collecte environ 9 millions de bulletins individuels (BI) : - Parmi ces bulletins, 4.7 millions font l’objet de traitements complémentaires afin de connaître le corps économique à un niveau local fin - Pour les actifs (1.7 millions de bulletins), on étudie les informations collectées sur l’employeur - Ces déclarations sont rapprochées du registre des entreprises (Sirene) afin d’identifier le numéro Siret de l’ établissement et d’enrichir les données du recensement avec l’adresse précise et l’activité économique. • Avec la procédure automatique actuelle seuls 44% des bulletins sont traités automatiquement et les autres passent en reprise manuelle entre les mains de gestionnaires (70 ETP sur 5 mois chaque année) ➔ 2 objectifs : - Essayer d’améliorer la codification automatique - Améliorer et enrichir l’interface de reprise avec un moteur de recommandations
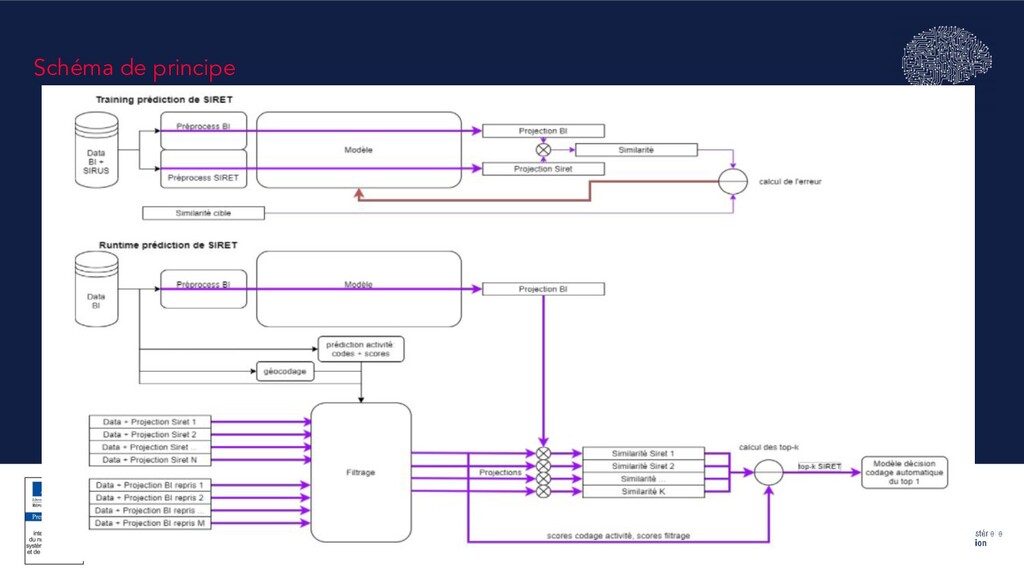
dans la chaîne de production du RP, “le produit” est un ensemble de briques modulaires et autonomes qui peuvent chacune être intégrées, ou pas, en fonction des performances. • L’algorithme : Réseaux de neurones “siamois” visant à trouver le SIRET de l’employeur indiqué sur le BI: • Répond à un problème de classification avec 8 millions de classes ! • Les BI et les SIRET passent par un même réseau et sont projetés dans un même espace vectoriel, • Apprentissage d’une distance qui va rapprocher les paires (BI, SIRET) concordantes, et éloigner les paires discordantes, • On peut ensuite, pour un BI, requêter les “k” SIRET les plus similaires parmi un ensemble de SIRET pré-sélectionnés avec elasticsearch (requêtes spécifiques sur raison sociale, géolocalisation, hôpitaux ...) et des BI “ressemblants” • Une nouvelle interface de reprise pour les gestionnaires : • Plus pratique • Propose des échos pertinents et prend en compte les choix des gestionnaires pour faire évoluer les prédictions suivantes
résultats selon tous les points de vue ne sont pas encore connus : • Métriques de performance de l’algorithme : • Résultats en sortie de méta-modèle (sur 200k BI « codables »): Top 1 : 67.7%, Top 3 : 78.4%, Top 5 : 82.71%, Top 10: 90% Codification automatique: • Seuil à choisir: precision 0.80 : seuil = 0.23, rappel = 92% ➔ ~77.5% de BI codés auto precision 0.90 : seuil = 0.75, rappel = 78% ➔ ~58.6% de BI codés auto precision 0.95 : seuil = 0.94, rappel = 58% ➔ ~41.3% de BI codés auto • Du point de vue métier et au regard des objectifs de l’Insee : • En attente d’un test de reprise sur 50 000 bulletins, en mai
qualité du code • Développement de compétences sur des briques techniques peu ou pas utilisées dans la réalisation d’études statistiques “classiques” • Code paramétrable • Nouveaux modèles • Difficultés à faire cohabiter les méthodes de travail de ce type d’expérimentations avec les “habitudes” de la maison • Difficultés à communiquer sur les résultats apportés par l’IA
chaîne sur 50 000 bulletins avec l’aide d’une vingtaine de gestionnaires pilotes • Une personne de la DSI (équipe maintenance de l’ancienne application) vient rejoindre le projet et sera en charge de la mise en test de l’application, de son suivi, de produire les résultats de la campagne et d’ évaluer les performances ➔ Décisions sur les modules à pérenniser
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}