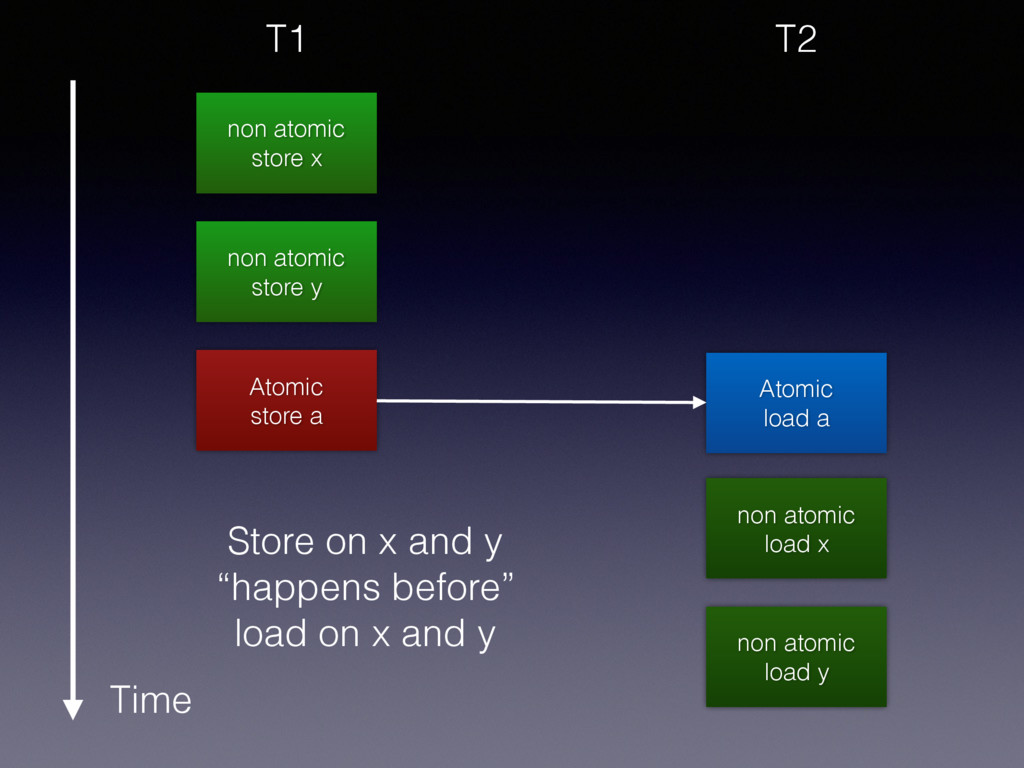
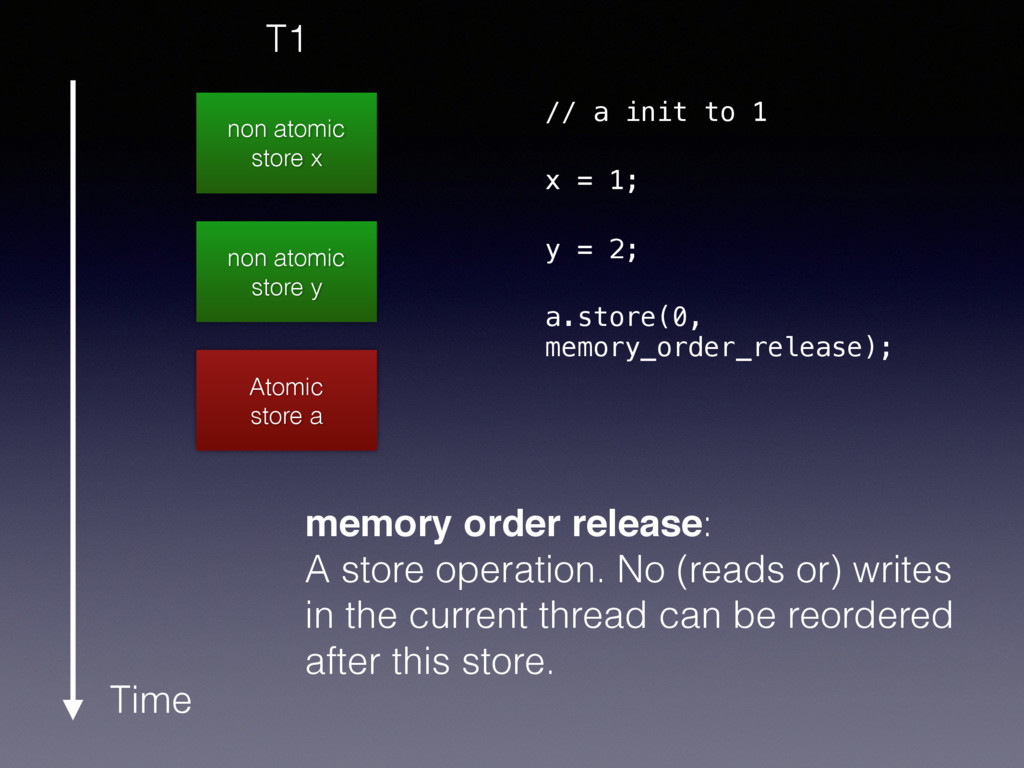
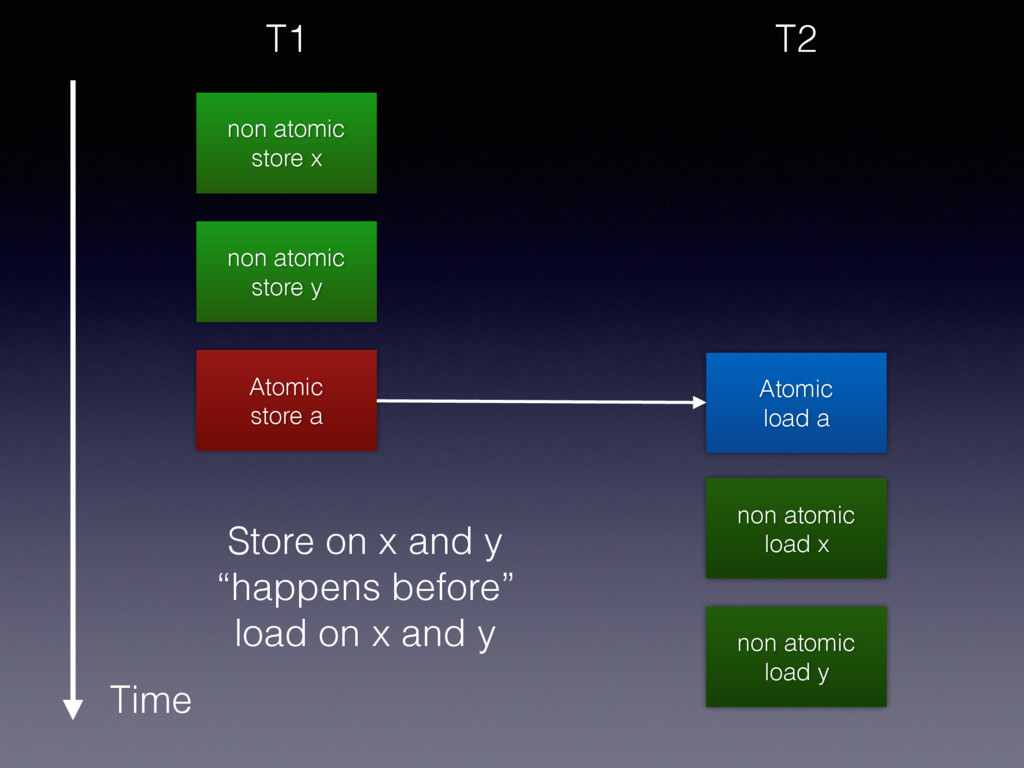
a Time T1 memory order release: A store operation. No (reads or) writes in the current thread can be reordered after this store. // a init to 1 x = 1; y = 2; a.store(0, memory_order_release);
y Time T2 while (a.load (memory_order_acquire)) { /* spin lock */ } // read x, y memory order acquire: A load operation. No reads (or writes) in the current thread can be reordered before this load.
constraints, only atomicity is required of this operation • memory_order_acquire: A load operation. No reads (or writes) in the current thread can be reordered before this load. • memory_order_release: A store operation. No (reads or) writes in the current thread can be reordered after this store. • memory_order_acq_rel: A read-modify-write operation. This is both acquire and release. • memory_order_seq_cst: Any operation with this memory order is both an acquire operation and a release operation, plus a single total order exists in which all threads observe all modifications in the same order
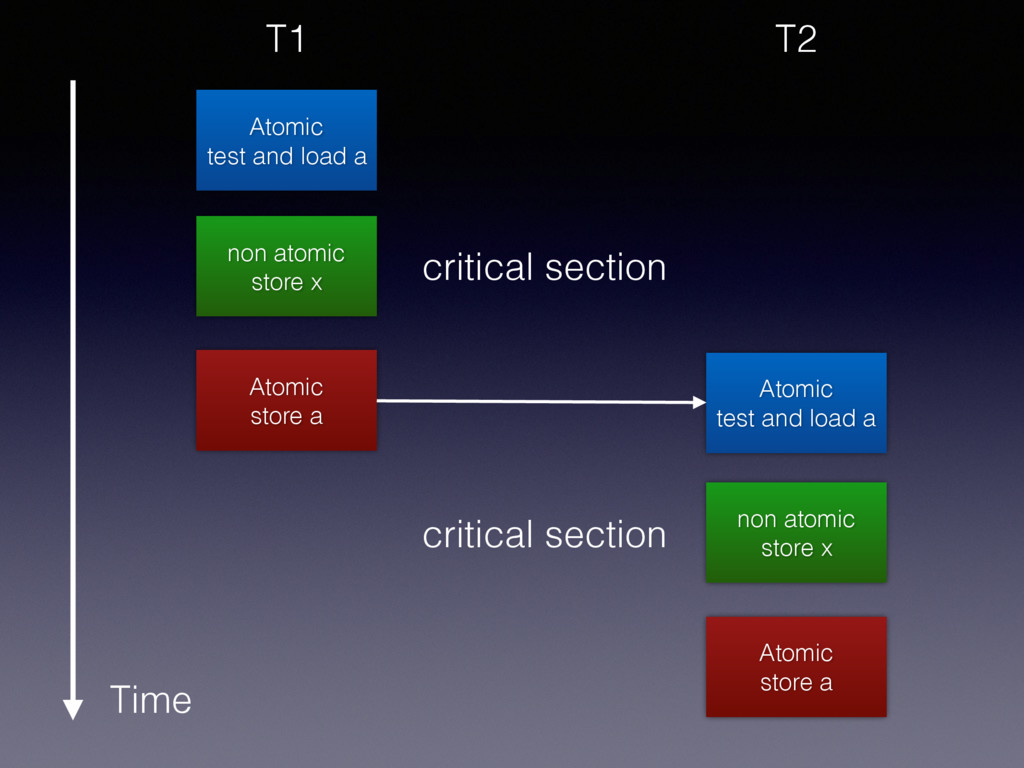
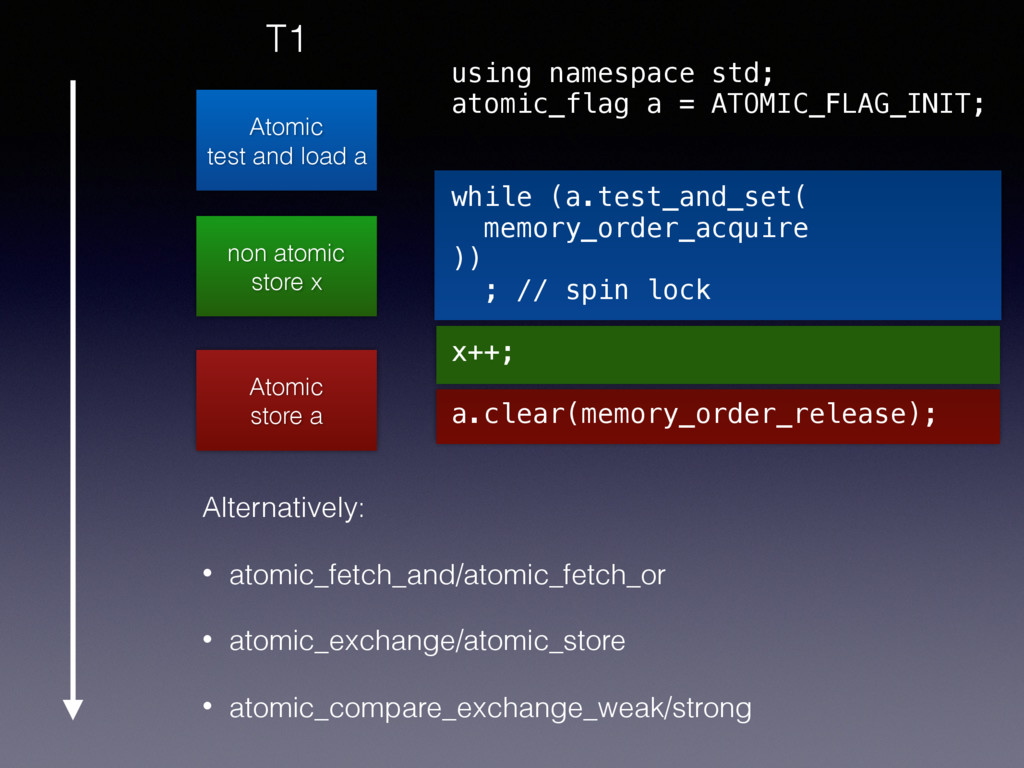
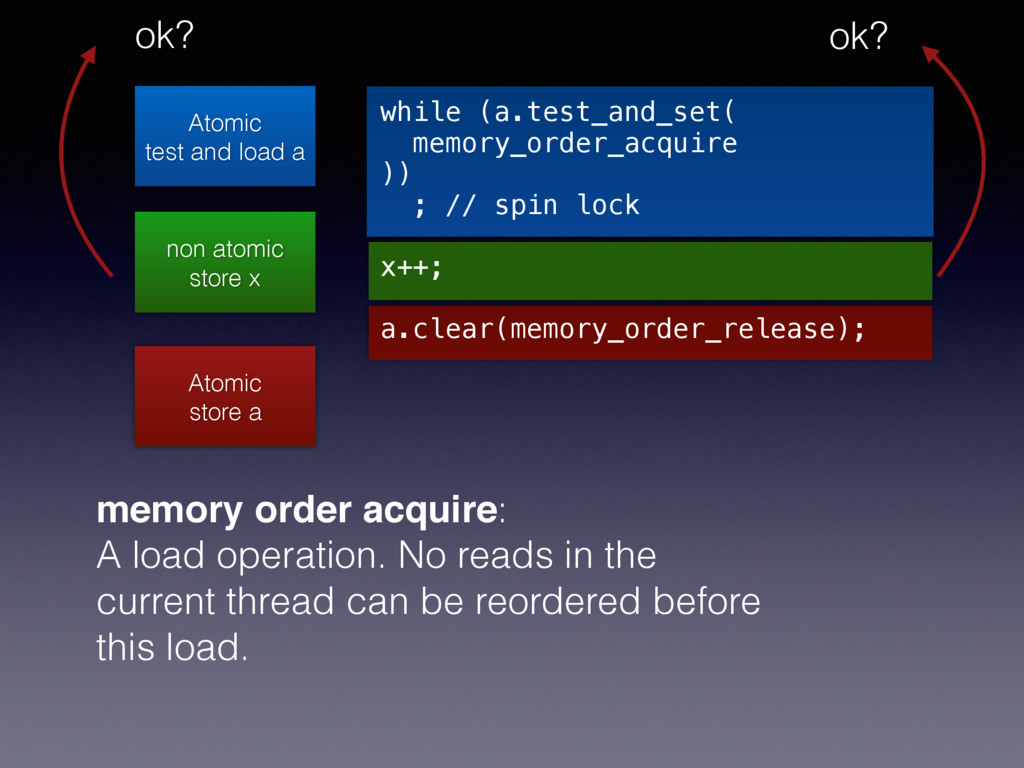
and load a while (a.test_and_set( memory_order_acquire )) ; // spin lock x++; a.clear(memory_order_release); memory order acquire: A load operation. No reads in the current thread can be reordered before this load. ok?
and load a while (a.test_and_set( memory_order_acquire )) ; // spin lock x++; a.clear(memory_order_release); memory order acquire: A load operation. No reads or writes in the current thread can be reordered before this load. ok? Added in Oct, 2016
is a memory address, then the operation has an implicit LOCK prefix, that is, the exchange operation is atomic. • LOCK Causes the processor's LOCK# signal to be asserted during execution of the accompanying instruction. In a multiprocessor environment, the LOCK# signal insures that the processor has exclusive use of any shared memory while the signal is asserted.
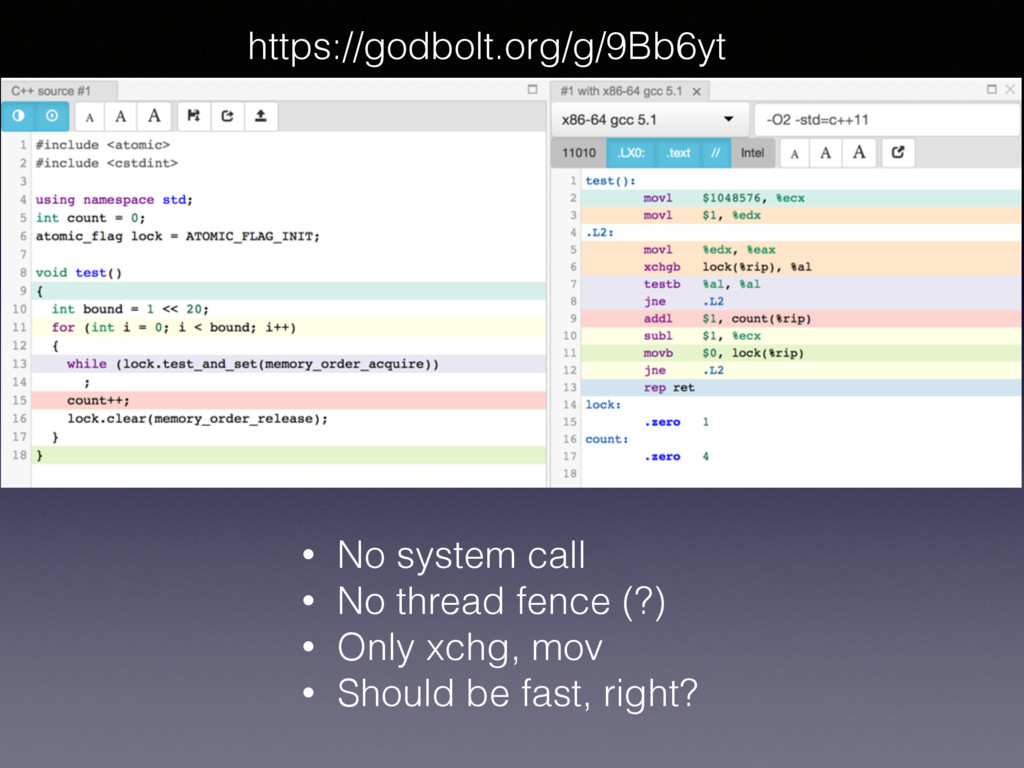
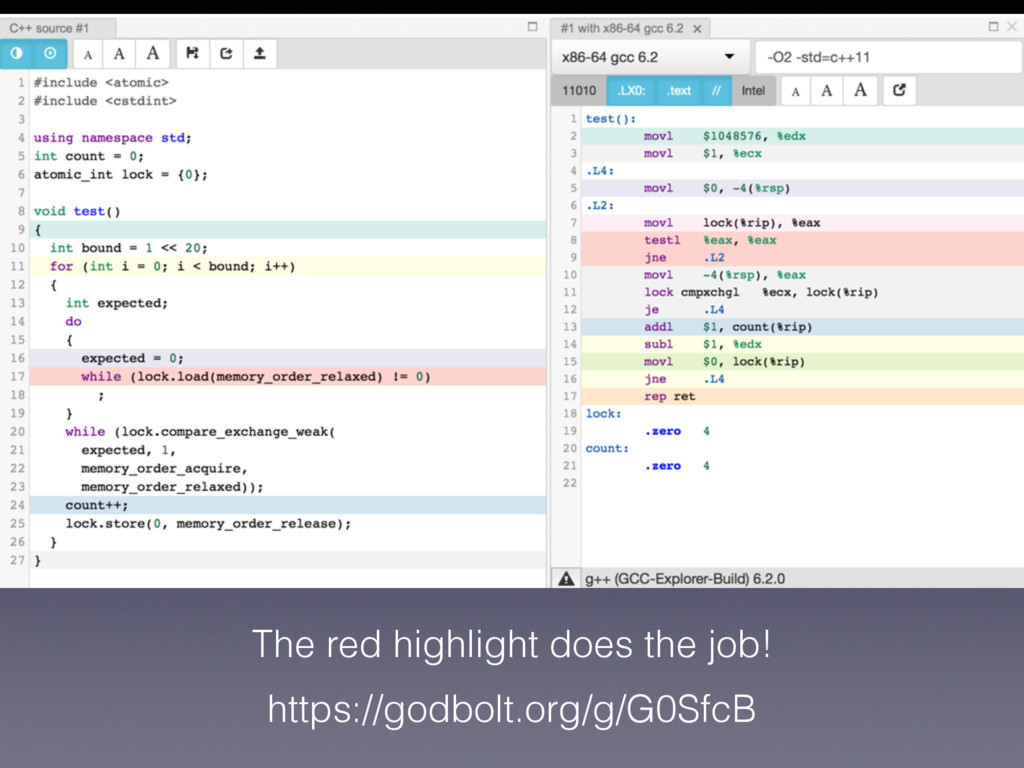
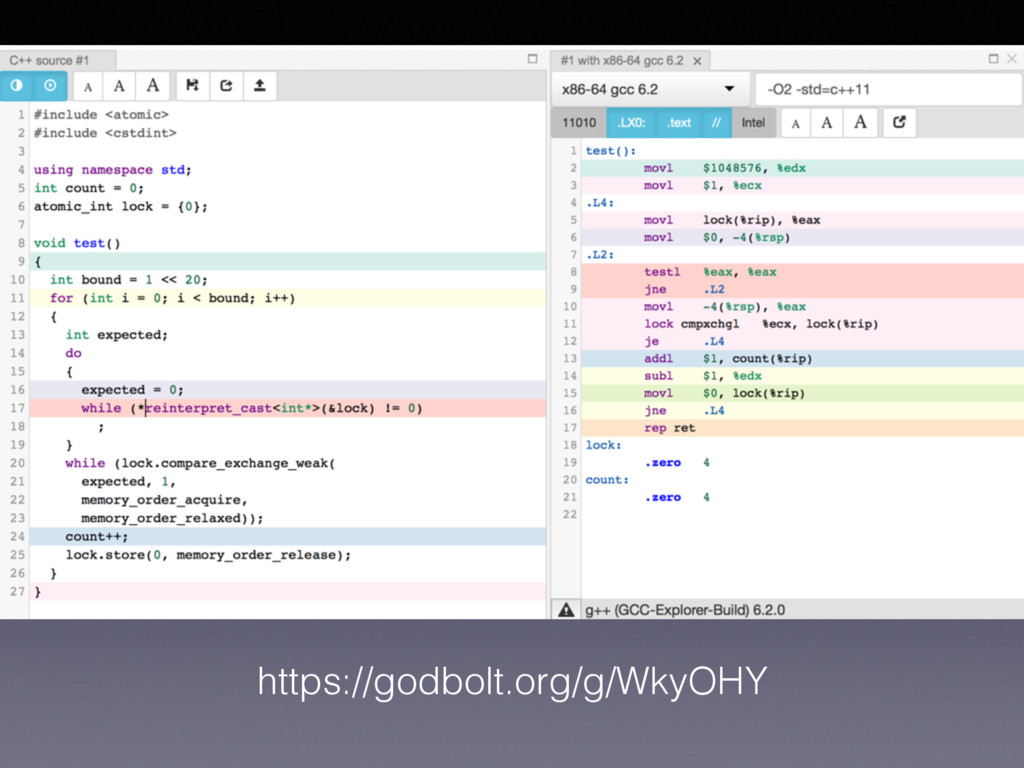
same as lock.load(memory_order_relaxed) • memory order relaxed, acquire, acq_rel, seq_cst doesn’t matter here • But only on X86! • Unless you compile and test, you know nothing!
lock, the state is not safe • Two threads increasing the size (ok) • One thread increasing the size, the other does the opposite (bad) • One thread free the resource, the other inserting object (crash!)
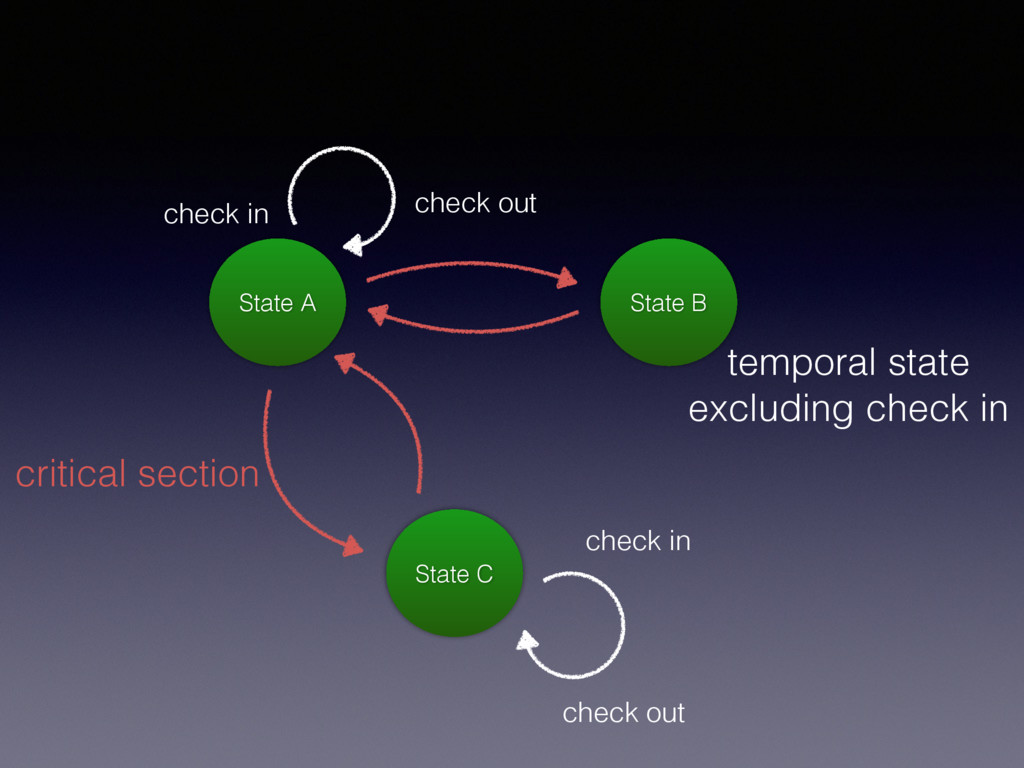
check_out (like release read lock) • book_critical exclude new check in if already booked, failed to book • enter_critical wait until all check_in checked out then enter • exit_critical
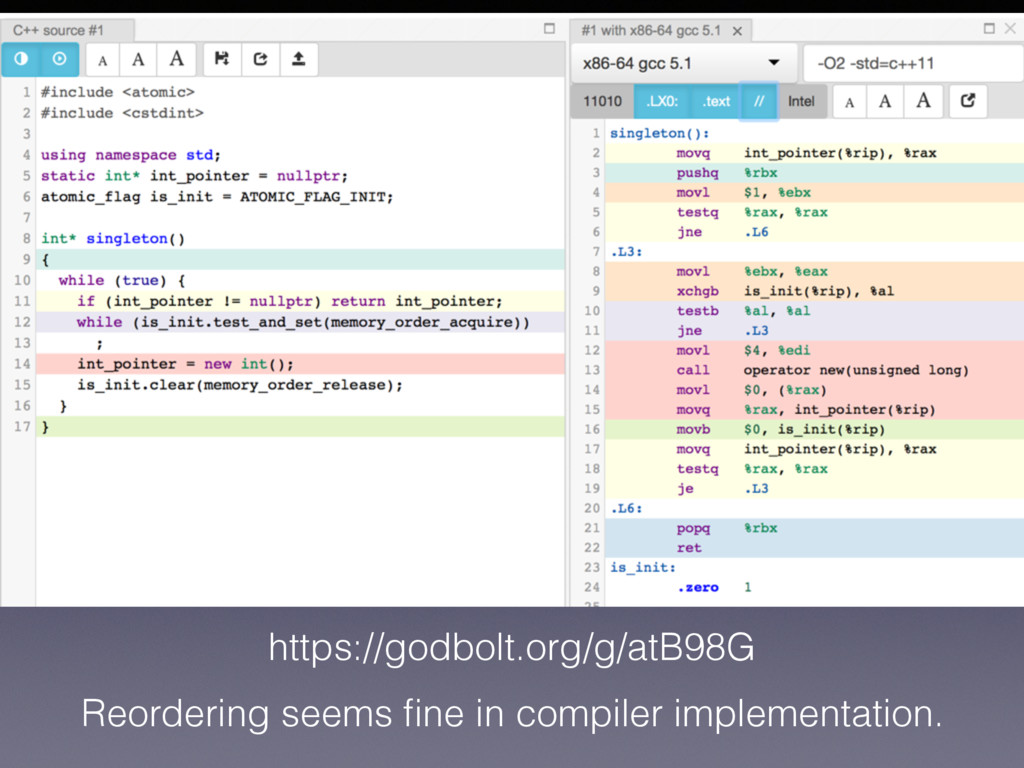
blog posts on atomic • The Art of Multiprocessor Programming • C++ Concurrency In Action • GCC Transactional Memory • GCC X86 hard ware transaction reference • X86 references: http://x86.renejeschke.de • Compile code online: http://gcc.godbolt.org • https://github.com/dryman/atomic_patterns
structures to big data • O(1) deserialization (mmap) • Target for high throughput (big data), but also low latency applications (this is why I entered atomic programming) • Version 3 is still under development (branch OPIC-33)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}