{ // register the current worker into the dispatch pool w.dispatcher.pool <- w select { case v := <-w.data: if bulkstr, ok := v.([][]string); ok { wordMap := processData(bulkstr) w.dispatcher.sink <- wordMap } w.dispatcher.wg.Done() case <-w.quit: return } } }() }
greater than the length of the array, or the number of elements in dictionnary is greater than the available space from idex to the end of destination array.
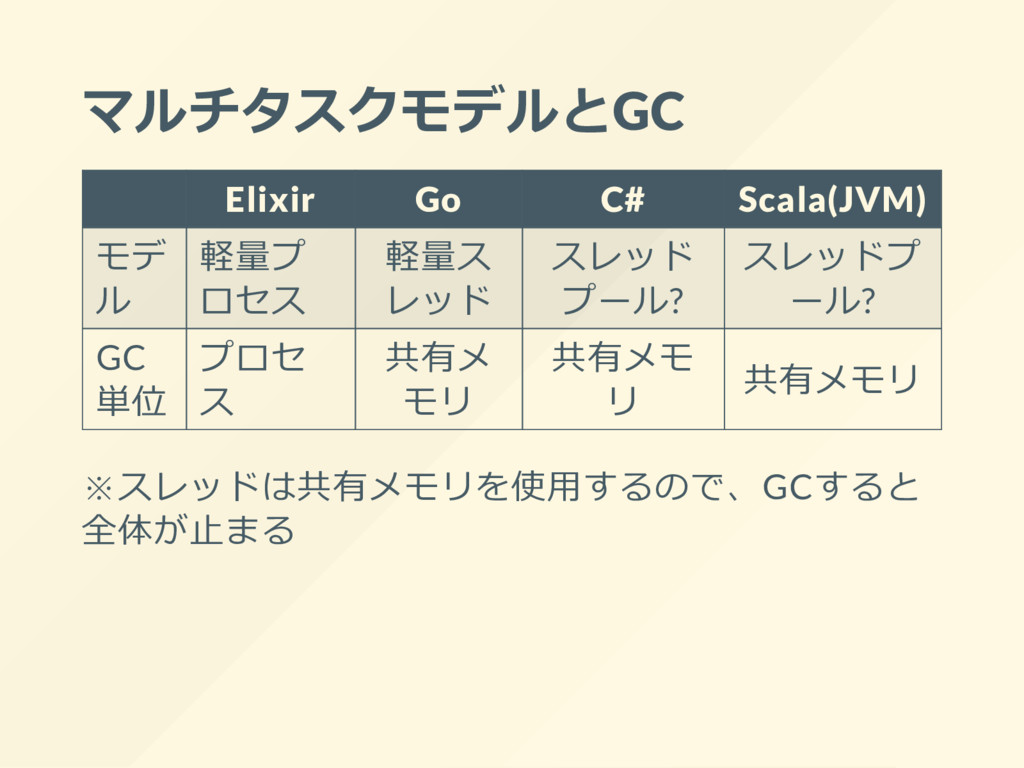
B+? D ポーテーション 〇 〇 ? 〇 〇 安定度 S B A A A 環境構築コスト A S B C A 学習コスト B+ A B+ B- A 記述量 S C A S A メンテナンス性 A B A A A ドキュメント B+ A A S A Elixirの安定度がSなのはGCの仕組による(プロセ ス単位)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
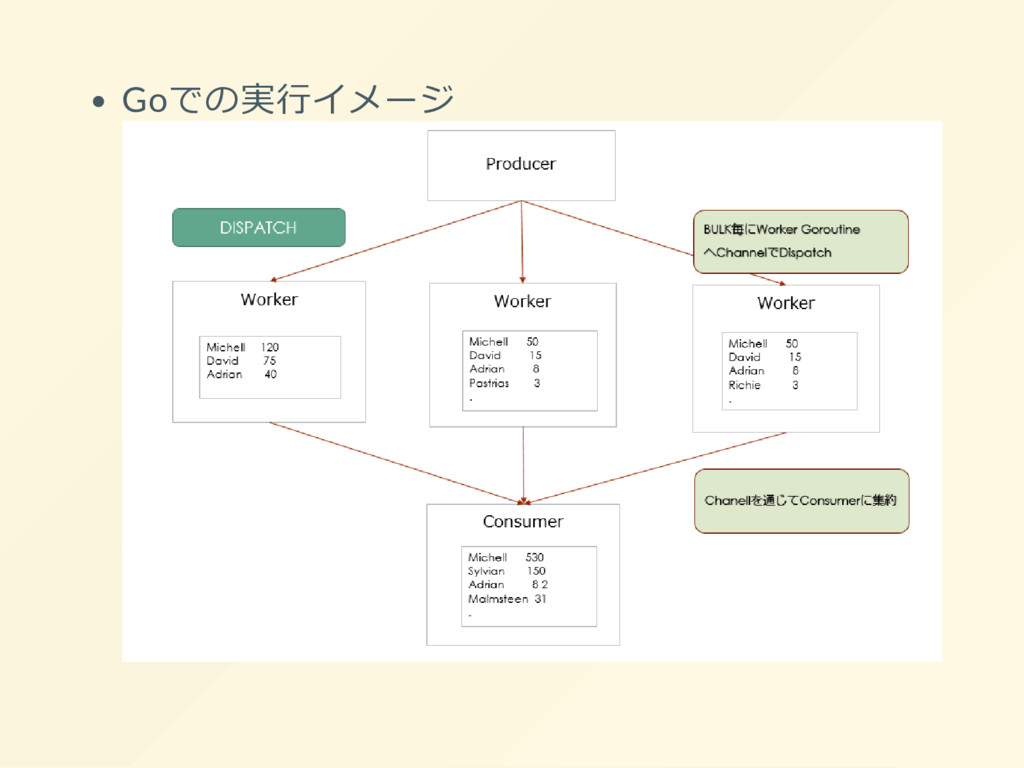{kind=link}
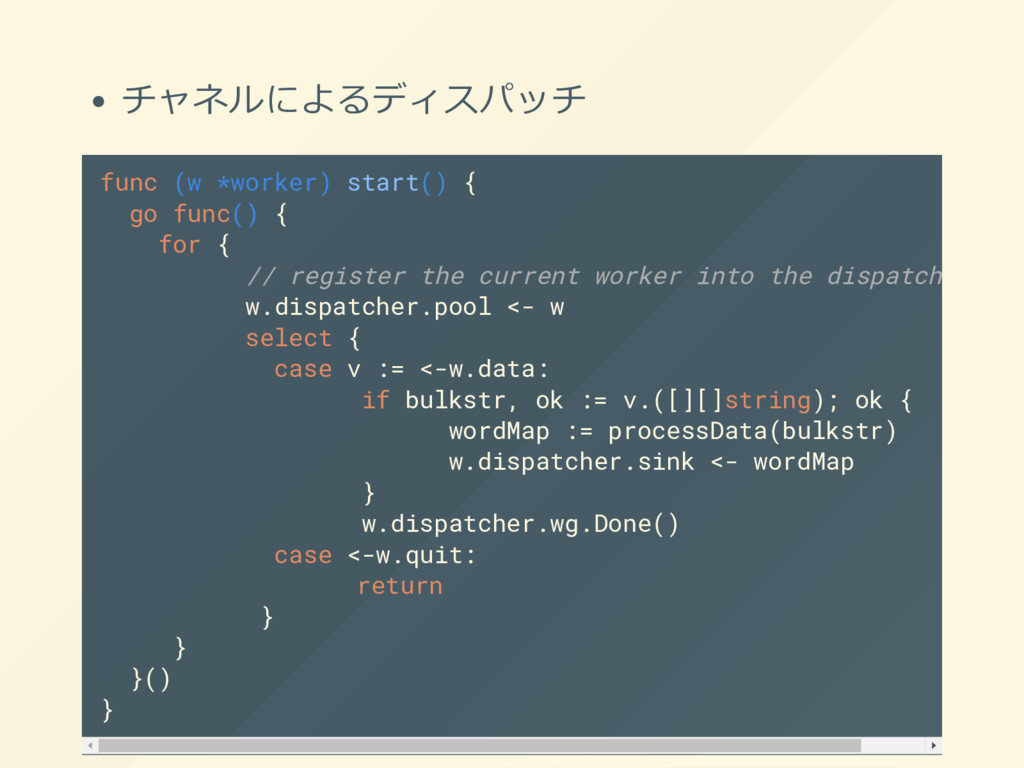{kind=link}
![バルクデータをマップ化 func processData(r [][]string) map[string]int { var m = map[string]int{}](https://files.speakerdeck.com/presentations/7257d1c8c31b4a6eb02413e9da2ee1c3/slide_26.jpg){kind=link}
![// チャネルからクラスタ化された集計結果を集める func waitAndSum(sumMap map[string]int, d *Dispatcher, quit for {](https://files.speakerdeck.com/presentations/7257d1c8c31b4a6eb02413e9da2ee1c3/slide_27.jpg){kind=link}
{kind=link}
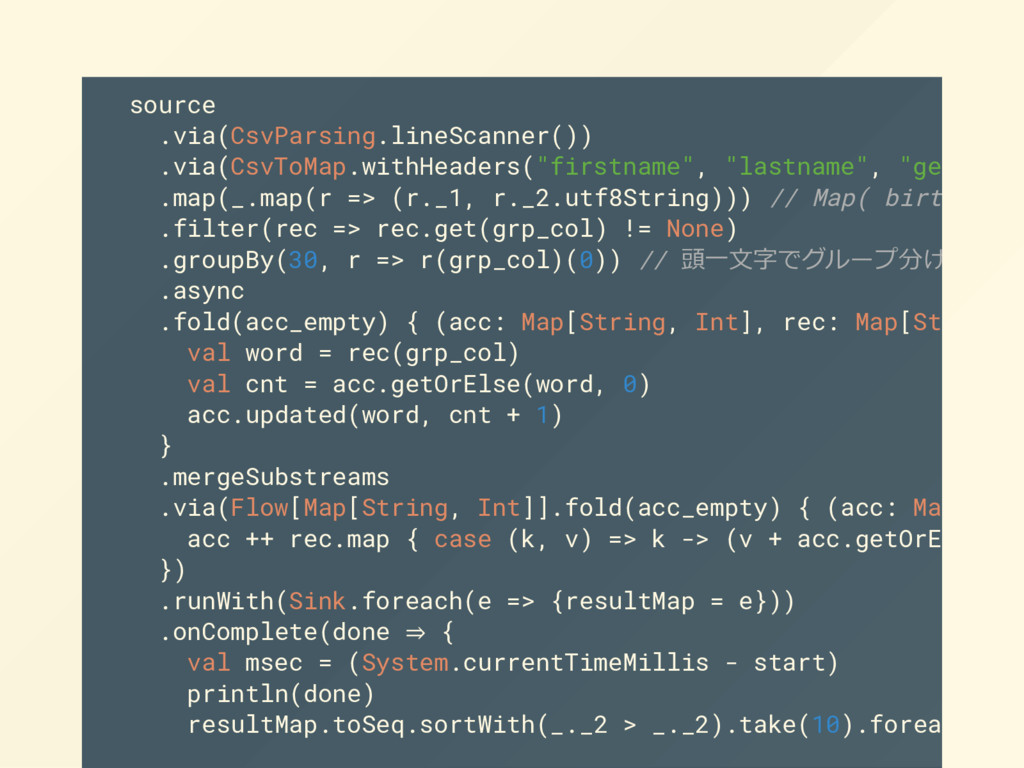{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Windows 10 Home Edition Corei5 [email protected] Hz (Kabylake) 2コア4スレッド 16GMemory](https://files.speakerdeck.com/presentations/7257d1c8c31b4a6eb02413e9da2ee1c3/slide_35.jpg){kind=link}
![Windows10 Home edition Corei5 [email protected] Hz 2コア4スレッド Elixir Go C#](https://files.speakerdeck.com/presentations/7257d1c8c31b4a6eb02413e9da2ee1c3/slide_36.jpg){kind=link}
{kind=link}
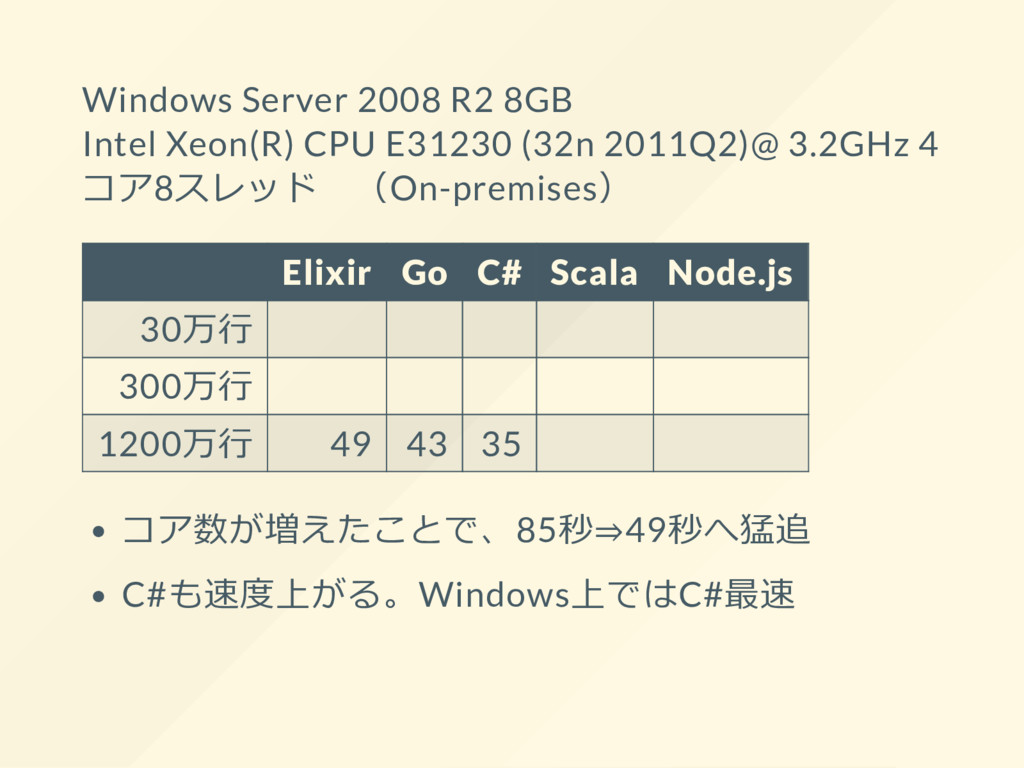{kind=link}
{kind=link}
{kind=link}
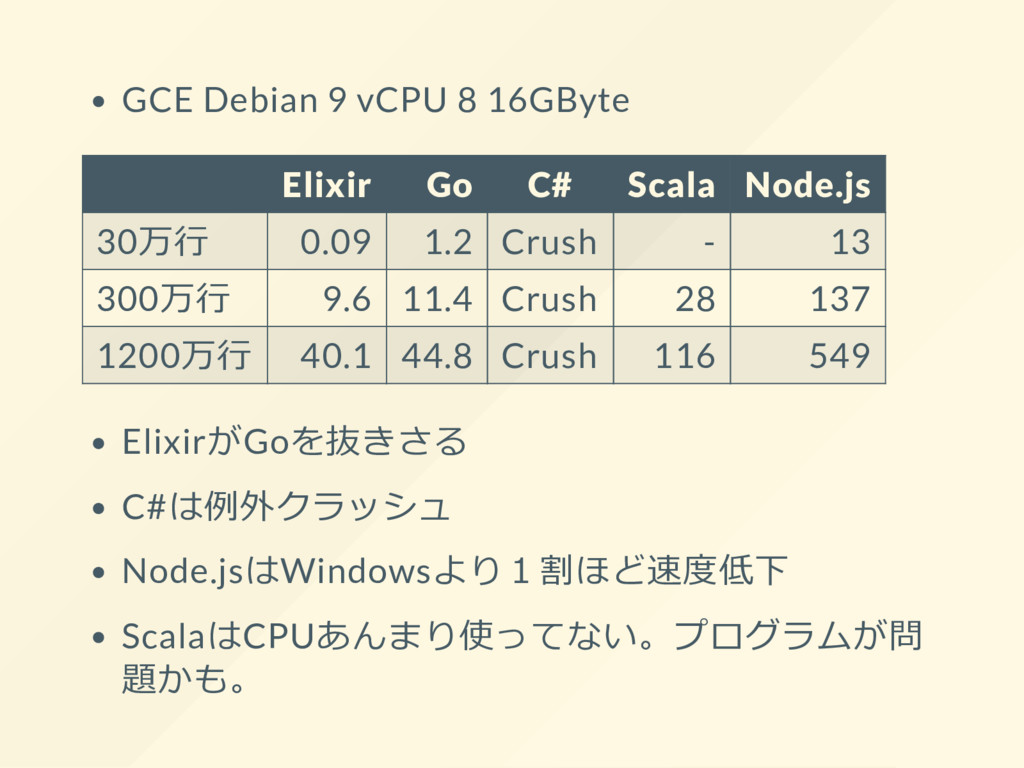{kind=link}
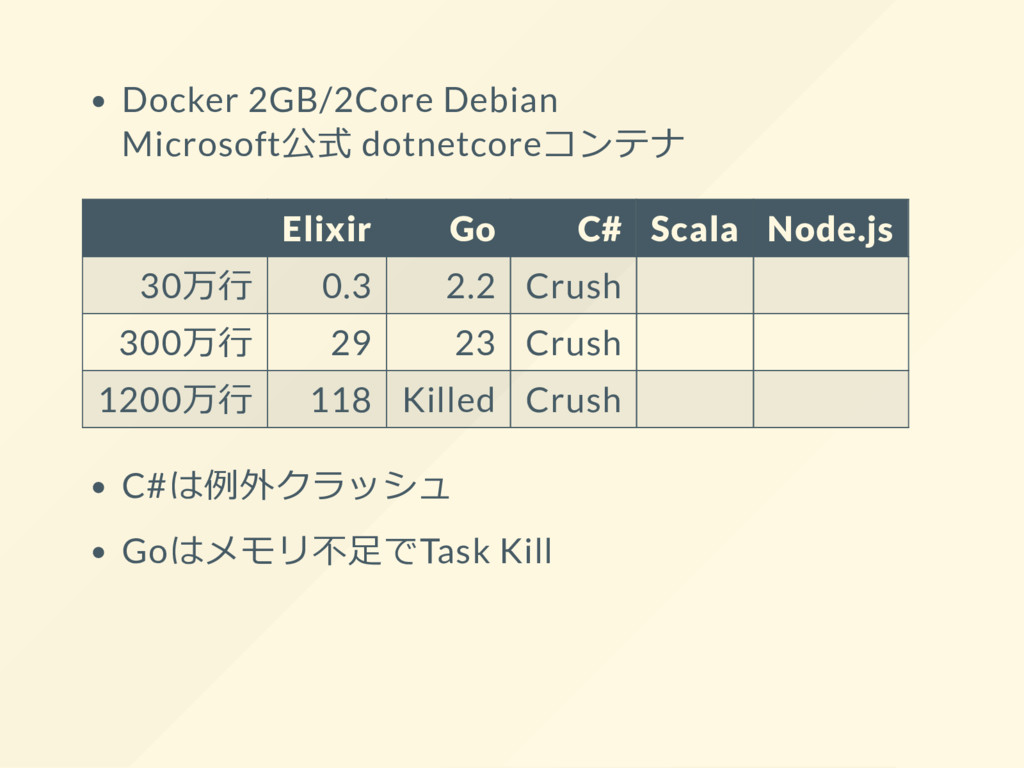{kind=link}
{kind=link}
{kind=link}
{kind=link}
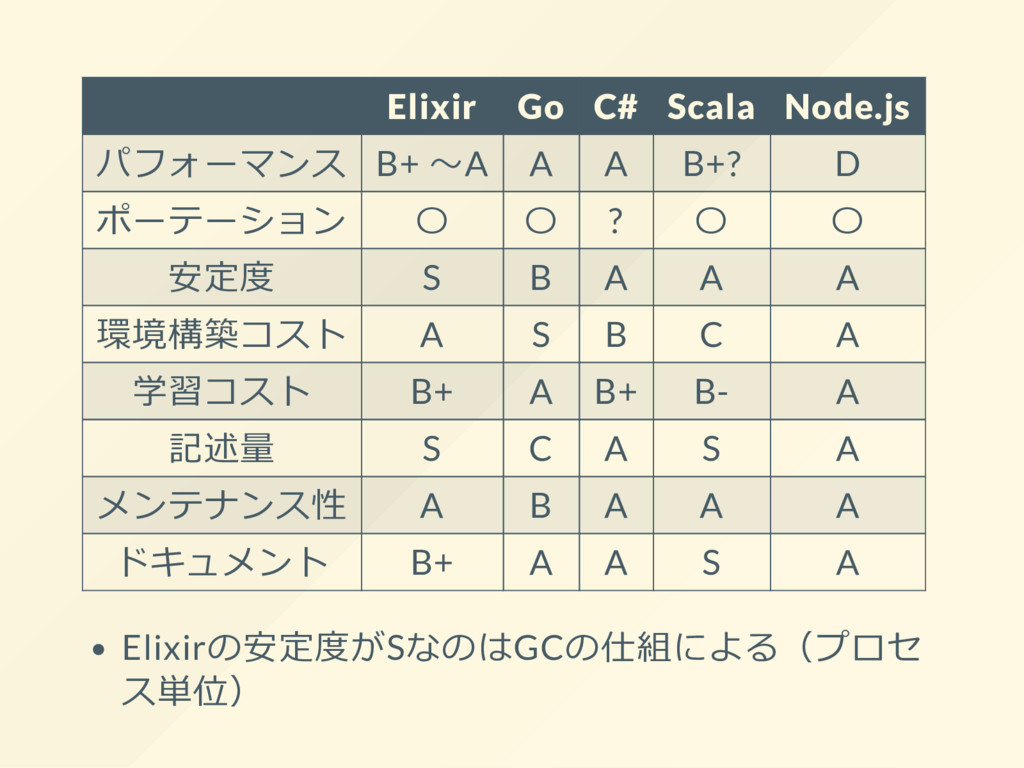{kind=link}
{kind=link}