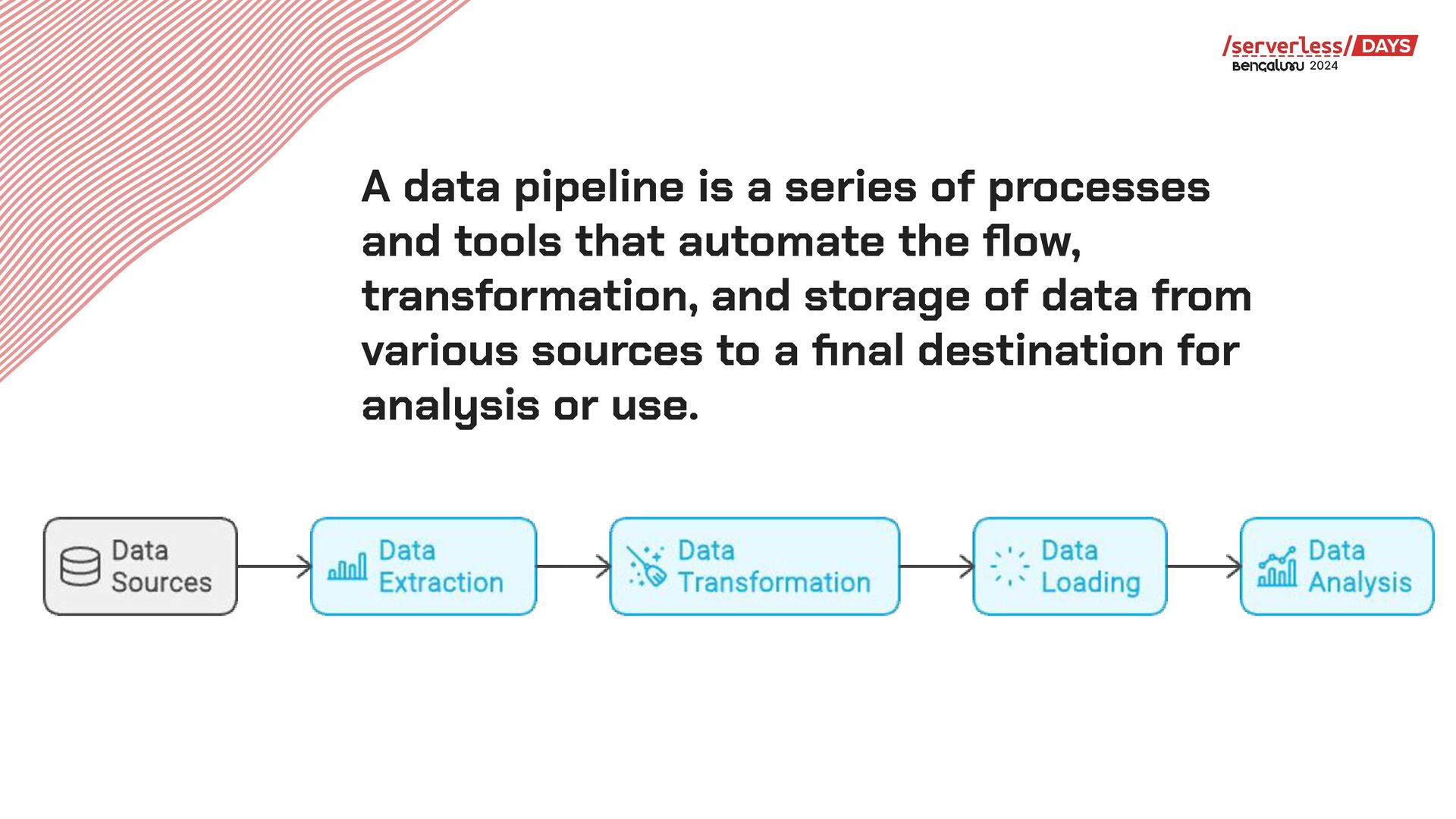
Streaming ETL pipelines ingest and process data as it arrives, minimizing latencies. This is in contrast to traditional batch ETL pipelines which process data in batches, often causing inconsistencies with the source data set. Streaming ETL pipelines feed data to various downstream systems, including real-time analytics, BI, and machine learning as they need cleansed and normalized data for smooth operations.
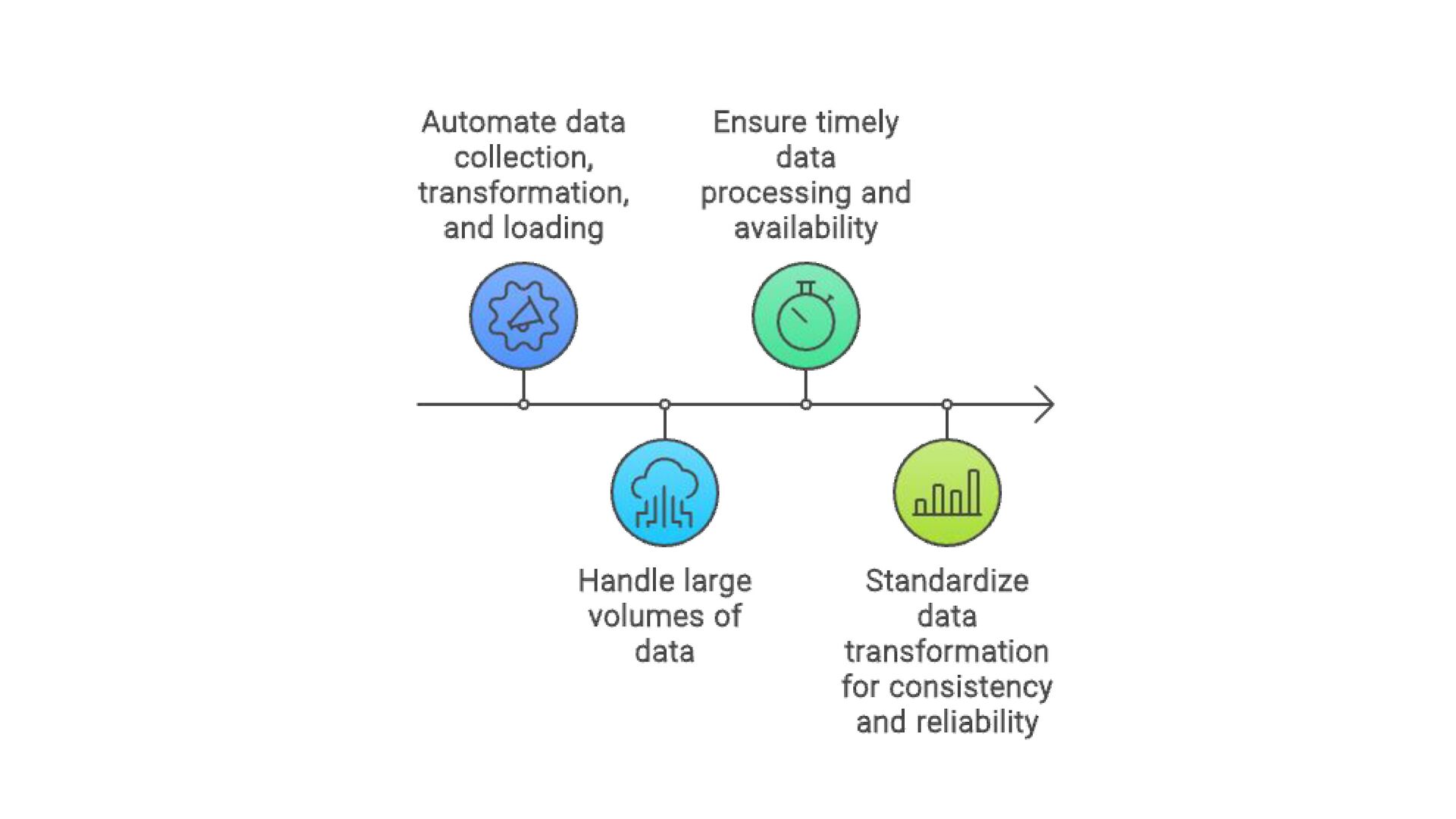
Making streaming ETL pipelines serverless offers several benefits for businesses and technical teams. From a business perspective, serverless streaming ETL can reduce operational costs, improve scalability, and enhance agility. Since there is no need to provision or manage infrastructure, organizations can save on hardware, software, and IT resources.
From a technical standpoint, serverless streaming ETL simplifies the development and deployment process, enabling teams to focus on building business logic rather than managing infrastructure.
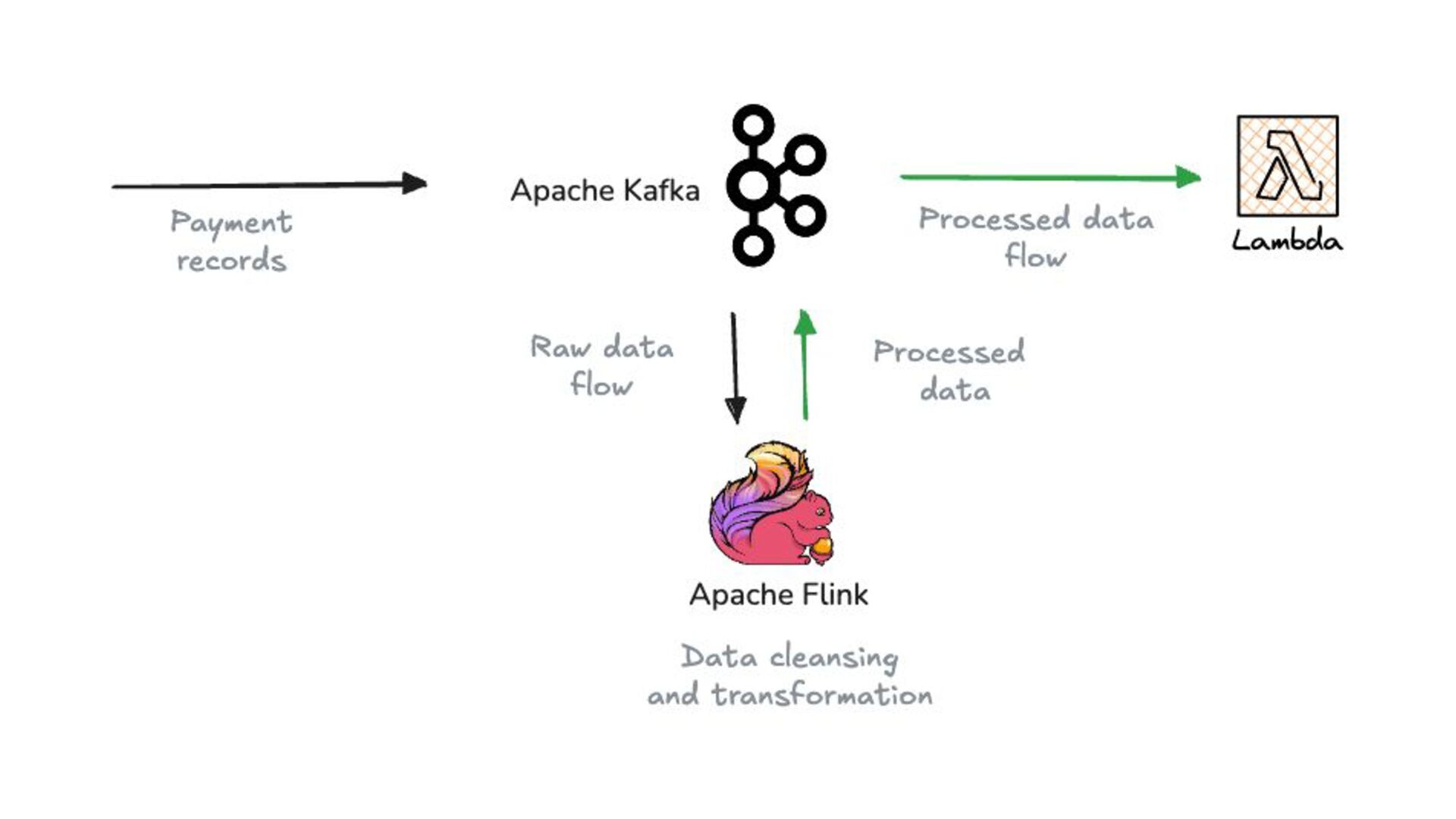
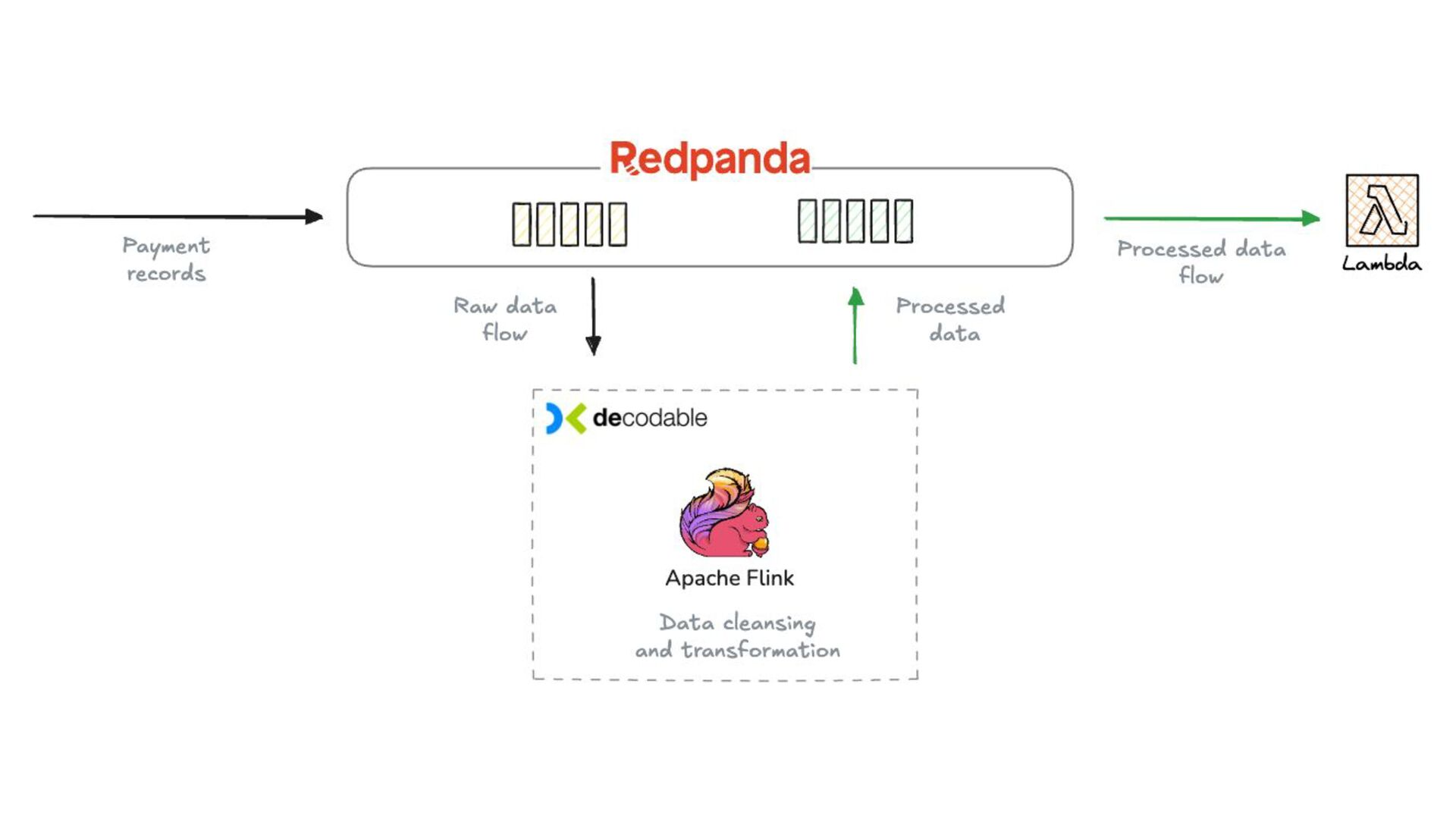
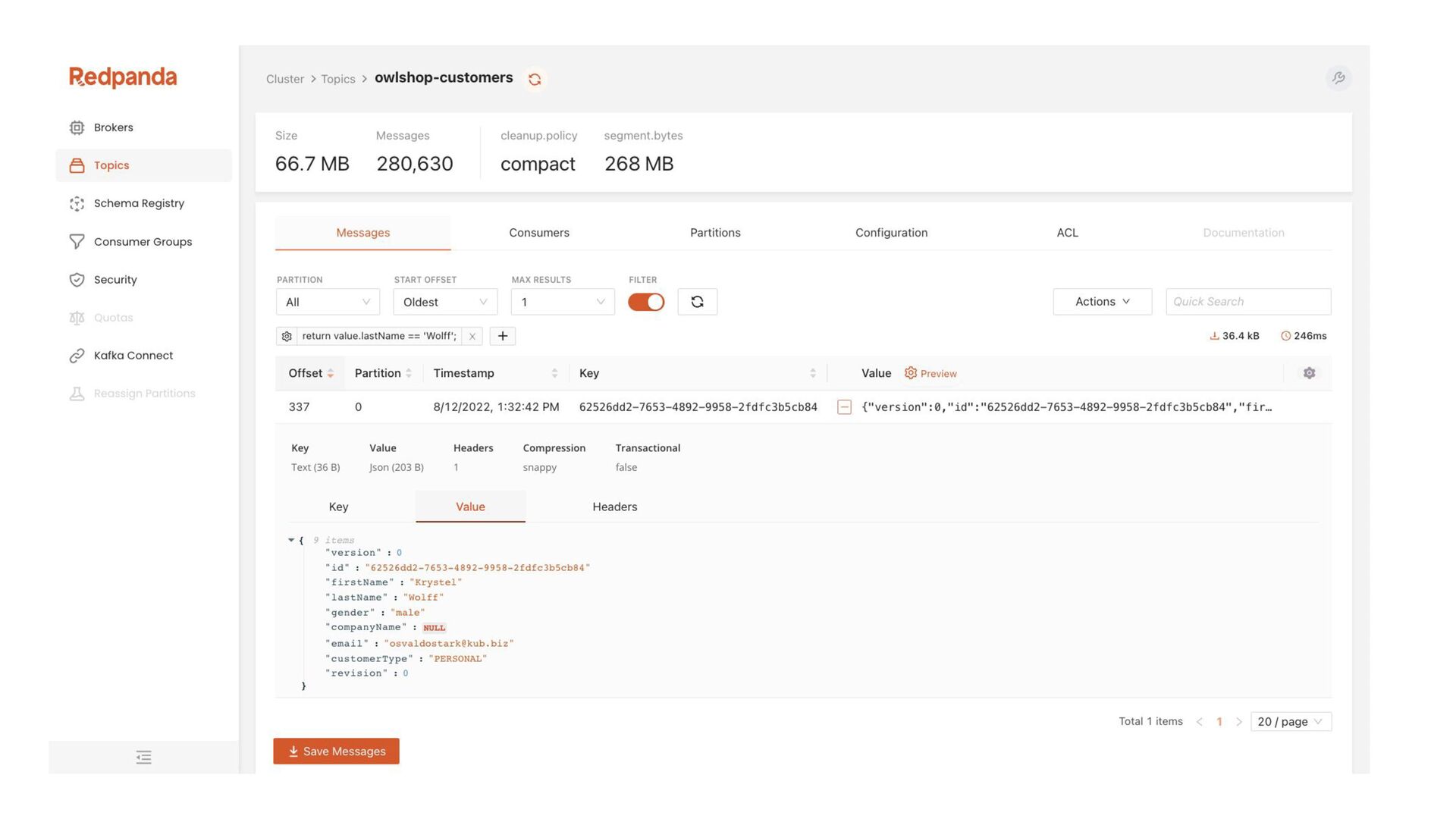
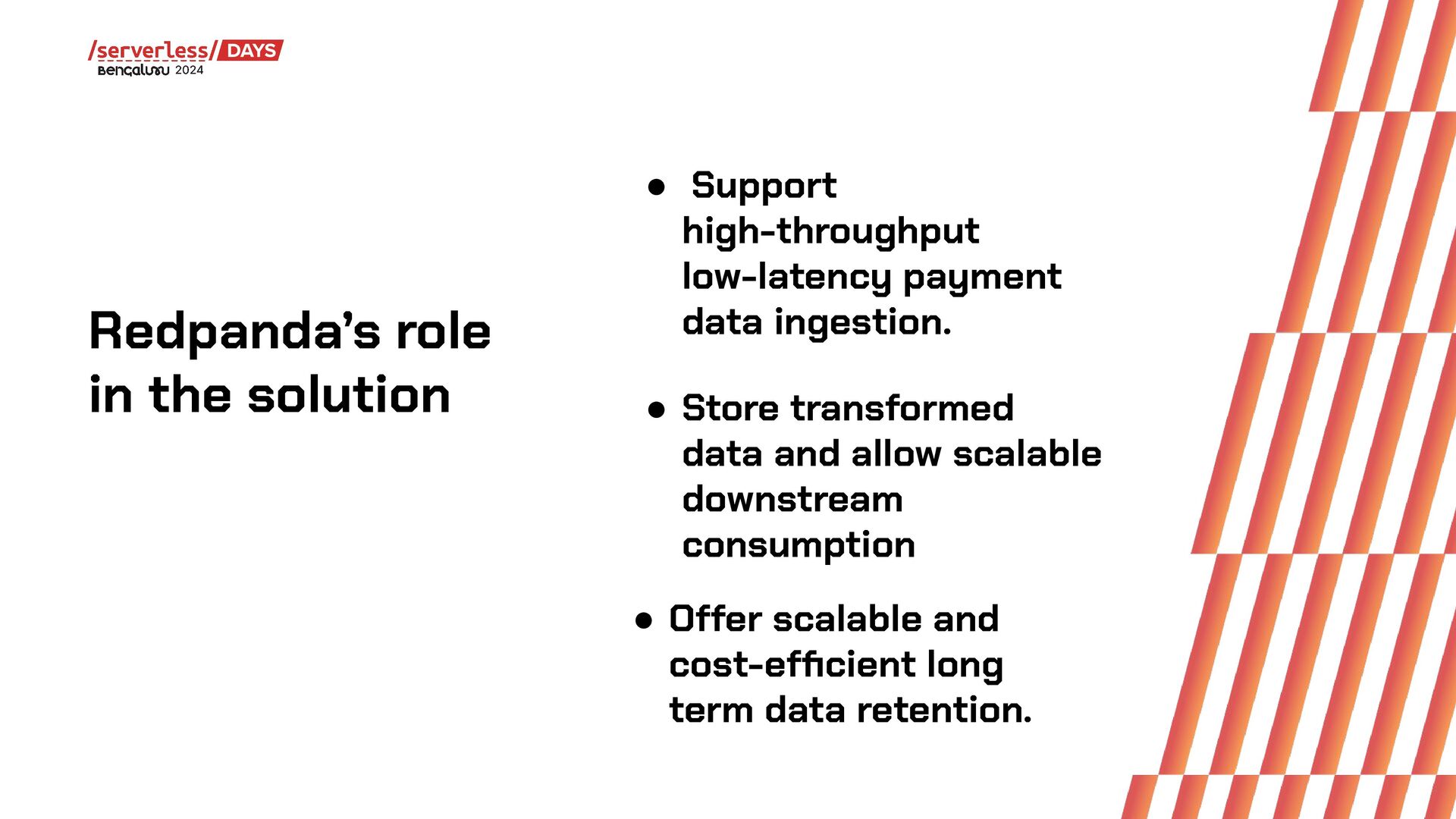
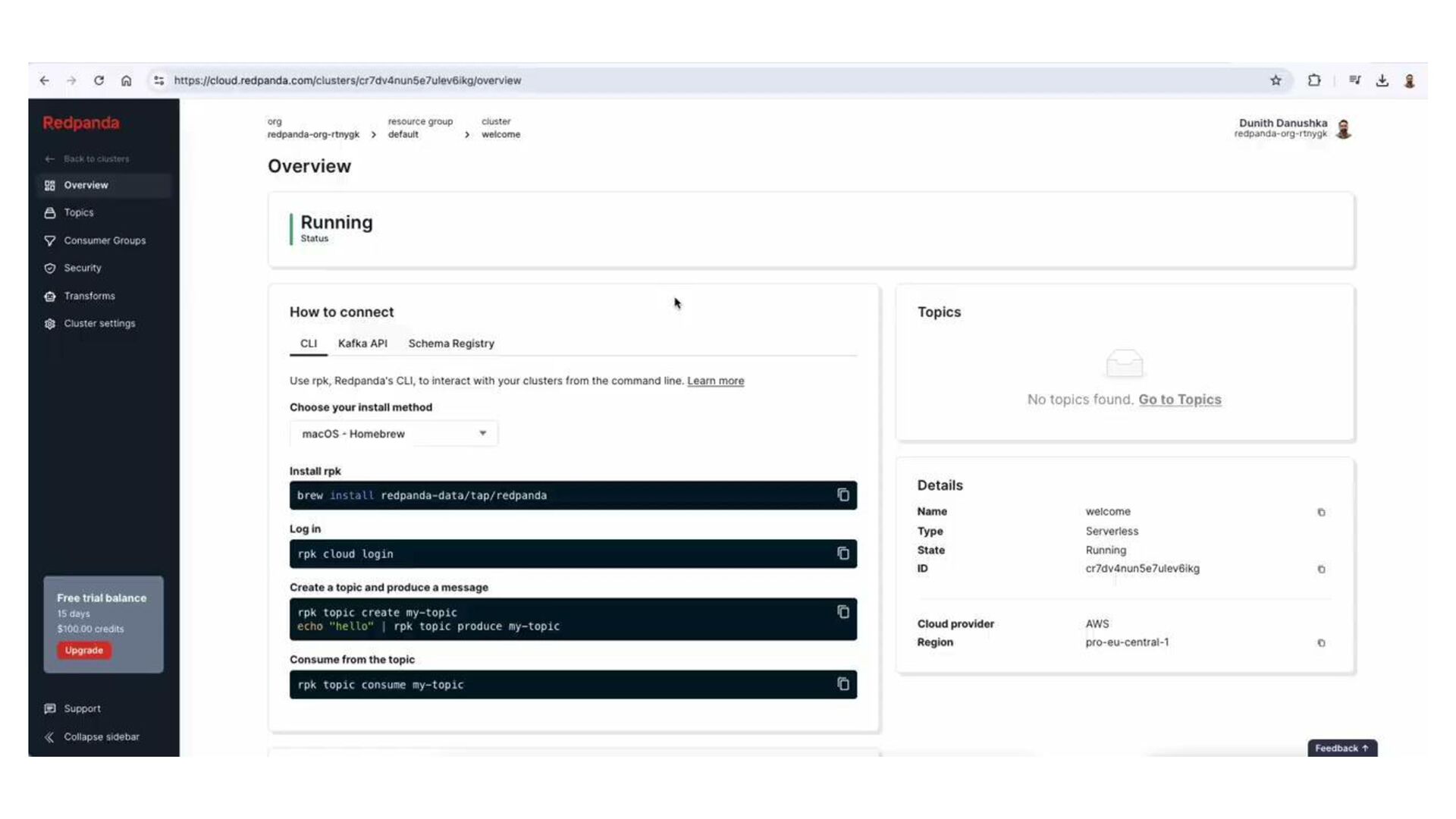
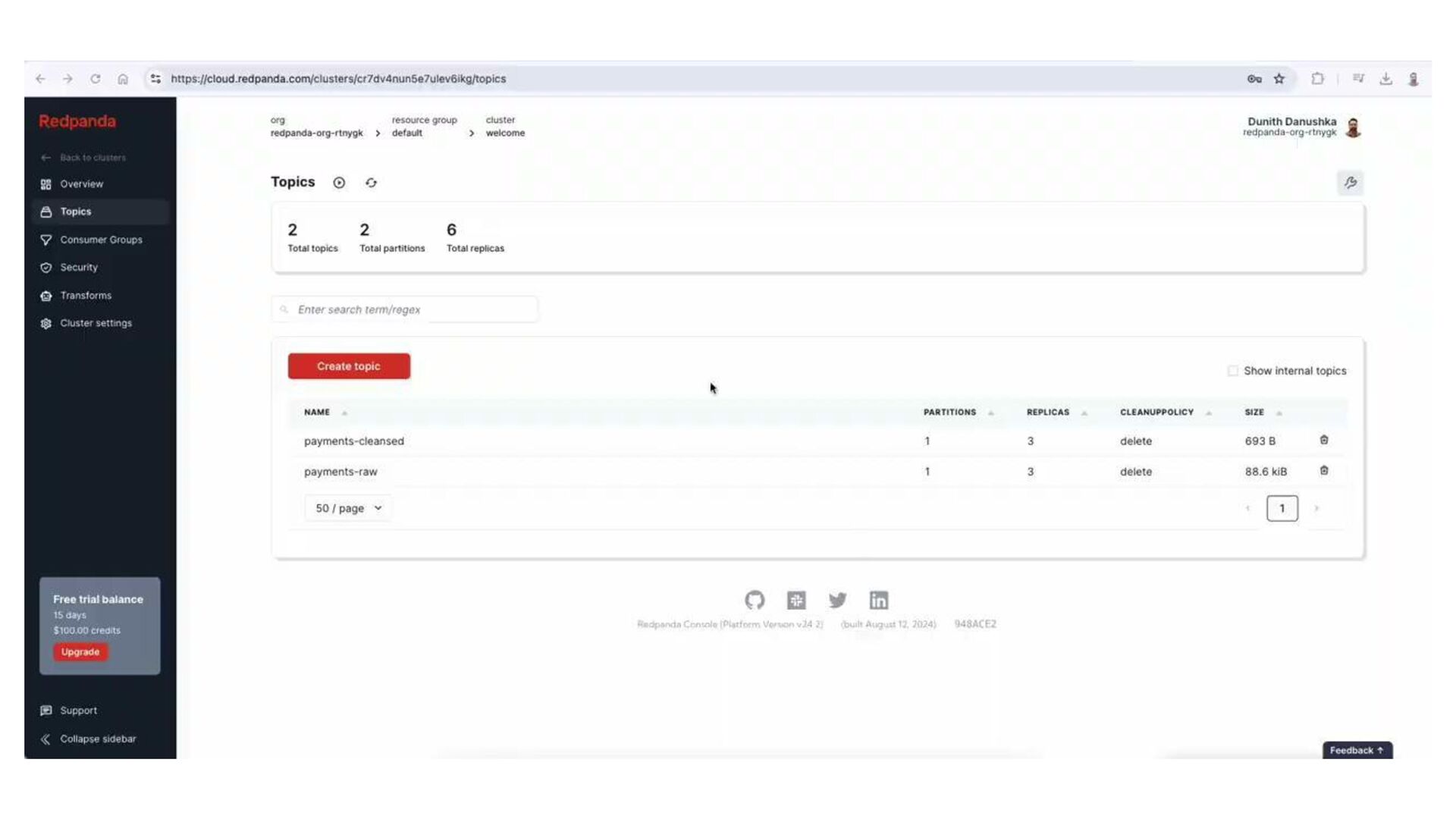
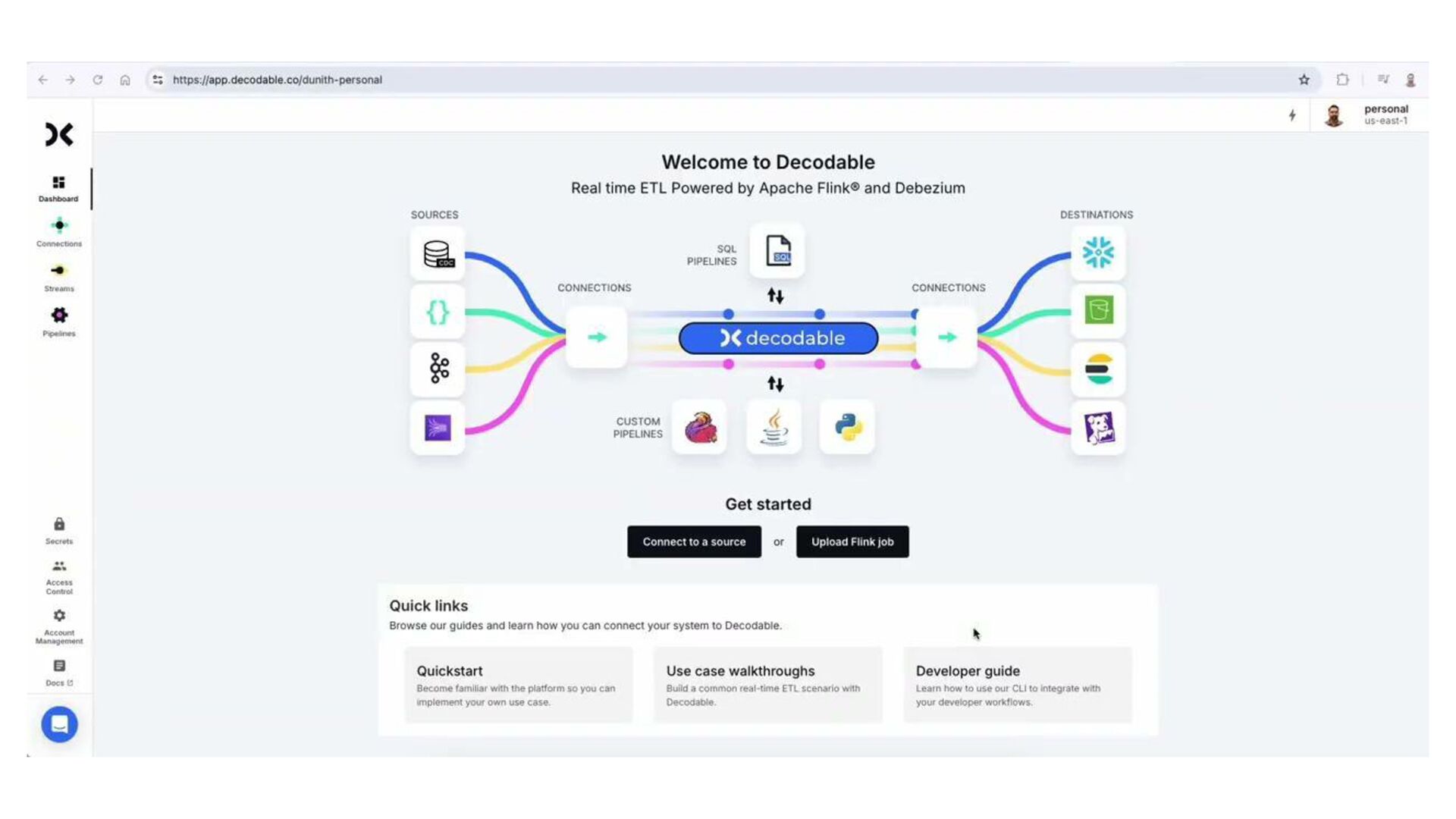
In this talk, we design, build, and run a streaming ETL pipeline using several serverless streaming data technologies. That includes Redpanda, a streaming data platform with Kafka API compatibility, Redpanda Connect as the streaming ETL engine, and Apache Pinot as the serving layer database.
Data professionals including developers, data engineers, and architects would benefit from this talk as they can learn how to piece together different serverless technologies to build a real-time data pipeline. They will also see it in action, scaling up and down to accommodate varying demand spikes, which simulates realistic situations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Contact me at: [email protected] @dunithd linkedin.com/in/dunithd](https://files.speakerdeck.com/presentations/fc3a776ffe2c44a49eed5f6bddd2b92c/slide_34.jpg){kind=link}