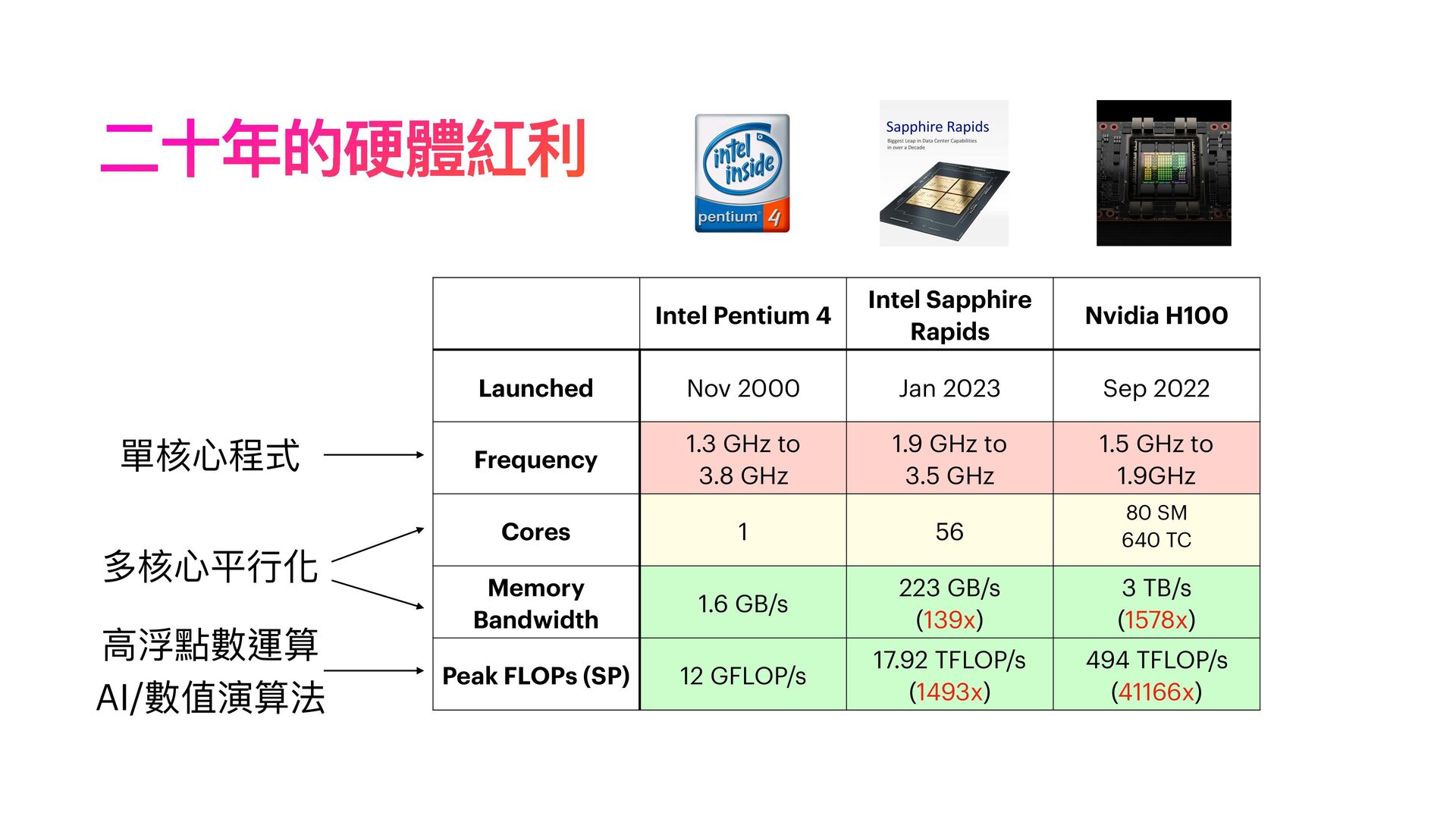
科技界的快速演變令人瞠目結舌。過去十年,我們見證從手機應用、巨量資料 (Big Data),和Web 2.0 開發框架的變遷,如 Ruby on Rails 及其衍生產品。技術從 Hadoop 到 Spark 的轉變,雲端容器技術和 AI 處理框架 (如Tensorflow 和 PyTorch) 的興起,都顯示了這一變化。昔日的 OpenCV、libsvm, word2vec, LSTM 和 GAN 等技術,如今已由 LLM / StableDiffusion 等技術所替代。
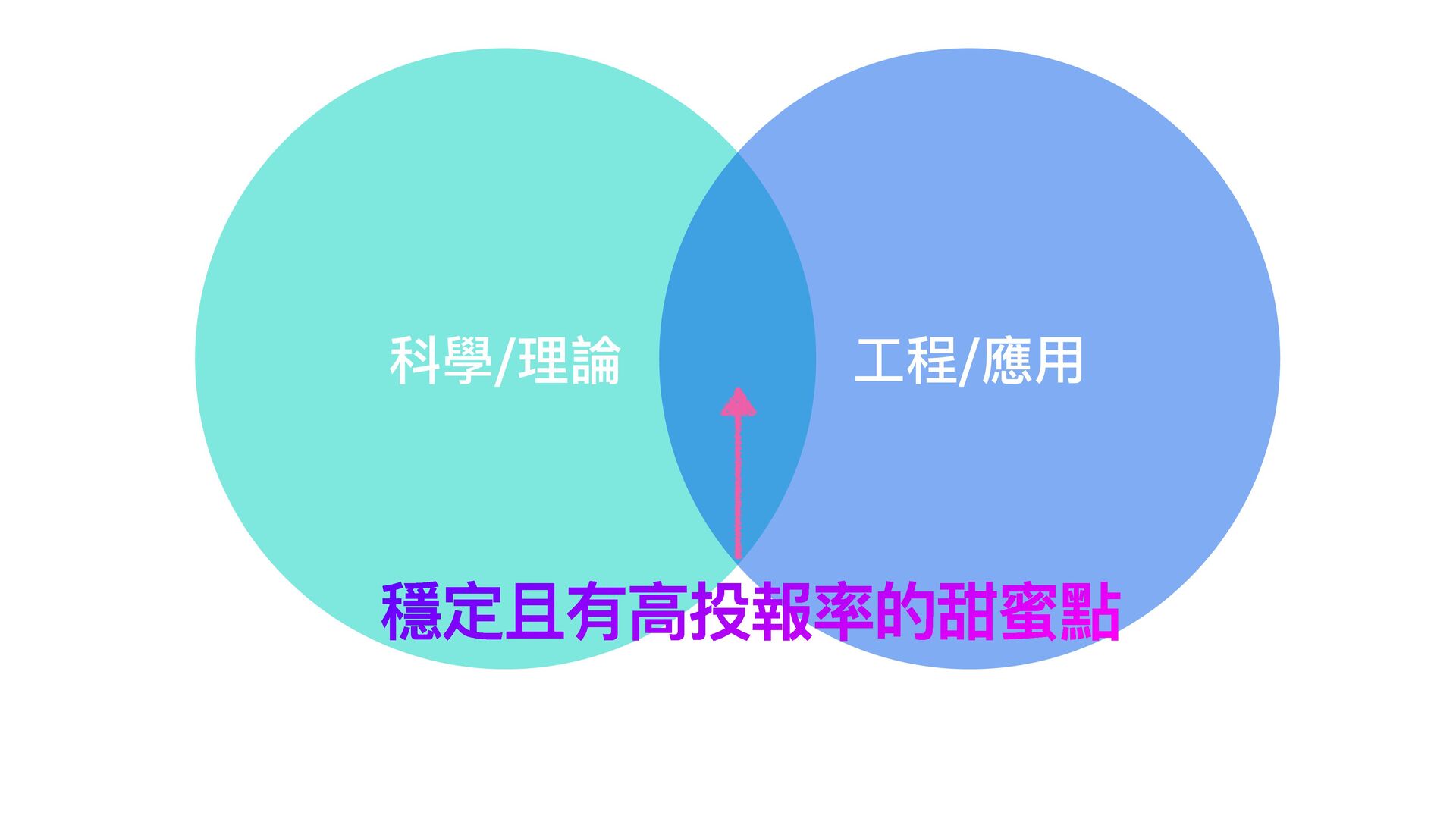
本演講由 Google AI 團隊的底層技術開發者主講,探討如何在技術迅速迭代的時代中,建立並保持關鍵技能。我們將深入分析現代演算法,探討如何與最新硬體技術同步,並兼顧理論與應用,以最大化 AI 時代的硬體利益。除了介紹核心概念,講者還將透過實例展示新世代軟體開發的機遇與挑戰。
主講人簡介
Felix Chern 是 Google Research 的資深工程師,專注於開發 Google Tensor Processing Unit (TPU) 編譯器和設計創新演算法。擁有台大機械工程學士學位的他,自學電腦科學,專精於底層技術。在Google Research這個充滿頂尖電腦科學碩博士的環境中,Felix 憑藉對演算法和現代計算硬體架構的深入了解,成為該領域的佼佼者。他不僅在 Google 對人工智慧技術的尖端發展做出亮眼的研究貢獻,也熱衷於閒暇時間分享資訊技術的最新動態,並熱心協助志同道合的朋友深入電腦科學領域。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}