y cuellos de botella? Cómo aseguramos 100% uptime? Cómo garantizamos una buena experiencia para todos? Depende… no tenemos todas las respuestas, pero sí algunas sugerencias :)
data persisted only on DBs - Temp data persisted on cache tier - Treat your servers as cattle - Scale OUT > Scale UP - Auto-scaling by CPU/RAM/IO usage
Plan for failure - Auto-remediation & self-healing - Failover procedures "Everything fails, all the time". Werner Vogels, CTO AWS (not actually a meme)
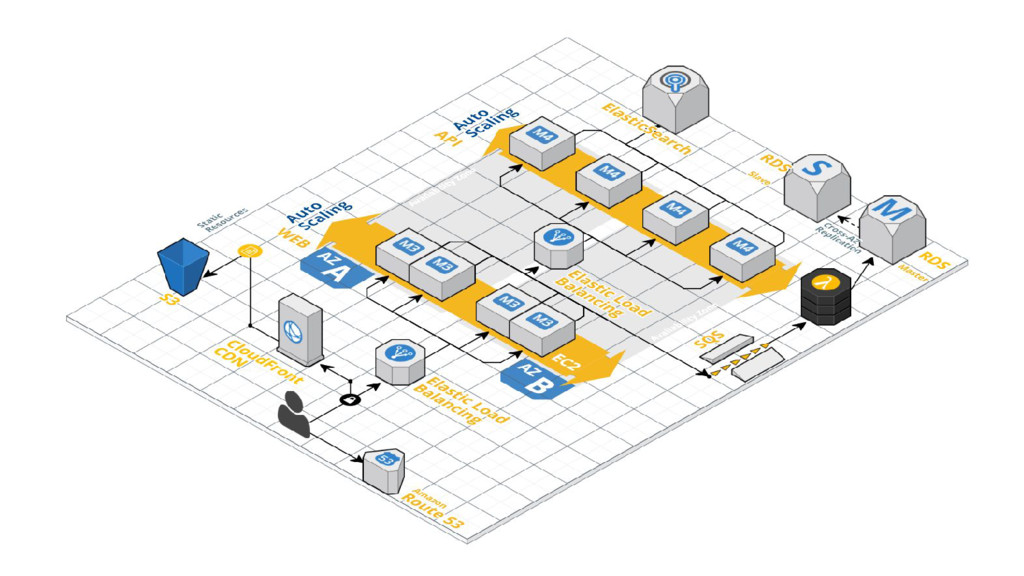
Cloud! - Duplicate (triplicate?) critical component’s - Use highly available and fault tolerant services “If an individual EC2 instance or an entire AWS Availability Zone fails, your app should stay up. This is the essence of architecting for High Availability (HA).” Best Practices
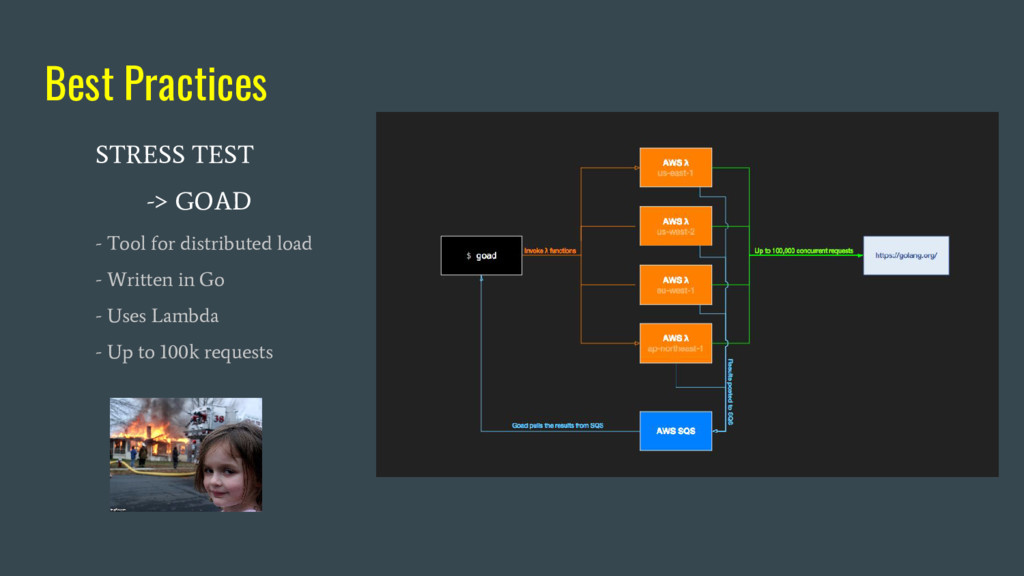
can support - Test your infra under heavy load - Stress every component - Fail early, fail fast, fail again Tools: - AB / Siege / jMeter - Goad / Vegeta - etc. etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}