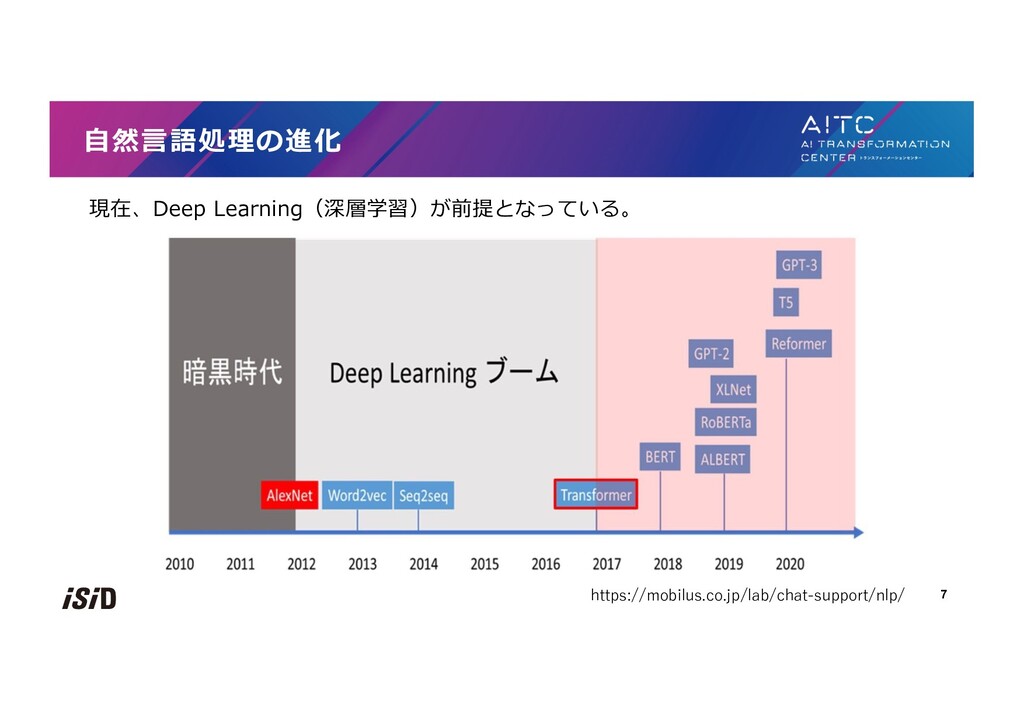
[negative] a sometimes tedious film. 2⽂が同じ意味かどうか [同じ] The bird is bathing in the sink. Birdie is washing itself in the water basin. [異なる] The black dog is running through the snow. A race car driver is driving his car through the mud. https://gluebenchmark.com/leaderboard モデルの性能を計るため、英語の⾔語理解タスクのデータセットが⽤意されている。 9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![⾃然⾔語処理(Natural Language Processing) 8|⽉|24|⽇|に|開幕|する|東京|パラリンピック|は|、無|観客|で|の|開催|と|なる|。 ⾃然⾔語(⽇本語、英語など)をコンピュータに処理・理解させる技術。 基礎解析 [⽇付表現] [----イベント名-----] 機械翻訳 情報検索](https://files.speakerdeck.com/presentations/9c654535815948b7923237628aaf0469/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![GLUE(⾔語理解タスク)[Wang+ 18] モデルの性能を計るため、英語の⾔語理解タスクのデータセットが⽤意されている。 8 https://gluebenchmark.com/leaderboard](https://files.speakerdeck.com/presentations/9c654535815948b7923237628aaf0469/slide_7.jpg){kind=link}
![GLUE(⾔語理解タスク)[Wang+ 18] ポジネガ判定 [positive] itʼs charming and often affecting journey.](https://files.speakerdeck.com/presentations/9c654535815948b7923237628aaf0469/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
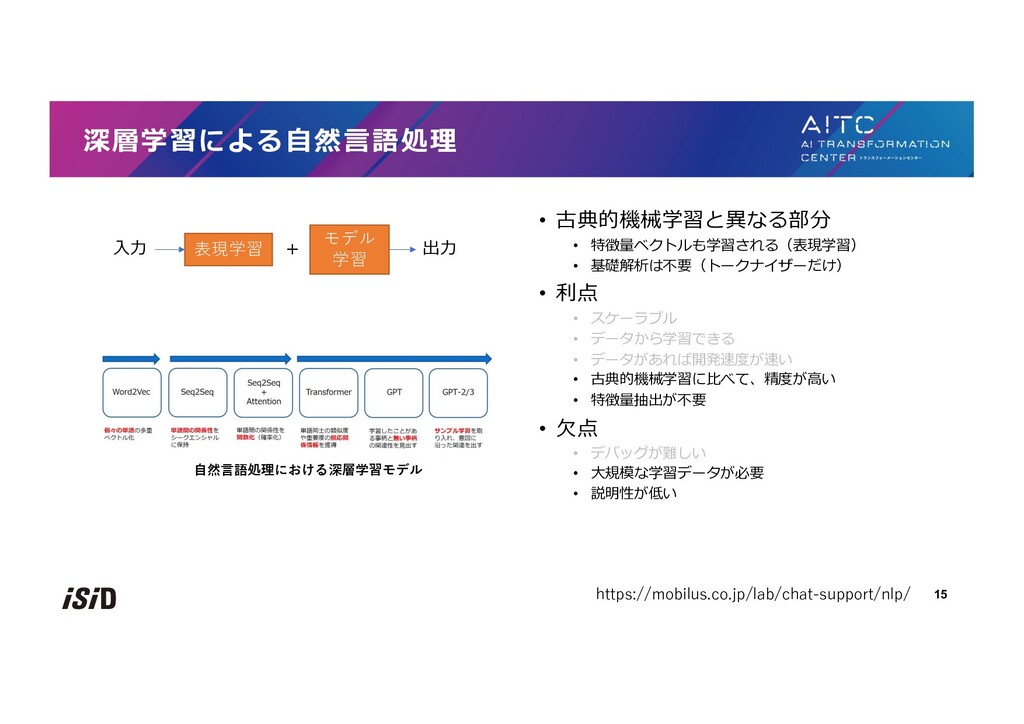
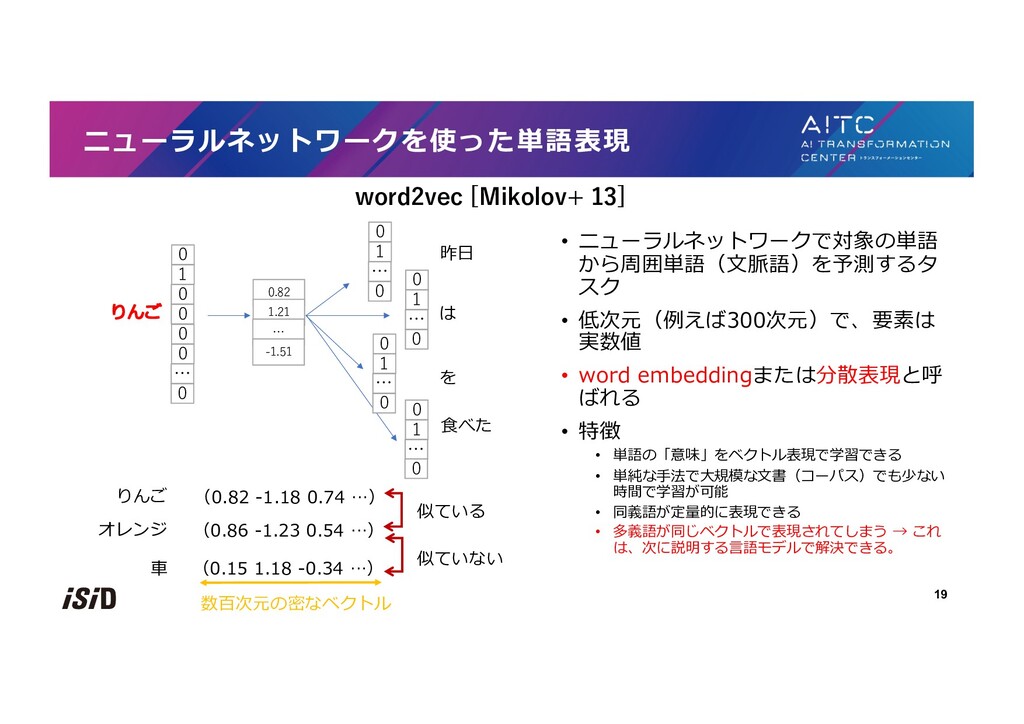
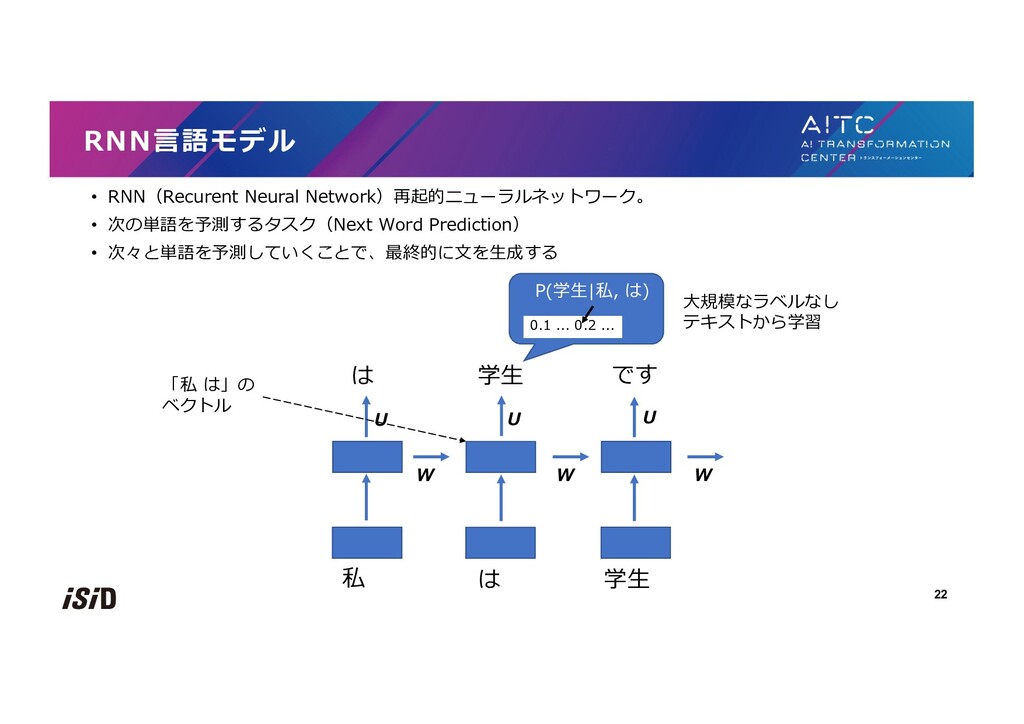
![• 分布仮説 [Firth+ 1957] • 単語の意味はその単語の⽂脈によって特徴つけられる • =似た⽂脈で出現する単語は意味が似ている • 共起に基づくベクトル表現](https://files.speakerdeck.com/presentations/9c654535815948b7923237628aaf0469/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
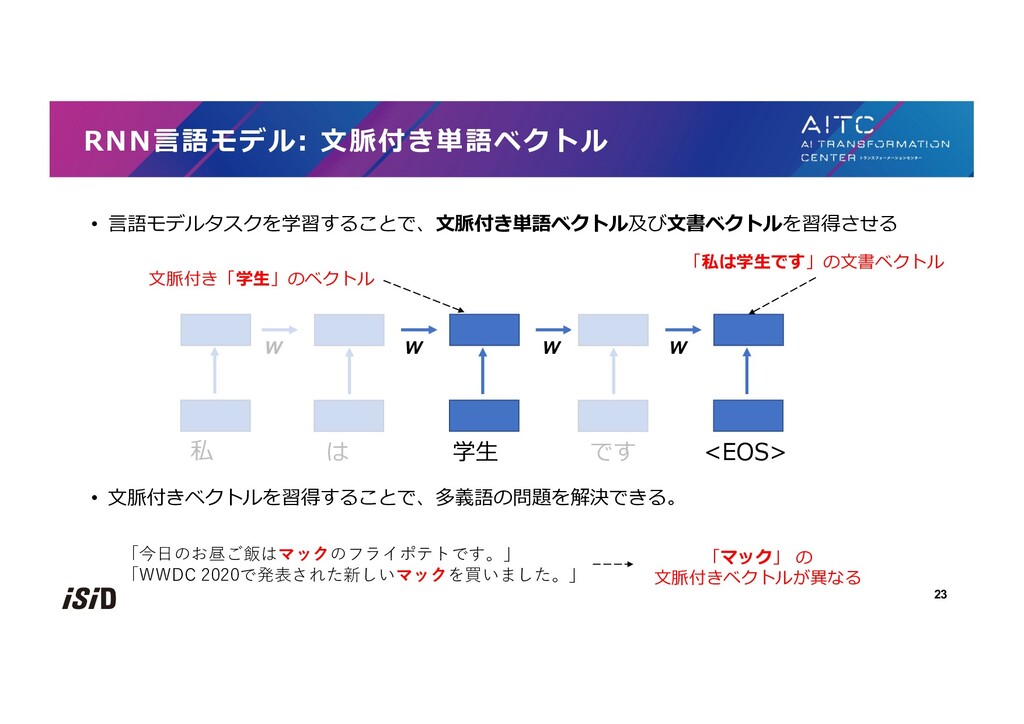{kind=link}
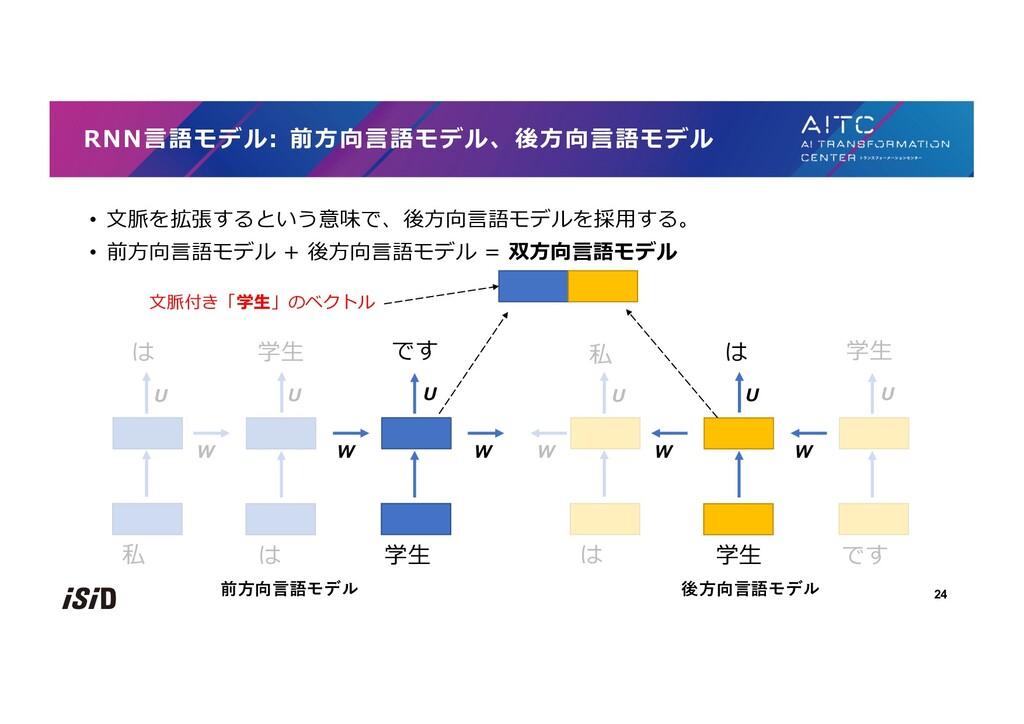{kind=link}
{kind=link}
{kind=link}
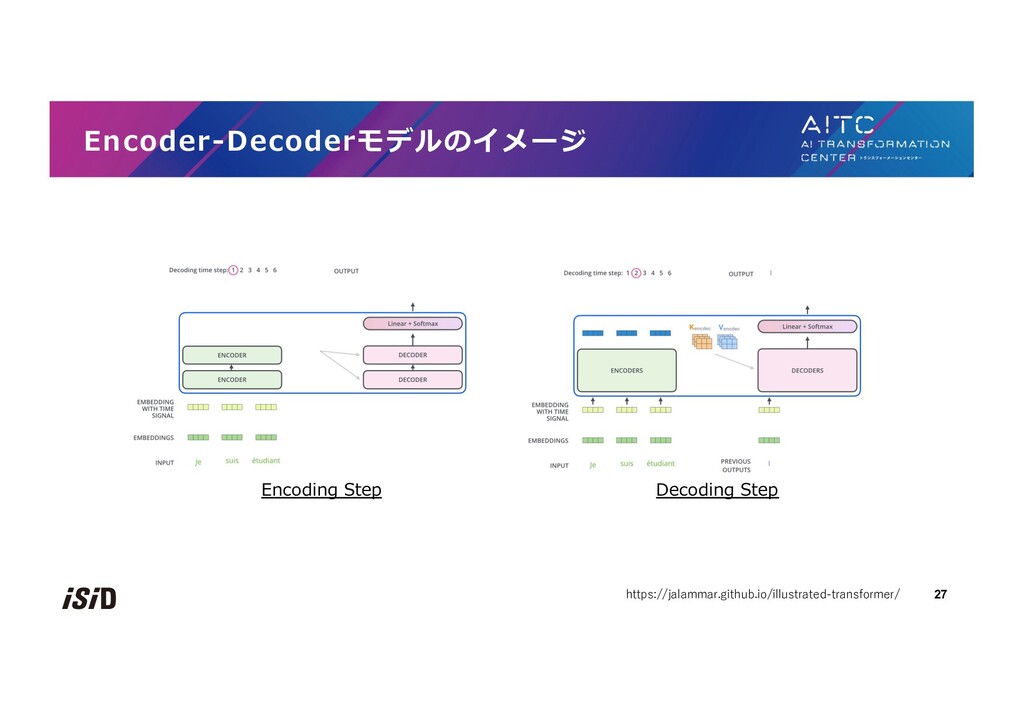{kind=link}
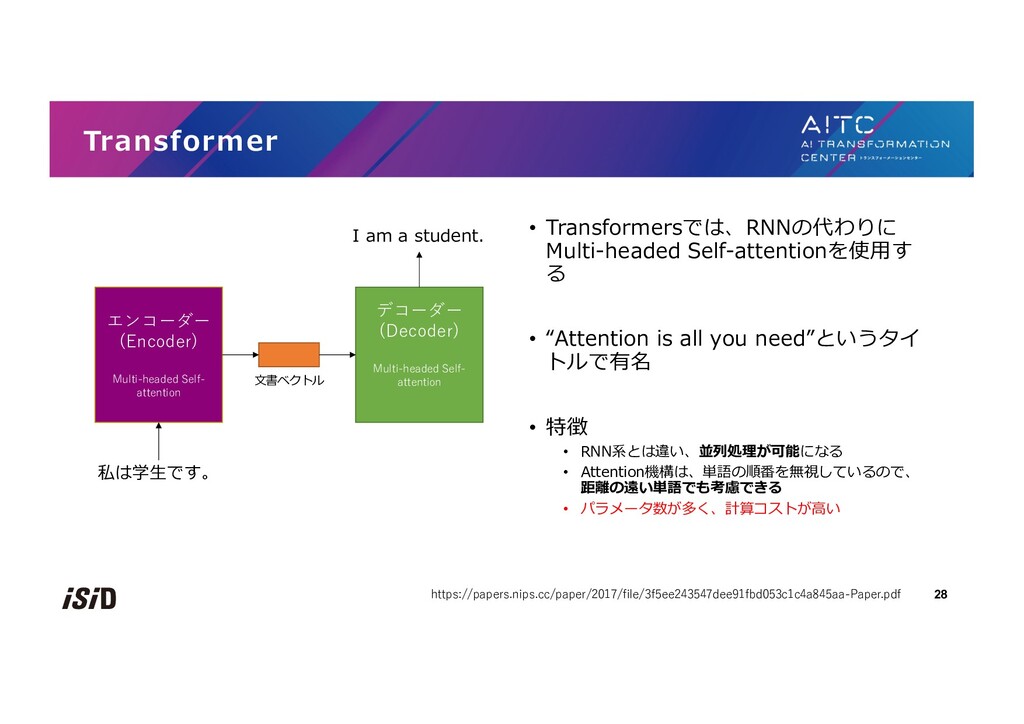{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}