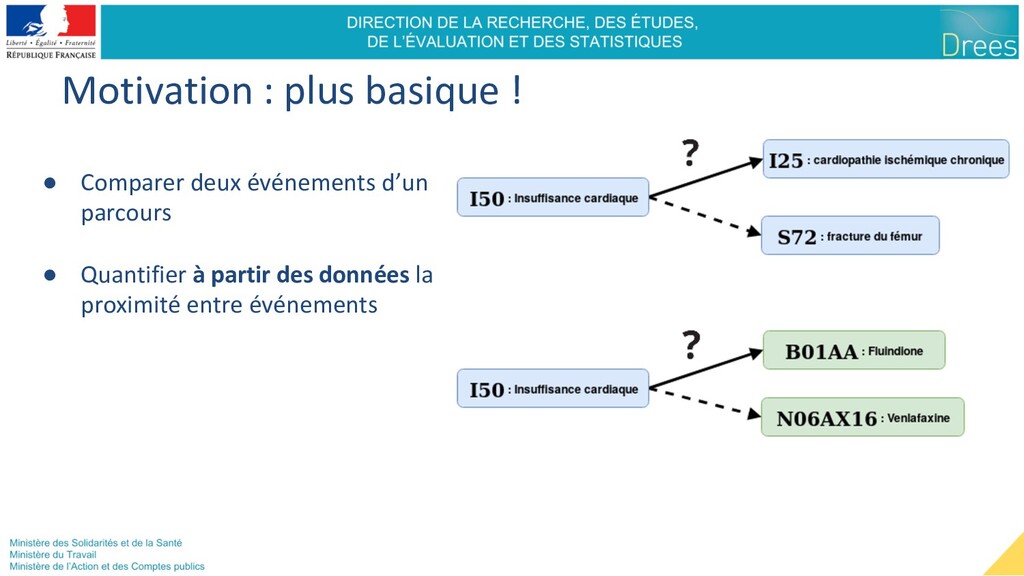
sont proches ssi ils apparaissent dans des contextes similaires (“You shall know a word by the company it keeps”, hypothèse de distribution de Firth, 1957) La reine est assise sur le trône et discute avec le roi des problèmes du royaume. On force deux mots à se rapprocher quand ils co-occurrent dans une fenêtre de taille donnée (exemple 5 mots). fenêtre = 2 x 5 mots
(SNDS) est un pseudonymisées couvrant l'ensemble de la population française et contenant l'ensemble des soins présentés au remboursement. Créé en 2016 dans la continuité d'un entrepôt précédent, géré par la Caisse Nationale de l'Assurance Maladie (CNAM), il permet de chaîner : - les données de l'assurance maladie (base SNIIRAM) - les données des hôpitaux (base PMSI) - les causes médicales de décès (base du CépiDC de l'Inserm) En quelques chiffres, le SNDS c'est plus de 3000 variables, et un flux annuel de : - 1,2 milliards de feuilles de soins - 11 millions de séjours hospitaliers - 500 millions d'actes - Plusieurs To de données
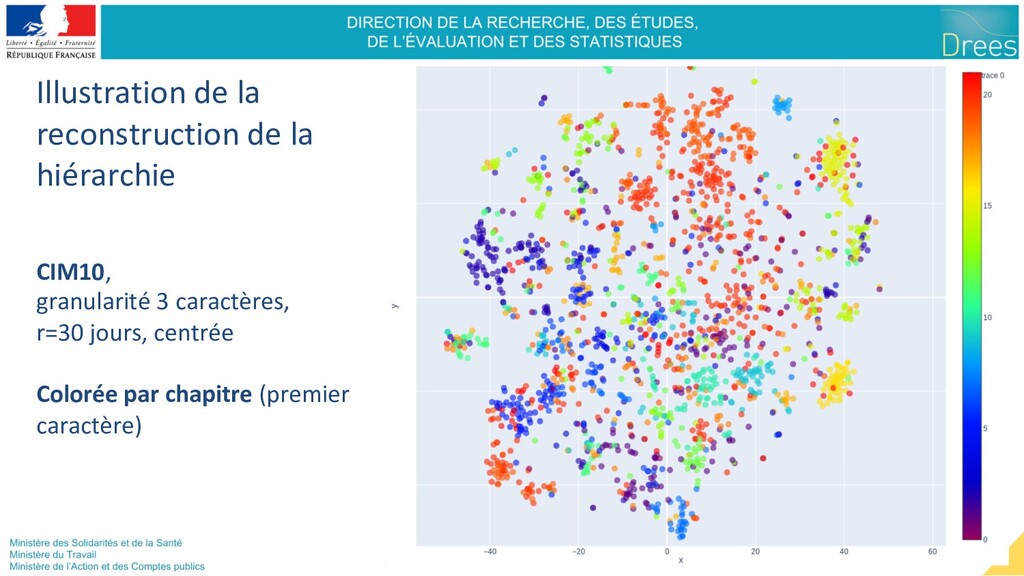
en année et regarder les vecteurs évoluant le plus -> Premiers résultats encourageant https://drees.shinyapps.io/embeddings3peri odes100parmi15k/ • Aide au phénotypage : ◦ Détection de population/pathologie en partant d’un code central et en incluant ses plus proches voisins. Intéressant en transfer learning -> Difficulté d’évaluer l’efficacité car manques de gold standard !
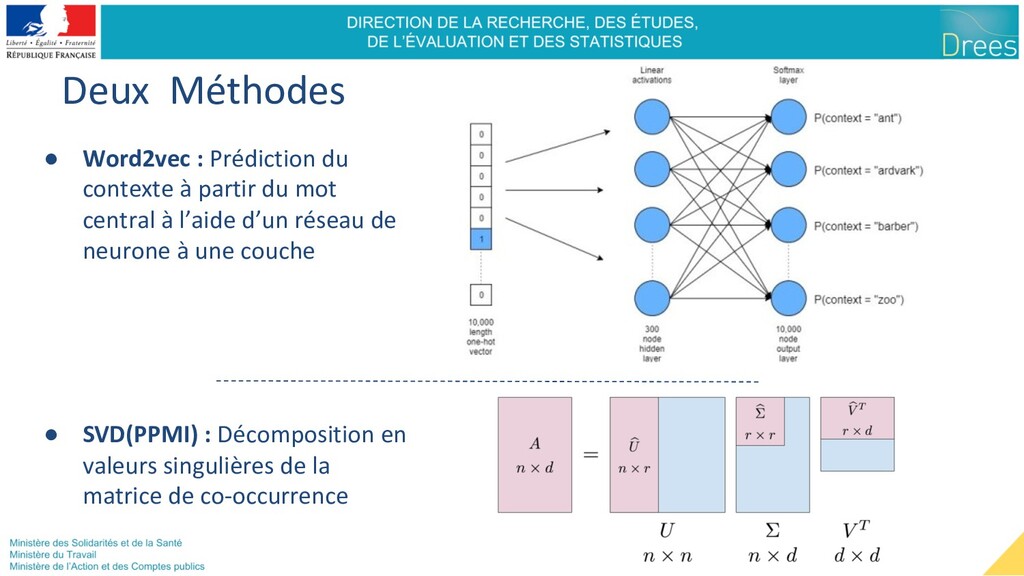
Y.-I. Chiu, et D. Sontag, « Learning Low-Dimensional Representations of Medical Concepts », AMIA Jt Summits Transl Sci Proc. 2016, p. 41–50, 2016. - A. L. Beam et al., « Clinical Concept Embeddings Learned from Massive Sources of Multimodal Medical Data », arXiv:1804.01486 [cs, stat], avr. 2018. Références sur word2vec en langages : - T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, et J. Dean, « Distributed Representations of Words and Phrases and their Compositionality », Nips process, vol. 2013, p. 9. - O. Levy et Y. Goldberg, « Neural Word Embedding as Implicit Matrix Factorization », Nips process, vol. 2014, p. 9 Codes : - SNDS2vec webapp, exploration : - lien externe : http://snds2vec.health-data-hub.fr:8051/ - Code source application : https://gitlab.com/DREES_code/OSAM/appli_snds2vec_fr - Notebook d’explorations (python) : https://gitlab.com/DREES_code/OSAM/snds2vec_analyse
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}