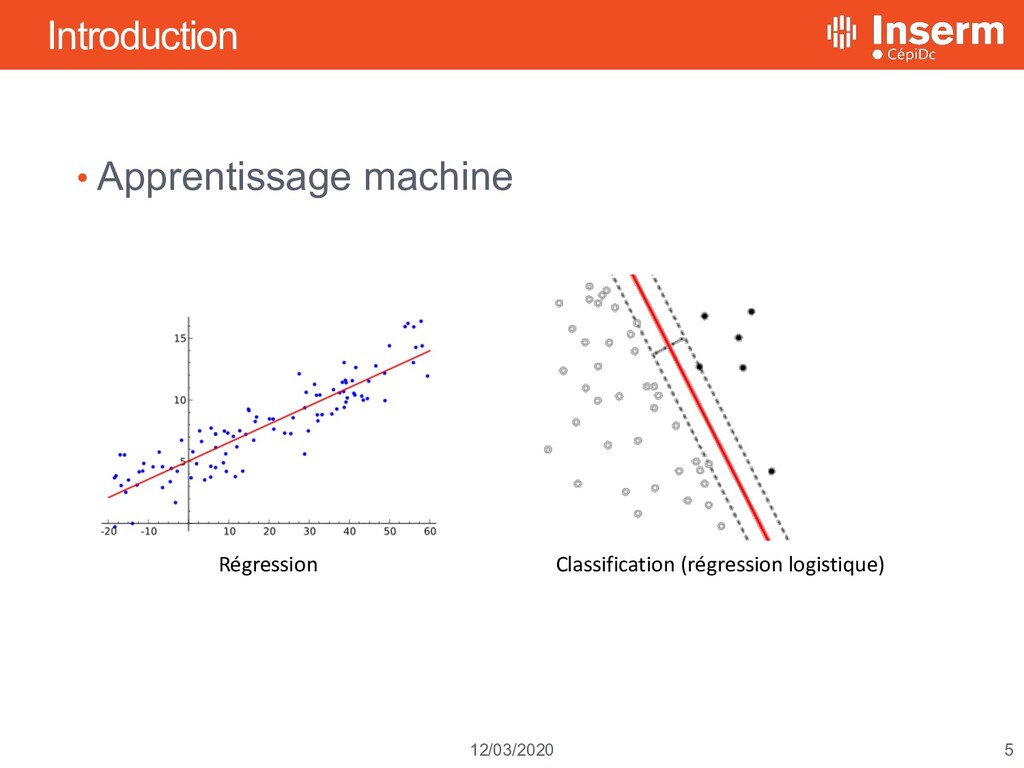
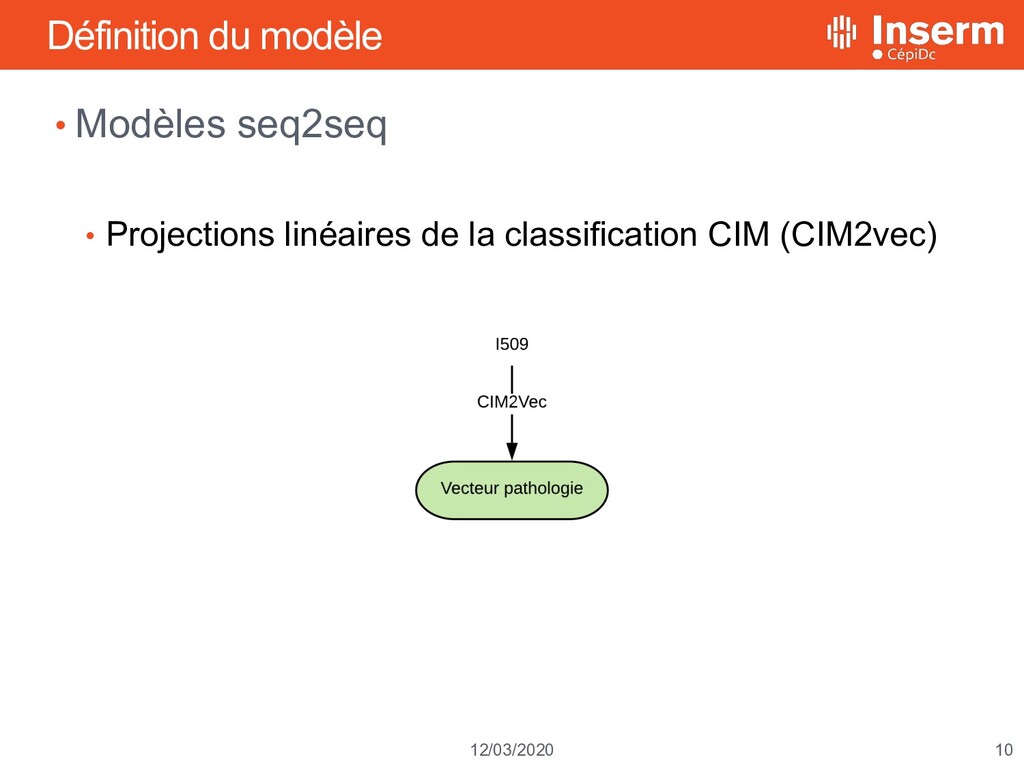
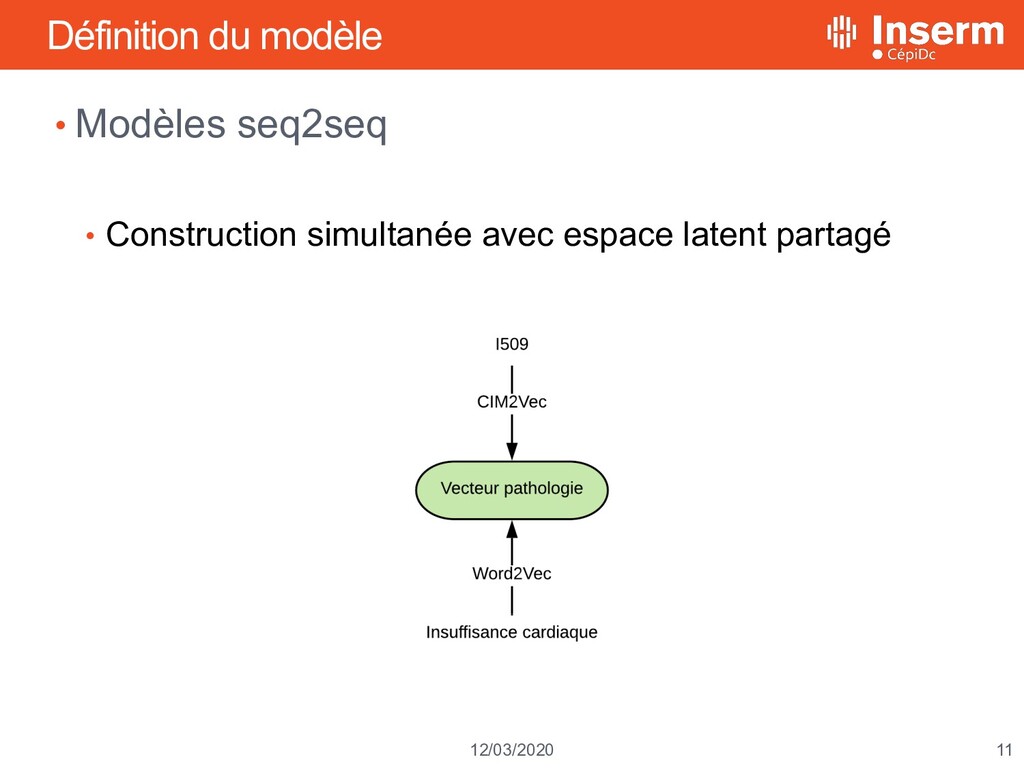
décès 11 mars 2020 Apprentissage profond et reconnaissance d’entités médicales CIM10 à partir du langage naturel Louis Falissard, Claire Imbaud, Walid Ghosn, Karim Bounebache, Grégoire Rey
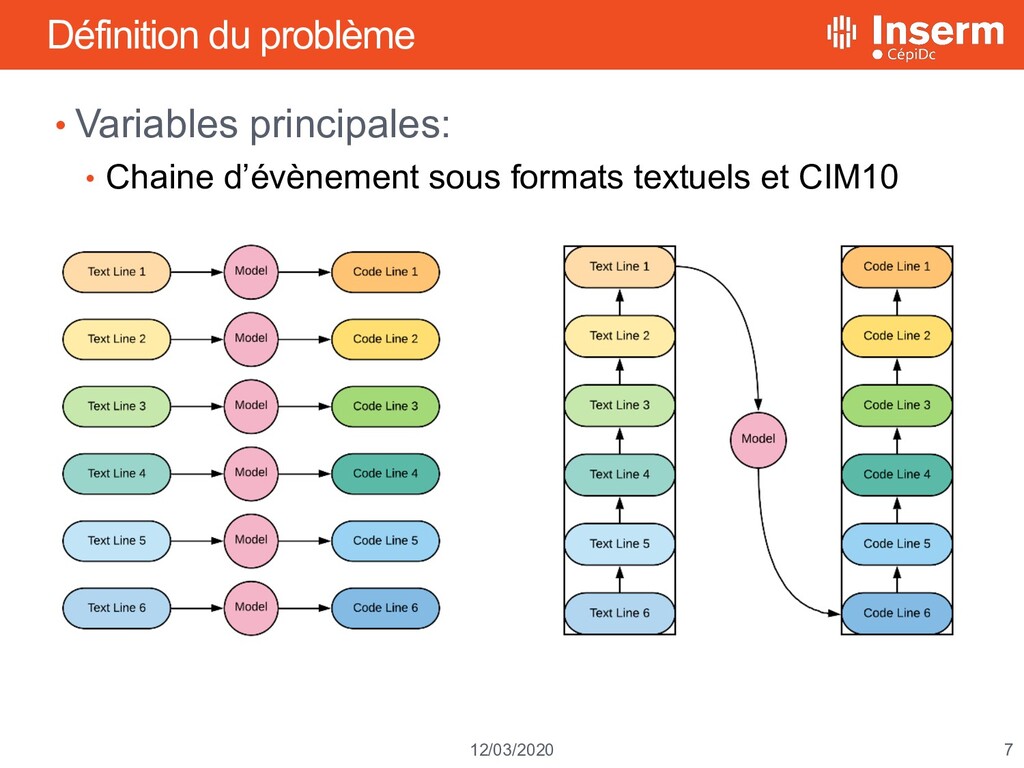
de décès • Renseignée par le médecin sur le certificat en langage naturel • Convertie en code CIM10 préalablement au codage • Principale source d’information impliquée dans les règles de décisions de l’OMS Line Natural language ICD10 encoding 1 STROKE IN SEPTEMBER LEFT HEMIPARESIS I64 G819 2 FALL SCALP LACERATION FRACTURE HUMERUS S010 W19 S423 3 CORONARY ARTERY DISEASE I251 4 ACUTE INTRACRANIAL HEMORRHAGE I629 6 DEMENTIA DEPRESSION HYPERTENSION F03 F329 I10
Base de données du CépiDc sur les années 2011 à 2016 • Base exhaustive des certificats de décès en France • ≈ 3 millions d’observations • Conditions favorables à l’exploitation de méthodes d’apprentissage profond
Choix du modèle: Transformer (légèrement modifié pour gérer les variables conditionnelles) • Implémentation pratique du modèle avec la version Python de la librairie tensorflow • Optimisation pendant 500 000 itérations réparties en parallèle sur trois GPUs Nvidia RTX 2070 Source: Attention is all you need (Vaswani et al, 2016)
performances • Définition de la F-mesure utilisée − Un code est vrai positif si le modèle le prédit et qu'il est contenu dans la valeur cible − Un code est faux positif si le modèle le prédit et qu'il n'est pas contenu dans la valeur cible − Un code est faux négatif s'il n'est pas prédit et qu'il est contenu dans la valeur cible
performances • F-mesure de 0.952 (avec ensemble de modèles) • Comparaison avec l’état de l’art: F-mesure de 0.825 (système expert + SVM) • Avancée récente: réplication de la méthode sur données anglaises (6 millions d’observations) • F-mesure de 0,987 (modèle unique) • Comparaison avec l’état de l’art: F-mesure de 0.85 (apprentissage profond avec réseau récurrent) Source: CLEF eHealth 2017 Multilingual Information Extraction task overview: ICD10 coding of death certificates in English and French (Névéol et al, 2017)
performances de niveau nosologiste • Multiples applications potentielles • Contrôle de qualité • Accélération de la production de données • Codage rétrospectif homogène • Perspectives: • Amélioration des performances en exploitant des données multilingues
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}