Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GMOペパボのデータ基盤とデータ活用の現在地 / Current State of GMO P...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Hiroka Zaitsu
July 31, 2025
Technology
410
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GMOペパボのデータ基盤とデータ活用の現在地 / Current State of GMO Pepabo's Data Infrastructure and Data Utilization
第4回福岡データエンジニアリング勉強会(LT)
https://fukuoka-data-engineering.connpass.com/event/359031/
Hiroka Zaitsu
July 31, 2025
More Decks by Hiroka Zaitsu
See All by Hiroka Zaitsu
データで人の行動を変える - ペパボのデータ基盤 Bigfoot - / Driving Behavior Change with Data - Bigfoot: Pepabo's Data Platform
zaimy
0
22
AI が Approve する開発フロー / How AI Reviewers Accelerate Our Development
zaimy
1
390
Agent Ready になるためにデータ基盤チームが今年やること / How We're Making Our Data Platform Agent-Ready
zaimy
0
290
ビジネス職が分析も担う事業部制組織でのデータ活用の仕組みづくり / Enabling Data Analytics in Business-Led Divisional Organizations
zaimy
1
860
Vertex AI Matching Engine と CLIP を使って EC サービスの類似画像検索機能を作る / Development of similar image search function for EC services using Vertex AI Matching Engine and CLIP
zaimy
0
810
BigQuery の日本語データを Dataflow と Vertex AI でトピックモデリング / Topic modeling of Japanese data in BigQuery with Dataflow and Vertex AI
zaimy
1
6.4k
データサイエンティストの仕事紹介 / Data Scientist Job Introduction
zaimy
1
690
GMOペパボのサービスと研究開発を支えるデータ基盤の裏側 / Inside Story of Data Infrastructure Supporting GMO Pepabo's Services and R&D
zaimy
1
1.9k
正則化とロジスティック回帰/machine-learning-lecture-regularization-and-logistic-regression
zaimy
0
9.2k
Other Decks in Technology
See All in Technology
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
1
250
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
5
810
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
230
人手不足への挑戦:車両保全を支えるIoTとクラウド内製化の道【SORACOM Discovery 2026】
soracom
PRO
0
170
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
360
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
140
Pavlokで始める電撃駆動開発
sgrsn
0
100
害獣害虫を自動判別! ペストコントロール支援ビジネス成功のヒント【SORACOM Discovery 2026】
soracom
PRO
0
130
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
260
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
270
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
360
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
780
Featured
See All Featured
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
270
Ethics towards AI in product and experience design
skipperchong
2
330
Are puppies a ranking factor?
jonoalderson
1
3.7k
Context Engineering - Making Every Token Count
addyosmani
9
1k
For a Future-Friendly Web
brad_frost
183
10k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
280
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
It's Worth the Effort
3n
188
29k
Between Models and Reality
mayunak
4
380
Documentation Writing (for coders)
carmenintech
77
5.4k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Transcript
GMOペパボのデータ基盤と データ活用の現在地 財津大夏 (@zaimy) GMOペパボ株式会社 技術部データ基盤チーム 2025.08.01 第4回福岡データエンジニアリング勉強会
自己紹介 財津 大夏 ZAITSU Hiroka 技術部データ基盤チーム シニアエンジニア 2012年よりホスティングやECサービスのディレ クターとして、データ駆動のマーケティングや サービス運用改善に取り組む。2018年よりデー タサイエンティスト、2022年よりデータエンジ
ニアとして、データ基盤の開発やその利用によ るサービス改善に取り組んでいる。二児の父。 スバルのファン。
アジェンダ 本日お話しすること 1. ペパボとデータ基盤「Bigfoot」 2. データ基盤の仕組み 3. データ基盤に関わる組織 4. データ活用の事例
Bigfootくん キャラクターグッズ販売中です!!! https://suzuri.jp/zaimy/designs/13278107
ペパボとデータ基盤 「Bigfoot」
GMOペパボ株式会社 "もっとおもしろくできる" という企業理念のもと、 "人類のアウトプットを増やす" ために様々なサービスを提供しています 5
ペパボで目指すもの DX Criteriaとデータ駆動 DX Criteria (v202506) - 企業のデジタル化とソフトウェア活用のためのガイドライン 5つのテーマのうちの1つ「データ駆動」の実現が社内のビジョンとして掲げられている マーケティング自動化
データを元にサービスの振る舞いを変える、サービスの動的改善 自動的な意思決定 意思決定に必要な指標を計測可能・明確にして自動化を可能にする 例)統計的な判断 意思決定後のシステム挙動の変更も自動化する 例)バンディットアルゴリズム 6
ペパボで目指すもの いきなりデータ駆動にはなれない 実現を阻む一般的な課題 データを集める仕組みがない 集めたデータを分析する仕組みやスキルがない 分析したデータを活用する仕組みや組織体制がない 7
データ基盤で目指すもの 各段階においてシステムとリテラシによるデータ駆動を目指す データ基盤がシステムレイヤの各要素を扱いやすくした上で リテラシ面のサポートをチームとして行うことでデータ駆動を目指す 8
データ基盤の仕組み
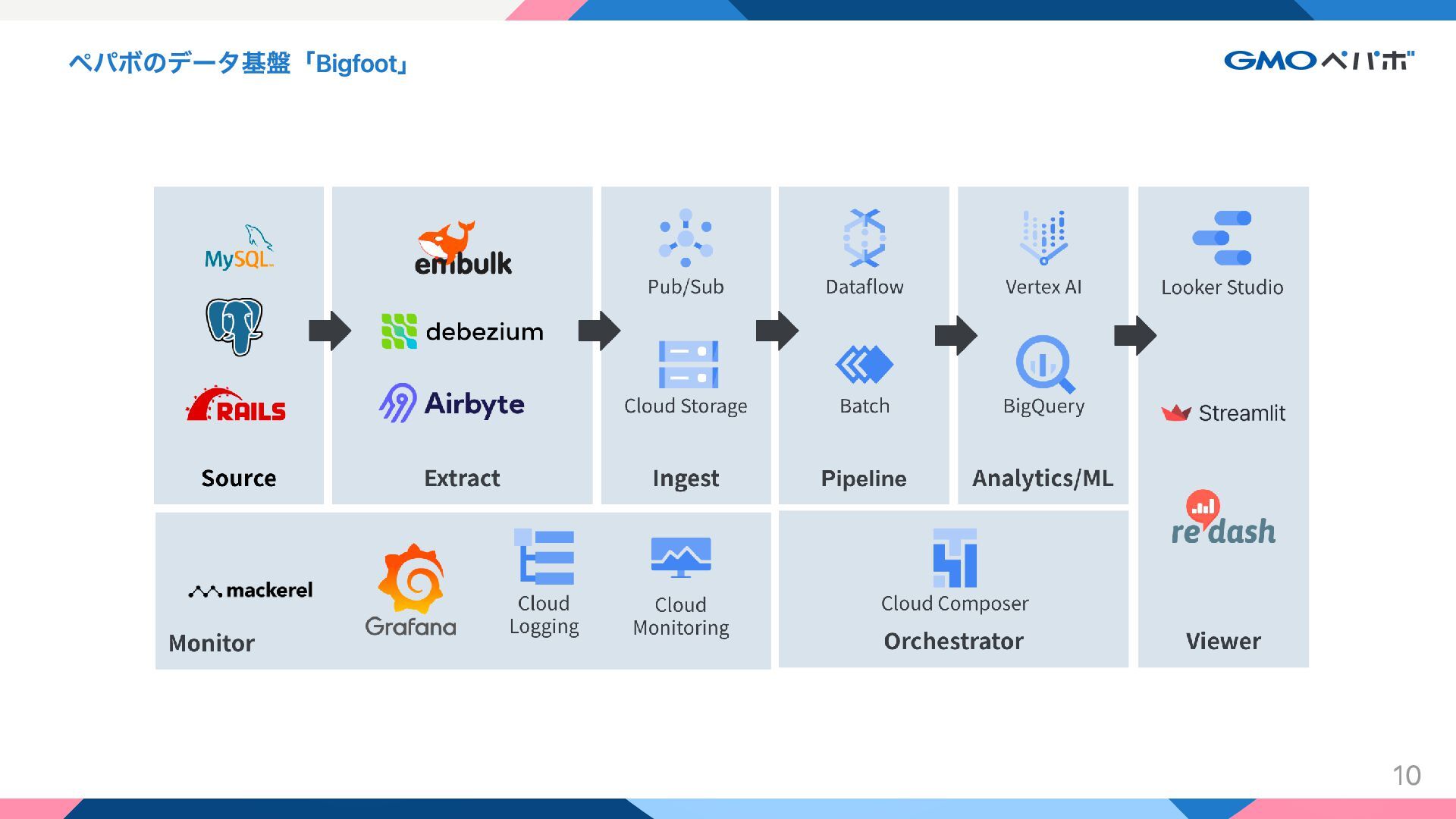
ペパボのデータ基盤「Bigfoot」 10
ペパボのデータ基盤「Bigfoot」 Extract, Load の工夫の例 複数のサービスがある = 複数のデータベース, 設計の異なる複数のログがある サービス DB
からデータ基盤までの EL パイプラインとログ設計を定型化 サービス DB とデータ基盤の間に「データ抽出基盤 Yeti」を構成 サービスの行動ログを生成する Rack/PHP 用のミドルウェアを用意 Zendesk など SaaS のデータの取り込みには Airbyte OSS/Cloud も利用 ➡︎ 知識のサイロ化を防ぎ、ベストプラクティスを複数のサービスで使い回す 11
ペパボのデータ基盤「Bigfoot」- Extract, Load の工夫の例 サービス DB からデータ基盤までの EL パイプラインの定型化 -
Yeti Batch と CDC を組み合わせてサービス DB と BigQuery をニアリアルタイム同期する Batch: Embulk on-premiss または Embulk on AWS Batch (Fargate) を利用 Cloud Storage から BigQuery に Batch Load CDC: Debezium Server on AWS ECS を利用 Cloud Pub/Sub Topic へメッセージを送信 BigQuery Subscriptions で BigQuery に Streaming Insert 詳細は https://tech.pepabo.com/2023/04/20/cdc-for-realtime-analysis/ 12
ペパボのデータ基盤「Bigfoot」- Extract, Load の工夫の例 ログ設計の定型化 - rack-bigfoot / php-bigfoot 数行の設定でサービスアプリケーションの通信内容からユーザーの行動ログを
取り出す Rack ミドルウェアや PHP ライブラリを用意 アプリケーションと Fluentd を繋ぐ 必要な共通パラメタをリクエスト・レスポンスヘッダから取得 サービス固有のパラメタを付与することも可能 ➡︎ 各サービスでエンジニアがログ設計や収集を意識しなくても良い 13
ペパボのデータ基盤「Bigfoot」 最近の技術的な取り組み OpenTelemetry を使ったログの収集と可視化 Debezium Server のトレースと同期遅延の計測 BigQuery の on-demand
と editions の併用 ジョブ内容によって自動的に最適な環境を選択する仕組みの開発 コスト最適化とパフォーマンスの向上 マーケティング向け SaaS との連携強化 Bigfoot を使ったマーケティングオートメーション これまでデータを活用できていなかった業務領域もデータ駆動にしていく 14
データ基盤に関わる組織
データ基盤に関わる組織 ペパボ(事業部制組織)の特徴 事業部メンバーはドメイン知識が深い 一方で業務範囲が広い 事業部にデータ活用の推進者が不在 マネージャーやディレクターが 業務の一環としてデータ分析 データ活用の程度はさまざま エンジニアの横断組織はあるが、サービス 運営に関わるビジネス職の横断組織はない
16
データ基盤に関わる組織 データ基盤立ち上げ当初(2016年~) 当時大規模投資を行っていたminne事業部で開発 開発者と利用者が同じ小さな組織の中にいてスキルセットも備わった状態 データを活用した施策の実行サイクルが回っていた 種々の情報の可視化や行動ログに基づくユーザーセグメントの利用など 17
データ基盤に関わる組織 全社基盤への移行期(2019年頃~) 当初の開発者と利用者が別組織(研究所やデータ基盤チーム)に異動 同メンバーが別組織から主に作り込む形になった 機械学習による推薦, バンディットアルゴリズム, 行動ログの複雑な集計など サービスのアプリケーションの実装のみ事業部パートナーのエンジニアが担当 結果、以下の問題が発生 事業部(特にデータ分析者)にデータ基盤を使った何かのオーナーシップがない
メンテナンスされずに施策ごと自然消滅 データ基盤は「よくわからない、難しいもの」という認知 18
データ基盤に関わる組織 改善の試み(2024年~) 1. Team Topologiesの導入 チームタイプとインタラクションモードの見直し 2. ELTモデルに基づく責任範囲の明確化 データパイプラインの各段階での責任分担 3.
Transform層のフレームワーク化 dbtへの移行とAirflow DAGのテンプレート化 4. ディレクターの基盤チーム加入によるサポート強化 利用者視点での支援とドキュメント・メタデータの整備 19
データ基盤に関わる組織 - 改善の試み(2024年~) Team Topologiesの導入 - チームタイプ 組織のチーム構造を適切に設計する方法論 4つのチームタイプ 1.
ストリームアラインドチーム: 価値の流れに沿って作業 2. プラットフォームチーム: セルフサービス機能を提供 3. イネイブリングチーム: 他チームの能力獲得を支援 4. コンプリケイテッドサブシステムチーム: 専門知識が必要なサブシステムを担当 20
データ基盤に関わる組織 - 改善の試み(2024年~) Team Topologiesの導入 - チームタイプ 従来のチームタイプ認識 事業部からはコンプリケイテッドサブシステムチームに見えていた 「専門的なことはお任せしたいです」
しかしデータ基盤チームがサブシステム全てを担当するとスケールしない 改善後の認識 イネイブリングチームとして明確化 やること、やらないことを明確にした ELTの各ステップを境界に責任範囲を決定 21
データ基盤に関わる組織 - 改善の試み(2024年~) ELTモデルに基づく責任範囲の明確化 改善前: ELTの責任範囲が曖昧 失敗時などは「事業部とデータ基盤チームで面倒を見る」という建て付け 実際はデータ基盤チームが対応することがほとんど 改善後: 責任範囲を明確化
Extract & Load: データ基盤チーム Transform & サービスアプリケーションへのReverse EL: 事業部 SaaSなどへのReverse EL: データ基盤チーム 共通化しやすい部分はデータ基盤チーム、ドメイン知識が必要な部分は事業部 22
データ基盤に関わる組織 - 改善の試み(2024年~) Transform層のフレームワーク化 改善前: DWH上のTransformはすべてAirflow DAG Pythonコードを書けば何でもできる BigQueryなどGoogle Cloudサービスの実行、Pythonコードの実行など
柔軟性は高いが習得が困難 改善後: 用途に応じて最適化 DWH上のデータ変換のみ → dbt on Airflowに移行 DAGが必要だが再利用可能なパターン → DAGをテンプレート化 事業部別、やりたいこと別に10行程度のコード追加で生成可能にした 23
データ基盤に関わる組織 - 改善の試み(2024年~) ディレクターの基盤チーム加入 従来: エンジニア向け基盤(X-as-a-Service的発想) コードサンプル, ドキュメントを読めばわかる 改善後: ビジネス職かつデータ分析経験者によるコラボレーションの追加
ビジネス職の中でデータ基盤を社内トップクラスに活用していた3名が加入 データ分析者の困りごとに近い立場でコミュニケーションできる 利用者向けドキュメントの整備 利用者にとって必要なメタデータの追加 24
データ基盤に関わる組織 - 現在 当たり前レベルが向上しはじめた 改善前: スプレッドシートにデータがある 集計ロジックも各所にある 集計されたデータを見て「こういう傾向がある」で終わりがち 改善後: SSoTなデータをもとに仮説と施策と検証のサイクルを回す
まず仮説ありきで検証可能な施策を実行する データ作成の作業ではなくデータ活用にフォーカスする 25
データ基盤に関わる組織 - 現在 チームの変化 データ基盤チームの変化 データ基盤からデータ基盤サービスへ XaaSを目指しつつ、営業・コンサル・コーチング的コラボレーション 事業部の変化 事業部パートナーによるTransformの新規作成とその活用 他事業部で既に行っているSaaS活用を実装コストなしで水平展開
データで困ったとき、やりたいことがあるときのデータ基盤チームへの声かけ増 26
データ活用の事例
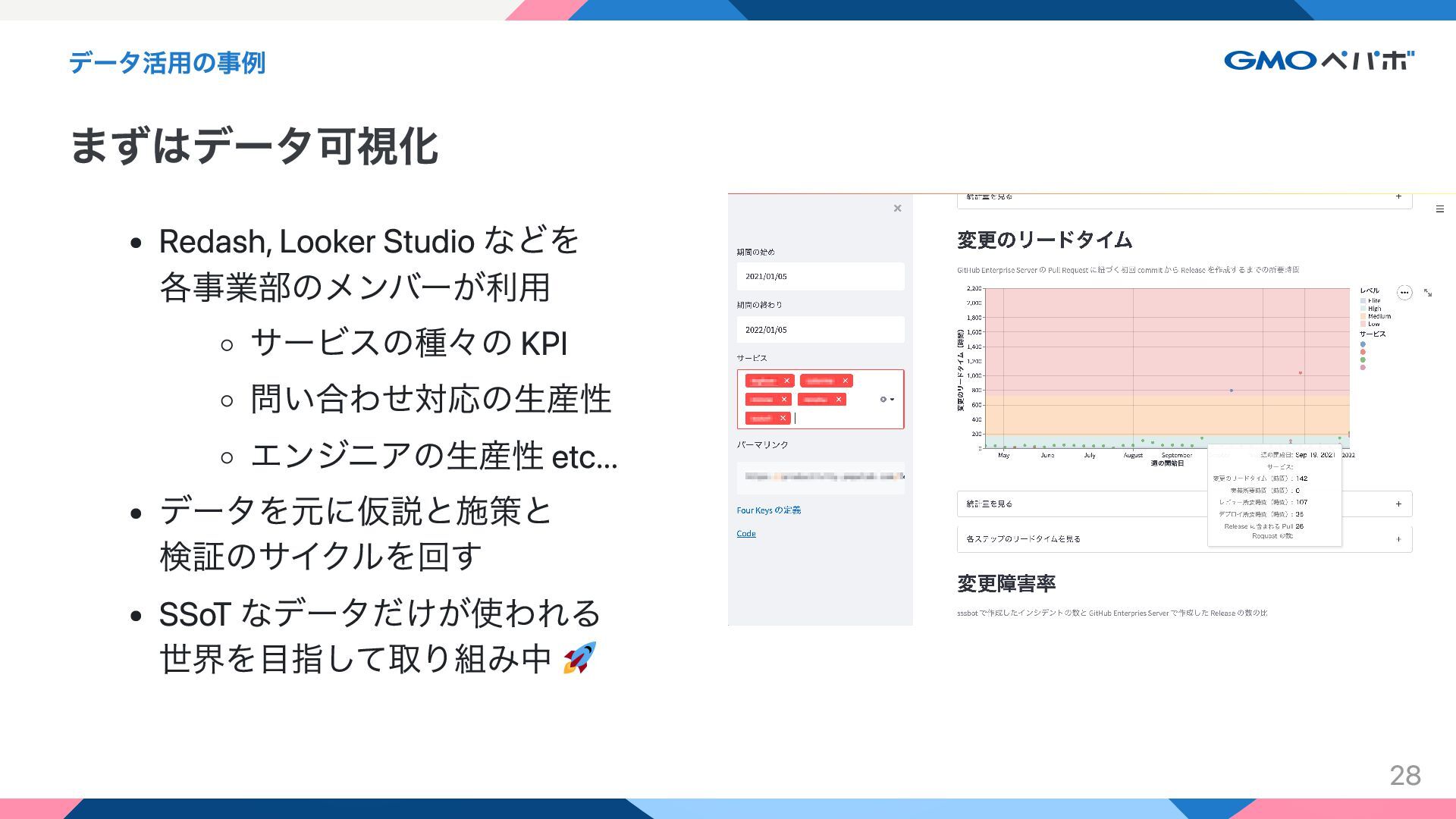
データ活用の事例 まずはデータ可視化 Redash, Looker Studio などを 各事業部のメンバーが利用 サービスの種々の KPI 問い合わせ対応の生産性
エンジニアの生産性 etc... データを元に仮説と施策と 検証のサイクルを回す SSoT なデータだけが使われる 世界を目指して取り組み中 28
データ活用の事例 離脱ユーザーへのリテンション 行動ログから離脱ユーザーを抽出するワークフローを作成 商品をカートに入れたが買わなかったユーザー 同じ商品を何度も見ているユーザー ワークフローの処理結果をアプリケーションに取り込み メール配信やアプリ内通知でリテンション施策を実行 さらに行動ログからユーザーごとにアクティブになりやすい時間を特定 該当の時間に配信することで高い開封率と注文率を実現 29
データ活用の事例 類似画像推薦 CLIP を使って画像の特徴をベクトル化 Vertex AI Matching Engine で高速なベクトル検索 構成の検討や試行錯誤を含めて、開発開始から
2 週間でリリース 詳細は https://tech.pepabo.com/2023/06/13/suzuri-similar-image-recommendation/ 30
データ活用の事例 その他 機械学習を用いたECサイトでの商品レコメンデーション 協調フィルタリングなど行動ログを用いた嗜好推定 商品情報のトピックモデリング BigQuery の日本語データを Dataflow と Vertex
AI でトピックモデリング https://speakerdeck.com/zaimy/topic-modeling-of-japanese-data-in-bigquery-with-dataflow-and-vertex-ai バンディットアルゴリズムによる推薦やサイト内検索ロジックの改善 Synapse: 文脈と時間経過に応じて推薦手法の選択を最適化するメタ推薦システム https://speakerdeck.com/monochromegane/smash21-synapse 31
データ活用の事例 その他 ECサイトの売上予測 プロダクト担当者とデータサイエンティストで Prophet を使って EC サービスの注文額を予測する https://tech.pepabo.com/2022/12/16/minne-sales-prediction/ ECサイトの規約違反品の検出
財津 大夏, 三宅 悠介, 松本 亮介, ハンドメイド作品を対象としたECサイトにおける大量生産品の検出, 研究報告インター ネットと運用技術(IOT), Vol.2018-IOT-41, pp.1-8, May 2018. サーバーの計画的オートスケーリングでクラウドサービス利用料金を半分に削減 三宅 悠介, 松本 亮介, 力武 健次, 栗林 健太郎, アクセス頻度予測に基づく仮想サーバの計画的オートスケーリング, 情報科 学技術フォーラム講演論文集, Vol.17, No.4, pp.7-12, Sep 2018. 32
データ活用で "もっとおもしろくできる"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}