Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Learning Second edition - Notes o...
Search
Etsuji Nakai
December 05, 2019
Technology
120
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reinforcement Learning Second edition - Notes on Chapter 6
Etsuji Nakai
December 05, 2019
More Decks by Etsuji Nakai
See All by Etsuji Nakai
ハミルトン・ヤコビ方程式の解の性質と物理的意味
enakai00
0
800
Agent Development Kit によるエージェント開発入門
enakai00
23
9.1k
GDG Tokyo 生成 AI 論文をわいわい読む会
enakai00
1
690
Lecture course on Microservices : Part 1
enakai00
1
3.8k
Lecture course on Microservices : Part 2
enakai00
2
3.7k
Lecture course on Microservices : Part 3
enakai00
1
3.7k
Lecture course on Microservices : Part 4
enakai00
1
3.7k
JAX / Flax 入門
enakai00
1
1.5k
生成 AI の基礎 〜 サンプル実装で学ぶ基本原理
enakai00
7
4.4k
Other Decks in Technology
See All in Technology
AICoEでAIネイティブ組織への進化
yukiogawa
0
190
シンガポールで登壇してきます
yama3133
0
240
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
5k
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
180
AI Driven AI Governance
pict3
0
480
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
140
AI時代の闇と光
tatsuya1970
0
110
はじめてのWDM
miyukichi_ospf
1
150
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
390
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
290
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
280
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Technical Leadership for Architectural Decision Making
baasie
3
440
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Practical Orchestrator
shlominoach
191
11k
Code Review Best Practice
trishagee
74
20k
Transcript
Reinforcement Learning Second edition - Notes on Chapter 6 Etsuji
Nakai (@enakai00)
Off-policy MC control with ε - greedy の課題 2 •
ゴールから逆向きにエピソードをスキャンして、Value Function を更新していく。 • Target policy π が Greedy(非確率的)なので、π と異なるアクションがあると、それ以前 を含むパスの確率は 0 になり、そこでスキャンは打ち切られる。 • スタートからゴールまで Target policy にしたがって行動するエピソードがないと、スター ト付近の価値関数が学習できない。 ◦ つまり、長距離にわたる学習が困難 ⇨「Bootstrapping でない手法」の課題
Temporal Difference Prediction 3 • ゴールに至るまでの Total Reward で Value
function を見積もるのではなく、DP Method と同様に、エピソードに含まれる個々のステップを個別に評価する。 • S → A → R → S' というステップに対して、S' 以降の Total Reward は、現在の V(S') の値で 近似すると、 という見積もりができる。 • 現状の V(S) とここで得られた見積もりとの差分を TD Error と呼ぶ。 • 一定の重み α で TD Error による修正を加えていく。
Temporal Difference Prediction 4 • 問題点:Greedy Policy を採用すると、その Policy では到達しない状態のサンプルが得られ
なくなる。
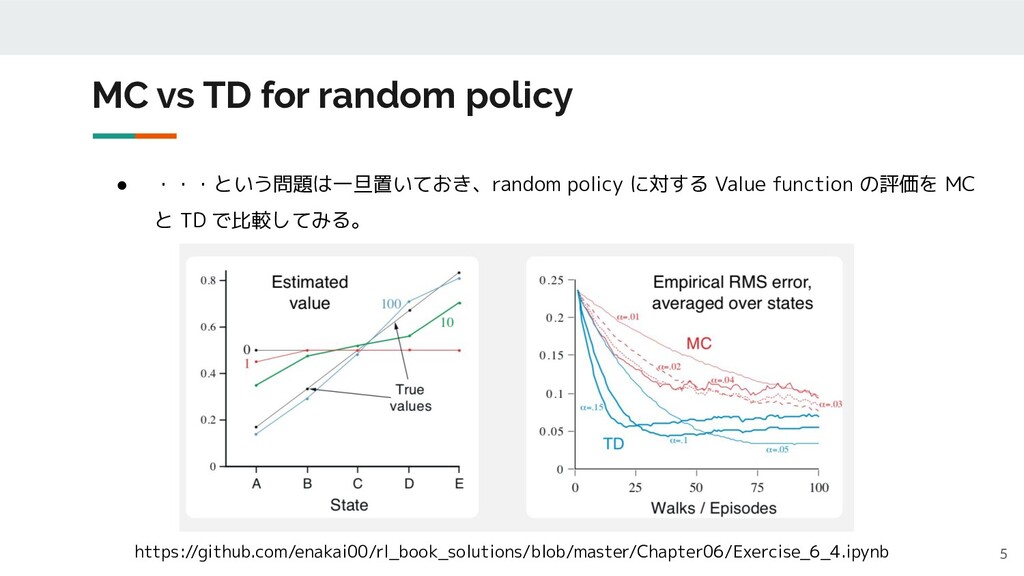
MC vs TD for random policy 5 • ・・・という問題は一旦置いておき、random policy
に対する Value function の評価を MC と TD で比較してみる。 https://github.com/enakai00/rl_book_solutions/blob/master/Chapter06/Exercise_6_4.ipynb
ポリシーの改善方法(Policy Iteration の復習) 6 ※ ここでは、 は既知とする。 ・任意のポリシー を1つ選択する ・Value function
を(何らかの方法で)計算する ・Action-Value function が決まる ・Greedy ポリシー ( が最大の a を確率 1 で選択する) この時、任意の s について が成り立つ。 つまり、π' は、π よりも優れたポリシーと言える。この改善処理を繰り返す。 TD の場合は、q π (s, a) を 求めておくことが必要
ポリシーの改善方法(SARSA) 7 • : 状態 S で Action A を取り、その後は、ポリシー
π で行動を続けた場合の Total Reward • ポリシー π の下に、 を取得して、Action-value function の見積もりを下記 でアップデートする。 • ポリシー π として、 を用いた Greedy policy を採用すると、 の更新に伴っ て、ポリシーも改善されていく。
ポリシーの改善方法(SARSA) 8 • 問題点:Greedy Policy を採用すると、その Policy では到達しない状態のサンプルが得られ なくなる!!!!!!! •
あきらめて、ε - greedy (一般には、 に基づいた何らかの Soft policy)を採用し て、ε を徐々に 0 に近づけるなどの工夫をする。 ⇨ これが、一般に SARSA (on-policy TD)と呼ばれる手法
ポリシーの改善方法(SARSA) 9
MC / TD の根本問題をもう一度よく考えてみよう 10 • 問題点:Greedy Policy を採用すると、その Policy
では到達しない状態のサンプルが得られ なくなる!!!!!!!と言ったけど・・・・ • Greedy でない Policy を採用すると、Greedy policy でその経路が得られる確率が 0 にな り、off-policy MC における Importance sampling ができないことが真の問題点 • あれ? じゃあ、TD の場合、上記の問題ってあるんだっけ・・・・?
MC / TD の根本問題をもう一度よく考えてみよう 11 • 下記のアップデートの根本原理は、 という関係式。 • :「 状態
S で Action A を取り、その後は、ポリシー π で行動を続けた場合の Total Reward」なので、上記のアップデートにおいて、Action A は、任意のポリシーで取得して 構わない。 • 一方、Action A' は、ポリシー π で取得したものを選択する必要がある。したがって、ここ で、Greedy policy を適用すれば、Greedy policy に基づいたポリシーの更新ができる。 ⇨ Q - Learning
• MC の場合 • Q - Learning の場合 MC と
Q-Learning の違い 12 この部分の Total reward をリアルなエピソードから取得する この部分の Total reward は、 で見積もる (なので、これ以降の経路は、 とは無関係で何でもよい。)
• 任意のポリシーでエピソードを集めまくれば、最適な Greedy ポリシーが決定できる。 • よって、エピソード収集用のポリシー(Behavior policy)を工夫することで、より長期的な経路のデー タを効率的に収集することができえる。 Q-Learning =
Off - policy TD 13
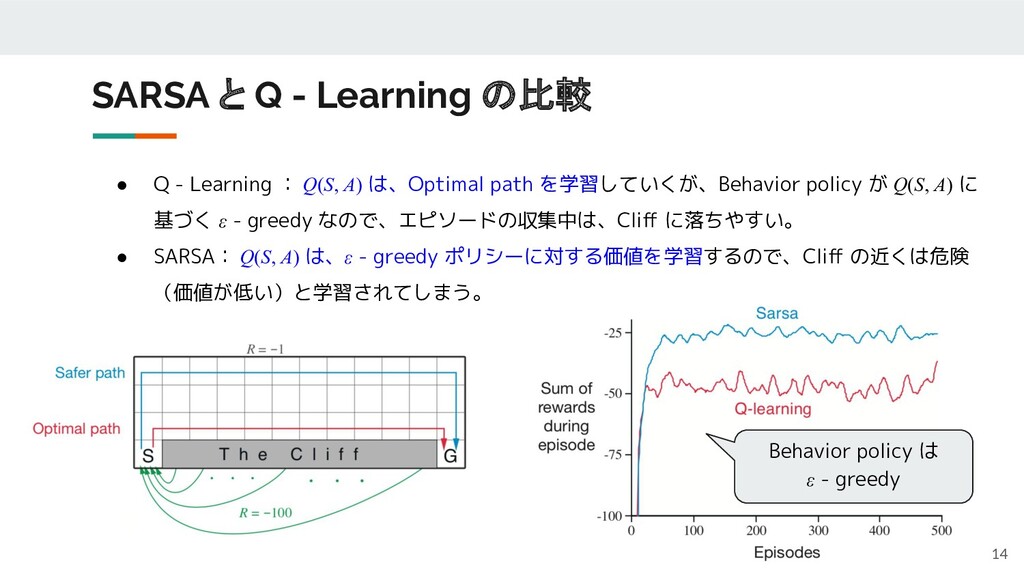
• Q - Learning : Q(S, A) は、Optimal path を学習していくが、Behavior
policy が Q(S, A) に 基づく ε - greedy なので、エピソードの収集中は、Cliff に落ちやすい。 • SARSA: Q(S, A) は、ε - greedy ポリシーに対する価値を学習するので、Cliff の近くは危険 (価値が低い)と学習されてしまう。 SARSA と Q - Learning の比較 14 Behavior policy は ε - greedy
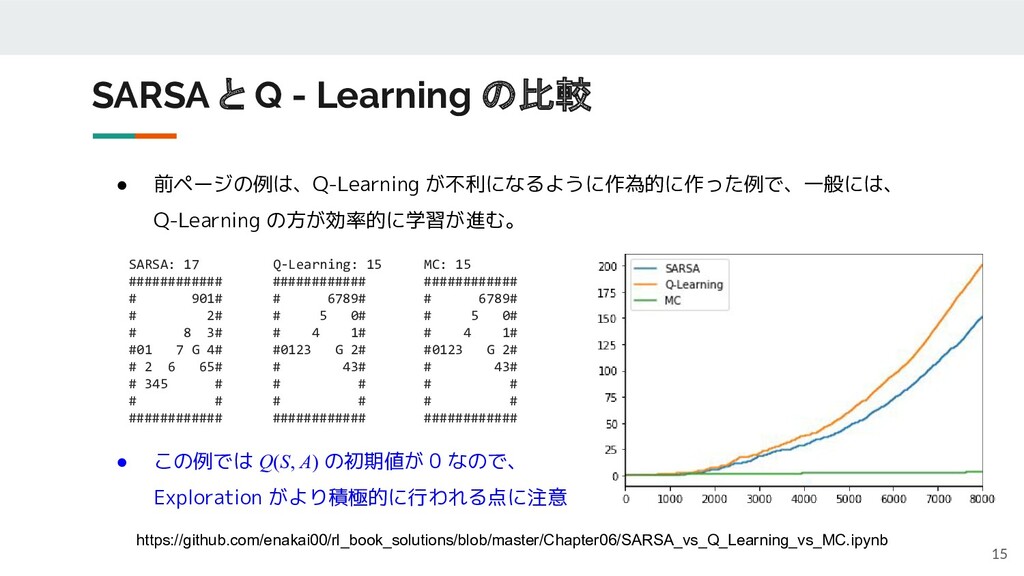
• 前ページの例は、Q-Learning が不利になるように作為的に作った例で、一般には、 Q-Learning の方が効率的に学習が進む。 SARSA と Q - Learning
の比較 15 https://github.com/enakai00/rl_book_solutions/blob/master/Chapter06/SARSA_vs_Q_Learning_vs_MC.ipynb SARSA: 17 ############ # 901# # 2# # 8 3# #01 7 G 4# # 2 6 65# # 345 # # # ############ Q-Learning: 15 ############ # 6789# # 5 0# # 4 1# #0123 G 2# # 43# # # # # ############ MC: 15 ############ # 6789# # 5 0# # 4 1# #0123 G 2# # 43# # # # # ############ • この例では Q(S, A) の初期値が 0 なので、 Exploration がより積極的に行われる点に注意
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}