С помощью систем мониторинга все мониторят свои системы. Но ведь сами системы мониторинга тоже нуждаются в мониторинге. На примере одного программного продукта (из сферы онлайн-аналитики больших объёмов данных), который с одной стороны содержит проприетарное закрытое ядро, а с другой стороны является платформой для открытой разработки (как внутренних расширений, так и интеграции с внешним миром с помощью всеобъемлющего API) мы рассмотрим кейсы тонкого self-health-чека и как такие возможности помогают make business monitoring great again.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
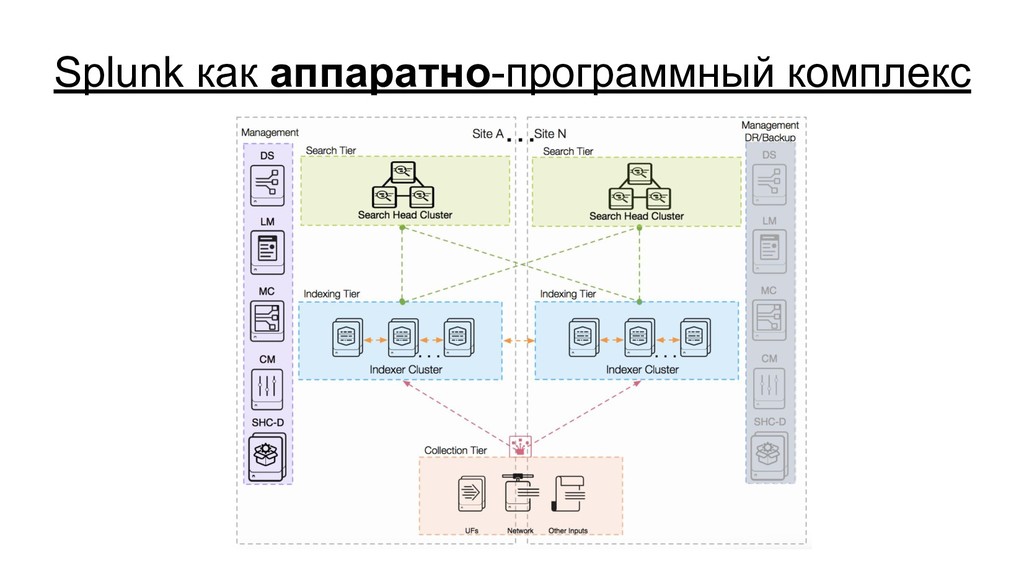{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
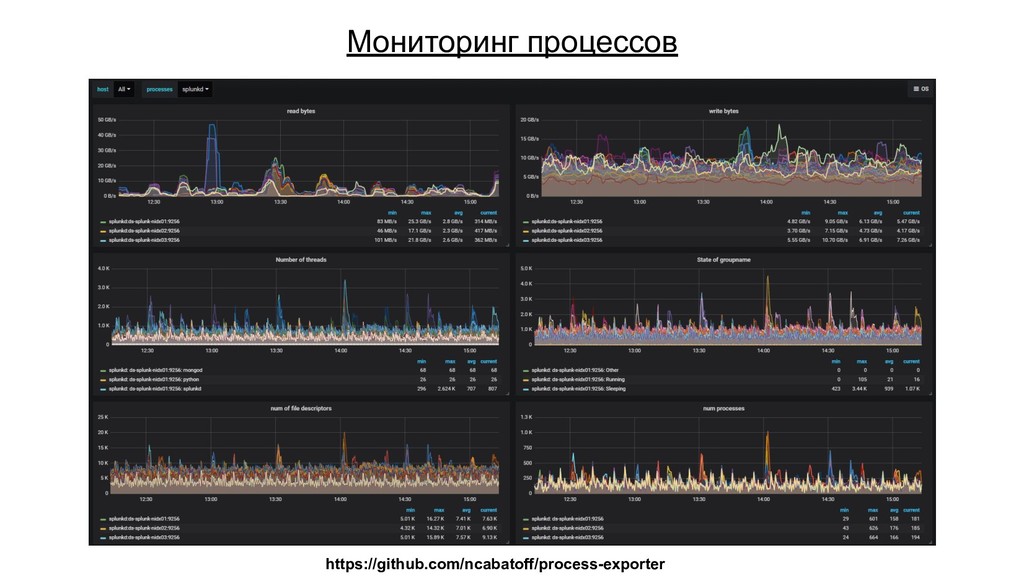{kind=link}
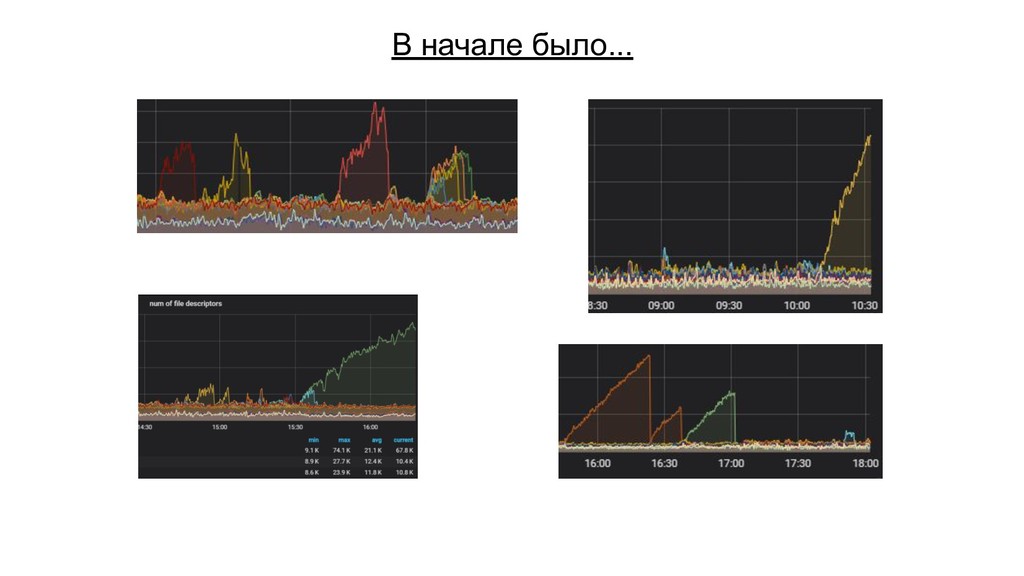{kind=link}
{kind=link}
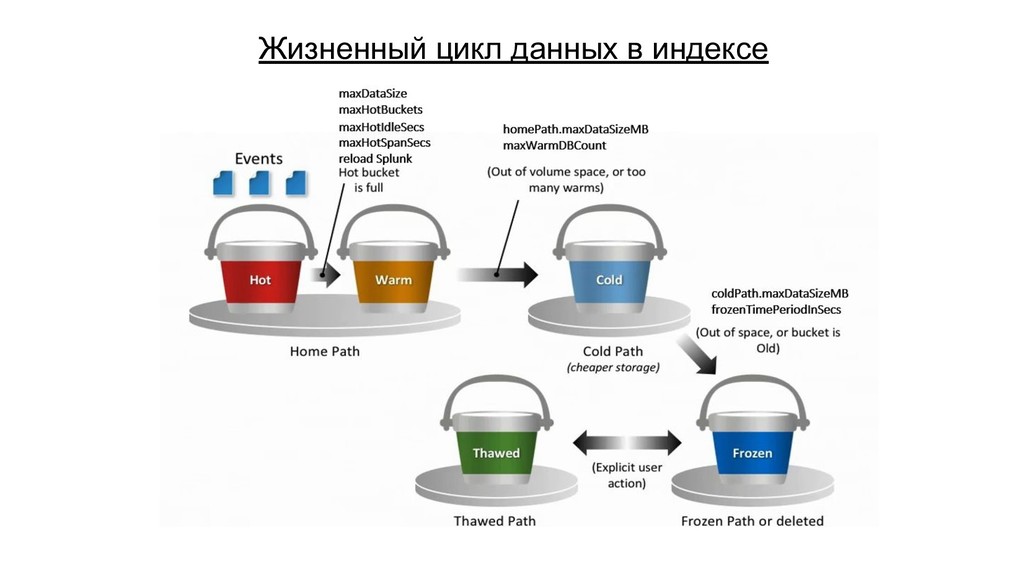{kind=link}
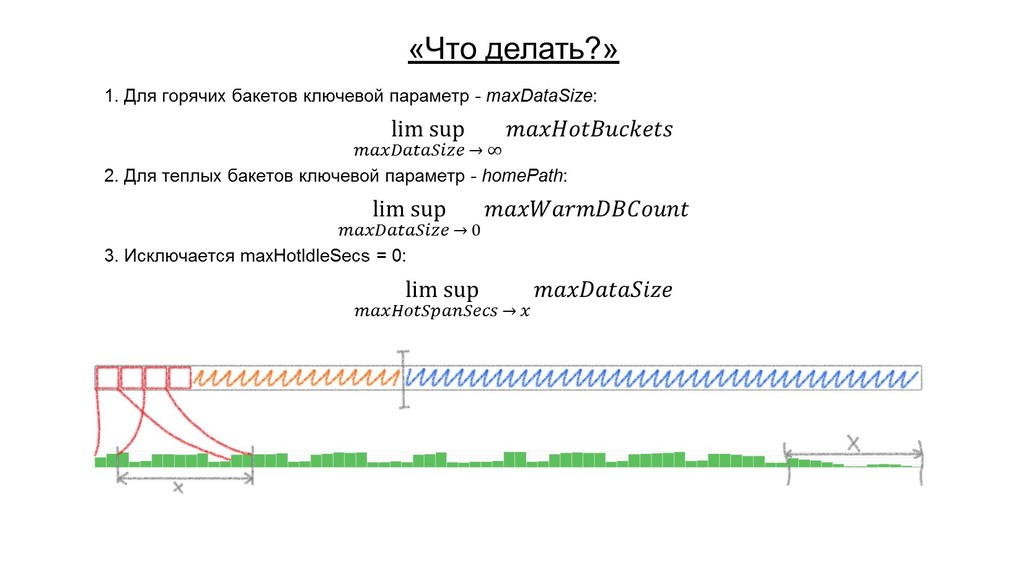
![Откуда горки растут [filenet] homePath = $SPLUNK_DB/cl_filenet/db coldPath = $SPLUNK_DB/cl_filenet/colddb](https://files.speakerdeck.com/presentations/db39715c1c194c74b5309f0394beca73/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}