word FROM (SELECT split(R.rec, '\t') FROM (SELECT replace (R.rec, '\"', '') FROM (SELECT replace (R.rec, '\r\n', '\n') FROM (SELECT replace (R.rec, ',', '\t') FROM (SELECT rec FROM TABLE (stram_pkg.read ("text.csv")) ) R ) R ) R ) R ) R ) R GROUP BY word
![Elixir Flowで膨⼤な Imageリストを捌く Created by Enpedasi/twinbee ( [@enpedasi] ) 2018/8/24](https://files.speakerdeck.com/presentations/76c2bdc619534b498985404c353e02cf/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
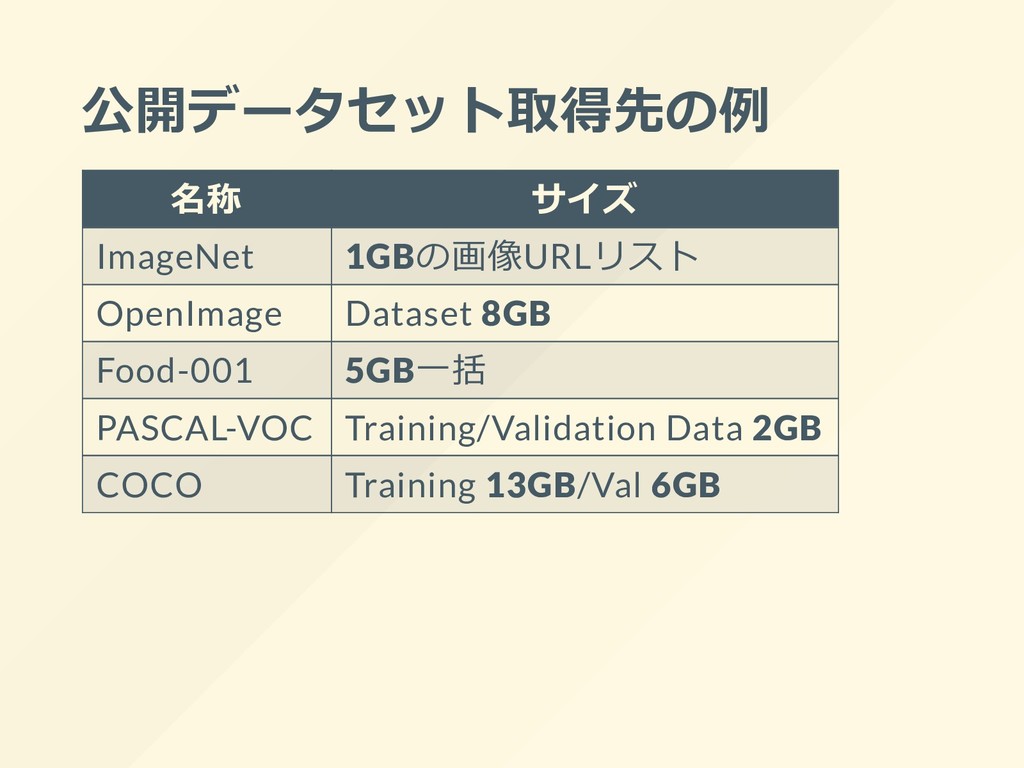
![SELECT ーー 実在しない⽂法です word, count(*) cnt FROM (SELECT R.rec[2] as](https://files.speakerdeck.com/presentations/76c2bdc619534b498985404c353e02cf/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
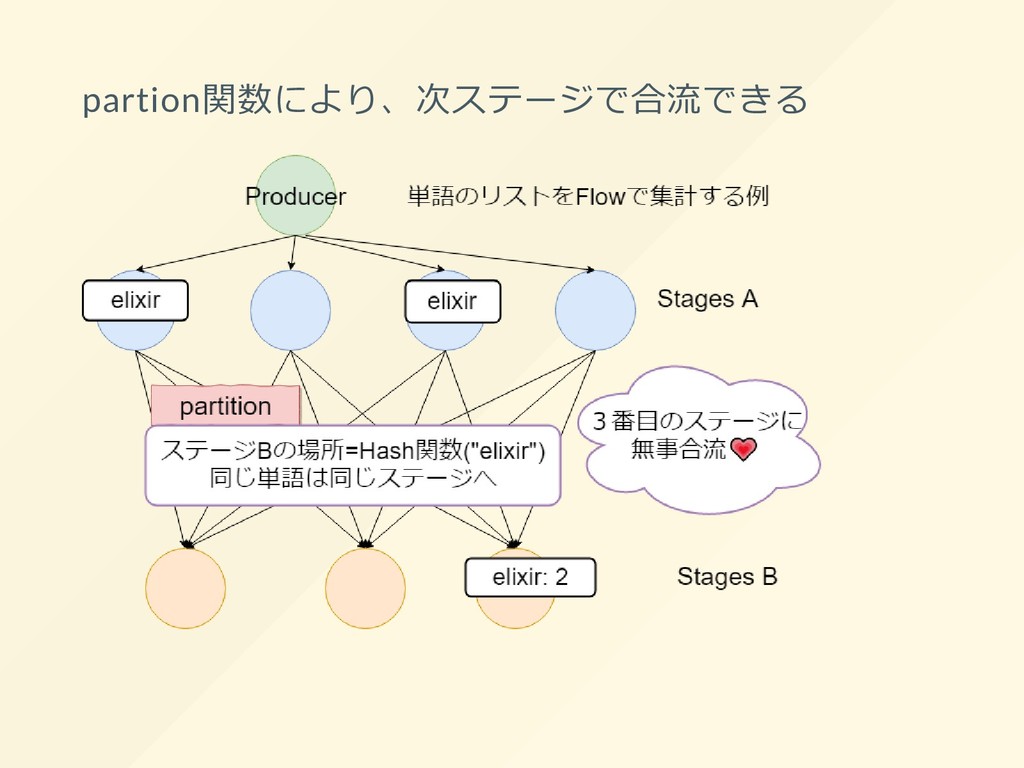
![単語の集計を考えた場合、 partition関数による、多段構成がないと・・・ 同じ単語も、どのステージに配布されるかわからない ⇒集計されず、 [elixir: 1, elixir:1 ] という結果に…](https://files.speakerdeck.com/presentations/76c2bdc619534b498985404c353e02cf/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
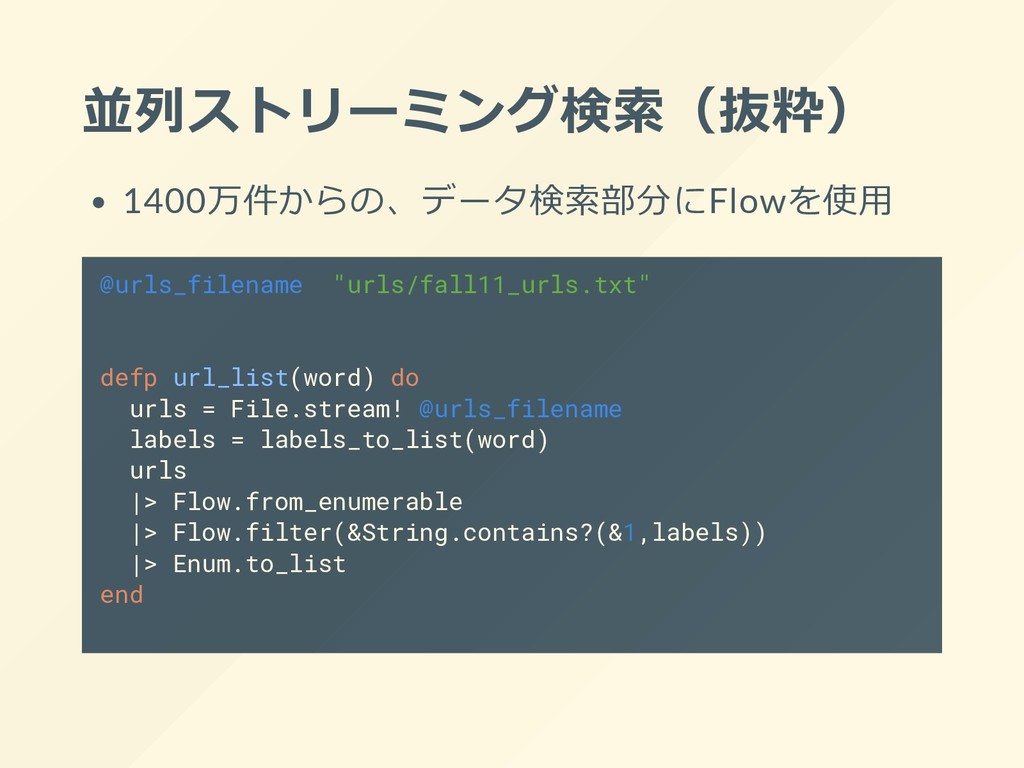{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
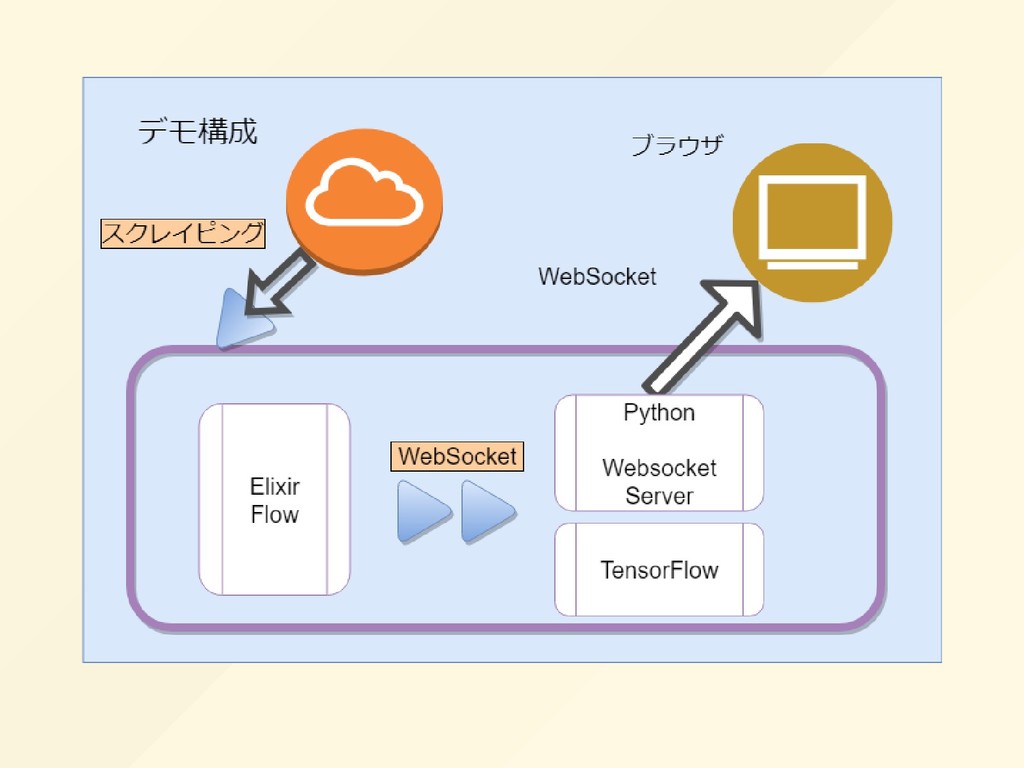{kind=link}
{kind=link}