Bloomberg Finance L.P. All rights reserved. Modernizing Search: Aligning Systems with Users and Current Trends EG Intelligence Conference 2023 Keynote September 14, 2023 Edgar Meij, Ph.D. Head of AI Search and Discovery @edgarmeij | [email protected]
just finance, right? • A technology company founded in New York City in 1981 • 350,000+ subscribers in 170 countries • Over 21,000 employees in 159 locations, including over 8,000 software engineers – with more than 250 engineers and data scientists working on AI and related problems • Increased use of and contributions to open source software • Increased presence in academic research
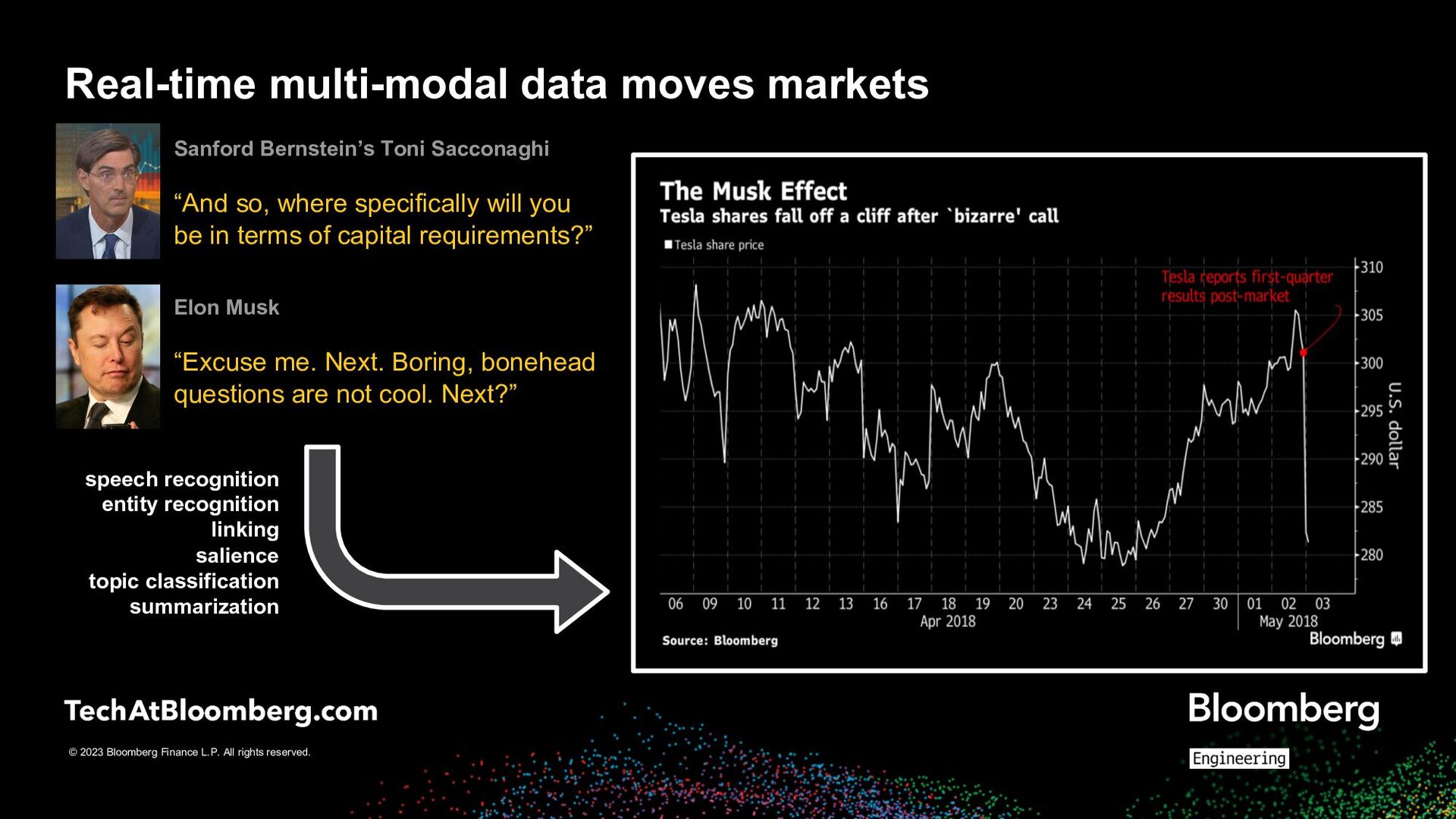
Toni Sacconaghi “And so, where specifically will you be in terms of capital requirements?” Real-time multi-modal data moves markets speech recognition entity recognition linking salience topic classification summarization Elon Musk “Excuse me. Next. Boring, bonehead questions are not cool. Next?”
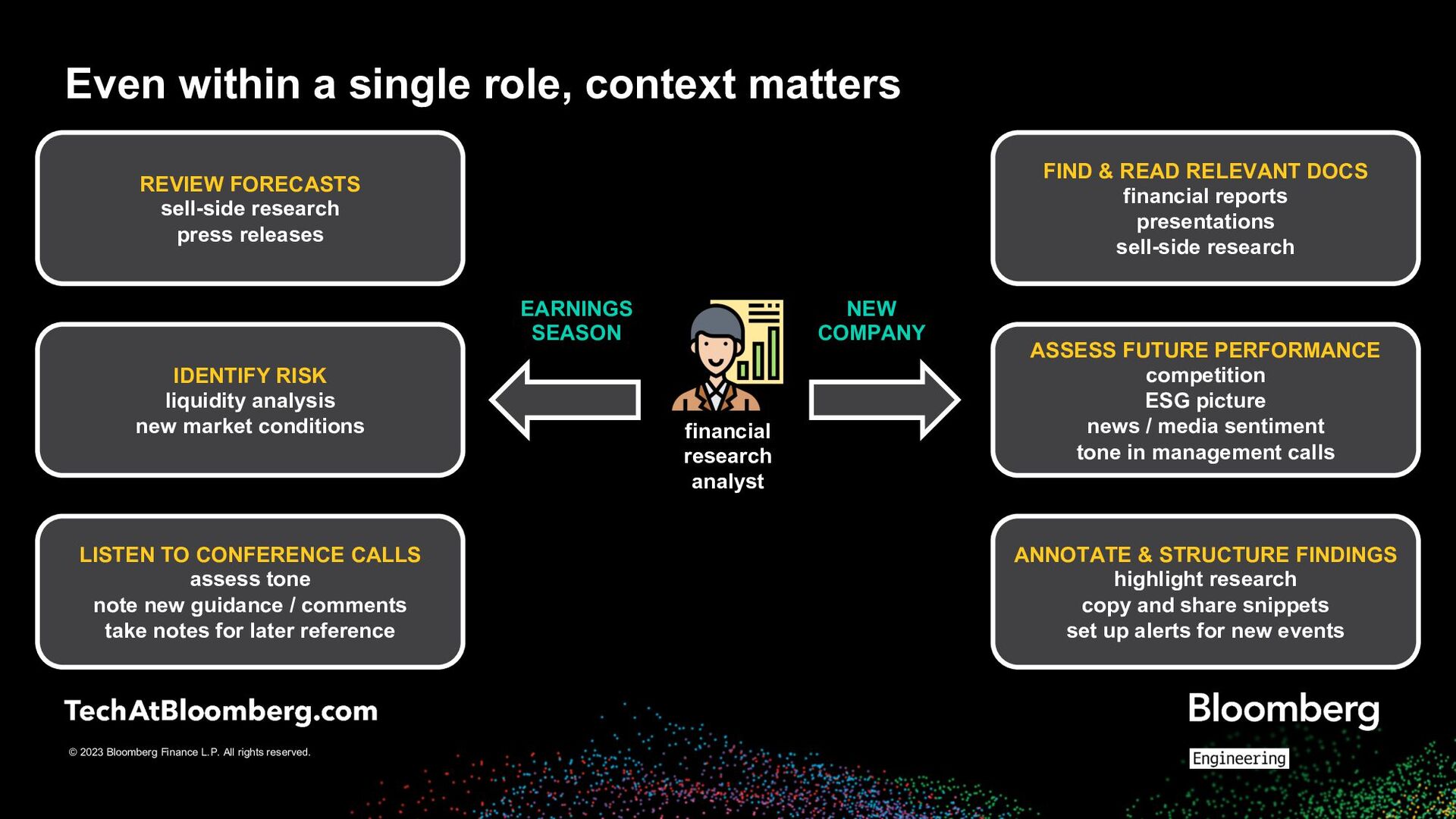
a single role, context matters financial research analyst REVIEW FORECASTS sell-side research press releases IDENTIFY RISK liquidity analysis new market conditions LISTEN TO CONFERENCE CALLS assess tone note new guidance / comments take notes for later reference FIND & READ RELEVANT DOCS financial reports presentations sell-side research ASSESS FUTURE PERFORMANCE competition ESG picture news / media sentiment tone in management calls ANNOTATE & STRUCTURE FINDINGS highlight research copy and share snippets set up alerts for new events EARNINGS SEASON NEW COMPANY
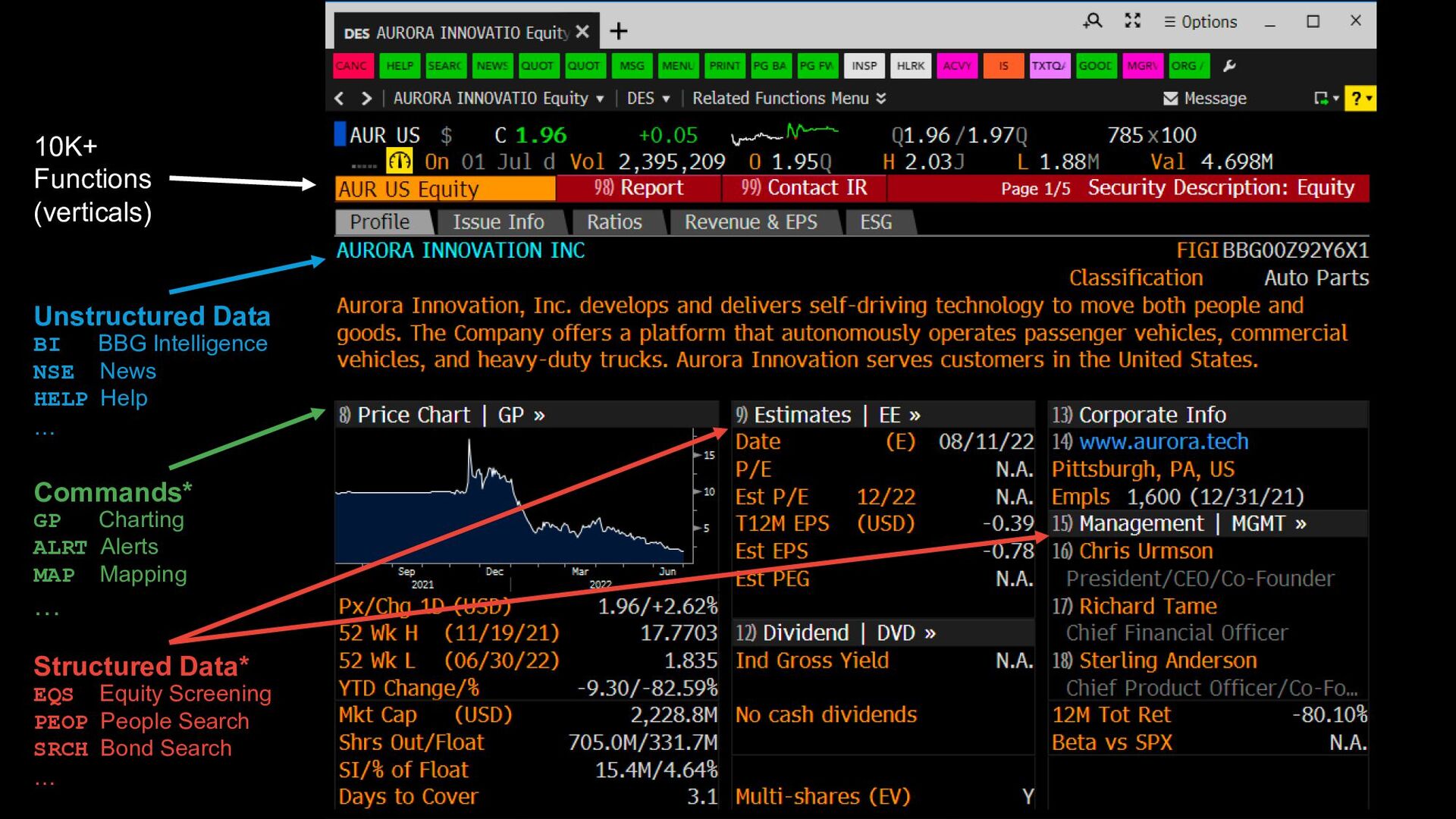
• Most of our clients use the Terminal in their day-to-day workflows to: ◦ Trade ◦ Spot inefficiencies/opportunities in the market ◦ Find signal ◦ Keep abreast of developments ◦ etc. • Deeply-engrained muscle memory for executing Bloomberg functions • Limited room for “discovery”
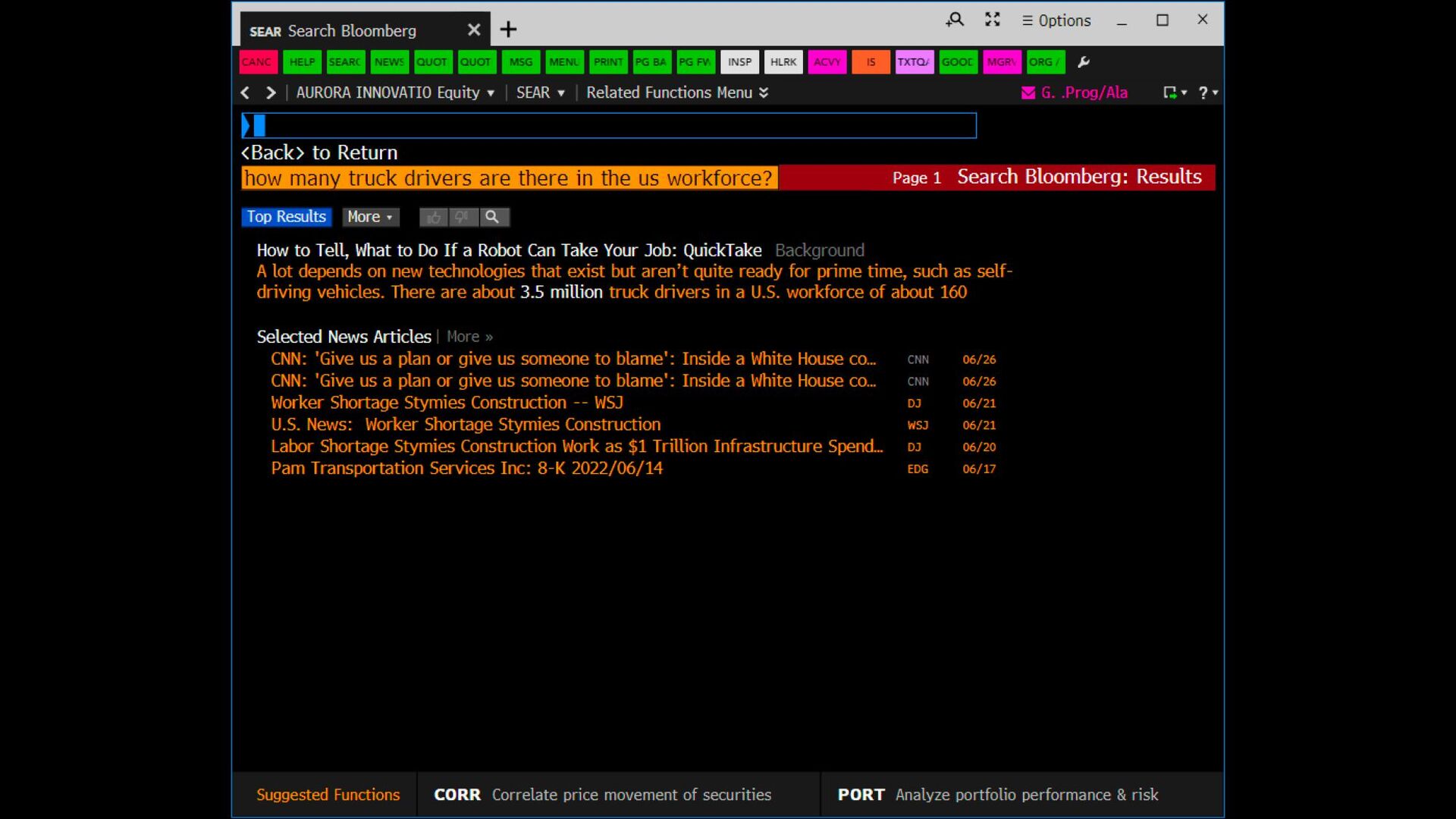
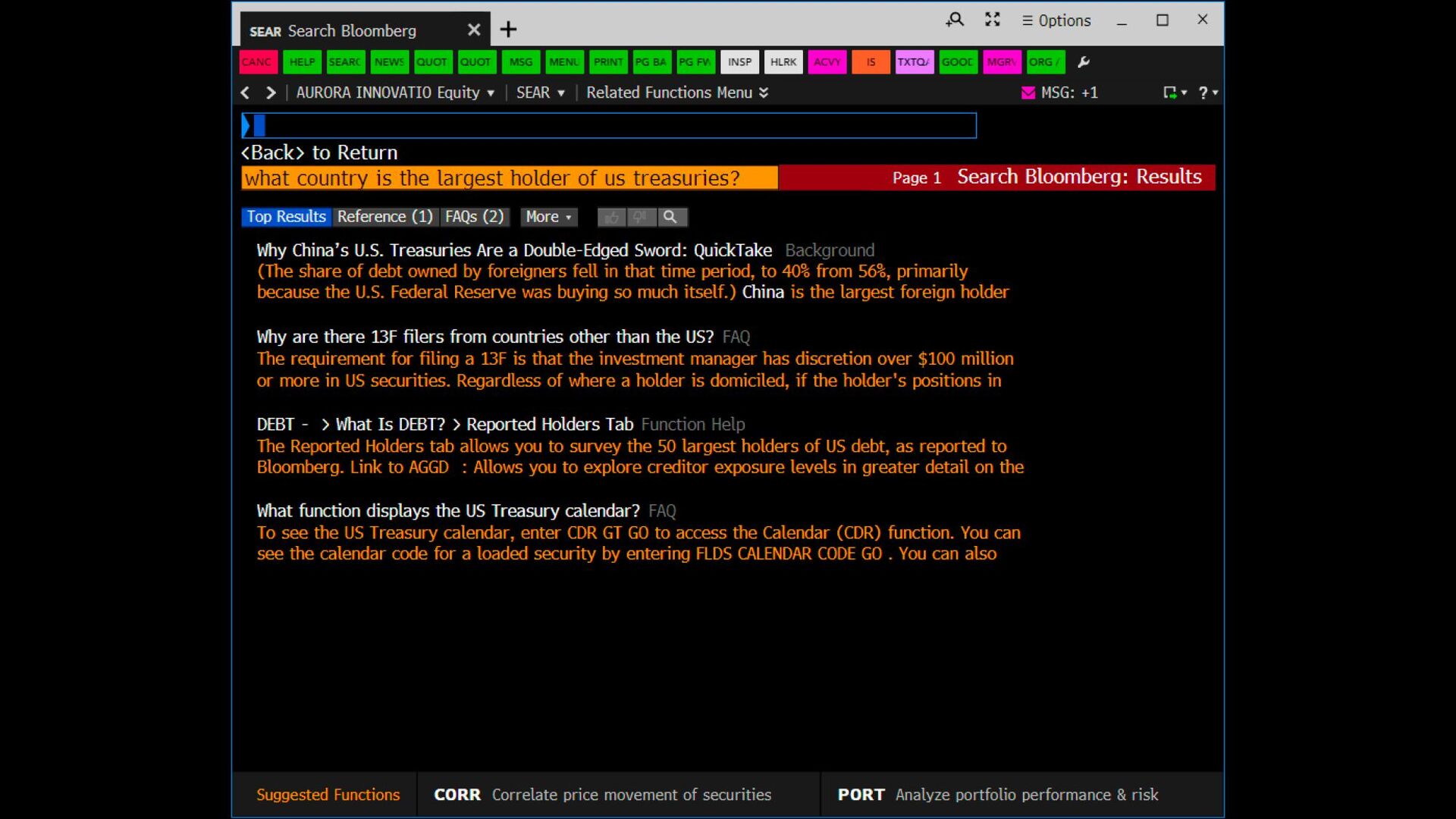
many disparate units of retrieval • Many disparate sources ◦ Some indexed by us ◦ Some indexed by others/owners • How do you normalize scores for results from different back-ends, and then merge and present a single list? ◦ Account for different “document” lengths and collection statistics ◦ Account for different “document” fields ◦ Account for multiple languages ◦ Account for multiple ranking functions ◦ Account for different, perhaps non-comparable scores
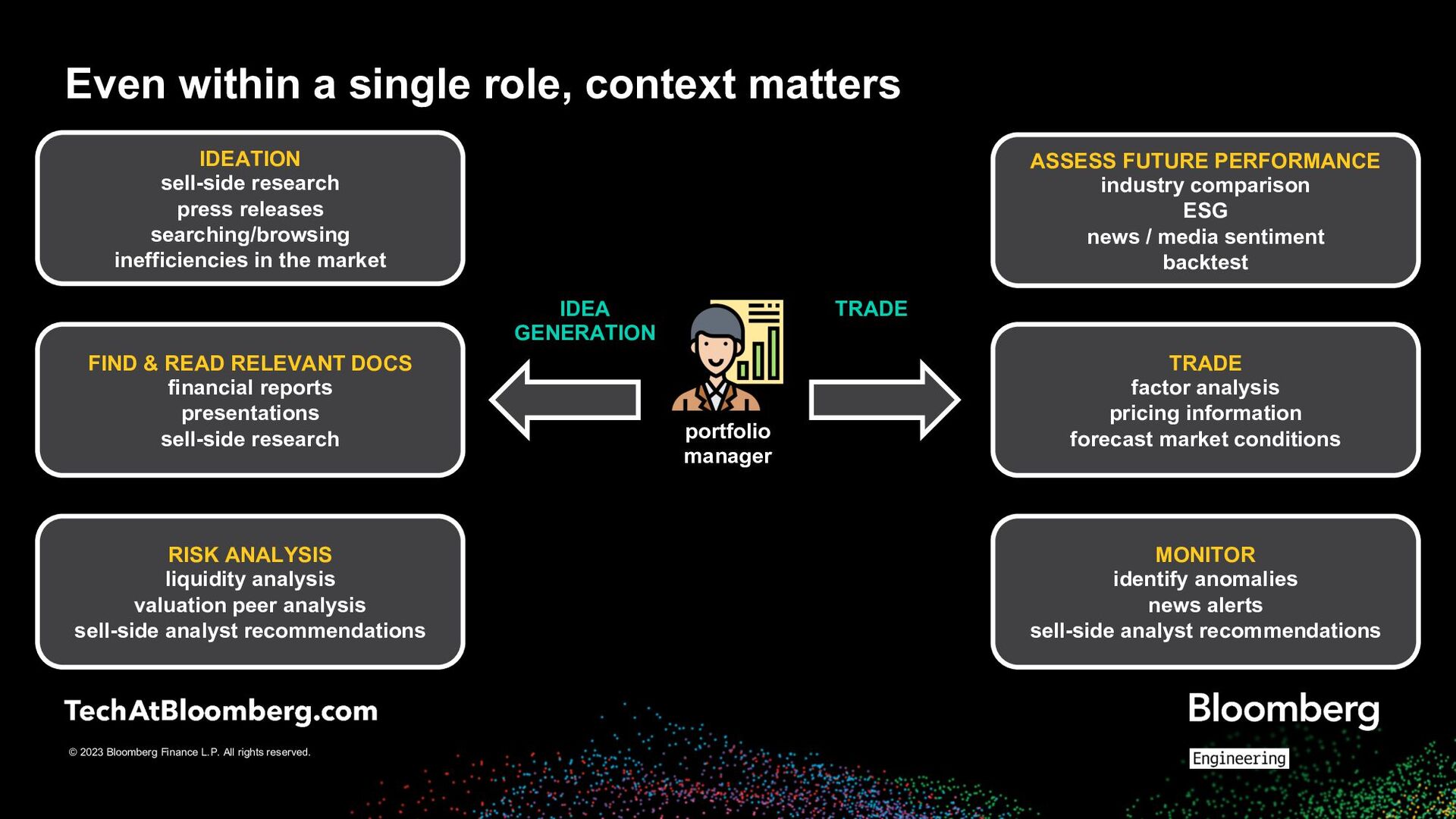
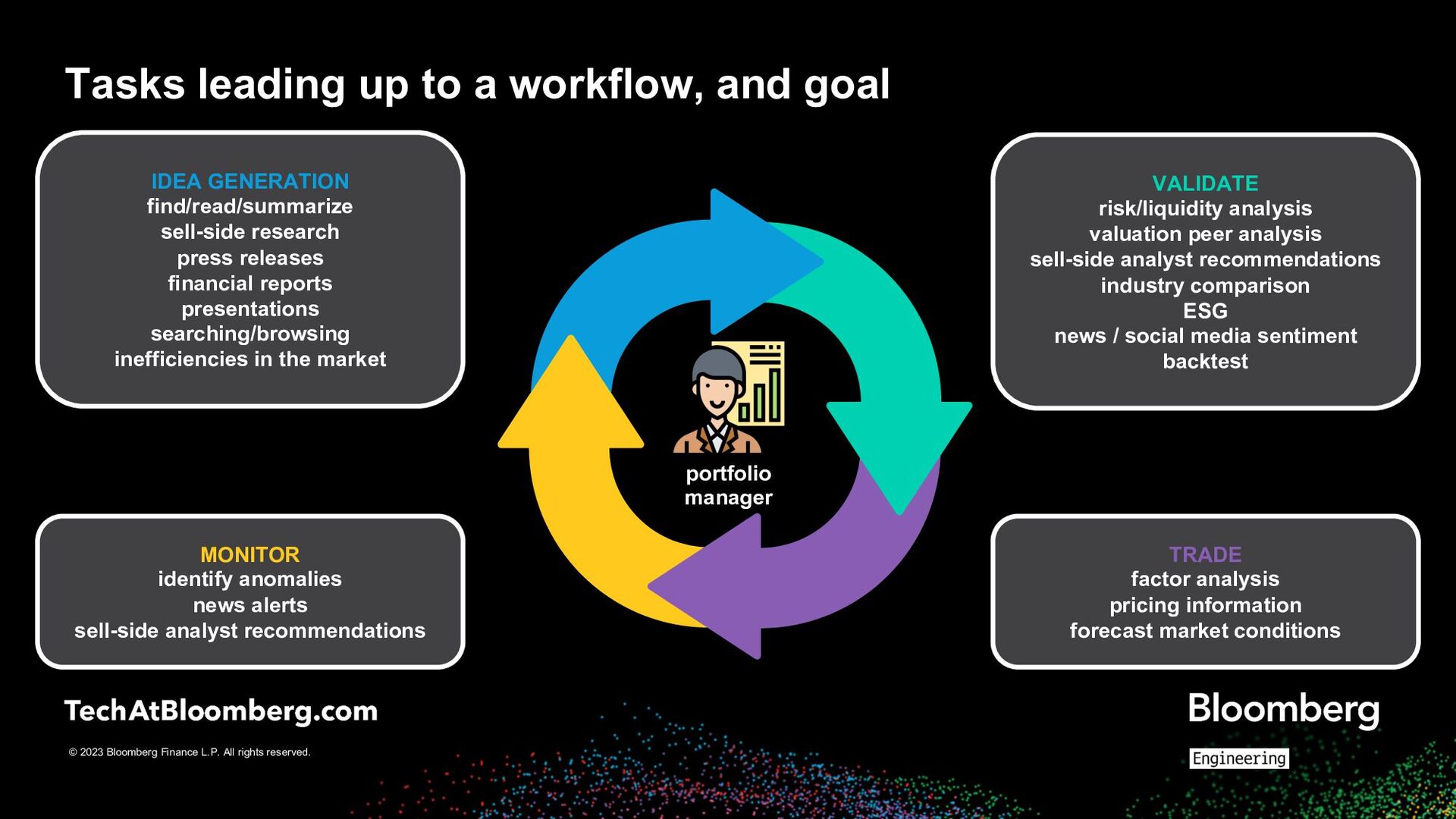
up to a workflow, and goal portfolio manager IDEA GENERATION find/read/summarize sell-side research press releases financial reports presentations searching/browsing inefficiencies in the market MONITOR identify anomalies news alerts sell-side analyst recommendations VALIDATE risk/liquidity analysis valuation peer analysis sell-side analyst recommendations industry comparison ESG news / social media sentiment backtest TRADE factor analysis pricing information forecast market conditions
tasks and workflows, and their struggles • Gather, analyze, and contextualize data • Talk to your users ◦ Ask for feedback ◦ Discuss product improvements, ask what they are doing when they thought of an improvement • What are the end-to-end tasks they are looking to solve? ◦ Why are they using your system? Do they come back for more? If not, why not? • Mockups and prototyping • Experimentation (usability testing, A/B tests)
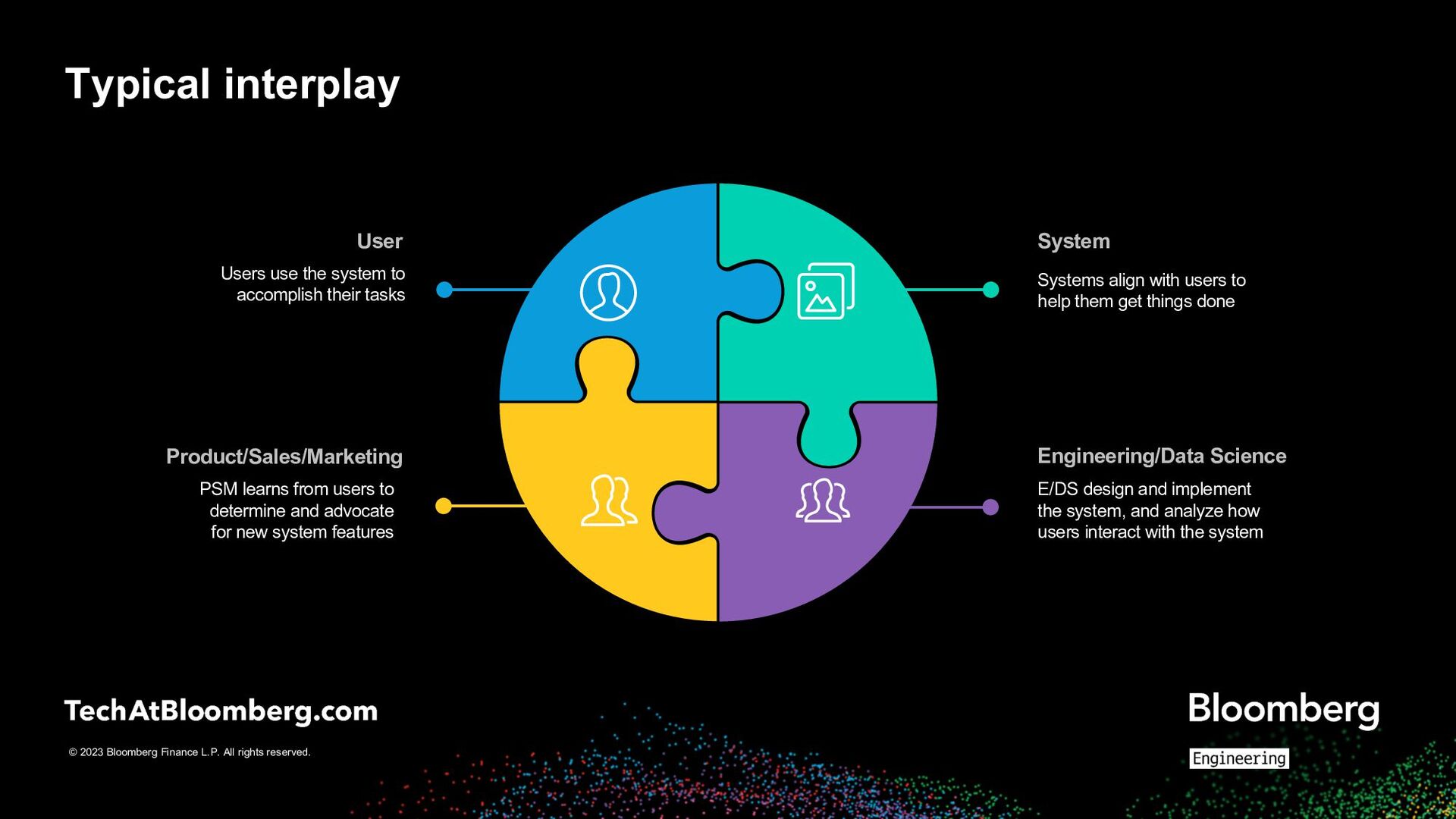
System Engineering/Data Science Users use the system to accomplish their tasks PSM learns from users to determine and advocate for new system features E/DS design and implement the system, and analyze how users interact with the system Systems align with users to help them get things done Typical interplay
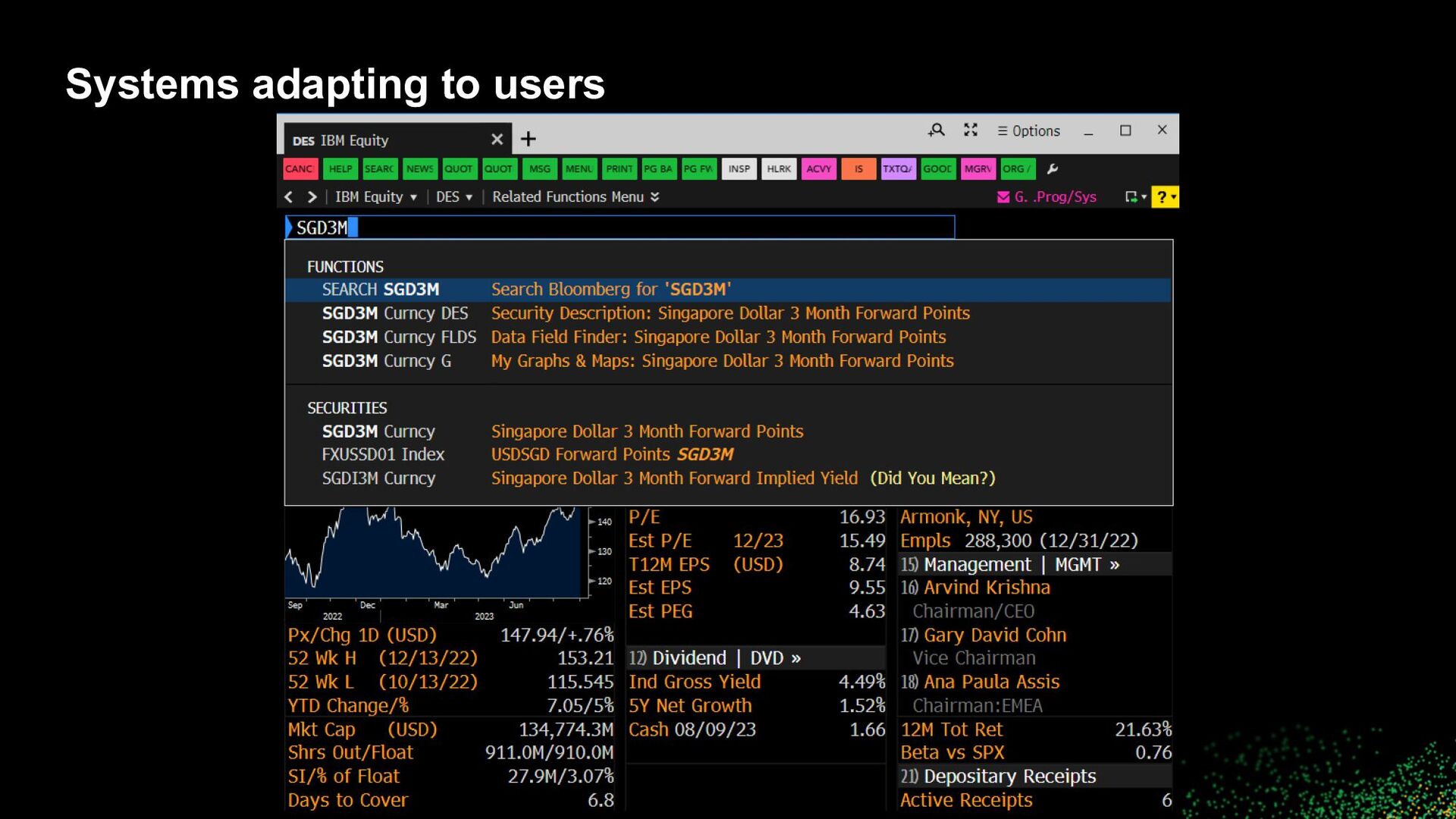
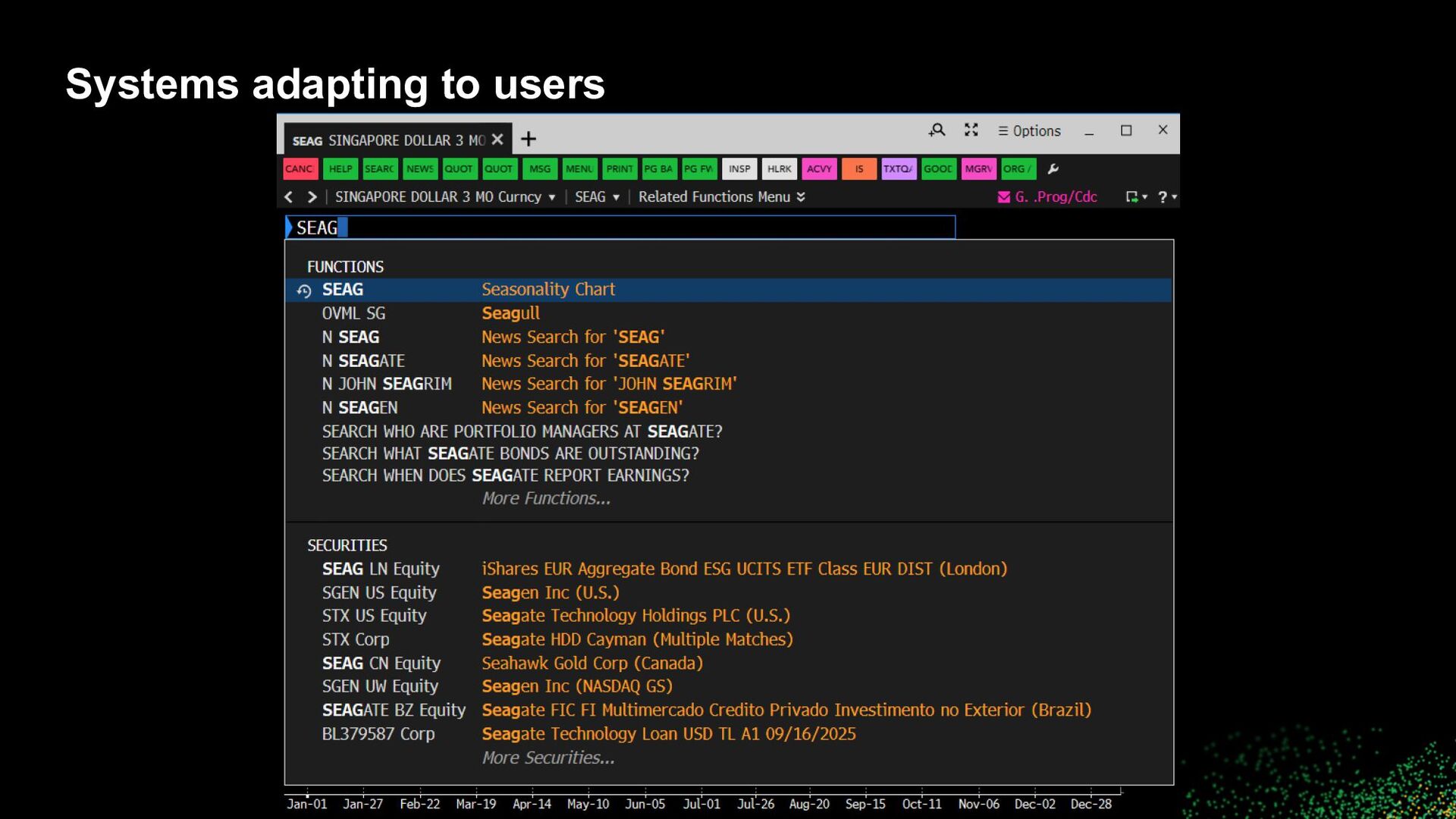
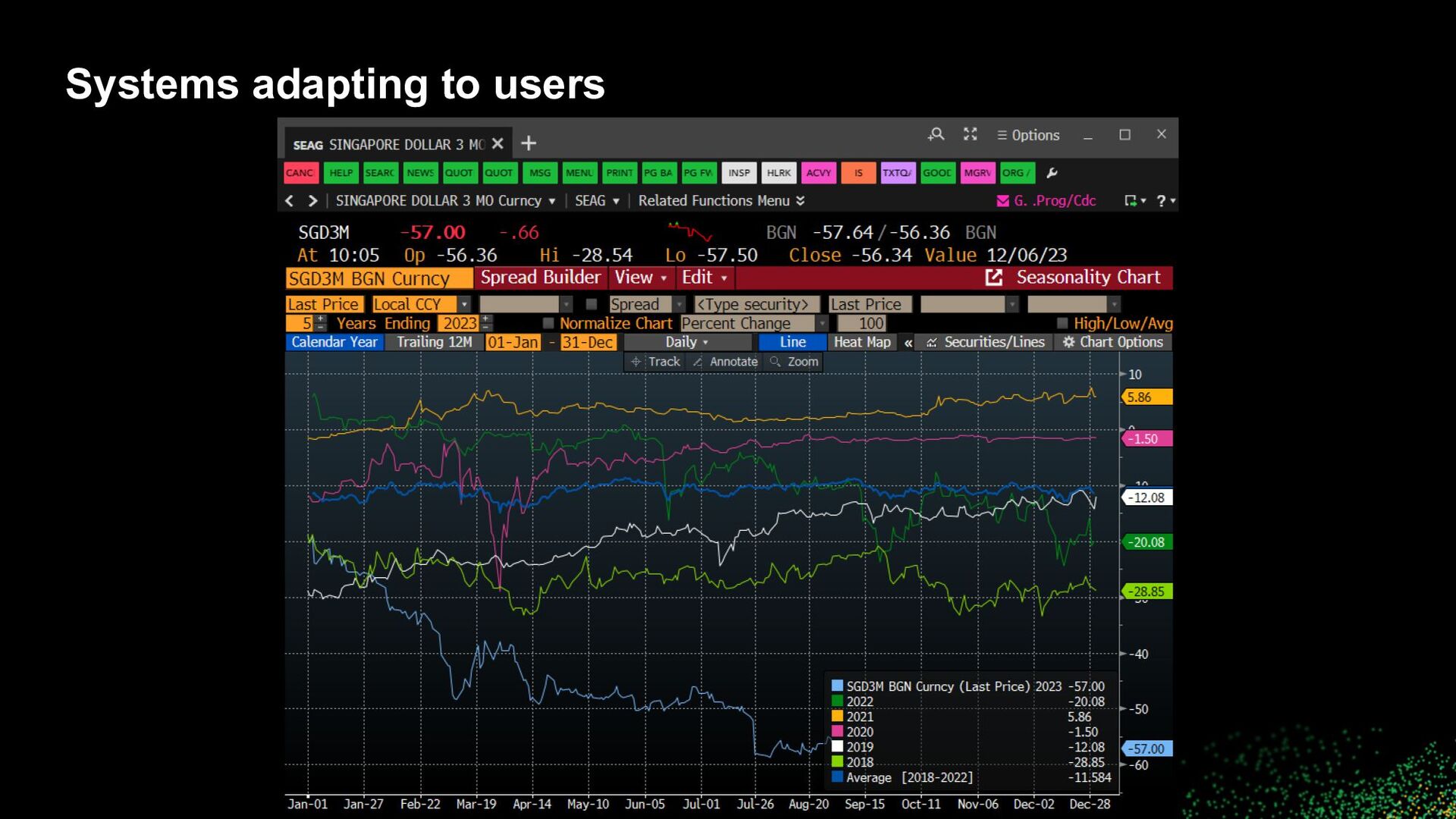
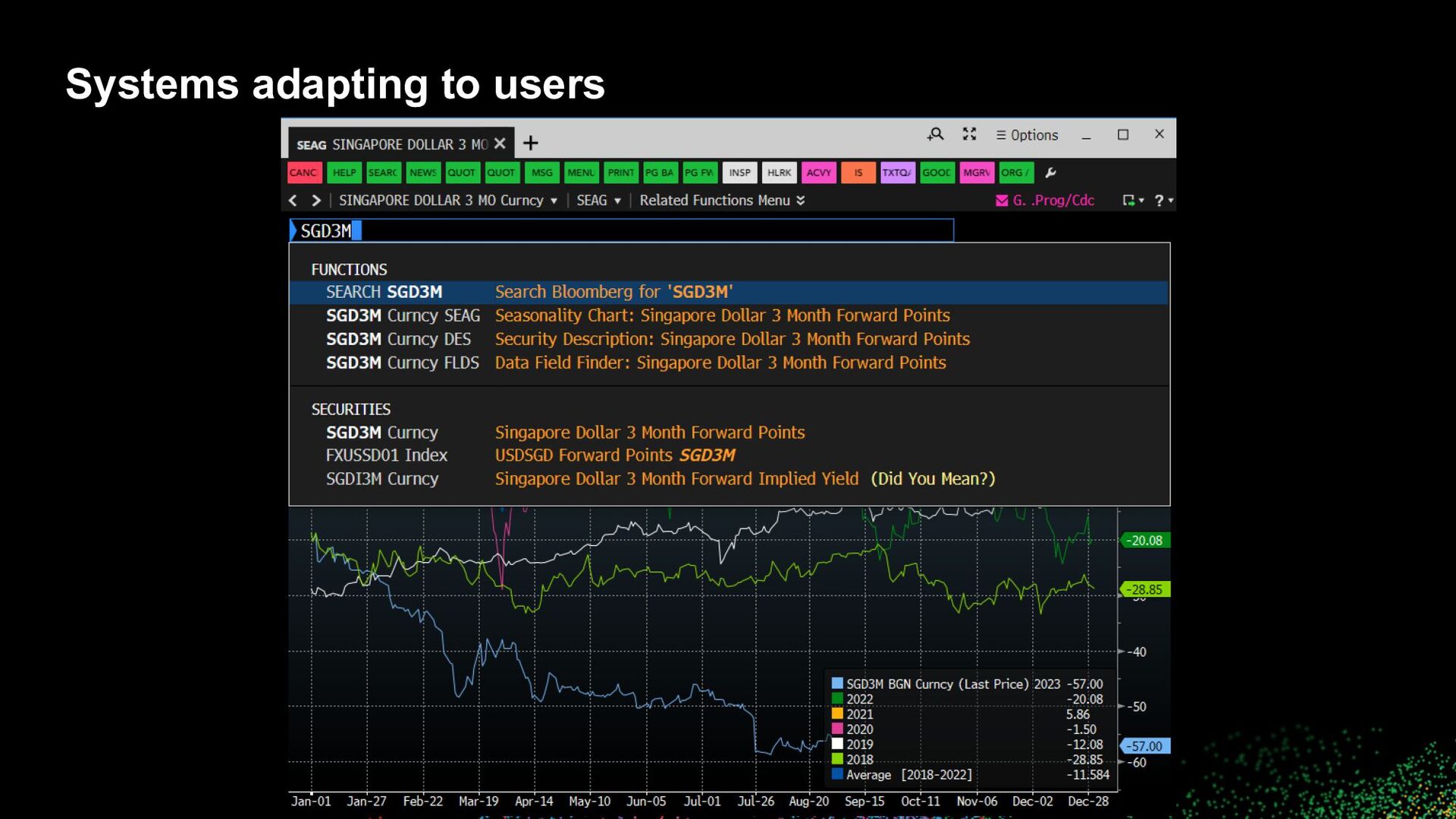
to users • How can “a system” better align to a user? ◦ Personalization ◦ Improved UI ◦ Suggestions and recommendations ◦ ML / Learning to rank ▪ Use features to encode business logic and explicit signals (likes, ratings, shares) ▪ Weave in implicit signals (clicks, dwell time) ▪ How to incorporate negative feedback (skips, dislikes)? ▪ How to scale? • Reinforcement learning in extremely large action spaces with >millions of items and >millions of users ▪ How to address cold start issues?
to users • Align results, suggestions, recommendations with user workflows and (constituent) tasks • Leverage all contextual information available ◦ Previous searches, clicks, purchases, etc. ◦ Current searches, clicks, purchases, etc. ◦ Profile information, demographics ◦ Cohort information ◦ World information, seasonality
Practice • Generation 1: Write a bunch of rules (“templates”, “grammars”) ◦ High-precision ◦ Slow, manual, difficult to maintain or update • Generation 2: Train a statistical classifier ◦ For sequence tagging: conditional random fields ◦ For document classification: logistic regression, SVMs, decision trees/random forests ◦ Need labeled data • Generation 3: Deep learning and human in the loop ◦ Need a lot of labeled data, or distant supervision ◦ May be slower
• How to train LTR models with (i) limited amounts of (ii) weakly supervised data? ◦ System bias: only feedback on seen items ◦ What if you don’t have that many users? ◦ What if you have cohorts with outliers/different behaviours? • Cold-start issues around sampling questions from logs for training ◦ If users don’t know they can ask questions they probably won’t ◦ Generate + paraphrase questions instead ü Novelty Controlled Paraphrase Generation with Retrieval Augmented Conditional Prompt Tuning, AAAI 2022
• How to deal with annotations/relevance assessments that change/decay over time? ◦ Developments in the real world ◦ Timeliness of answers, stale answers, expiring answers ◦ Temporally-anchored answers • Need online metrics, ability to blocklist, continuous (re)training
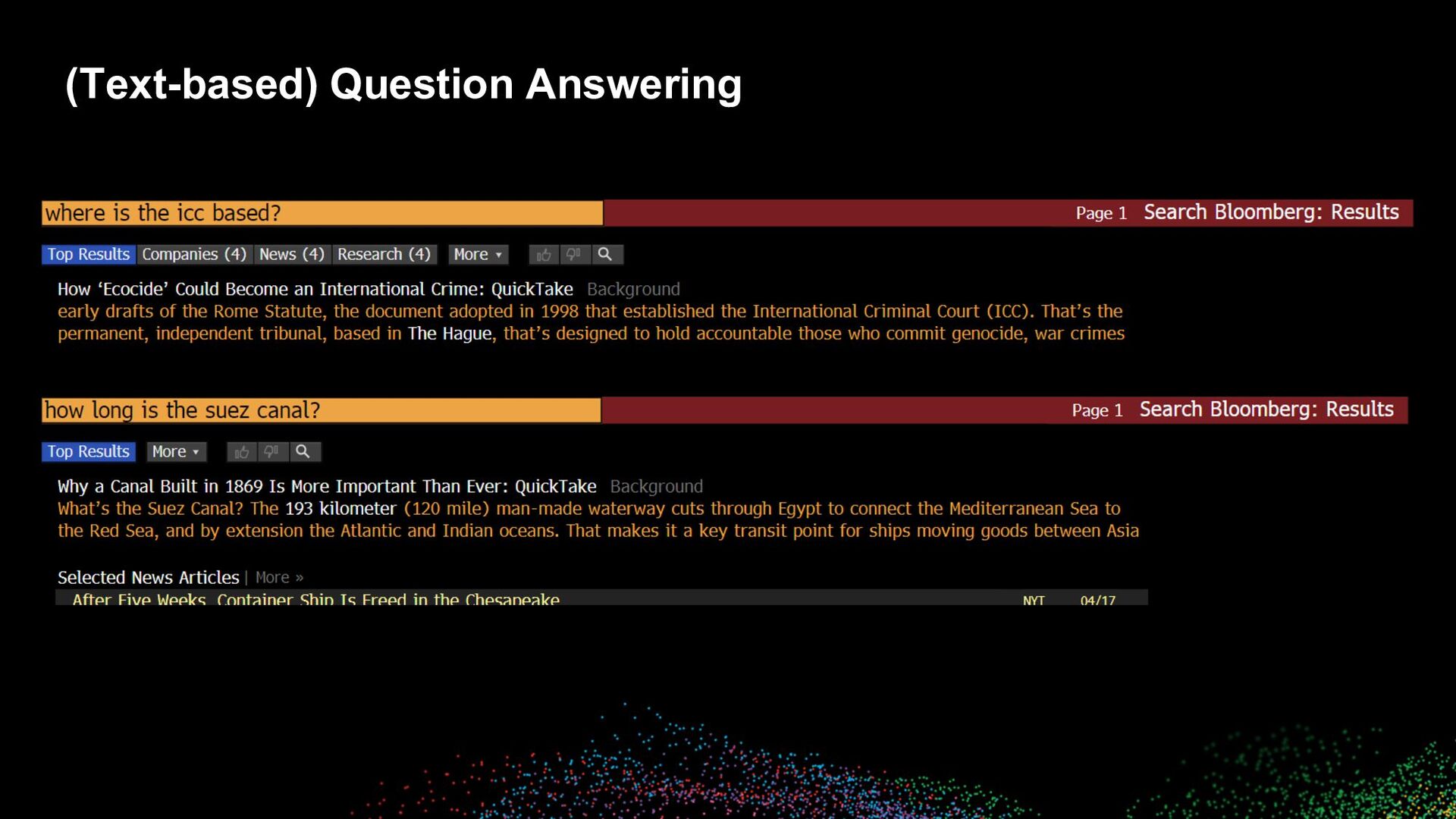
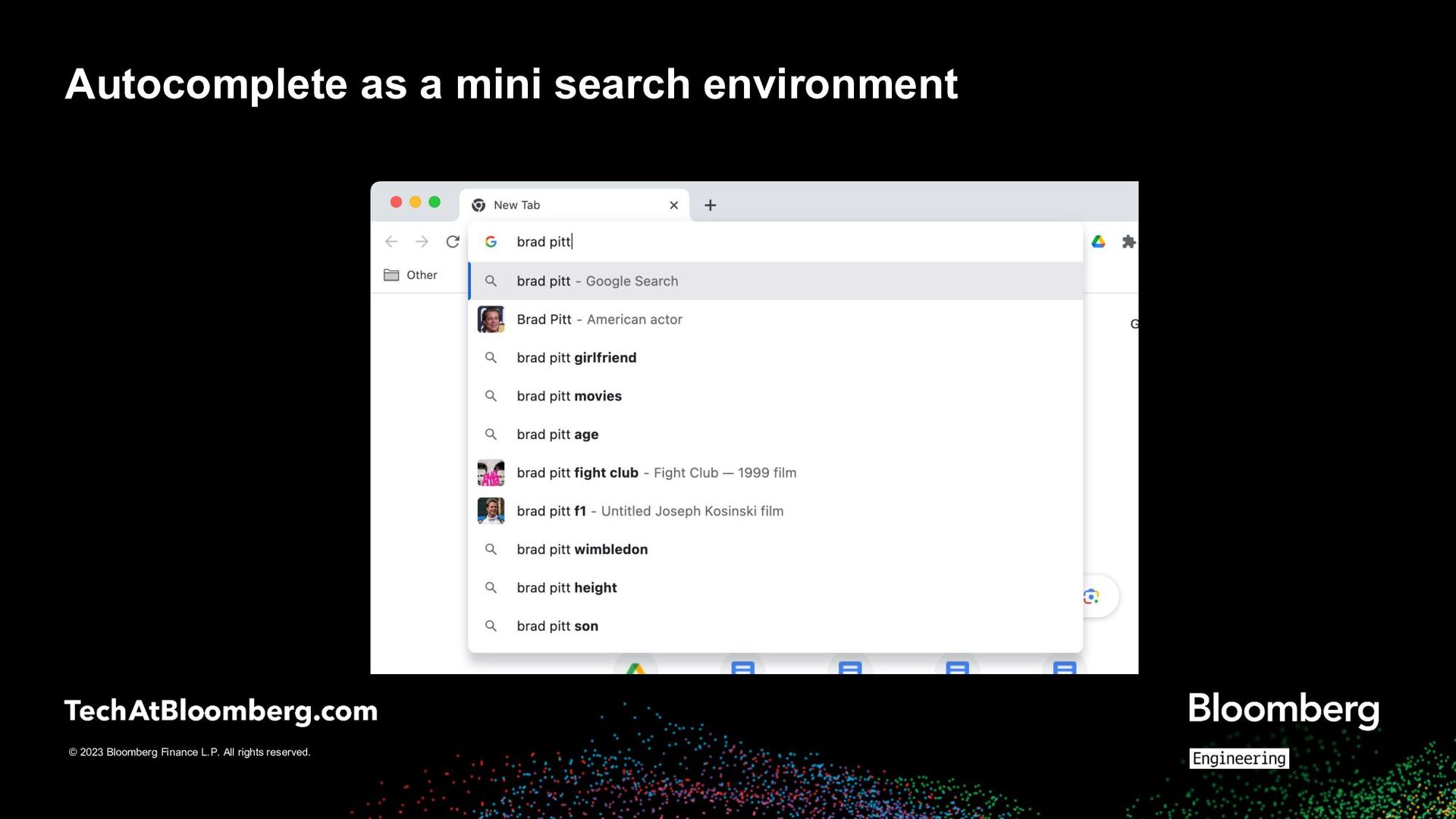
How do users learn what the system can do/support? ◦ Through marketing, advertising, word of mouth ◦ By trying out things ◦ Through suggestions and recommendations • Main flavors ◦ Without a query present ▪ navigation, recsys, editorial/trending suggestions ◦ With a (partial) query present ▪ autocomplete, query/entity/other suggestions ◦ With a query and results present ▪ query/entity/other suggestions ◦ With a query and results and interactions present ▪ query/entity/other suggestions
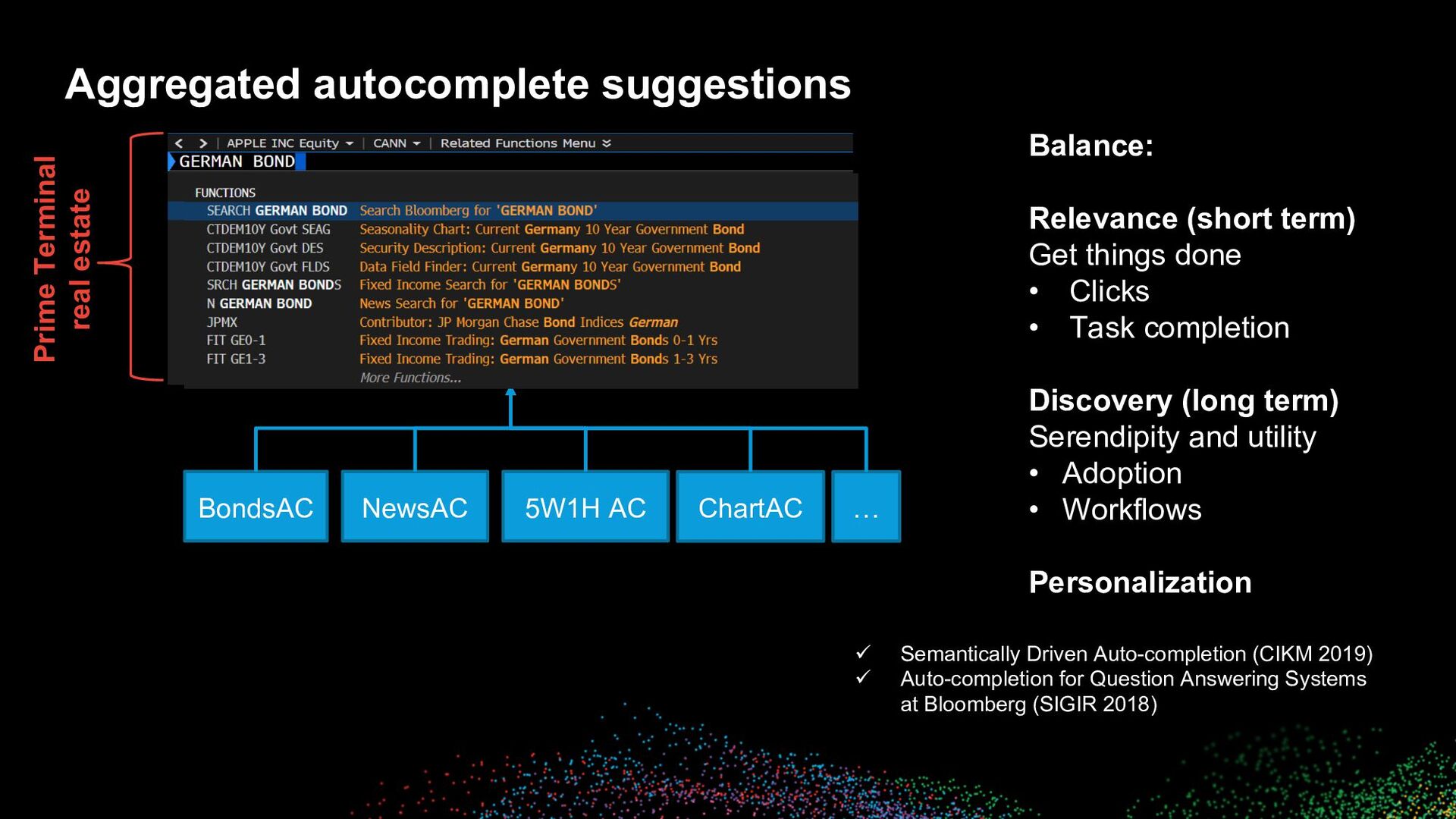
suggestions Prime Terminal real estate BondsAC NewsAC 5W1H AC ChartAC … Balance: Relevance (short term) Get things done • Clicks • Task completion Discovery (long term) Serendipity and utility • Adoption • Workflows Personalization ü Semantically Driven Auto-completion (CIKM 2019) ü Auto-completion for Question Answering Systems at Bloomberg (SIGIR 2018)
ML, bias/fairness • Typical ways of gauging fairness ◦ Equal treatment: metric scores are the same for all groups ◦ Equality of outcomes: predictions are aligned with groups • How to translate to search rankings? • How to interpret clicks? • How to incorporate rank/presentation bias?
retrievers • Combining keyword-based matching (“sparse retrieval”) with approximate nearest neighbor search (“dense retrieval”) ◦ Reranking ◦ Score merging ◦ Cross-encoders, ColBERT • Aim is to improve recall whilst keeping a handle on precision • *Many* open source frameworks available, including Apache Solr 9 / Elasticsearch 8 / Weaviate / etc. ◦ Choice of encoder is critical, as is finetuning it for a specific domain, task, and/or vocabulary ü Vector Search with OpenAI Embeddings: Lucene Is All You Need (2023)
• Being dependent on a (search) stack ◦ Elastic? Solr? ◦ Migrations, removing tech debt ◦ Patching up old systems or redesigning? ◦ Second stage re-ranker in-/outside of Solr • Legacy systems and patchwork processes ◦ Allocate time to disentangle and move to modern platforms and architectures
• In industry, no model is static ◦ New entities, new vocabulary, new contexts, new relationships, new data, etc. • Humans in the loop ◦ To generate questions, to annotate results, to judge relevance ◦ Help prevent model drift and ameliorate lack of recall, precision ◦ Provide important training data • “Automation is augmentation, not replacement” ◦ Need effective, easy to use tools for humans to work with algorithms
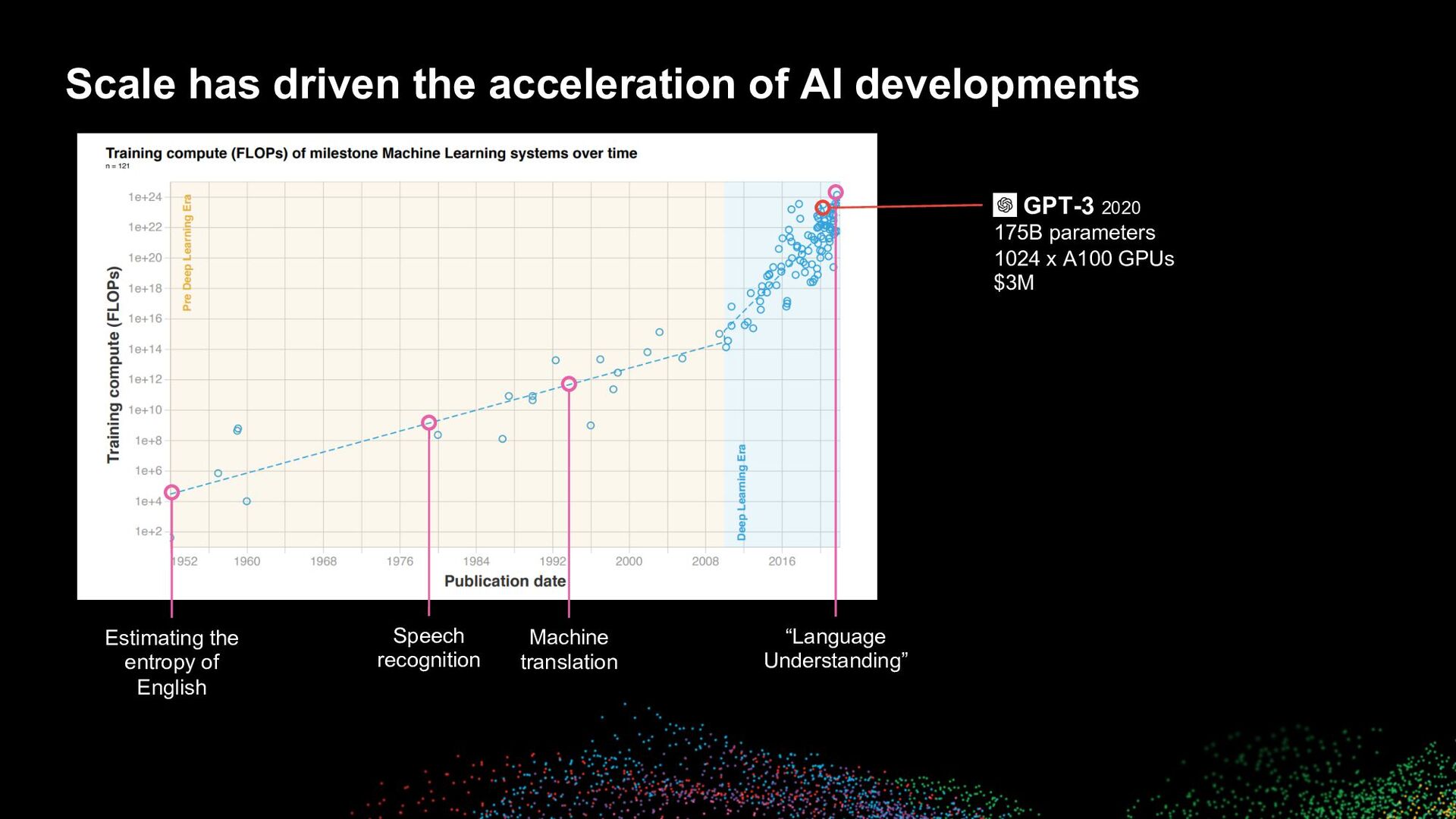
driven the acceleration of AI developments “Language Understanding” Machine translation Speech recognition Estimating the entropy of English GPT-3 2020 175B parameters 1024 x A100 GPUs $3M
• Buy vs. build: invest in resources and build from scratch, partner with vendor(s), or look at (and potentially improve) open source? ◦ Type of problem, type of data ◦ Where is the “alpha”? ◦ Accuracy ◦ Transparency ◦ Customization ◦ Maintenance, ease adding more/different data ◦ Time to market ◦ Privacy/Regulatory concerns ◦ Cost
• Interpretability, explainability • Regulatory / compliance ◦ Data permissioning: per-role/per-person ◦ On-/Off-prem data storage, compute ◦ Encrypting data at-rest and in-transfer ◦ Private data flows, separated networks ◦ Right to be forgotten
Large Language Model for Finance • BloombergGPT is a 50 billion parameter language model trained on ~600 billion tokens, half of which are from financial domain. • Two research questions ◦ What are the optimal choices for building a Large Language Model? ◦ What is the impact of domain specific data on the end model’s performance? ü "BloombergGPT: A large language model for finance." arXiv preprint arXiv:2303.17564 (2023).
the overall model architecture set, there are lots of knobs to tune • Model size & shape - what shape should each sub- component have? • Dataset size - what is the optimal amount of data? • Dataset composition - does in-domain data matter? • Low-level operator implementation - how do you build efficient compute? • Hardware - what is the most efficient hardware (and network) configuration? • Distributed optimizer - how do you efficiently pass parameters and gradients around during training? • Hyper-parameters - how to the set learning rate? • Numerical precision - what is the necessary precision for each of the parameters and gradients? • Tokenization - how big should the vocabulary size be? Do you want multi-word tokens?
Our training dataset consists of roughly equal parts public and private data: • Public data • The Pile (Gao et al., 2020) – 22 diverse domains • C4 (Raffel et al., 2019) – cleaner Common Crawl • Wikipedia from July 2022 • Private data • Web content • News wires and transcripts • SEC Edgar filings • Press Releases
information aggregation/federation • Generative IR? ◦ Automatically generating a single synthesized answer end-to-end inhibits user learning and serendipity. And what if you get it wrong? • Retrieval-augmented generation ◦ Do we still need search indexes? ◦ What is the unit of retrieval? ▪ Paragraphs? ▪ Items/entities? ▪ Actions? ▪ Summaries? ▪ API calls? ▪ Does it matter? • Cross-modal generation • Multi and cross-lingual ü Tutorial: Neuro-Symbolic Representations for IR (ECIR 2023) ü Dense Retrieval Adaptation using Target Domain Description (SIGIR 2023) ü Tutorial: Retrieval-based Language Models and Applications (ACL 2023) ü Transformer Memory as a Differentiable Search Index (2022)
search, aka stateful QA (“chatbots”) • Align closer and closer to the user’s information need • Align with specific parts/tasks in an end-to-end workflow • Interactive information retrieval, allowing interactions and follow-ups with rich result sets ü Improving Dialogue State Tracking with Turn-based Loss Function and Sequential Data Augmentation (EMNLP (Findings) 2021) ü Similarity-based Multi-Domain Dialogue State Tracking with Copy Mechanisms for Task-based Virtual Personal Assistants (WWW 2022)
Aim to understand your users, their tasks and workflows, and their struggles ◦ This requires multidisciplinary teams working together from complementary angles ◦ Align results, suggestions, and recommendations with user workflows and tasks, leveraging all available information • Deliver value and leverage the state-of-the-art through applied research ◦ Address challenges encountered in “production” scenarios (cold-start issues, confidence modeling, partially observed behavior, system-induced biases, and more) ◦ Validate through scientific peer review and open source contributions • Use LLMs and other modern techniques judiciously ◦ Curate data and perform continuous training with a human-in-the-loop
Bloomberg Finance L.P. All rights reserved. https://TechAtBloomberg.com/AI https://TechAtBloomberg.com/data-science-research-grant-program/ @edgarmeij | [email protected] Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}