Zero-Downtime Re-Indexing of Elasticsearch at SignalFx.
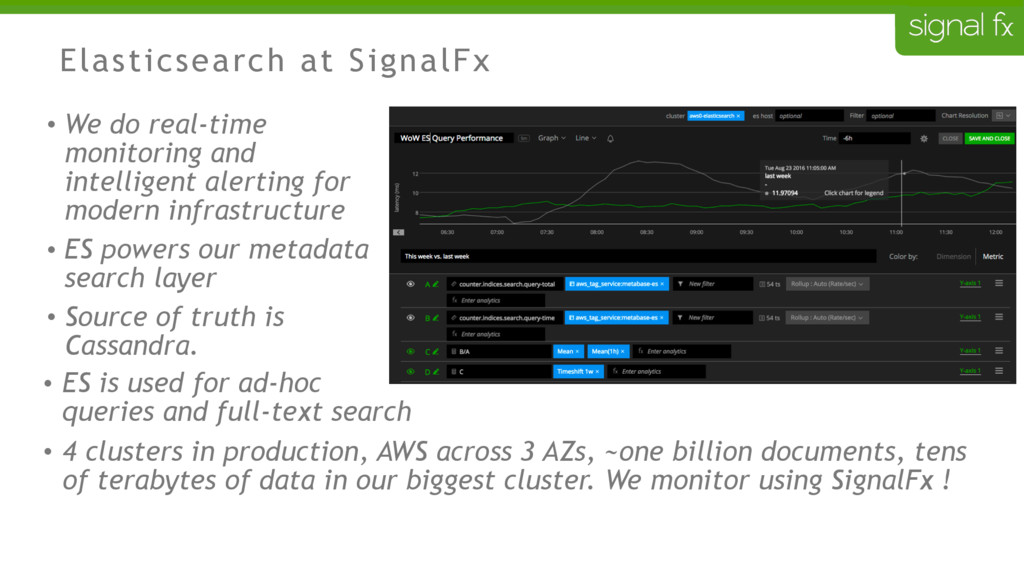
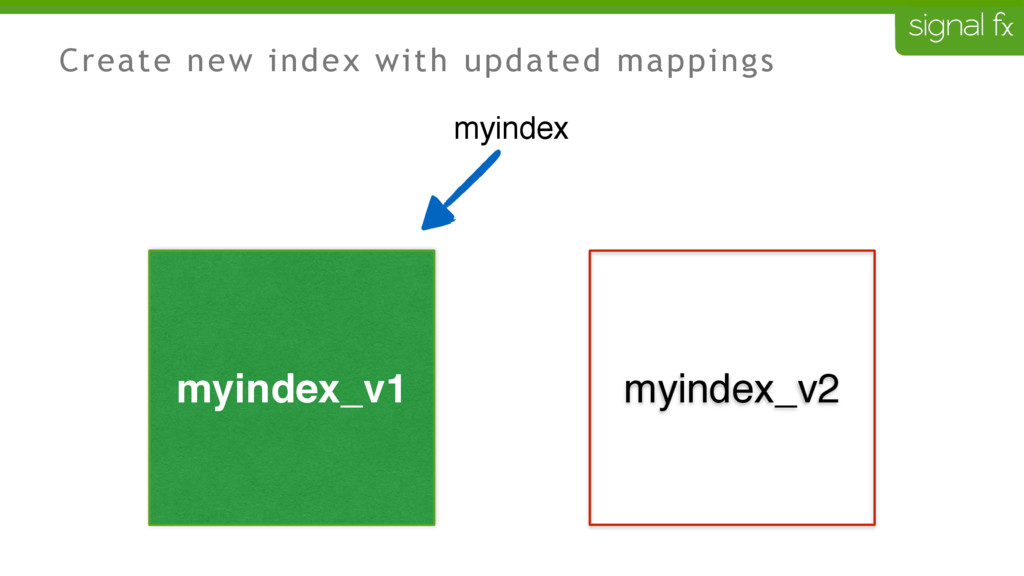
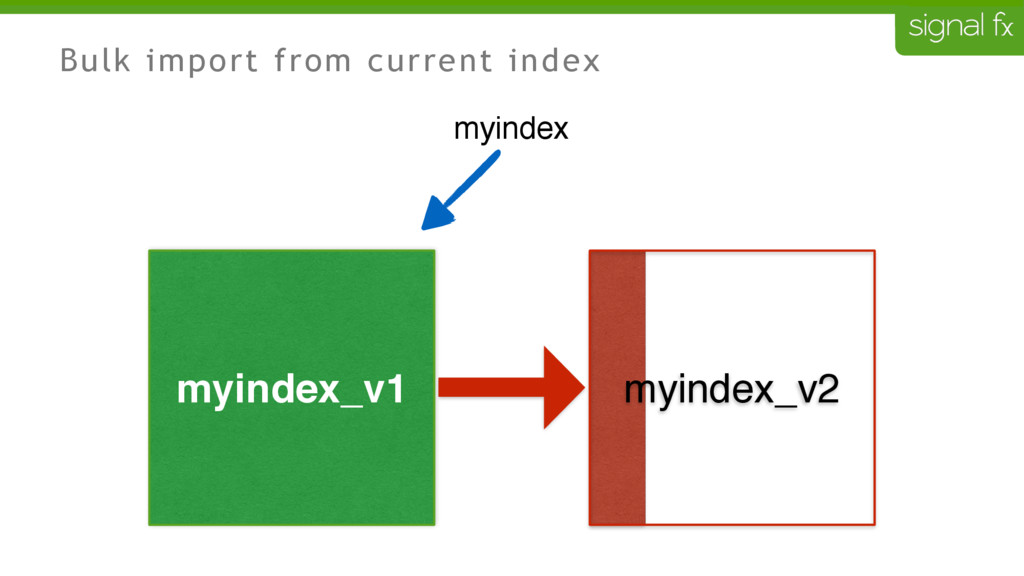
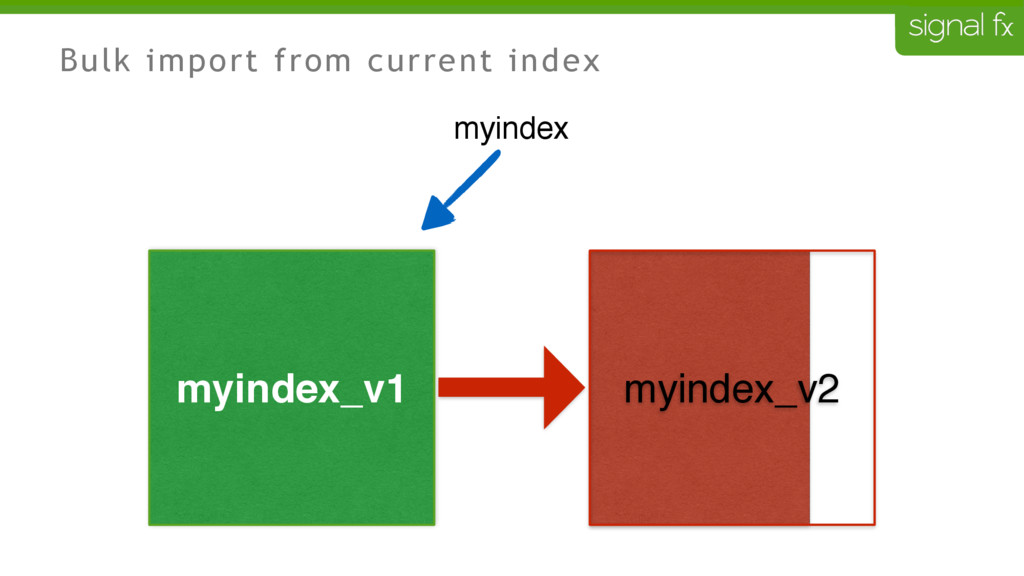
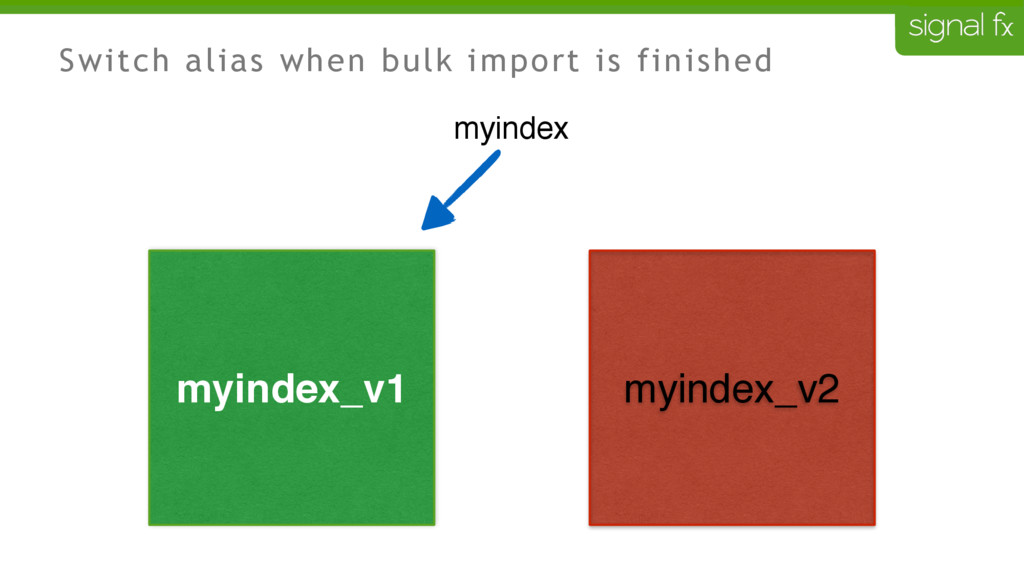
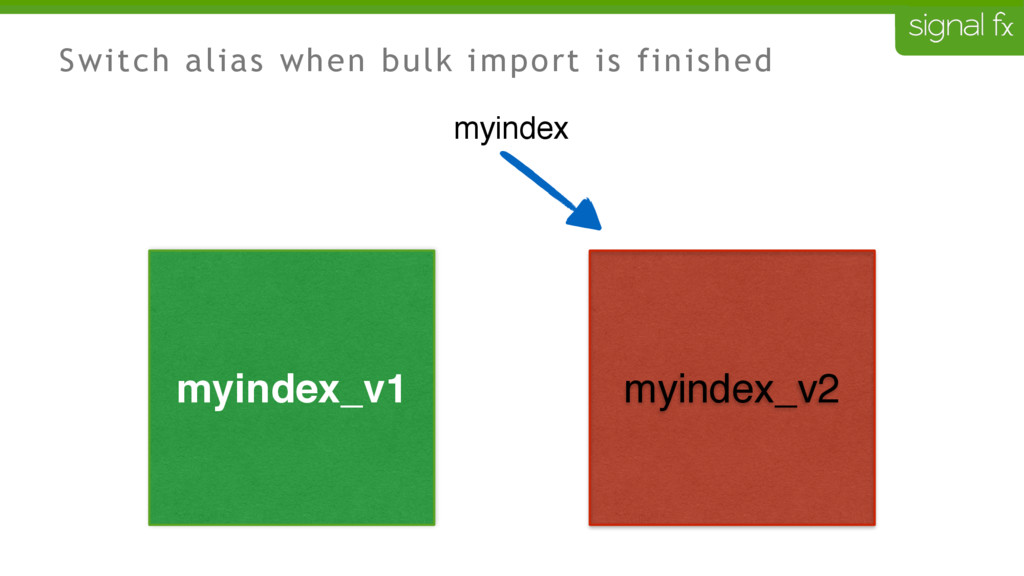
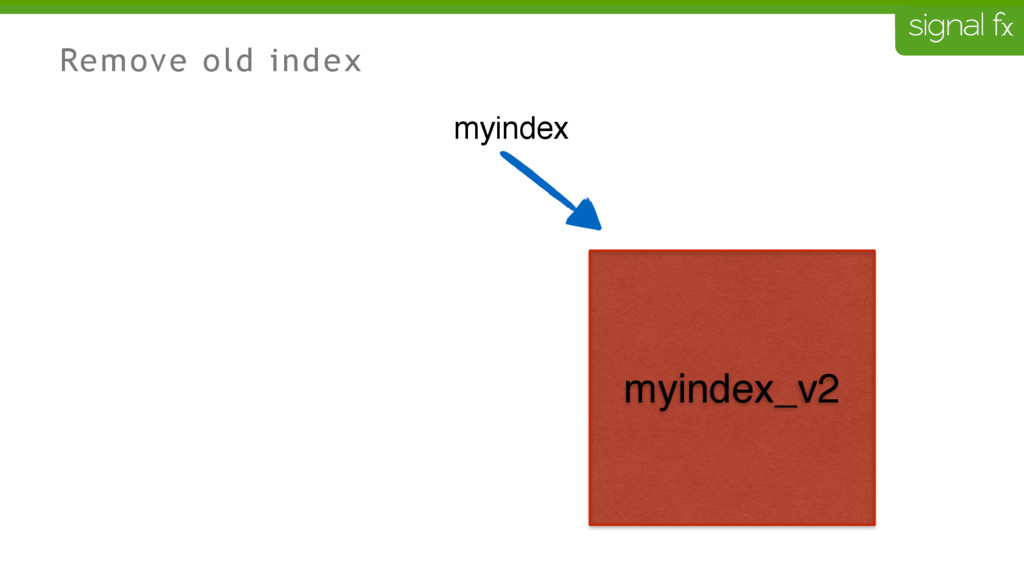
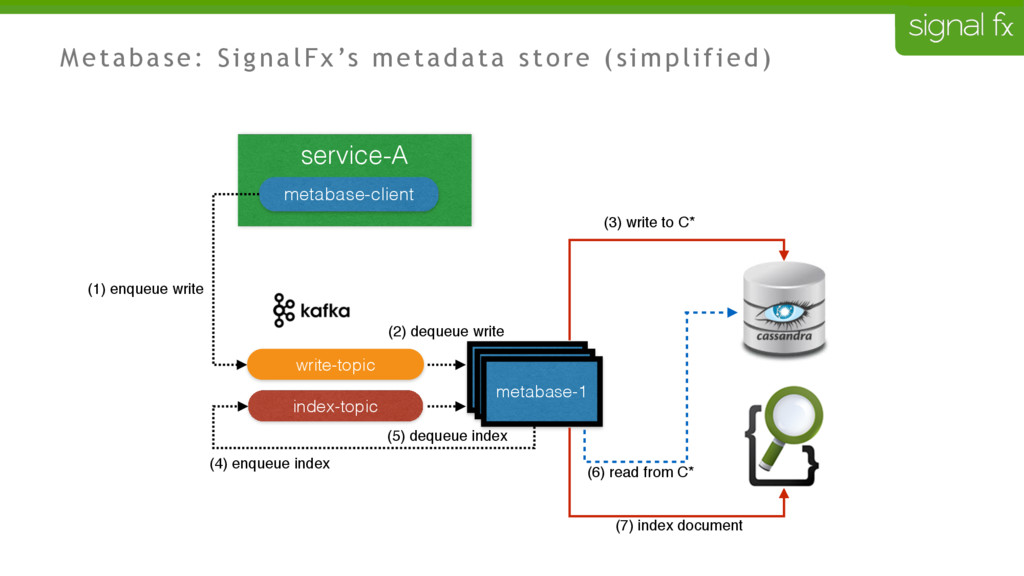
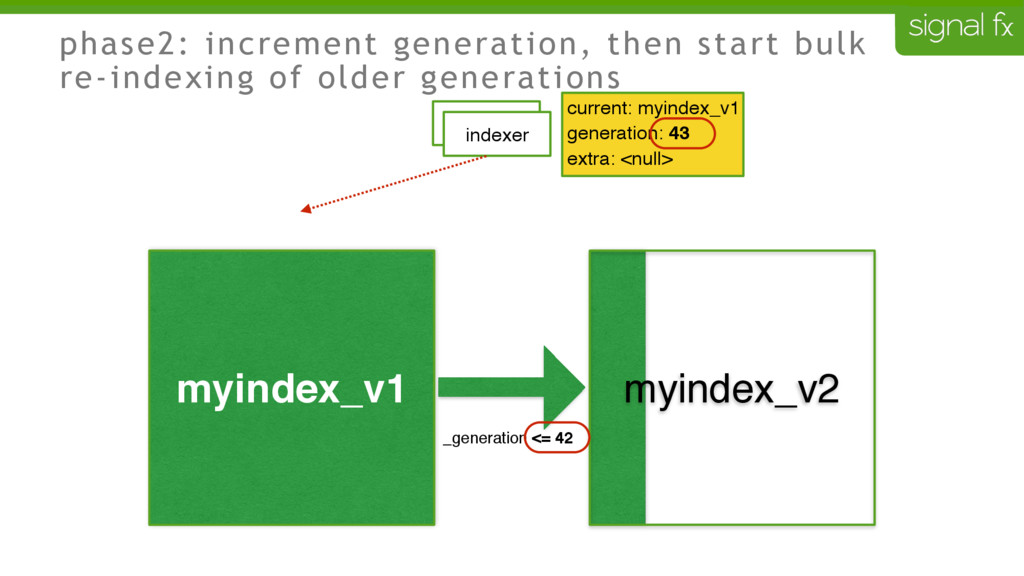
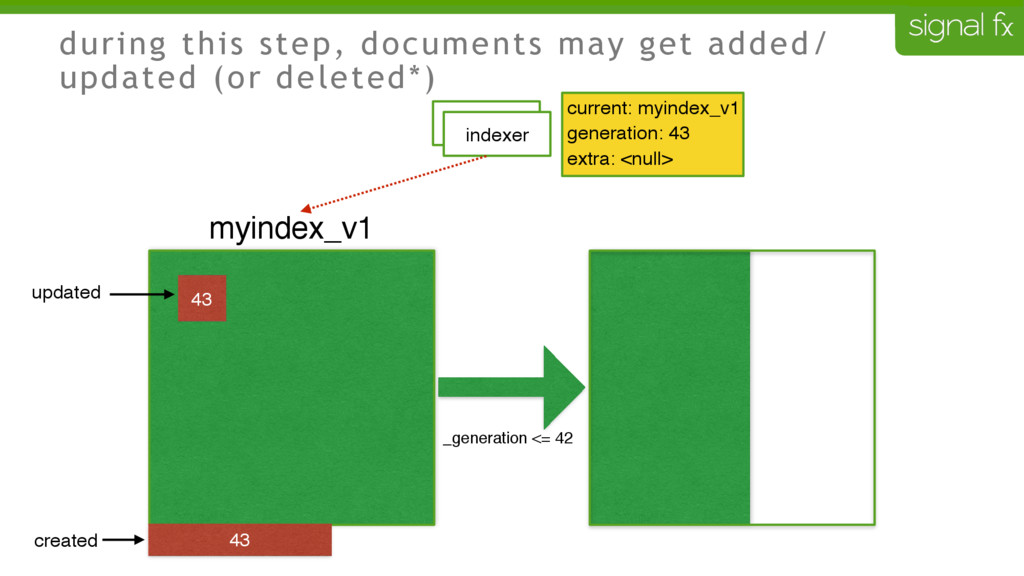
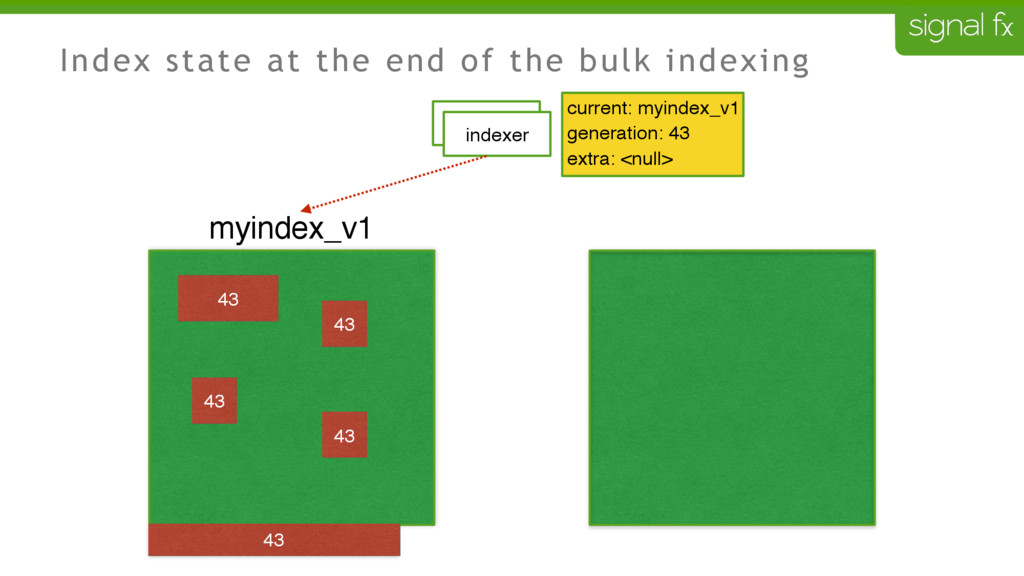
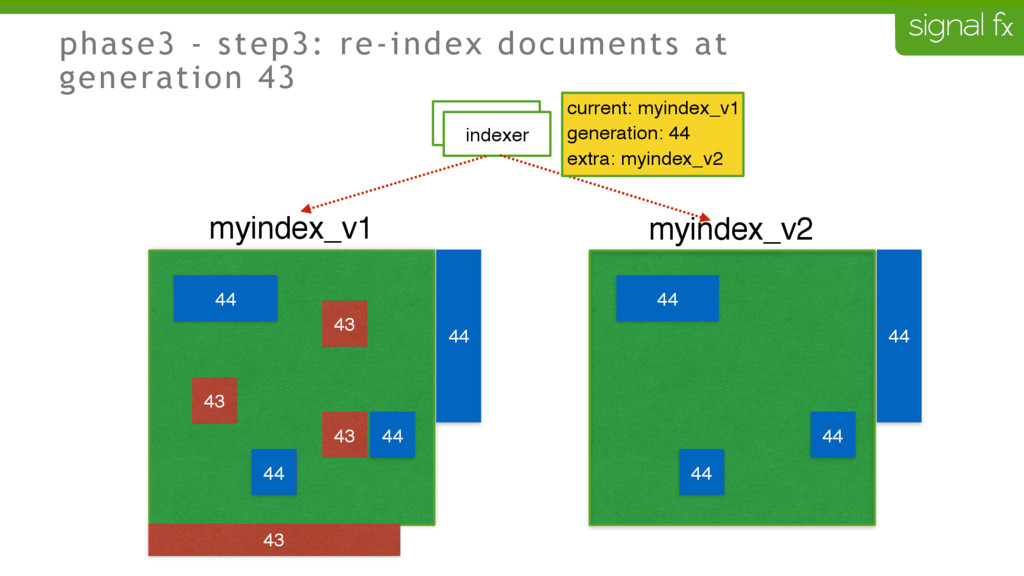
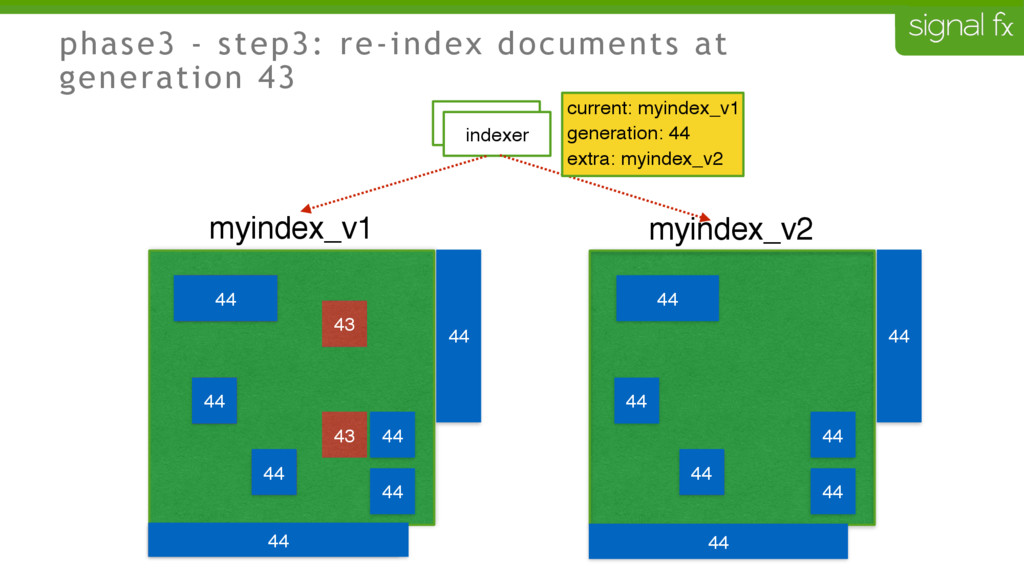
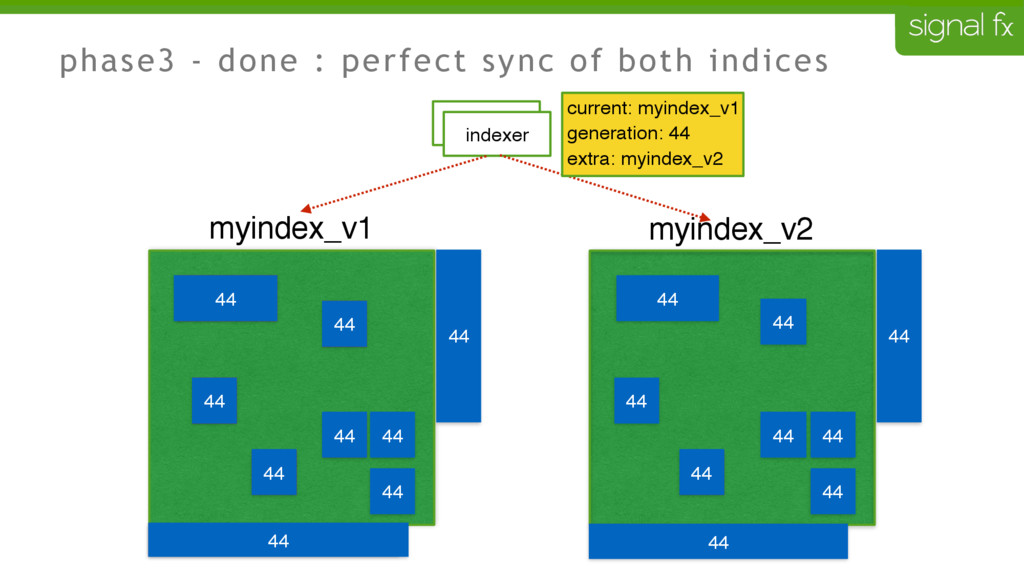
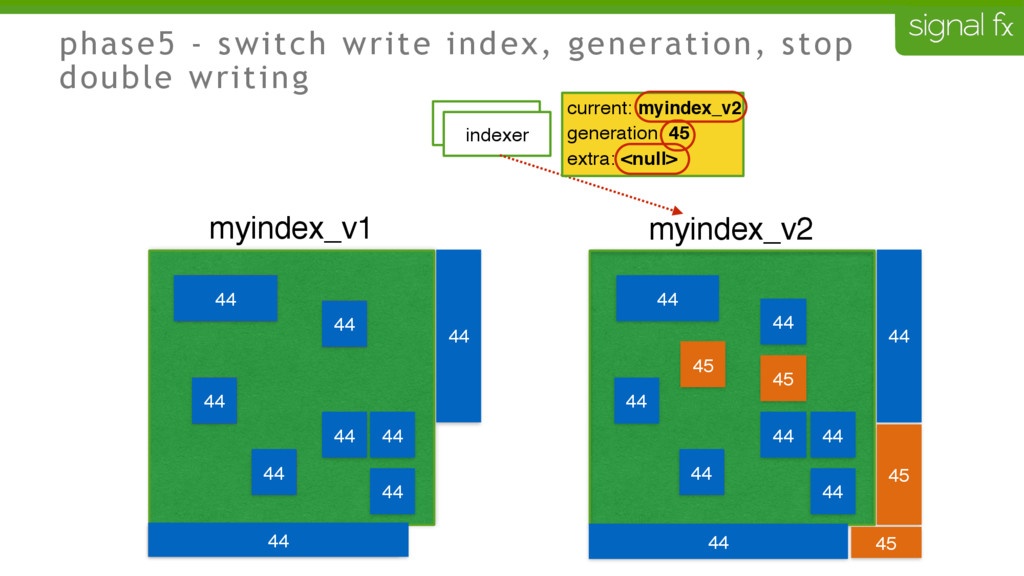
Certain changes in Elasticsearch, such as number of primary shards and mapping changes, require re-indexing. This can be challenging to do depending upon your data flows and uptime requirements. At SignalFx, we have designed our indexing pipeline to allow for a full re-indexing without impacting our service or its users. In this talk, Mahdi will present SignalFx's polyglot metadata search infrastructure and go through the zero-downtime re-indexing process. He will also talk about the lessons learned running this in production as well as how we plan to use this to do a zero-downtime upgrade from Elasticsearch 1.7 to 2.0.
Mahdi is a software engineer with a decade of experience writing software. Previously, he spent 7 years at VMware building key components of its cloud management stack. At SignalFx, Mahdi enjoys the challenges of concurrency and distributed systems while working on the search and metadata persistence layers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}