Bloomberg Finance L.P. All rights reserved. Search at Bloomberg: Challenges, Opportunities, and Lessons Learned SIGIR 2022 – SIRIP 2022 Keynote July 12, 2022 Edgar Meij, Ph.D. Head of AI Search and Discovery @edgarmeij | [email protected]
just finance, right? • A technology company founded in New York City in 1981 • 325,000+ subscribers in 170 countries • Over 20,000 employees in 163 locations, including over 7,000 software engineers – with more than 200 engineers and data scientists working on AI and related problems • Increased use of and contributions to open source software • Increased presence in academic research
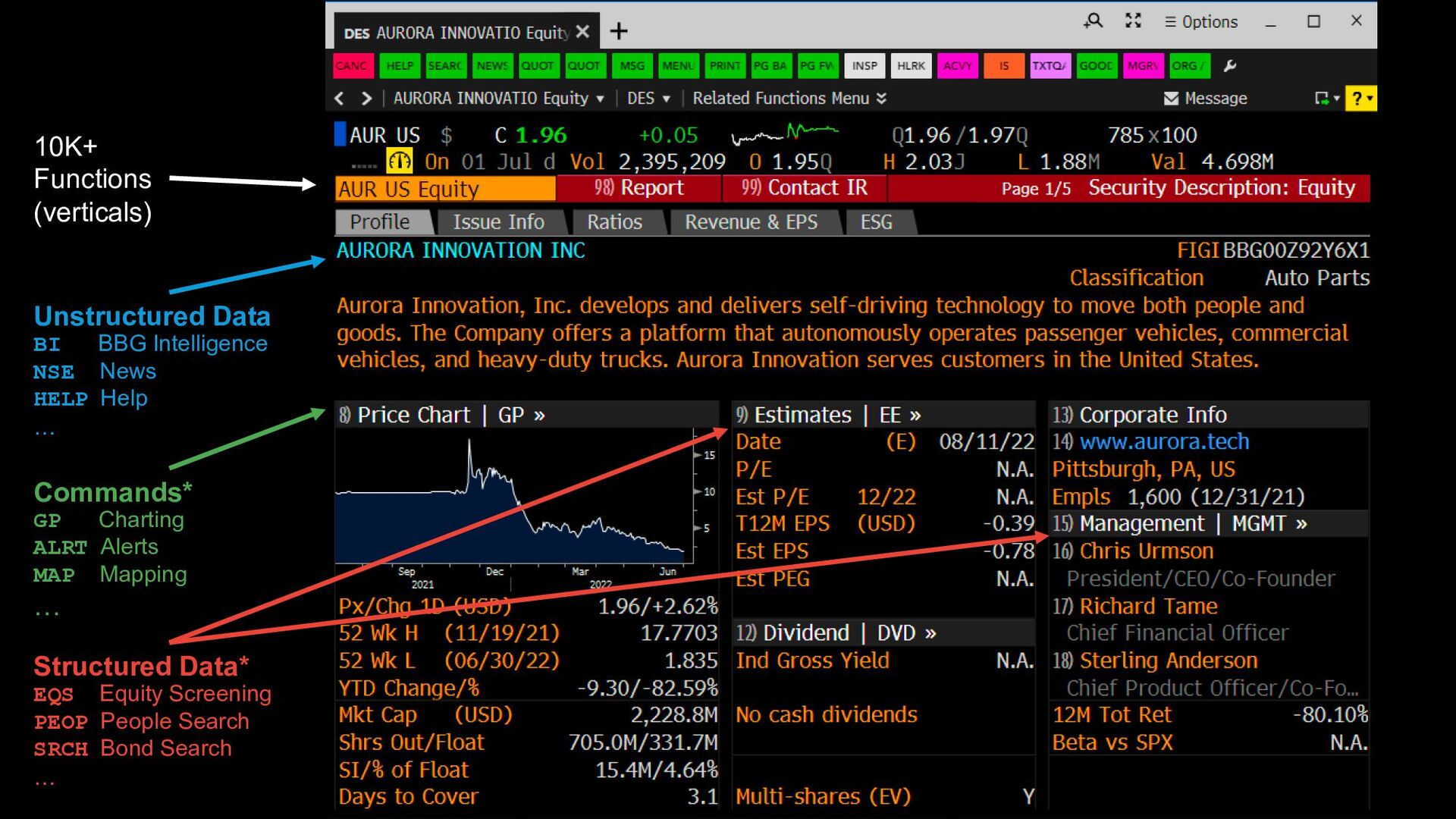
the backbone of the financial markets • Historically mostly “structured” market data (ticks/quotes/trades) ◦ Well-understood ◦ Enabling advanced forms of automation • Other types of data/information ◦ Real-world events, natural disasters ◦ Sociocultural phenomena ◦ Economic indicators ◦ Sales, revenue forecasts, futures, etc. ◦ Government policies ◦ Legal proceedings and litigation ◦ The weather ◦ … Our Challenge Identify financially-relevant signal from noisy, complex tangentially-related datasets
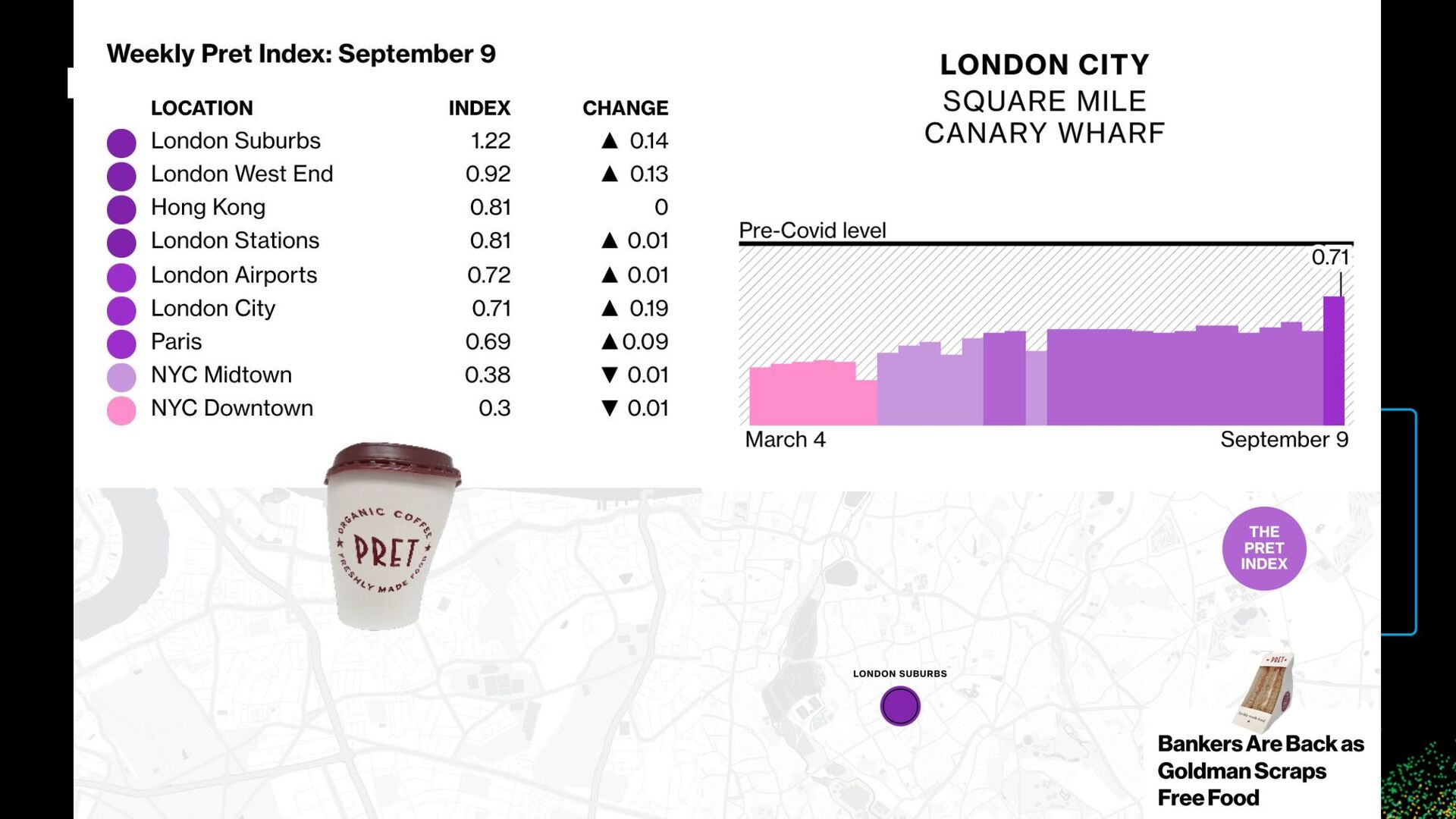
the backbone of the financial markets • Increasingly non-traditional factors, based on “alternative” data, such as: ◦ Satellite images / CO2 emissions over factories ◦ Sentiment analytics on news ◦ Shopping mall footfall traffic ◦ Number of people riding the subway ◦ “Pret index” ◦ Credit card transactions ◦ etc. • But also “unstructured” data… Our Challenge Identify financially-relevant signal from noisy, complex tangentially-related datasets
the backbone of the financial markets • Increasingly non-traditional factors, based on “alternative” data, such as: ◦ Satellite images / CO2 emissions over factories ◦ Sentiment analytics on news ◦ Shopping mall footfall traffic ◦ Number of people riding the subway ◦ “Pret index” ◦ Credit card transactions ◦ etc. • But also “unstructured” data… Our Challenge Identify financially-relevant signal from noisy, complex tangentially-related datasets
the backbone of the financial markets • Increasingly non-traditional factors, based on “alternative” data, such as: ◦ Satellite images / CO2 emissions over factories ◦ Sentiment analytics on news ◦ Shopping mall footfall traffic ◦ Number of people riding the subway ◦ “Pret index” ◦ Credit card transactions ◦ etc. • But also “unstructured” data… Challenge: identify financially-relevant signal from noisy, complex tangentially-related datasets.
• 80% of data exists in the form of “raw”, unstructured text, e.g., ◦ Company filings, earnings call transcripts ◦ Tweets, Reddit, Facebook posts, news stories ◦ Research analyst reports, CRMs ◦ Economic policy, govt communications ◦ Press releases ◦ Web pages ◦ Chats & e-mail, client feedback ◦ etc. ◦ Lots of jargon and custom terminology (sometimes even firm-specific!) Our Challenge Identify financially-relevant signal from noisy, complex tangentially-related datasets
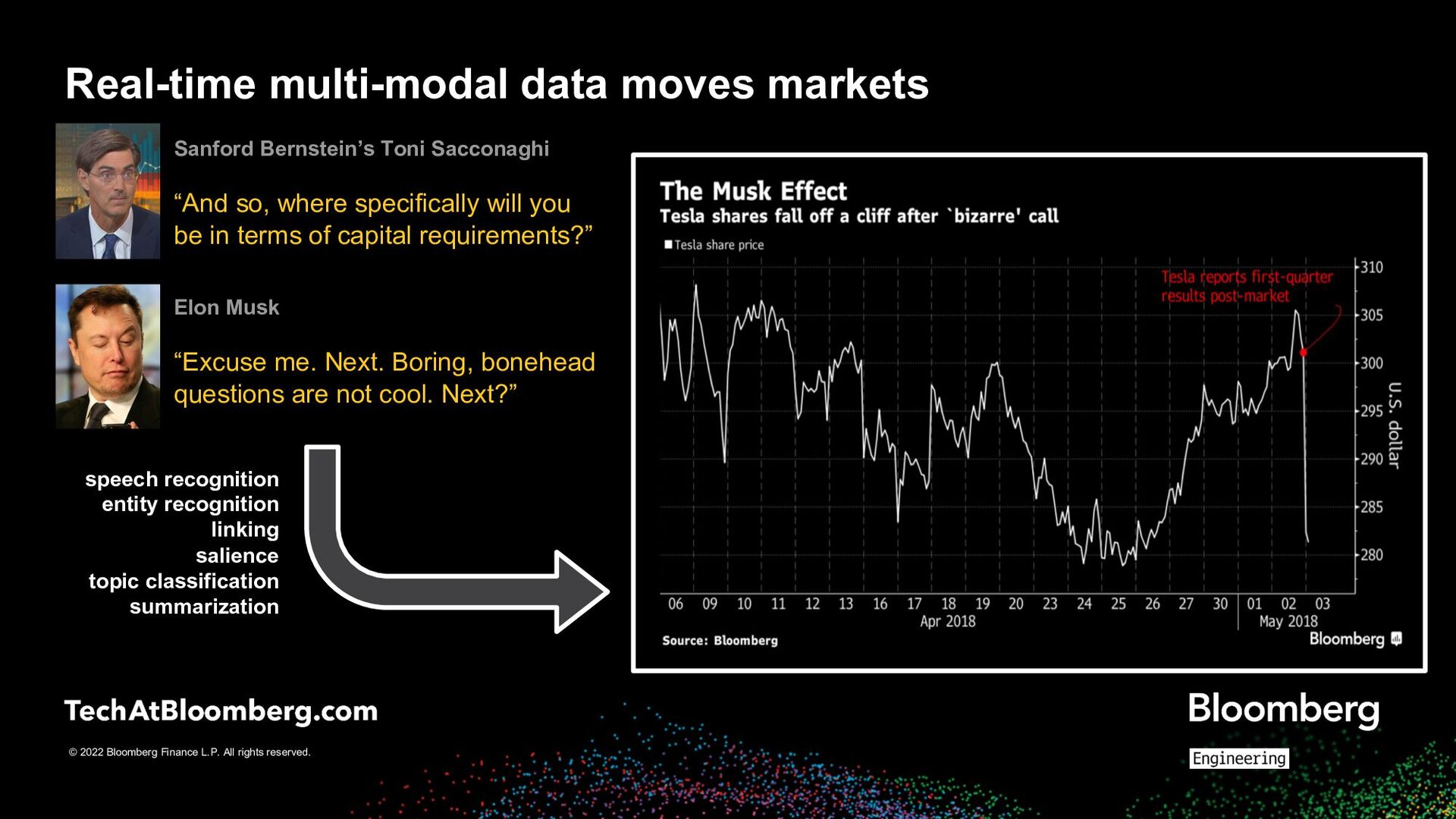
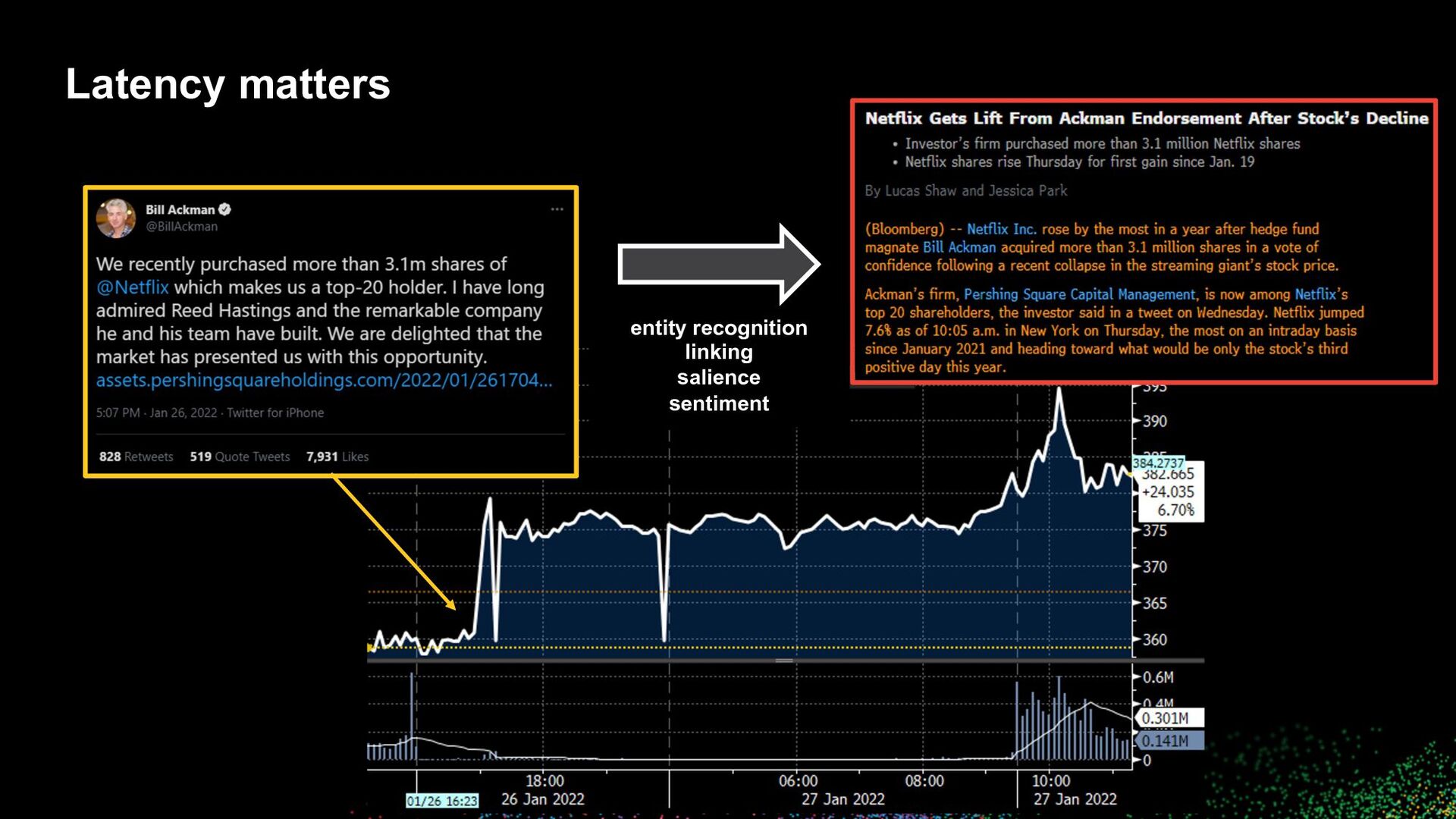
Toni Sacconaghi “And so, where specifically will you be in terms of capital requirements?” Real-time multi-modal data moves markets speech recognition entity recognition linking salience topic classification summarization Elon Musk “Excuse me. Next. Boring, bonehead questions are not cool. Next?”
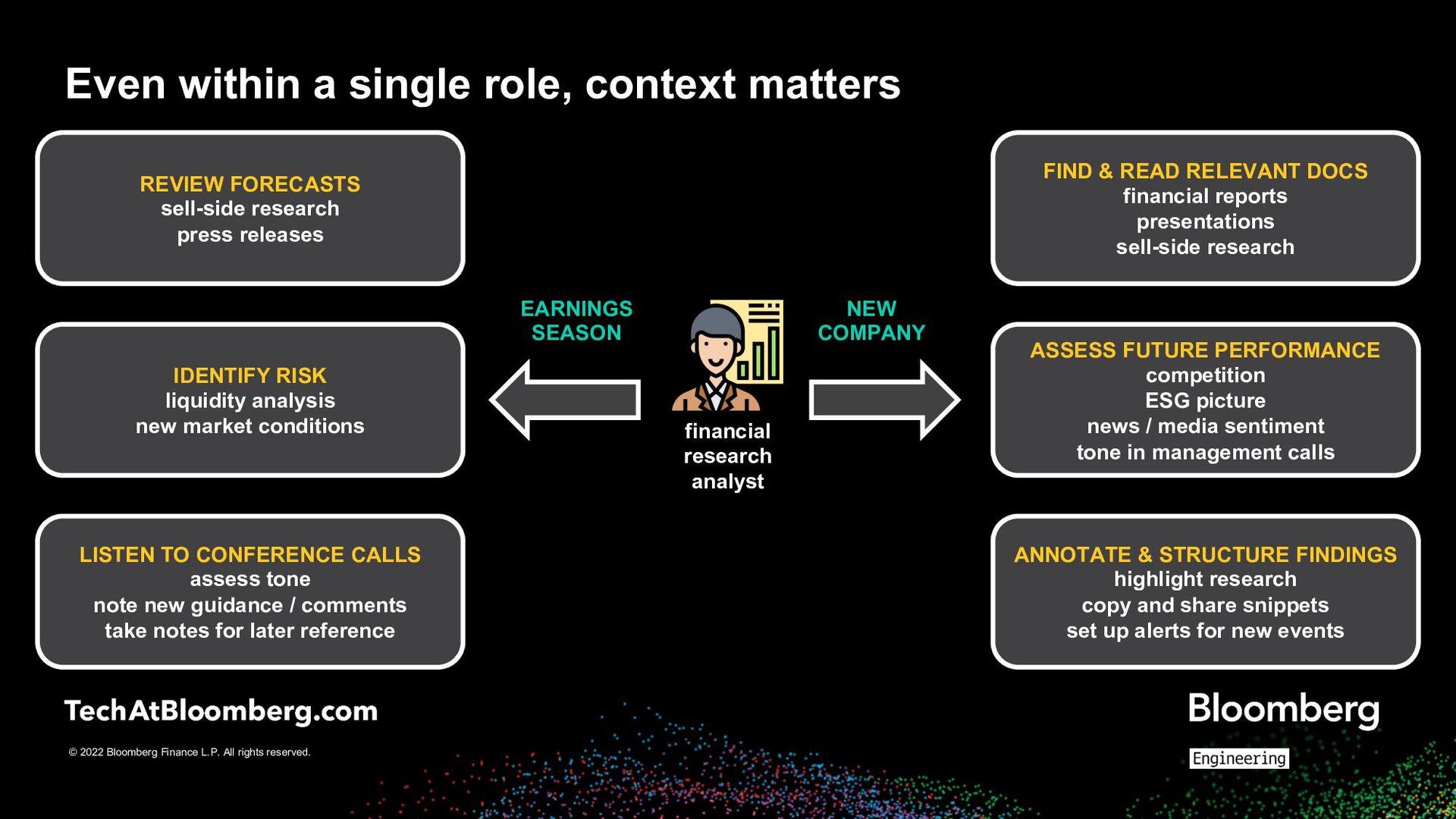
a single role, context matters financial research analyst REVIEW FORECASTS sell-side research press releases IDENTIFY RISK liquidity analysis new market conditions LISTEN TO CONFERENCE CALLS assess tone note new guidance / comments take notes for later reference FIND & READ RELEVANT DOCS financial reports presentations sell-side research ASSESS FUTURE PERFORMANCE competition ESG picture news / media sentiment tone in management calls ANNOTATE & STRUCTURE FINDINGS highlight research copy and share snippets set up alerts for new events EARNINGS SEASON NEW COMPANY
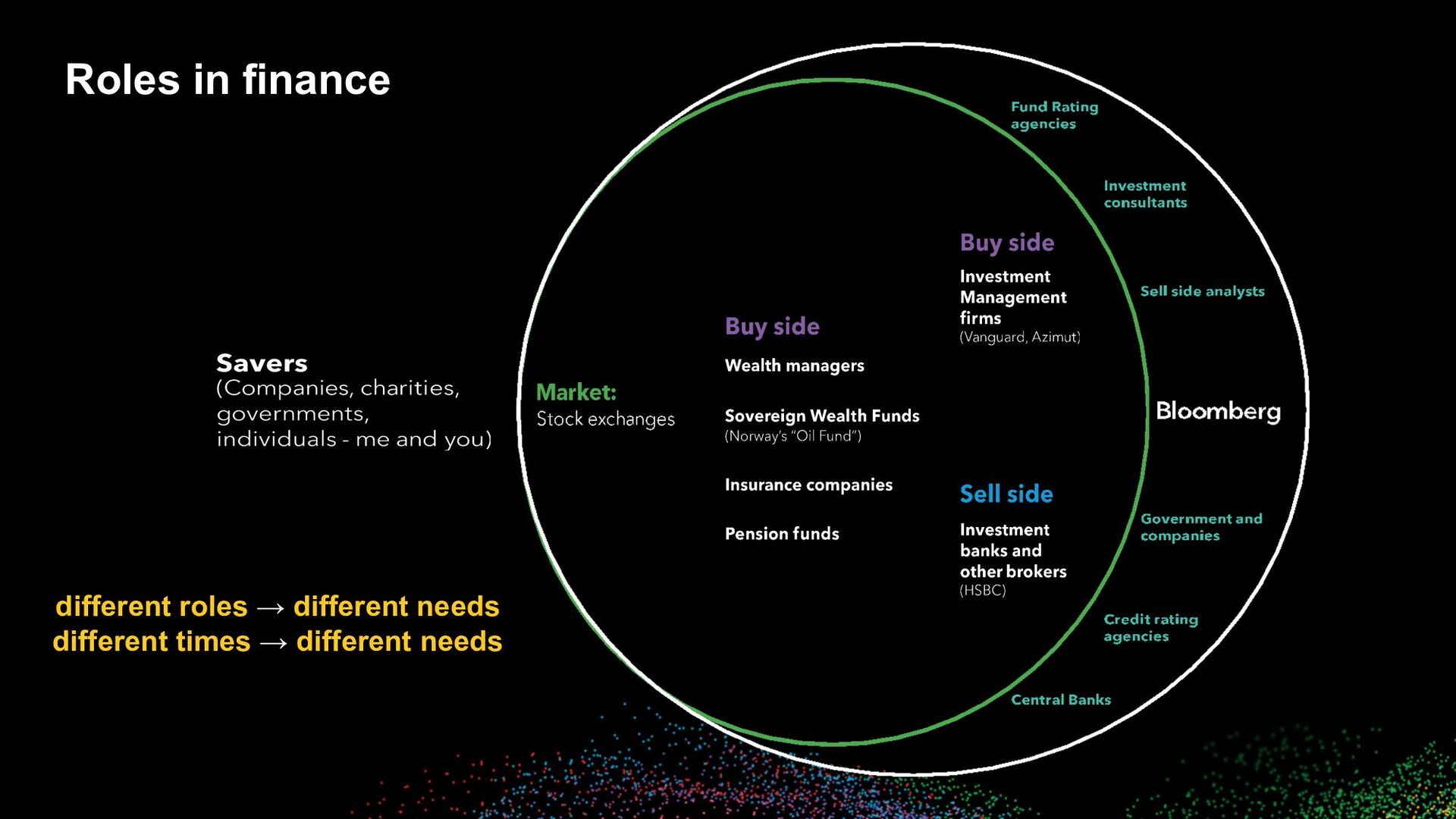
• Most of our clients use the Terminal in their day-to-day workflows to: ◦ Trade ◦ Spot inefficiencies/opportunities in the market ◦ Find signal ◦ Keep abreast of developments ◦ etc. • Deeply-engrained muscle memory for executing Bloomberg functions • Limited room for “discovery”
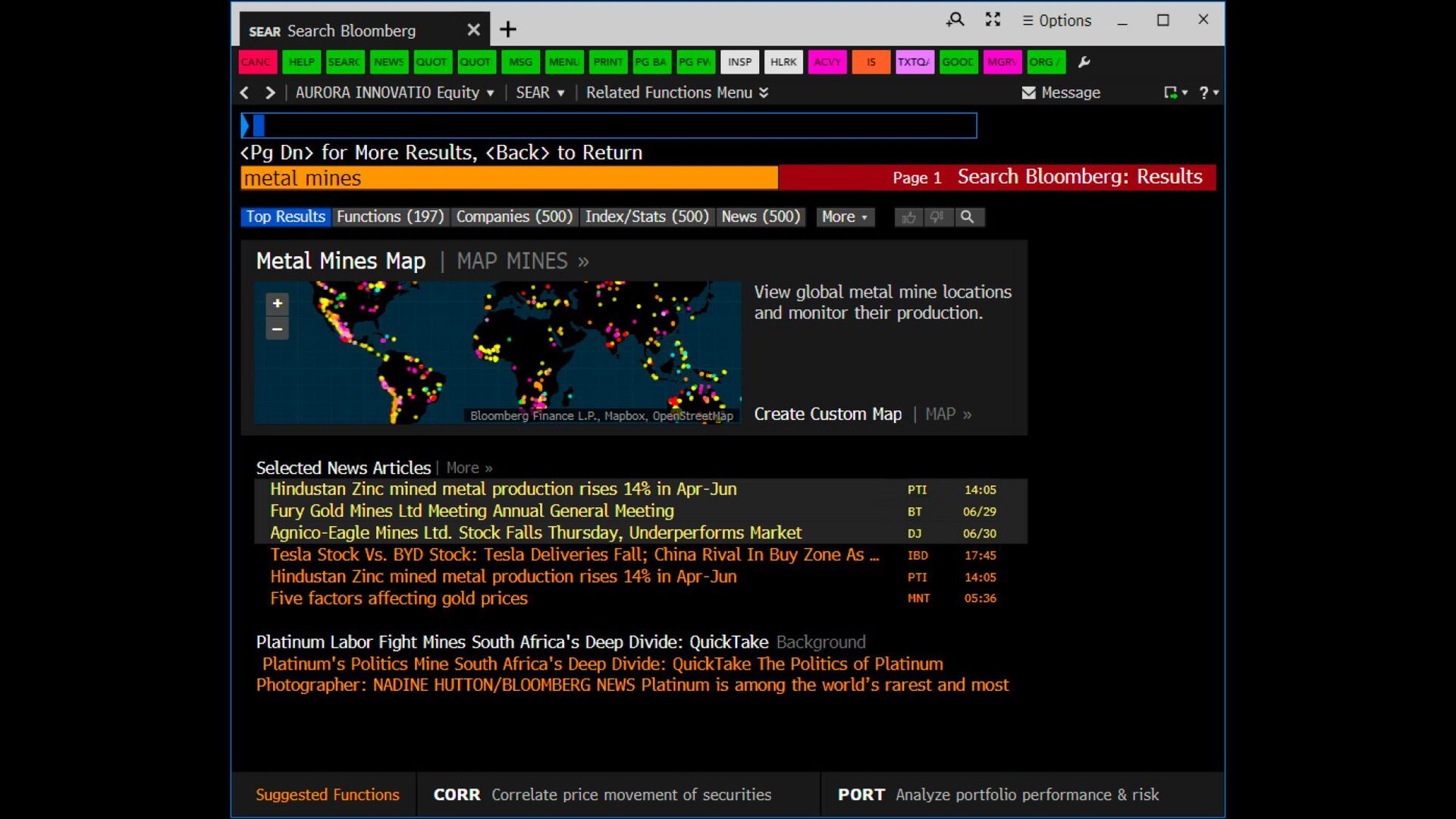
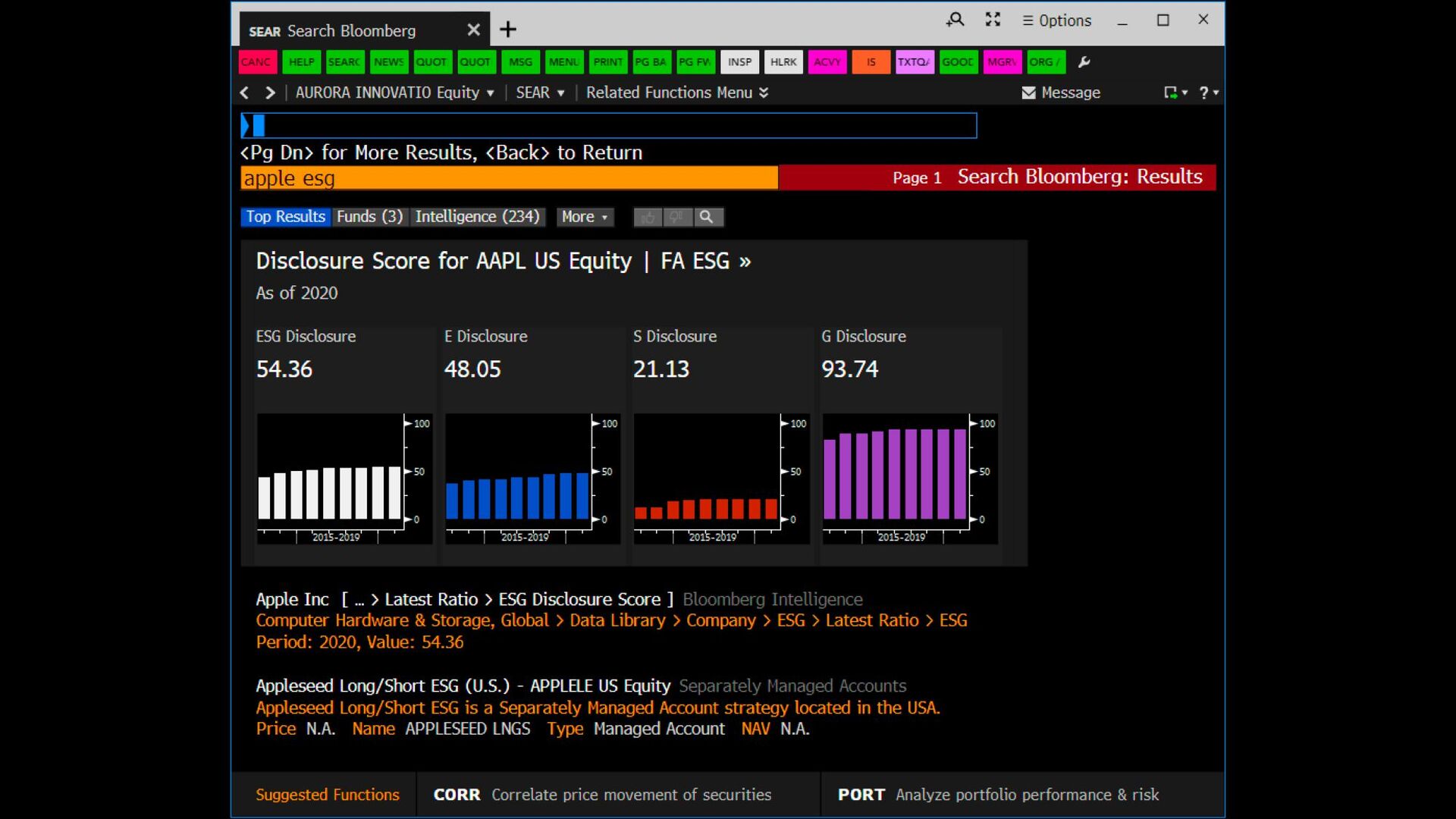
many disparate units of retrieval • Many disparate sources ◦ Some indexed by us ◦ Some indexed by others/owners • How do you normalize scores for results from different back-ends, and then merge and present a single list? ◦ Account for different “document” lengths and collection statistics ◦ Account for different “document” fields ◦ Account for multiple languages ◦ Account for multiple ranking functions ◦ Account for different, perhaps non-comparable scores
framework • Reuse, reuse, reuse! Lots of domains, but they share a lot in common: language about time, currency, aggregation ops, … • Developer efficiency Build a semantic parser for a new domain fast, then iterate • Flexibility To support language for new semantic operations • Performance Interactive times, on par with the typical search engine • Interpretability Not just an answer, but how it was derived Developer User
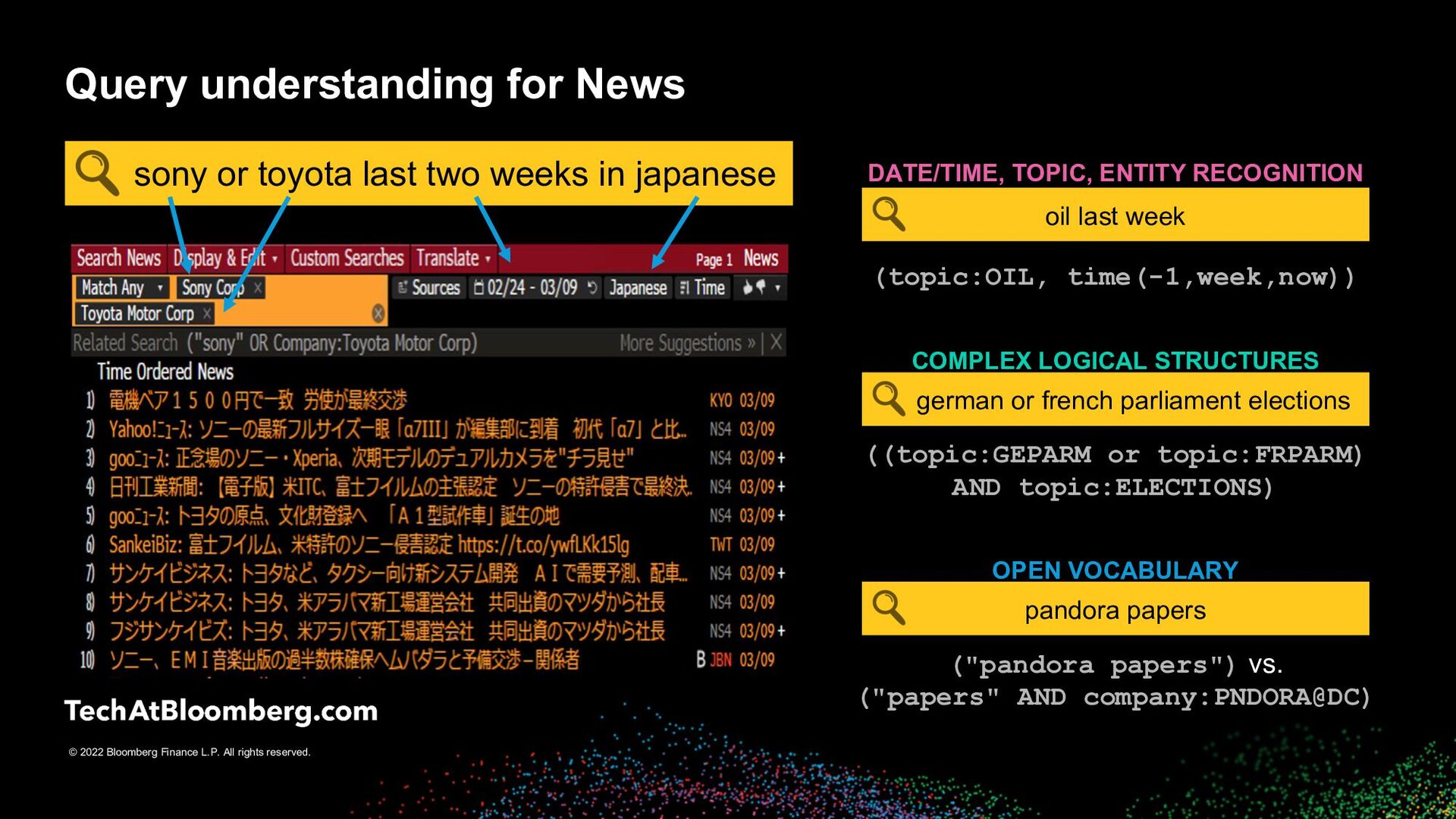
ENTITY RECOGNITION oil last week (topic:OIL, time(-1,week,now)) COMPLEX LOGICAL STRUCTURES german or french parliament elections ((topic:GEPARM or topic:FRPARM) AND topic:ELECTIONS) OPEN VOCABULARY pandora papers ("pandora papers") vs. ("papers" AND company:PNDORA@DC) Query understanding for News sony or toyota last two weeks in japanese german or french parliament elections oil last week pandora papers
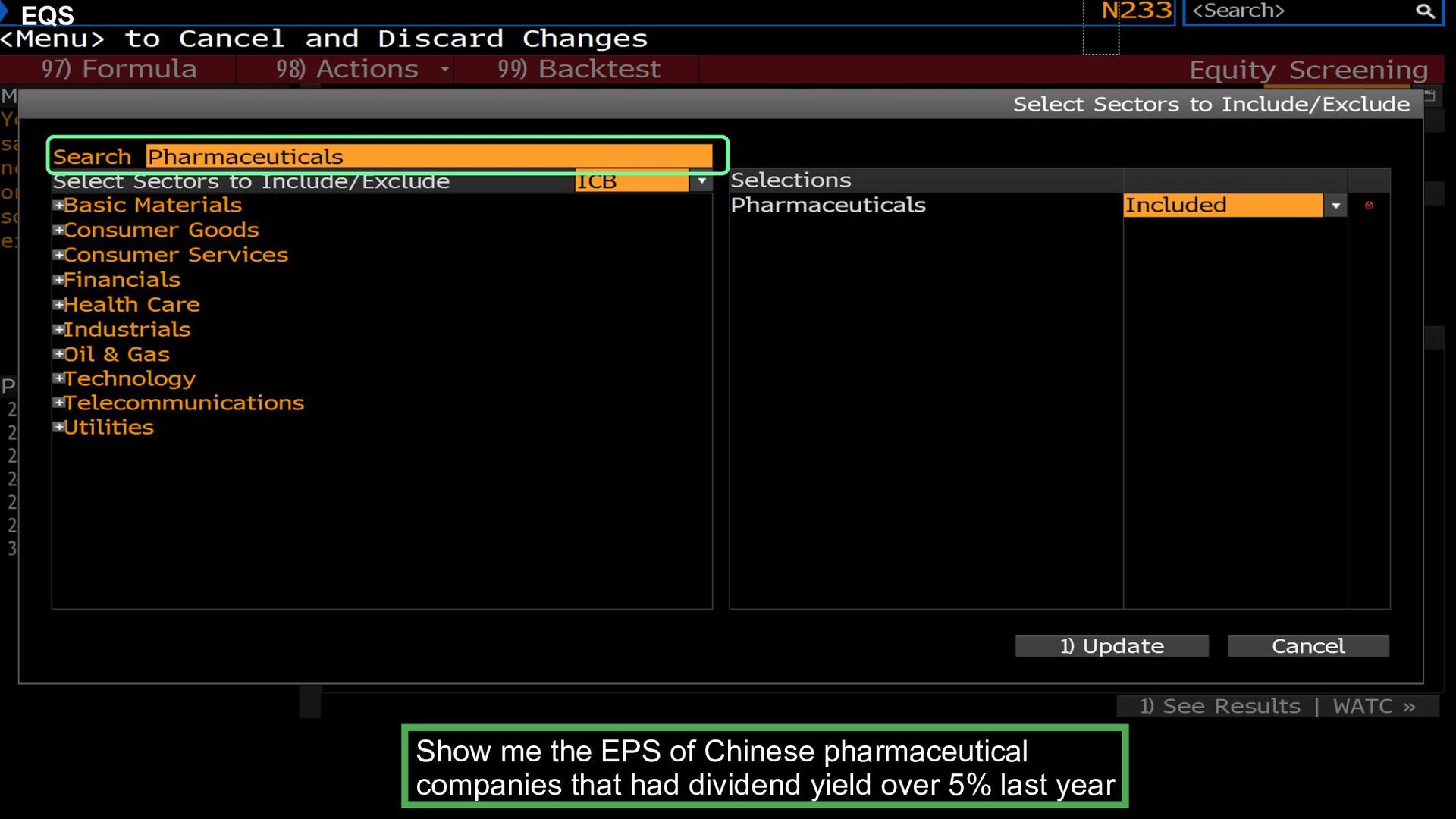
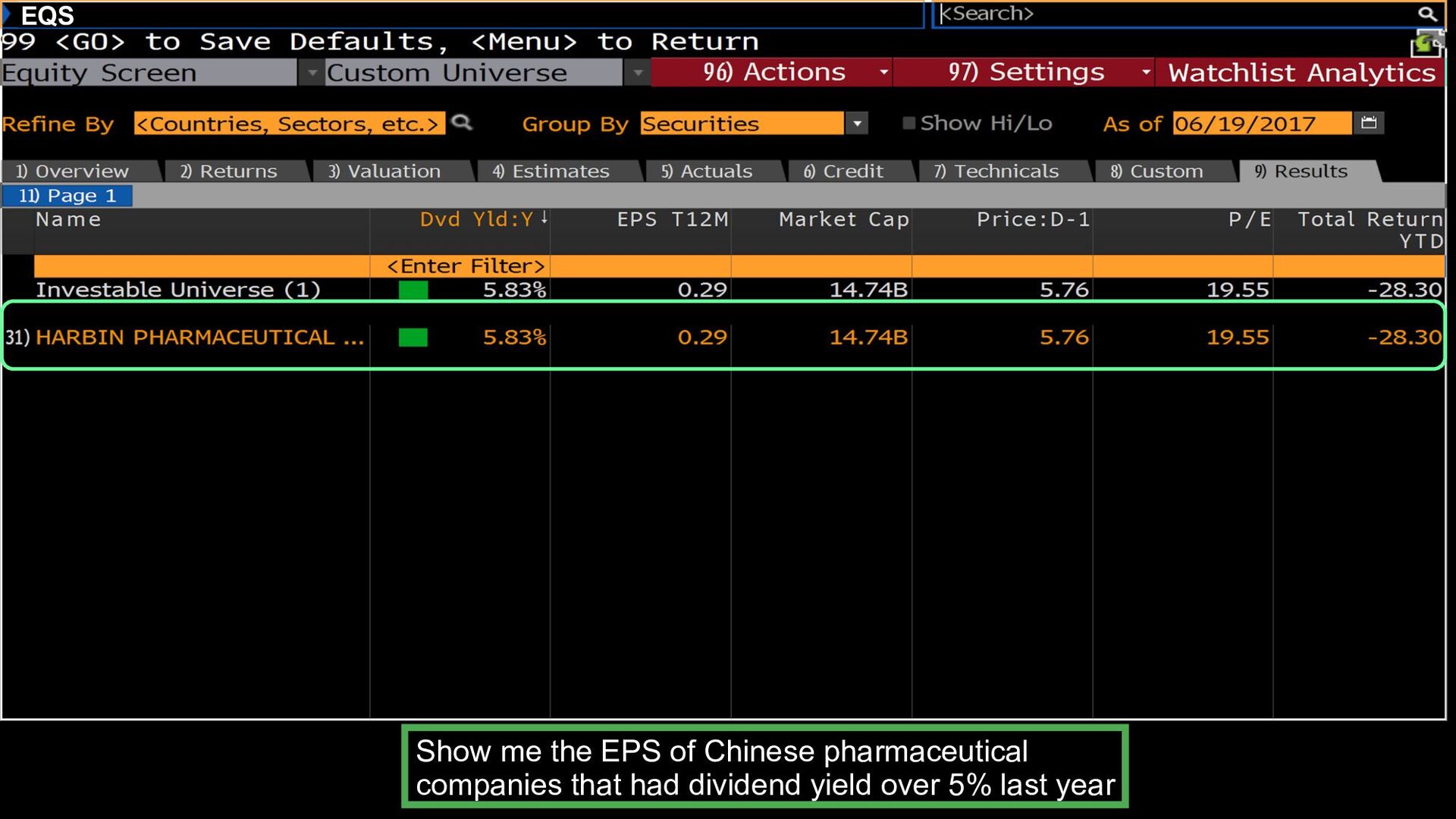
is used across the Bloomberg Terminal Bonds Charts Economic Equities Holdings News People Show all floating Asian tech bonds maturing in the next 10 years Yearly net income of Google and IBM in last 20 years Show GDP of China and Germany in Q1 2016 What are the top 10 Asian tech companies with eps >= 4 German holders of French ETFs Show me news about oil from the FT from the last month Who are the UMich alumni that work for GS in NYC?
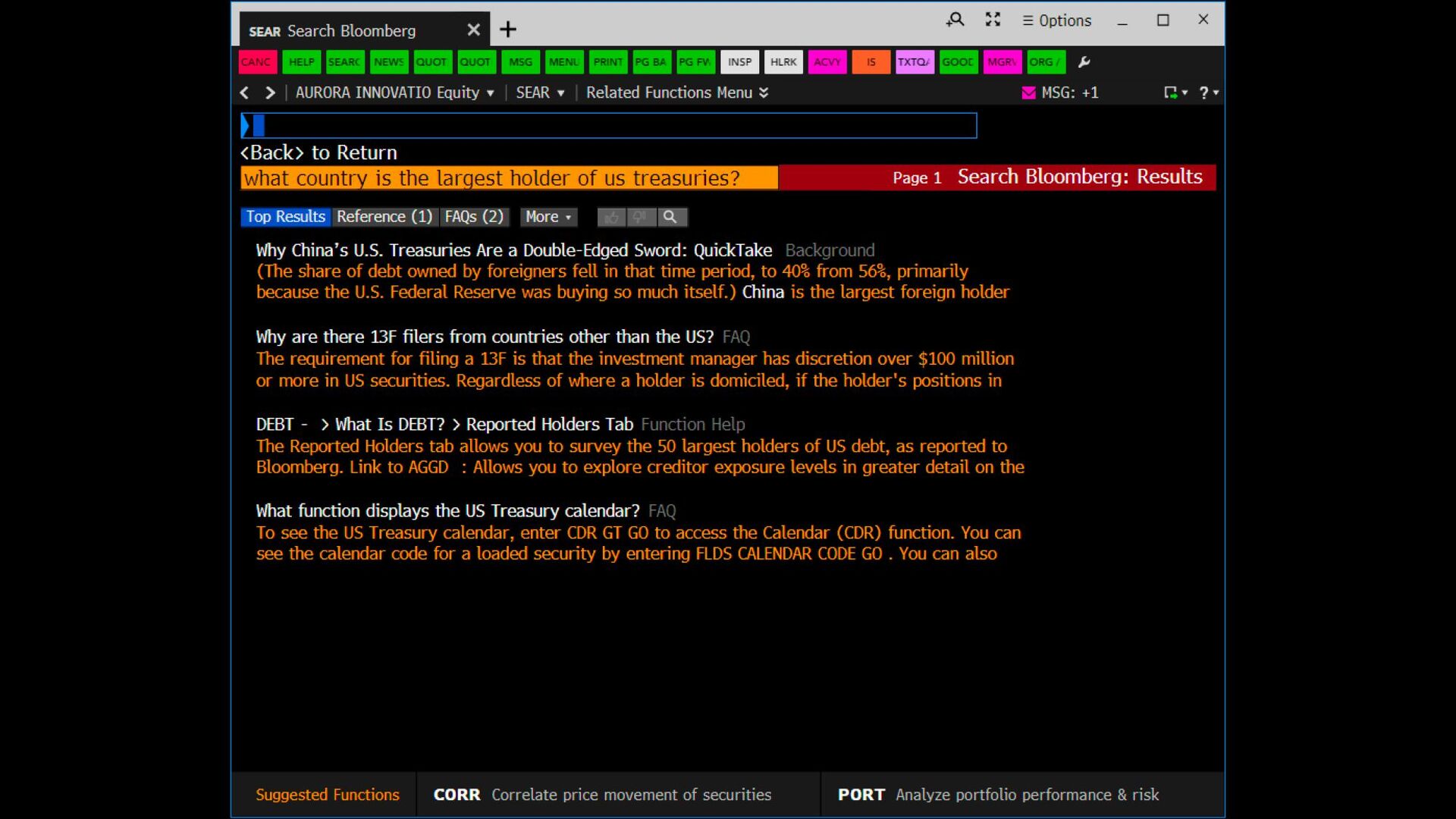
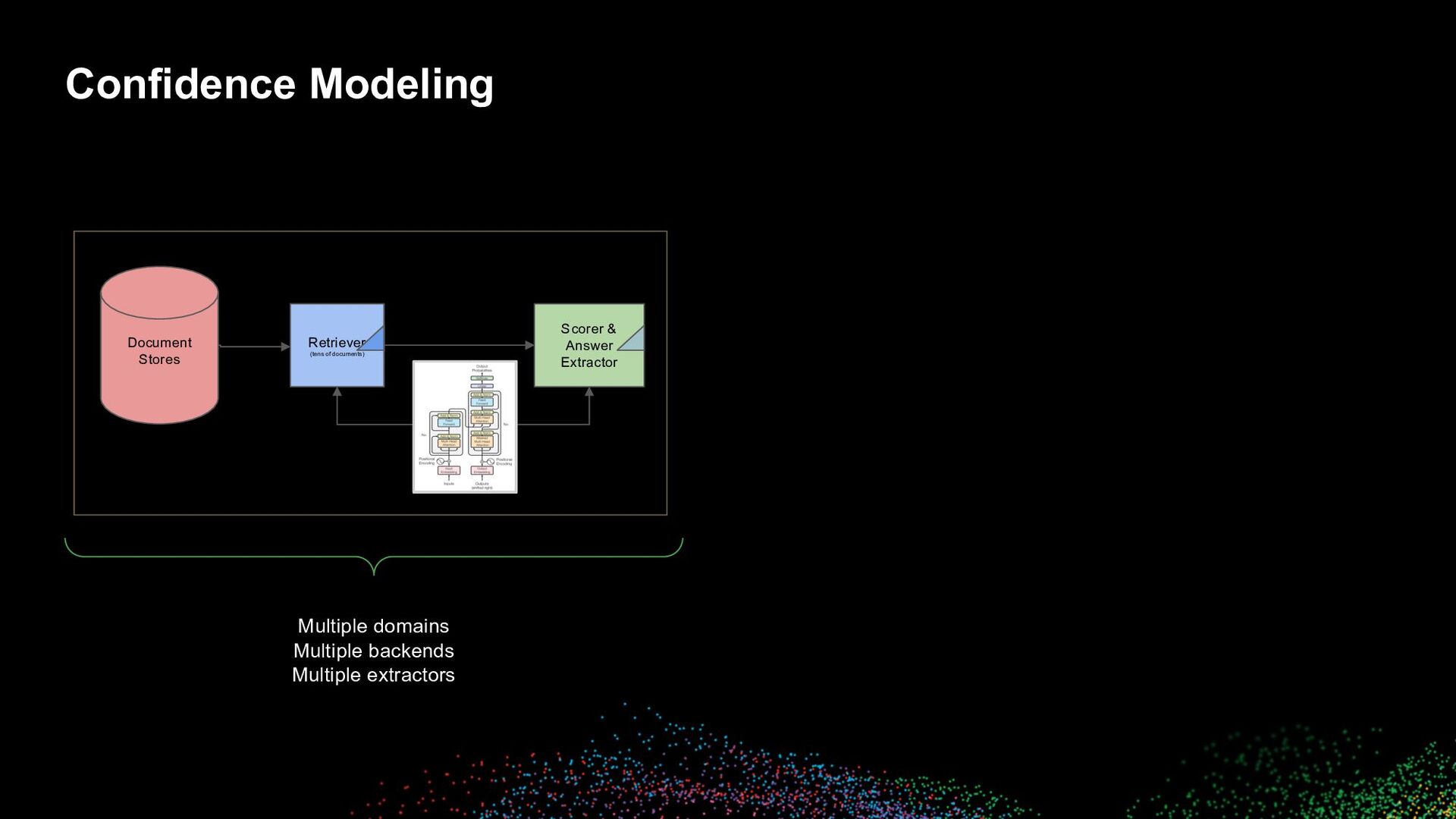
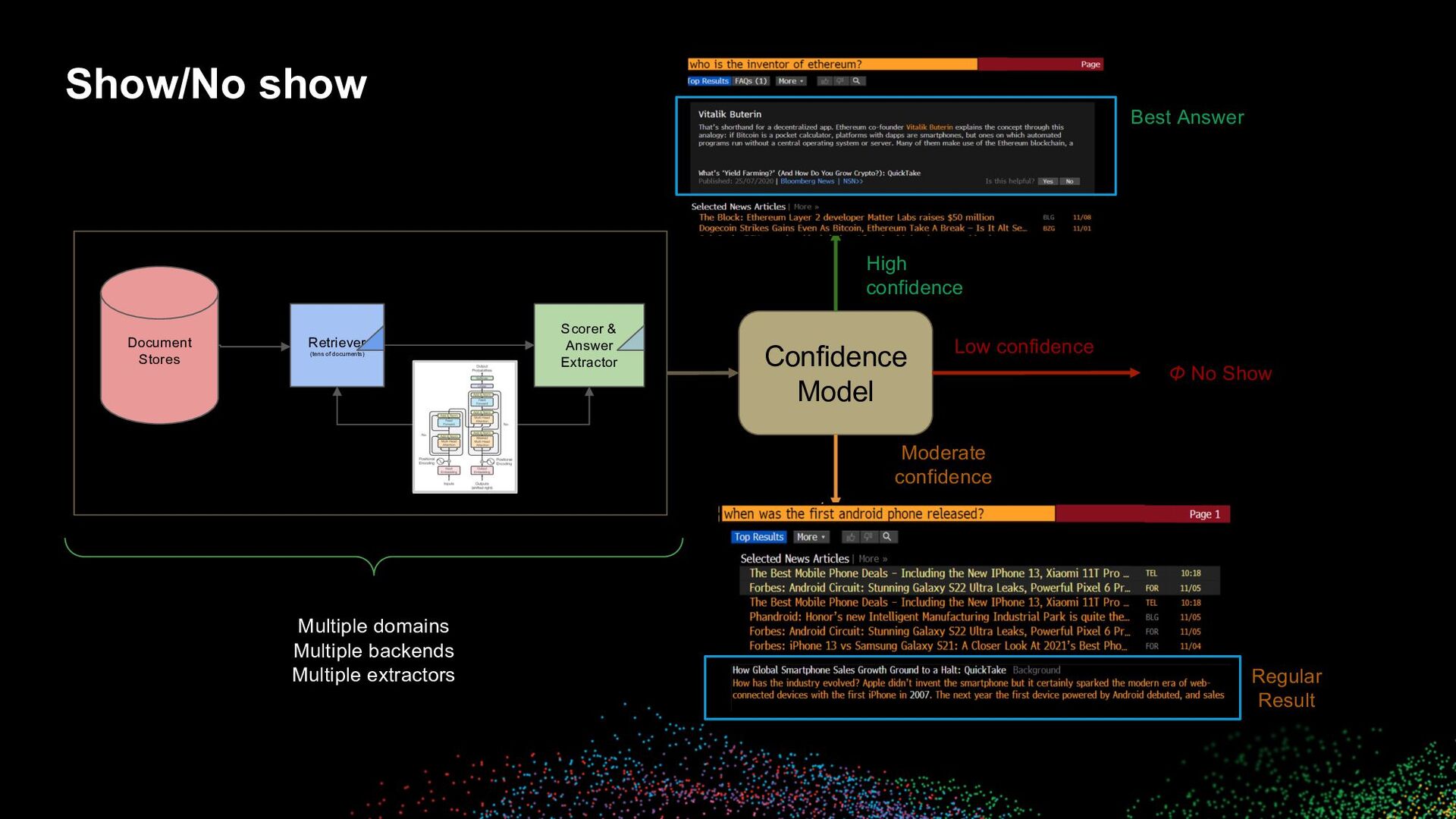
Multiple backends Multiple extractors Confidence Model High confidence Moderate confidence Regular Result Best Answer Low confidence Φ No Show TextQA Document Stores Retriever (tens of documents) Scorer & Answer Extractor Show/No show
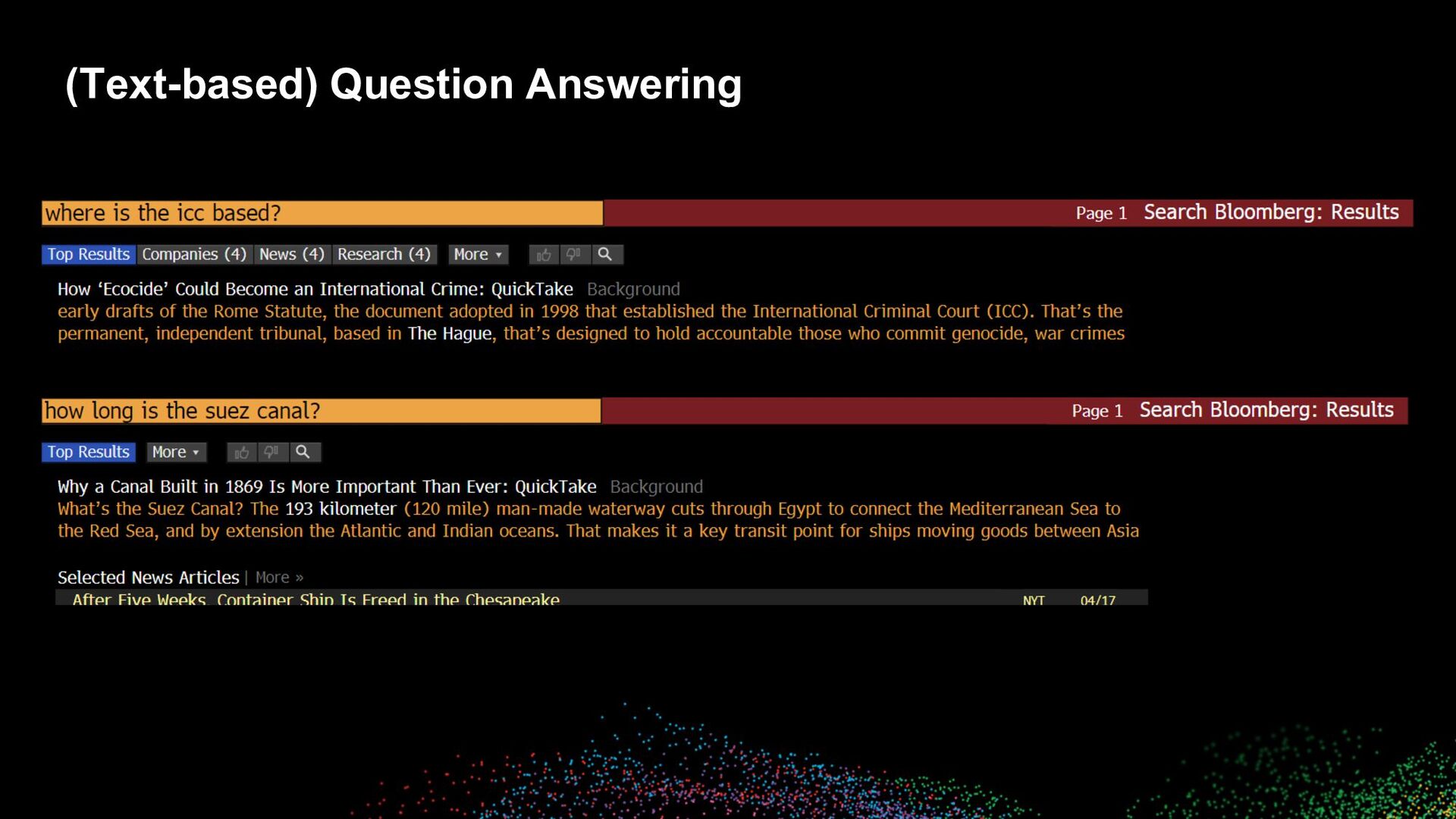
exotic examples • How much new railway development is planned in Europe? Should projects work as planned and remain on schedule, Europe could have more than 17,200 km of new and upgraded railway by 2025, out of a total planned pipeline of 39,180 km. This equates to about $97 billion of investment in 2022 and $110 billion in 2023. High-speed rail could provide about 22,500 additional km. Industrial and materials producers are closely monitoring higher demand. The U.K., France, Russia, Italy, Germany and Sweden -- where some listed construction companies operate -- are showing up with leading projects, both in execution or in the planning phase.EU governments are making significant efforts to use the co-funding available -- as much as possible -- to boost their economies. From 2000-17, Spain spent 47.3% of EU funds on high-speed rail. • When will the cruise industry return to profit? RECENT EVENT REACTION: Carnival's deflated January bookings for 2H cruises elevates our concern that the industry's targeted 2H return to profit could falter if the omicron variant's impact on sales lingers. Though Carnival expects to operate over 96% of disclosed 1Q capacity days despite virus disruption, even that shortfall could clip 1Q sales by 4% vs. consensus, our analysis shows.
many disparate units of retrieval • Search-as-a-platform • In-domain vs. cross-domain search • Domain specialists vs. novice users ◦ Aliases in-context ◦ How to quality control? • Sample live queries as much as you can
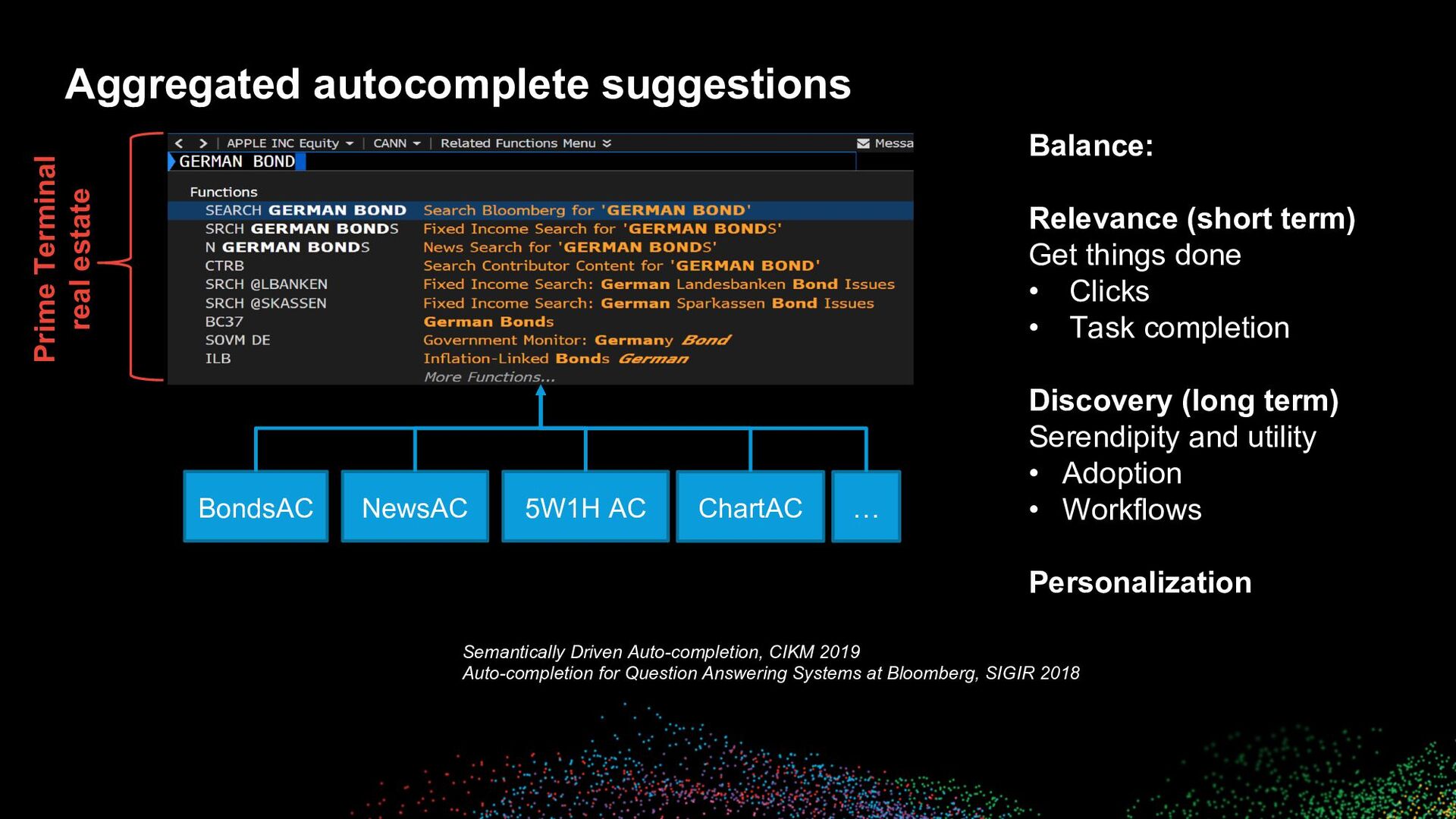
many disparate units of retrieval • Entity / Intent / Domain detection, for partial as well as for full queries ◦ In some cases NER is sufficient (when the label is unique) ◦ Typeahead prediction first, and then NER/NED on the full query instead of on partial queries seems to work better than NER/NED on partial queries • Adjust downstream ranking and presentation accordingly Identifying Named Entities as they are Typed, EACL 2021
Practice • Generation 1: Write a bunch of rules (“templates”, “grammars”) ◦ High-precision ◦ Slow, manual, difficult to maintain or update • Generation 2: Train a statistical classifier ◦ For sequence tagging: conditional random fields ◦ For document classification: logistic regression, SVMs, decision trees/random forests ◦ Need labeled data • Generation 3: Deep learning and human in the loop ◦ Need a lot of labeled data, or distant supervision ◦ May be slower
• How to train LTR models with (i) limited amounts of (ii) weakly supervised data? ◦ System bias: only feedback on seen items ◦ What if you don’t have that many users? ◦ What if you have cohorts with outliers/different behaviours? • Cold-start issues around sampling questions from logs for training ◦ If users don’t know they can ask questions they probably won’t ◦ Generate + paraphrase questions instead Novelty Controlled Paraphrase Generation with Retrieval Augmented Conditional Prompt Tuning, AAAI 2022
• How to deal with annotations/relevance assessments that change/decay over time? ◦ Developments in the real world ◦ Timeliness of answers, stale answers, expiring answers ◦ Temporally-anchored answers • Need online metrics, ability to blocklist, continuous (re)training
• In industry, no model is static ◦ New entities, new vocabulary, new contexts, new relationships, new data, etc. • Humans in the loop ◦ To generate questions, to annotate results, to judge relevance ◦ Help prevent model drift and ameliorate lack of recall, precision ◦ Provide important training data • “Automation is augmentation, not replacement” ◦ Need effective, easy to use tools for humans to work with algorithms
• Interpretability, explainability • Regulatory / compliance ◦ Data permissioning: per-role/per-person ◦ On-/Off-prem data storage, compute ◦ Encrypting data at-rest and in-transfer ◦ Private data flows, separated networks ◦ Right to be forgotten
• Buy vs. build: invest in resources and build from scratch, partner with vendor(s), or look at (and potentially improve) open source? ◦ Type of problem, type of data ◦ Where is the “alpha”? ◦ Accuracy ◦ Transparency ◦ Customization ◦ Maintenance, ease adding more/different data ◦ Time to market ◦ Privacy/Regulatory concerns ◦ Cost
• Being dependent on a (search) stack ◦ Elastic? Solr? ◦ Migrations, removing tech debt ◦ Patching up old systems or redesigning? ◦ Second stage re-ranker in-/outside of Solr • Legacy systems and patchwork processes ◦ Allocate time to disentangle and move to modern platforms and architectures
Search at Bloomberg: making structured and unstructured data machine- readable, human-interpretable, discoverable, and findable ◦ At scale with high accuracy and low latency, to enable swift and effective financial decision-making • Deliver value by pushing the state-of-the-art through applied research ◦ Address challenges encountered in “production” scenarios (cold-start issues, confidence modeling, partially observed behavior, system-induced biases, and more) ◦ Validation through scientific peer review, open source contributions • Generate data and perform continuous annotations/training with a human-in- the-loop, to address (some of) these issues
Bloomberg Finance L.P. All rights reserved. https://TechAtBloomberg.com/AI https://TechAtBloomberg.com/data-science-research-grant-program/ https://www.bloomberg.com/careers @edgarmeij | [email protected] Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}