Projet d'analyse des flux médiatiques et de production d'indicateurs associés (INA)
Le projet d'analyse des flux médiatiques et de production d'indicateurs associés vise à enrichir le débat public sur le sujet de la représentativité dans les médias.
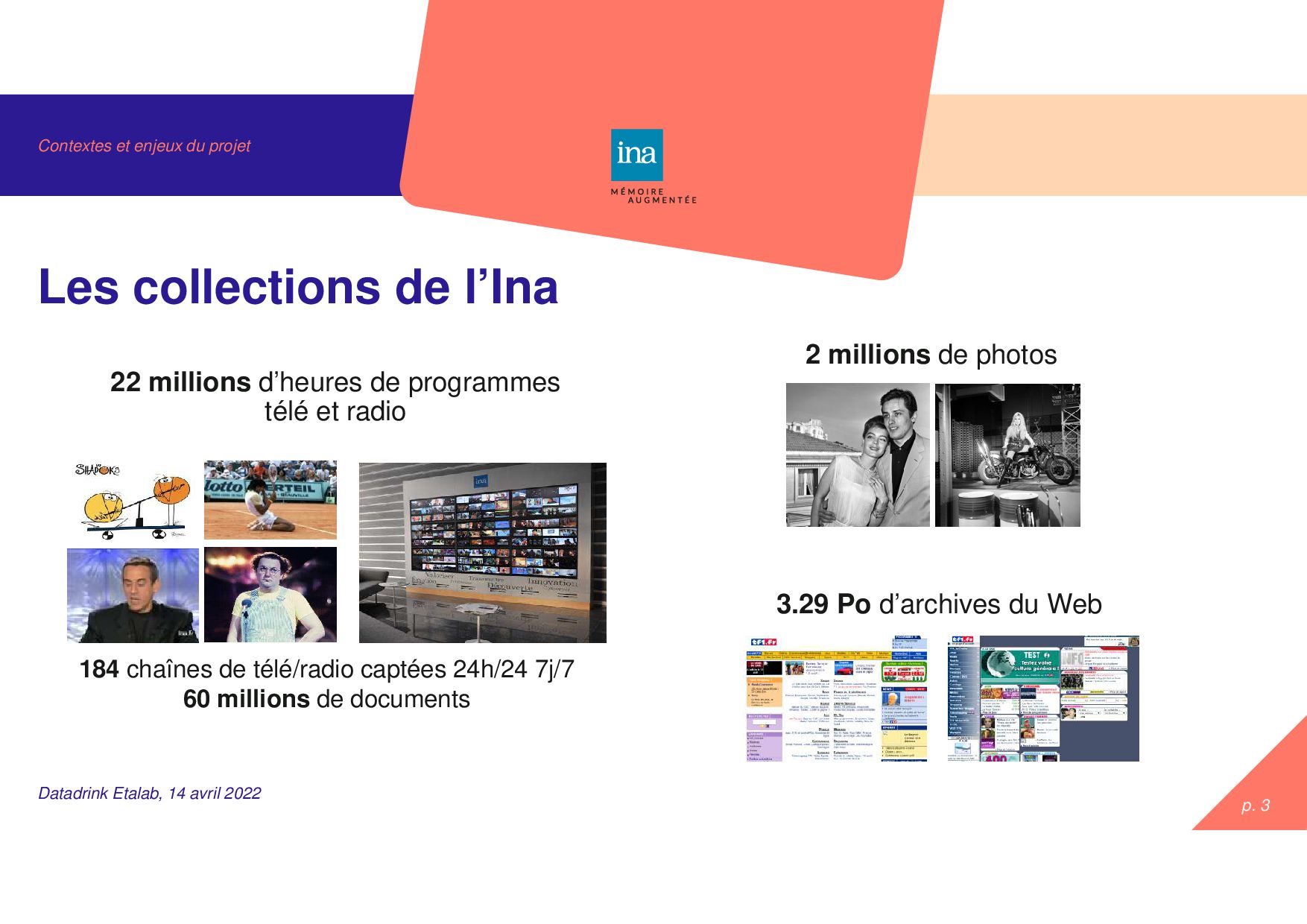
avril 2022 Les collections de l’Ina 22 millions d’heures de programmes télé et radio 2 millions de photos 3.29 Po d’archives du Web 184 chaînes de télé/radio captées 24h/24 7j/7 60 millions de documents
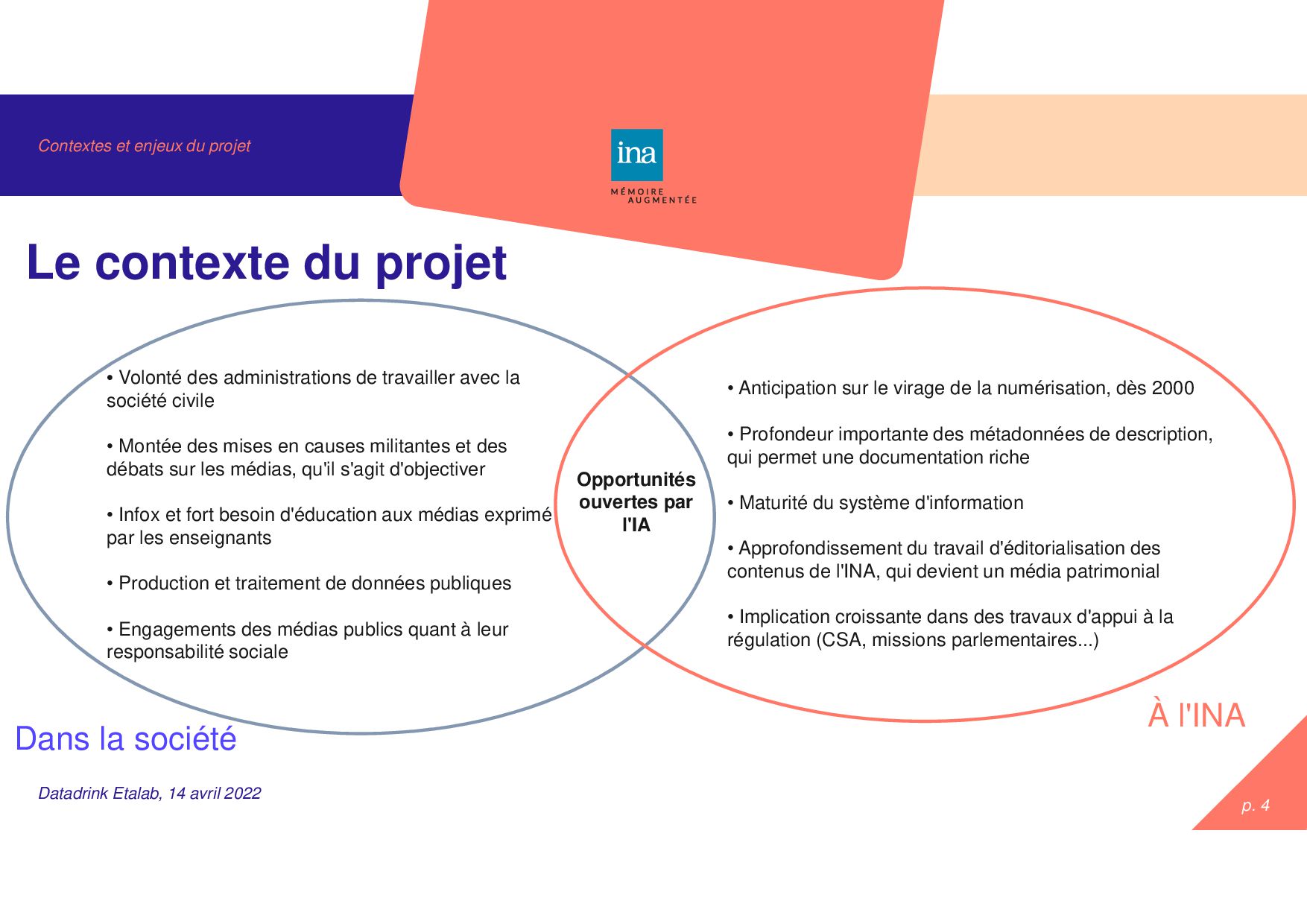
avril 2022 Le contexte du projet Dans la société À l'INA • Anticipation sur le virage de la numérisation, dès 2000 • Profondeur importante des métadonnées de description, qui permet une documentation riche • Maturité du système d'information • Approfondissement du travail d'éditorialisation des contenus de l'INA, qui devient un média patrimonial • Implication croissante dans des travaux d'appui à la régulation (CSA, missions parlementaires...) • Volonté des administrations de travailler avec la société civile • Montée des mises en causes militantes et des débats sur les médias, qu'il s'agit d'objectiver • Infox et fort besoin d'éducation aux médias exprimé par les enseignants • Production et traitement de données publiques • Engagements des médias publics quant à leur responsabilité sociale Opportunités ouvertes par l'IA
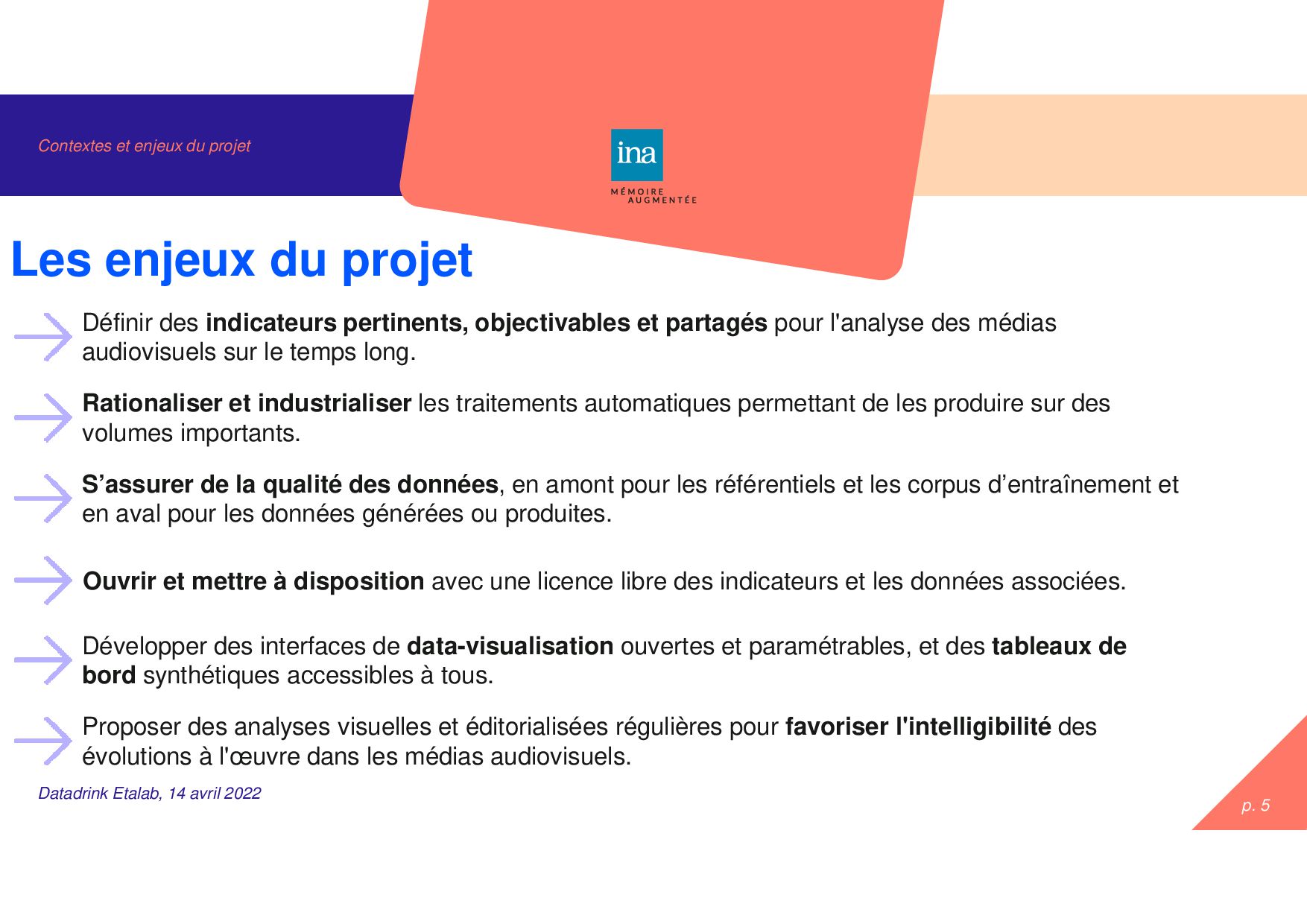
avril 2022 Les enjeux du projet Définir des indicateurs pertinents, objectivables et partagés pour l'analyse des médias audiovisuels sur le temps long. Rationaliser et industrialiser les traitements automatiques permettant de les produire sur des volumes importants. Développer des interfaces de data-visualisation ouvertes et paramétrables, et des tableaux de bord synthétiques accessibles à tous. Proposer des analyses visuelles et éditorialisées régulières pour favoriser l'intelligibilité des évolutions à l'œuvre dans les médias audiovisuels. Ouvrir et mettre à disposition avec une licence libre des indicateurs et les données associées. S’assurer de la qualité des données, en amont pour les référentiels et les corpus d’entraînement et en aval pour les données générées ou produites.
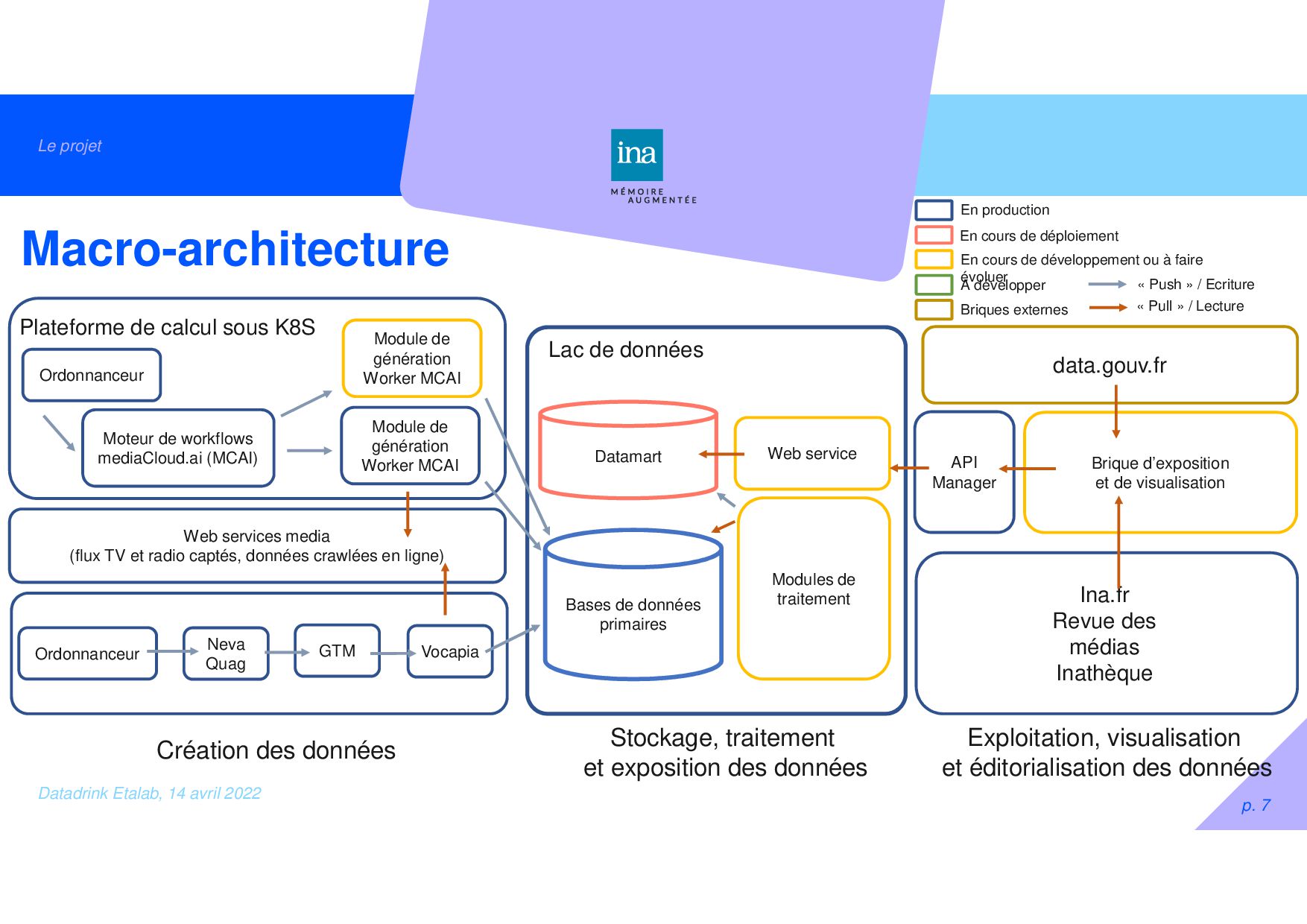
Moteur de workflows mediaCloud.ai (MCAI) Web services media (flux TV et radio captés, données crawlées en ligne) Module de génération Worker MCAI Module de génération Worker MCAI Création des données Lac de données Brique d’exposition et de visualisation Bases de données primaires Modules de traitement data.gouv.fr Datamart Ina.fr Revue des médias Inathèque Stockage, traitement et exposition des données Exploitation, visualisation et éditorialisation des données En production A développer En cours de développement ou à faire évoluer Briques externes « Push » / Ecriture « Pull » / Lecture Ordonnanceur Plateforme de calcul sous K8S En cours de déploiement API Manager Web service Ordonnanceur GTM Neva Quag Vocapia
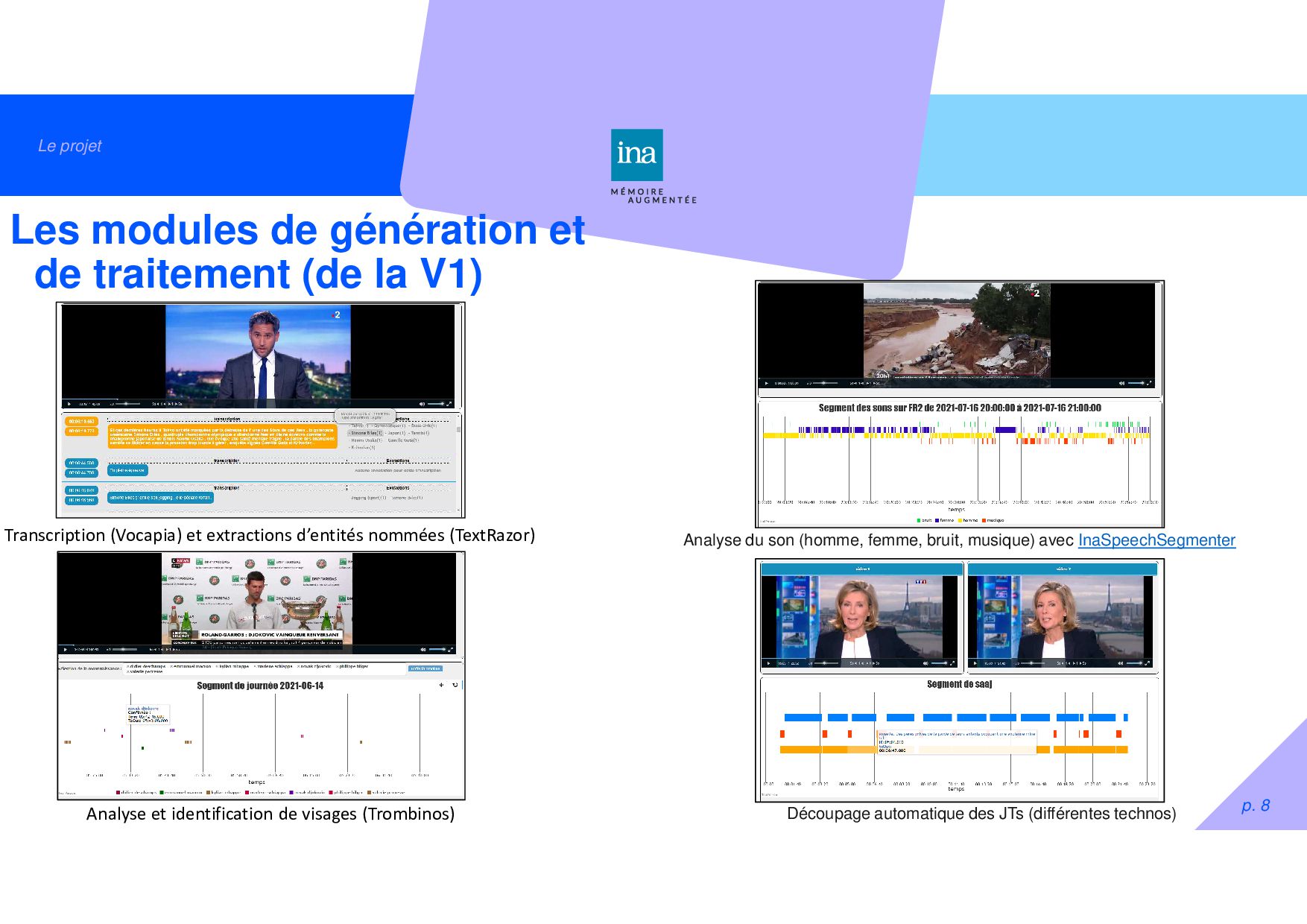
traitement (de la V1) Analyse du son (homme, femme, bruit, musique) avec InaSpeechSegmenter Transcription (Vocapia) et extractions d’entités nommées (TextRazor) Analyse et identification de visages (Trombinos) Découpage automatique des JTs (différentes technos)
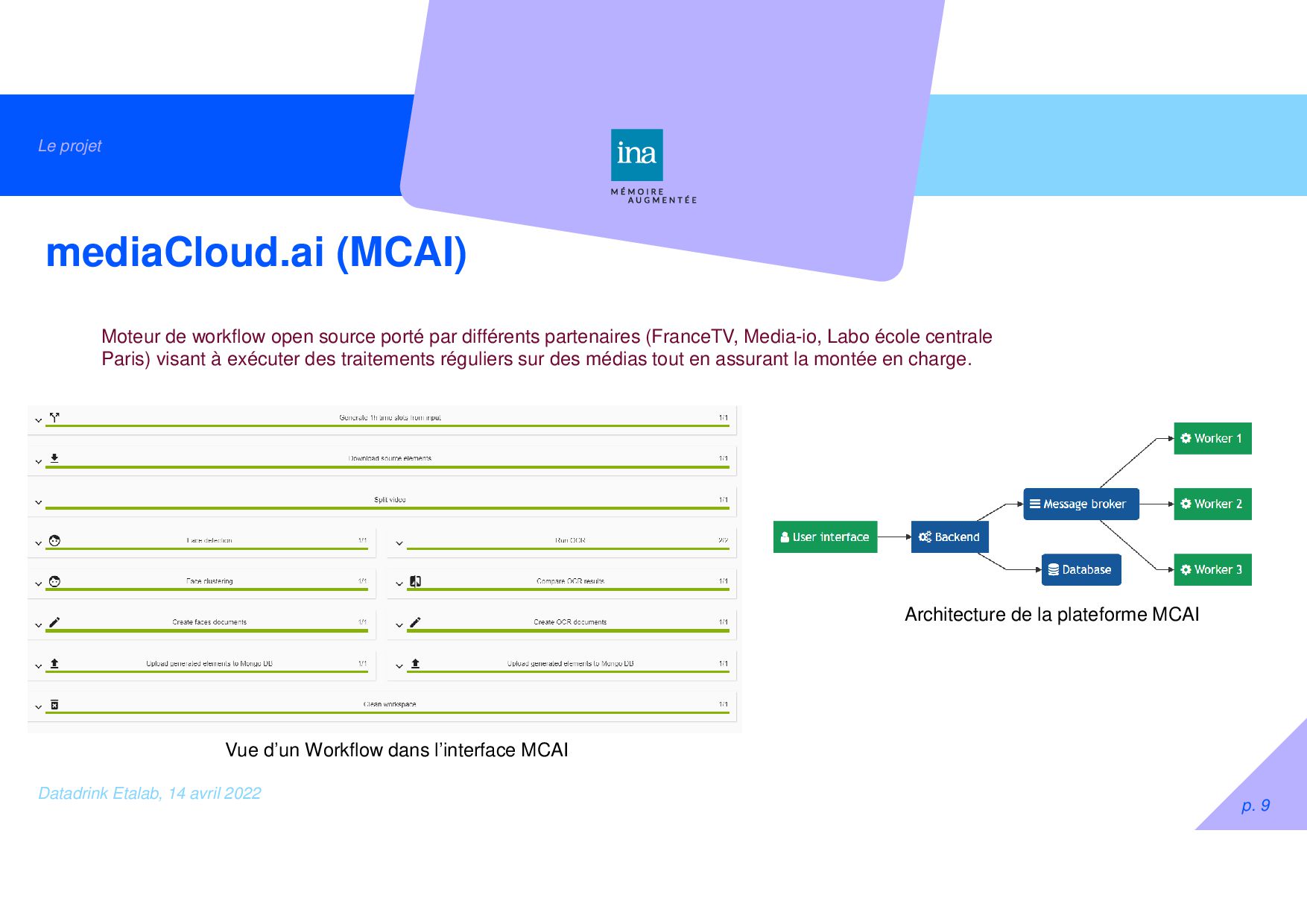
(MCAI) Moteur de workflow open source porté par différents partenaires (FranceTV, Media-io, Labo école centrale Paris) visant à exécuter des traitements réguliers sur des médias tout en assurant la montée en charge. Architecture de la plateforme MCAI Vue d’un Workflow dans l’interface MCAI
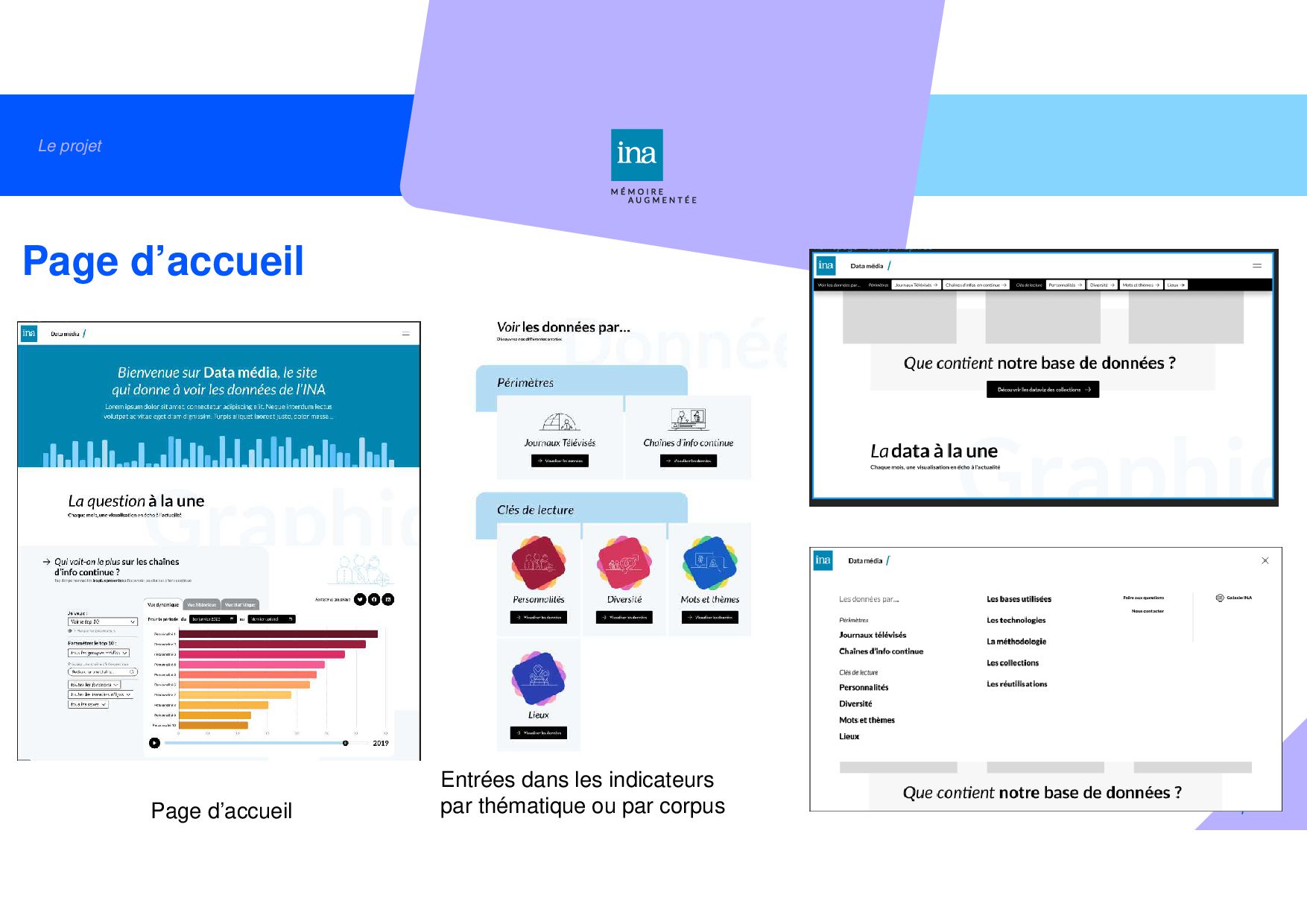
du site Diversité Personnalités Lieux Mots, thèmes, genres Chaîne d’information continue • Quelles personnalités voit-on le plus sur les chaînes d’information continue ? • Explorer la présence médiatique des personnalités Journaux télévisés • Quelles personnalités sont mentionnées dans les JT ? • Quelles personnalités ont été au cœur des sujets de JT ? • Qui sont les présentateurs des journaux télévisés ? • Explorer la présence médiatique des personnalités • Quels lieux sont mentionnés dans les JT ? • Quels sont les lieux les plus couverts par les sujets de journaux télévisés • Les JTs parlent-ils de chez moi ? • Quelles sont les rubriques les plus présentes dans les journaux télévisés ? • Comment chaque rubrique a été présente dans les journaux télévisés ? • Quels sont les mots-clés les plus présents dans les journaux télévisés ? • Explorez les journaux télévisés à travers leurs mots-clés • Explorez les journaux télévisés à travers les mots prononcés Tous programmes • Hommes-femmes : quelle répartition du temps de parole par jour ? • Hommes-femmes : quelle répartition du temps de parole dans le temps ? • Hommes-femmes : quelle évolution du temps de parole ? • Hommes-femmes : sur quel calendrier ? • Données issues de l’analyse de visages • Données issues de la transcription et l’extraction d’entités nommées • Données issues d’InaSpeechSegmenter • Données issues de l’OCR des incrustations à l’écran • Mix de données automatiques • Données issues du catalogage et de la documentation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}