Experience • MapReduce and Hive • Started hadoop using 8 nodes cluster • Later joined OpenX to manage and develop on 600+ nodes cluster • 100+TB/day data volume • http://idryman.org
an aggregation (or any other data operations) • Cardinality • Frequency distribution (is data skewed?) • Top-k elements • Don’t need to be precise, but be fast and stable
of a given query • Naive approach 1: Put into a hash set! • not enough memory! • Approach 2: Hash the input to a BitSet (allow collisions) • Linear counting [ACM’90] • Estimate collision impacts • Still require 1/10 size of the input (too large!)
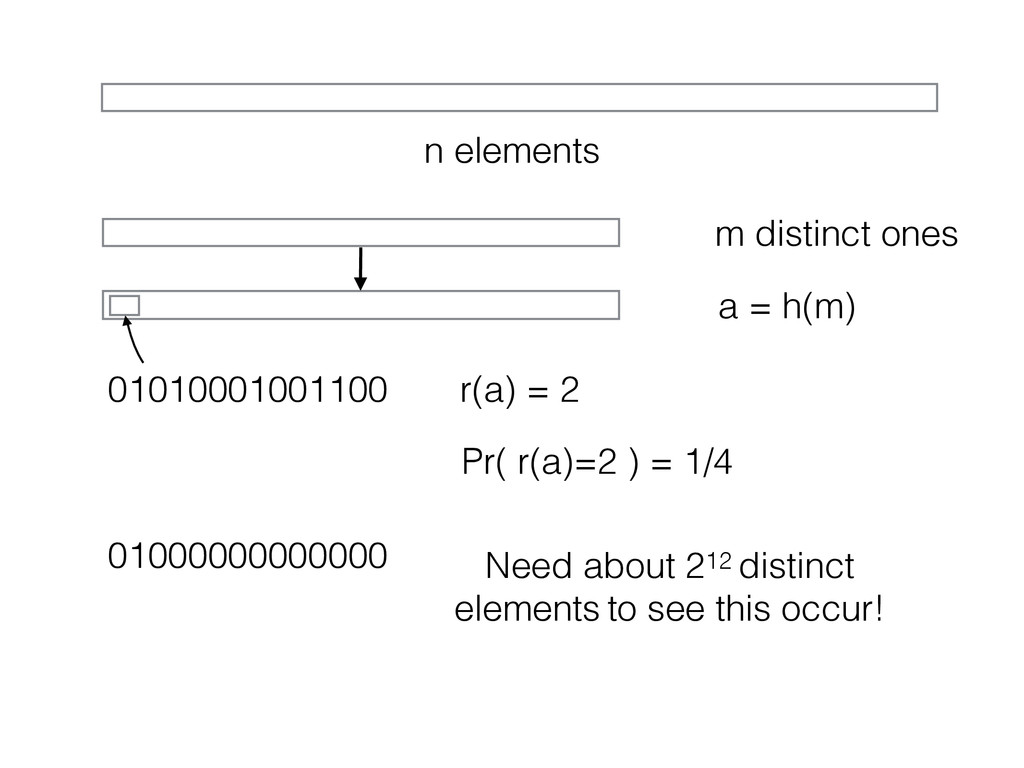
maps each of the n elements to at least log(n) bits • For each a = h(x), let r(a) be the number of trailing zeros • Record R = maximum r(a) seen • Cardinality estimate = 2R • Data size (R): 4 bytes or 8 byes
src GROUP BY col1, col2; SELECT hll(col1, col2).cardinality from src; ! -- create hyperloglog cache per hour FROM input_table src INSERT OVERWRITE TABLE hll_cache PARTITION (d='2015-03-01',h='00') SELECT hll(col1,col2) WHERE d='2015-03-01' AND h='00' INSERT OVERWRITE TABLE hll_cache PARTITION (d='2015-03-01',h='01') SELECT hll(col1,col2) WHERE d='2015-03-01' AND h='01' ! -- read the cache and calculate the cardinality of full day SELECT hll(hll_col).cardinality from hll_cache WHERE d='2015-03-01;' ! -- unpack hive hll struct and make it readable by postgres-hll, js-hll developed by Aggregate Knowledge, Inc. SELECT hll_col.signature from hll_cache WHERE d='2015-03-01'; https://github.com/dryman/hive-probabilistic-utils
Agent, etc.) every hour/minute. • How many unique users do we have every day/ week/month? • What is the churn rate? • It can even be visualized in browser! (js-hll)
{kind=link}
{kind=link}
{kind=link}
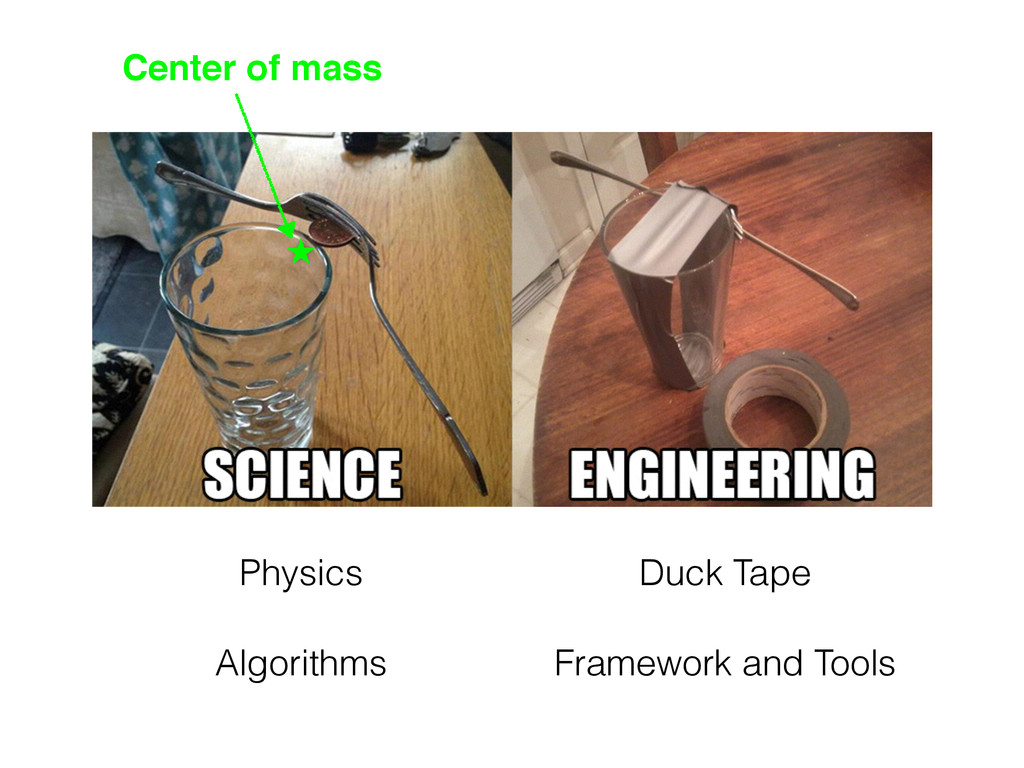{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
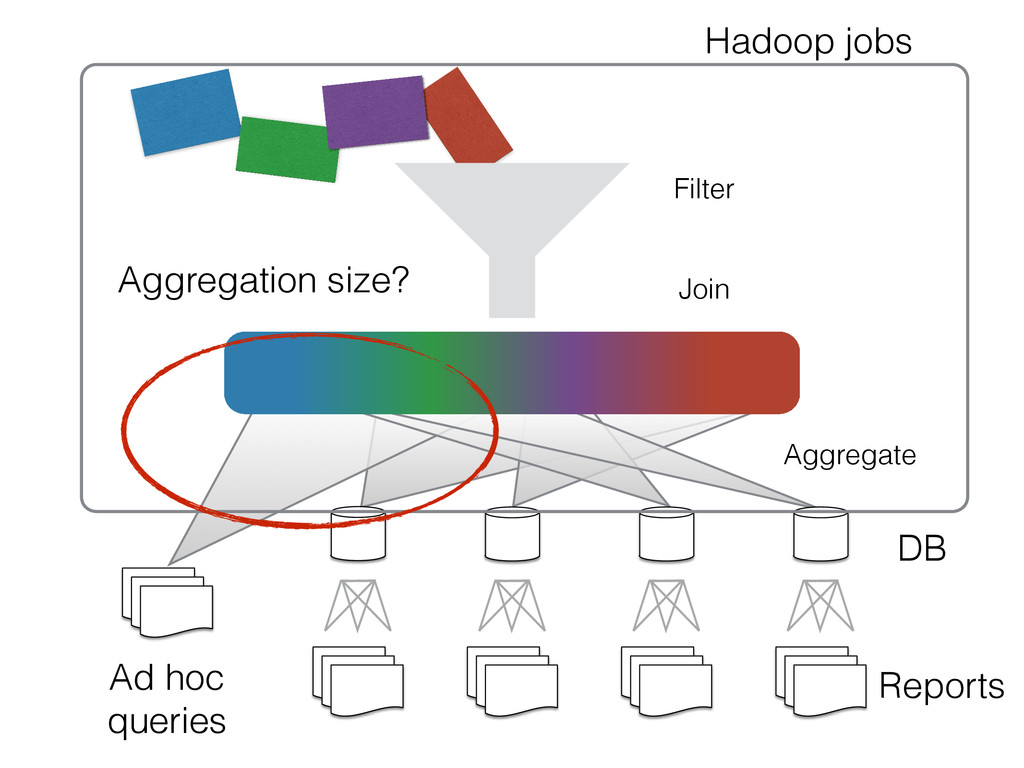{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}