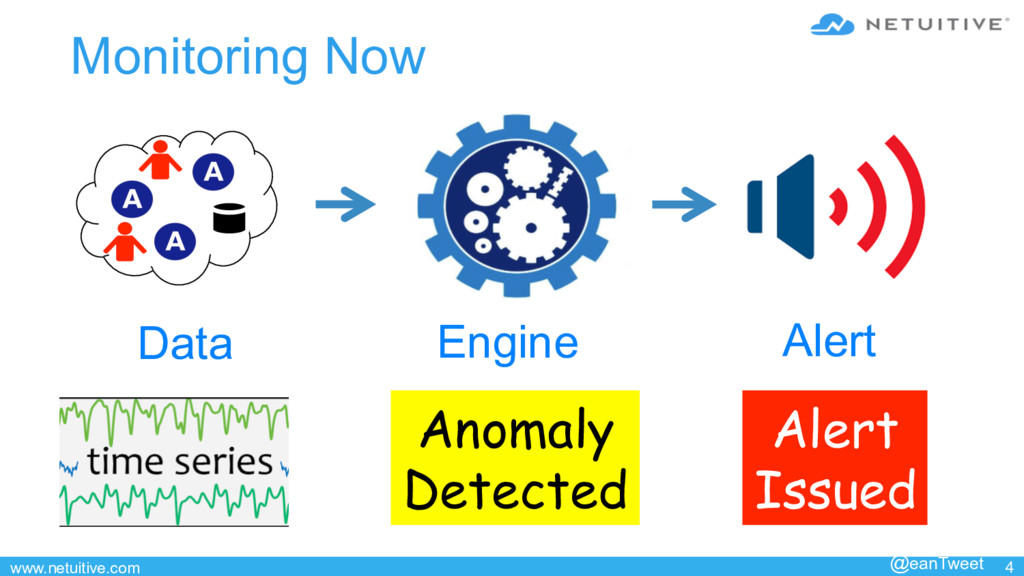
Detecting anomalies is easy. What’s hard is deciding what to do when you find one. A good decision takes a lot more information than what pure anomaly detection can provide.
This talk is about making your analytics accountable and provides practical steps to ensure that anomaly detection is helping, instead of pestering you with noise. Additionally, we cover strategies to ensure that mistakes, which are inevitable, aren’t repeated.
This talk provides a framework, lessons learned, and specific techniques for driving constant improvement in your monitoring’s decisions about what to do and when.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
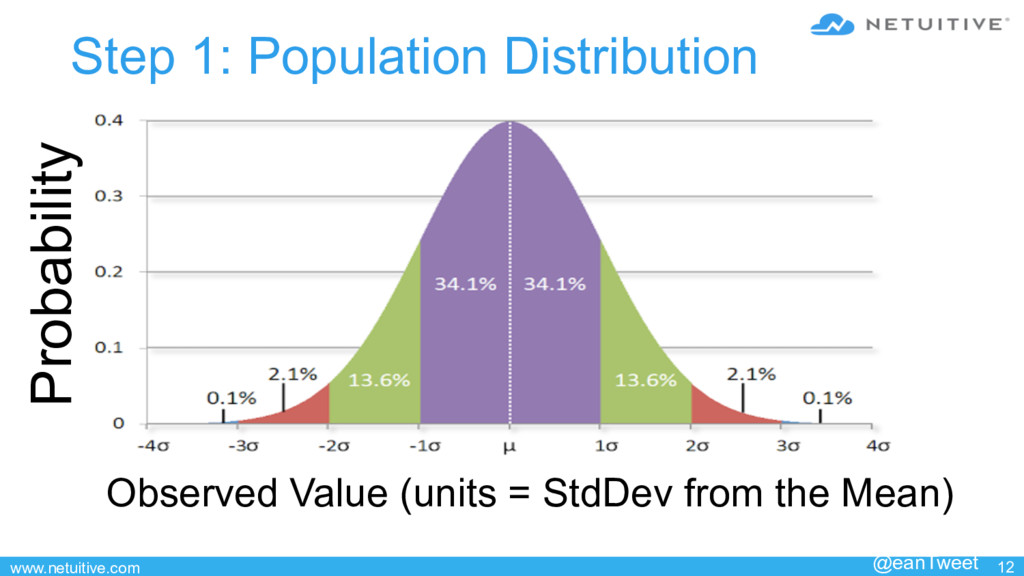
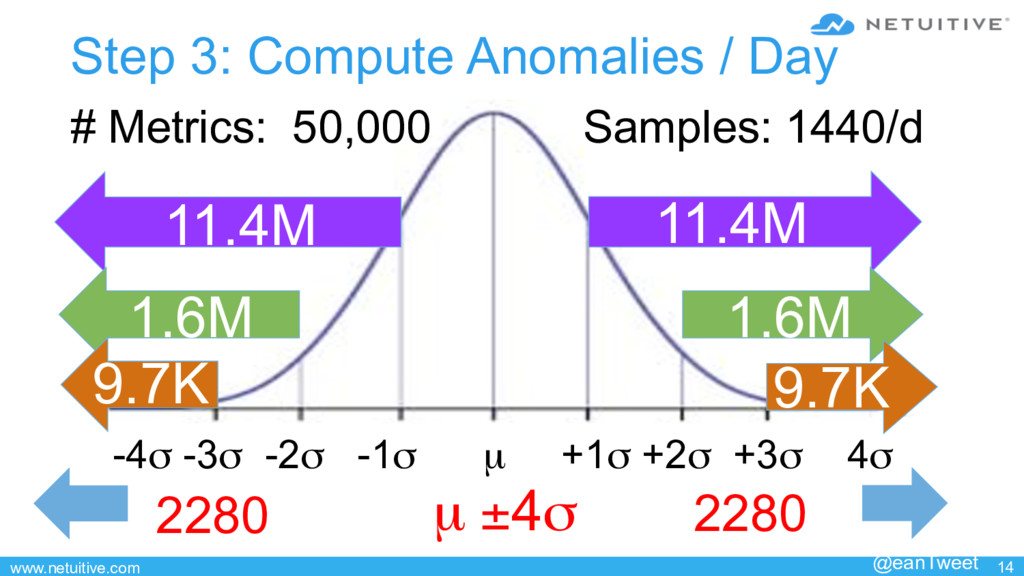
![www.netuitive.com 15 #anomalies∈ (−∞,−4σ ]= 2×50,000×1440× P(X ≤ −4) where](https://files.speakerdeck.com/presentations/ba25108f3cc0450485a5fe9adda361e9/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
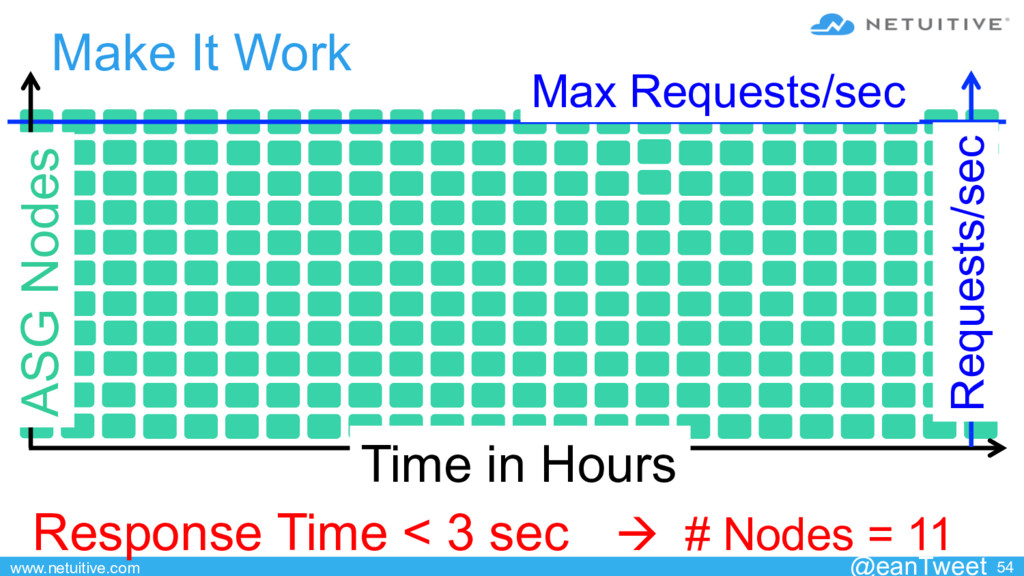{kind=link}
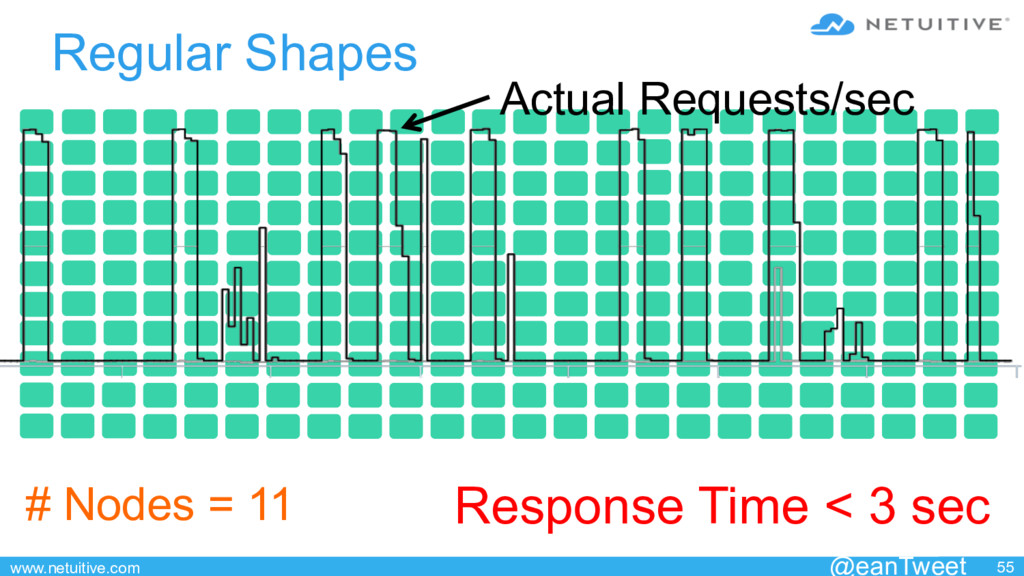{kind=link}
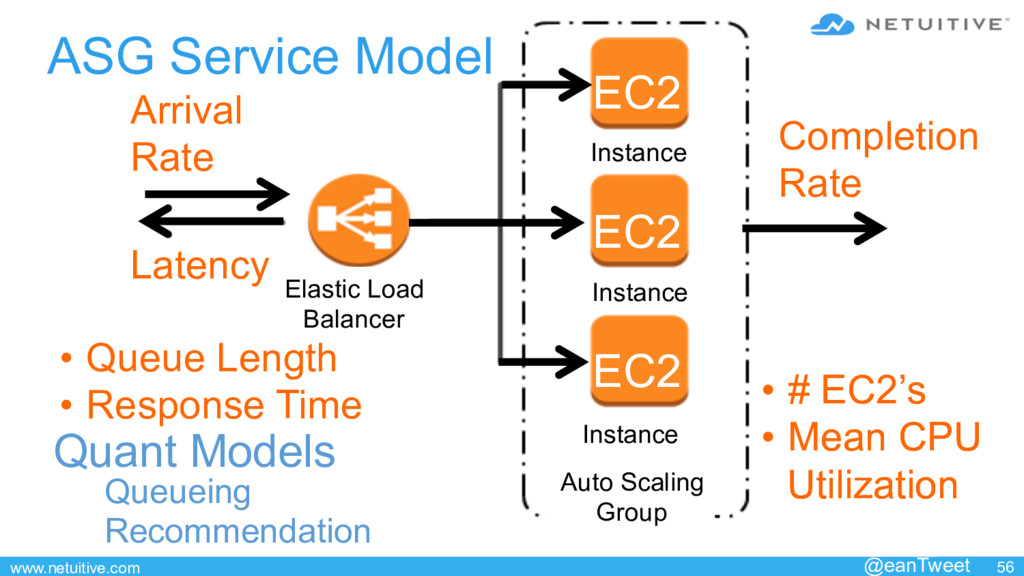{kind=link}
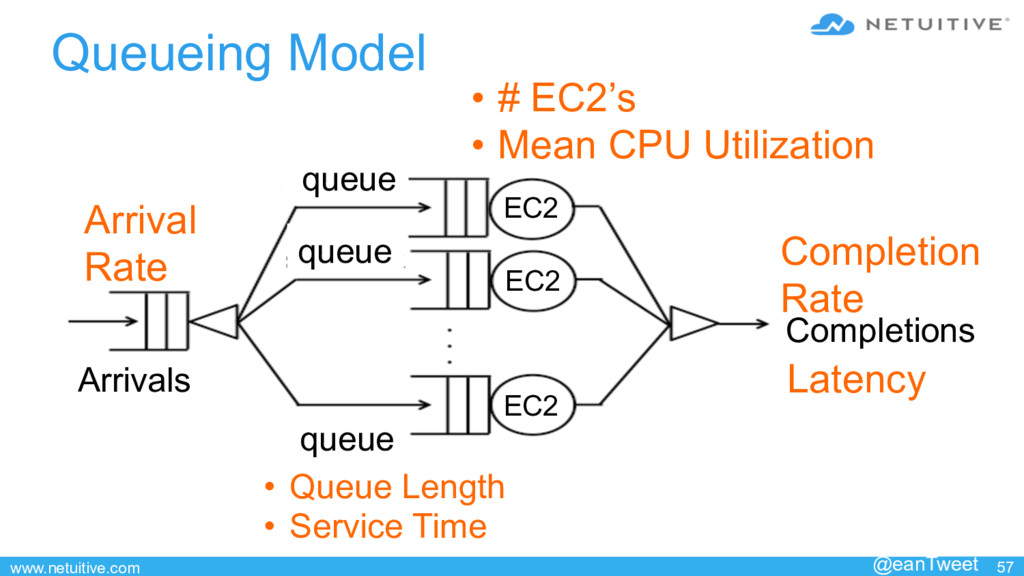{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.netuitive.com 67 Contact Info Elizabeth(Betsy) Nichols, Ph.D. [email protected] @eanTweet #talk-betsy-nichols](https://files.speakerdeck.com/presentations/ba25108f3cc0450485a5fe9adda361e9/slide_66.jpg){kind=link}