norchdir ./node_modules/norch/bin/norch Index some data into norch.js: ➜ datadir curl --form document=@node_modules/ reuters-21578-json/data/full/reuters-000.json http:// localhost:3030/indexer --form filterOn=places,topics,organisations
present, it will be autogenerated { id: ‘aTotallyOptionalID’, title: ‘A Really Cool Title’, tags: [‘coolness’, ‘awsomeness’] body: ‘Bla bla bla bla, lots of text here…’ }
batches are faster if your hardware can cope. [ { id: ‘1’, title: ‘A Really Cool Title’, tags: [‘coolness’, ‘awsomeness’] body: ‘Sparkly w00p w00p, lots of text here…’ }, { id: ‘two’, title: ‘A Really Boring Title’, tags: [‘dullness’, ‘boringness’] body: ‘Bla bla bla bla, lots of text here…’ } ]
{"*": ["africa", “bank"]} } Search title field for “africa bank” { "query": {"title": ["africa", “bank"]} } Search title field for “africa”, body for “bank” { "query": {"title": [“africa”], "body": [“bank”]} }
{}} } Or define ranges of values { "query": {"*": ["africa", “bank”]}, ”facets”: { "totalamt": { "ranges":[ ["000000000000000","000000050000000"], ["000000050000001","100000000000000" ] } } } You can also sort and limit your facets
{"*": ["africa", “bank”]}, ”filter”: { “totalamt" {["000000000000000", "000000050000000"]} } } You always specify a range so to filter on one value do { "query": {"*": ["africa", “bank”]}, ”filter”: { “totalamt" {["000000050000000", "000000050000000"]} } } You can filter on as many ranges as you want.
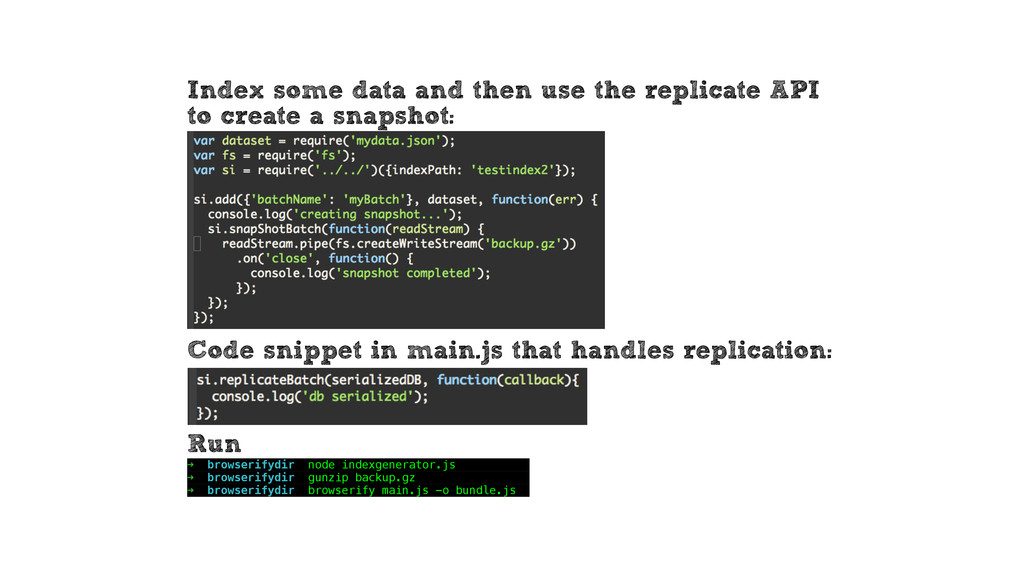
-o snapshot.gz Empty target index (if necessary) curl http://localhost:3030/empty Replicate into new or emptied index curl -X POST http://localhost:3030/replicate --data-binary @snapshot.gz -H "Content-Type: application/gzip"
queries Runs on low-end hardware (server and browser) Replication Weaknesses Strictly a small data Limited feature set Relatively small community compared to other search technologies (Elastic, Solr)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
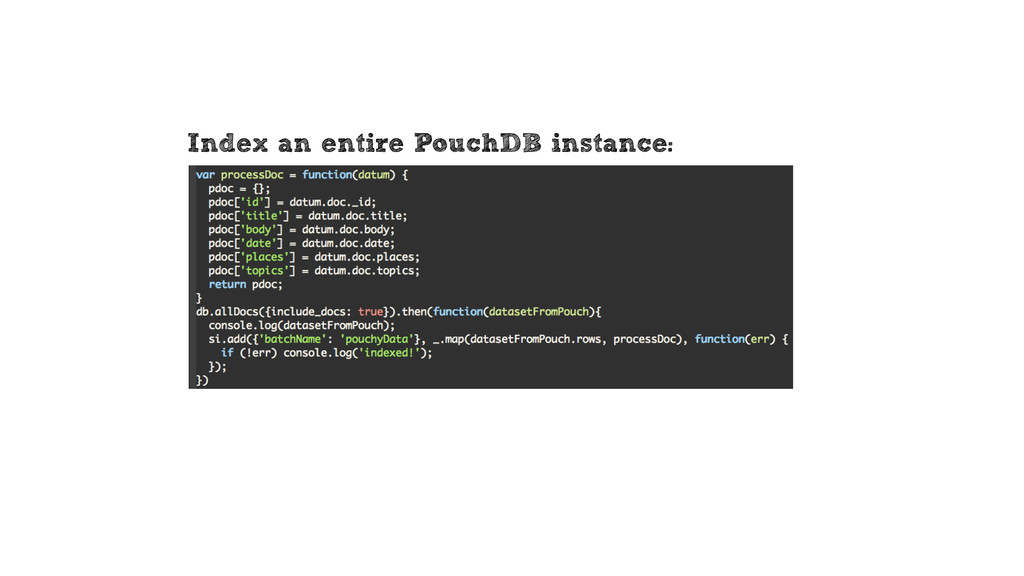{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Basic Queries Return everything in index { "query": {"*": [“*"]}](https://files.speakerdeck.com/presentations/796da1fbe2c54393b6ed54653947fa20/slide_33.jpg){kind=link}
![Basic Queries Return everything in index { "query": {"*": [“*"]}](https://files.speakerdeck.com/presentations/796da1fbe2c54393b6ed54653947fa20/slide_34.jpg){kind=link}
![Facets Simple facets { "query": {"*": ["africa", “bank”]}, ”facets”: {“totalamt":](https://files.speakerdeck.com/presentations/796da1fbe2c54393b6ed54653947fa20/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}