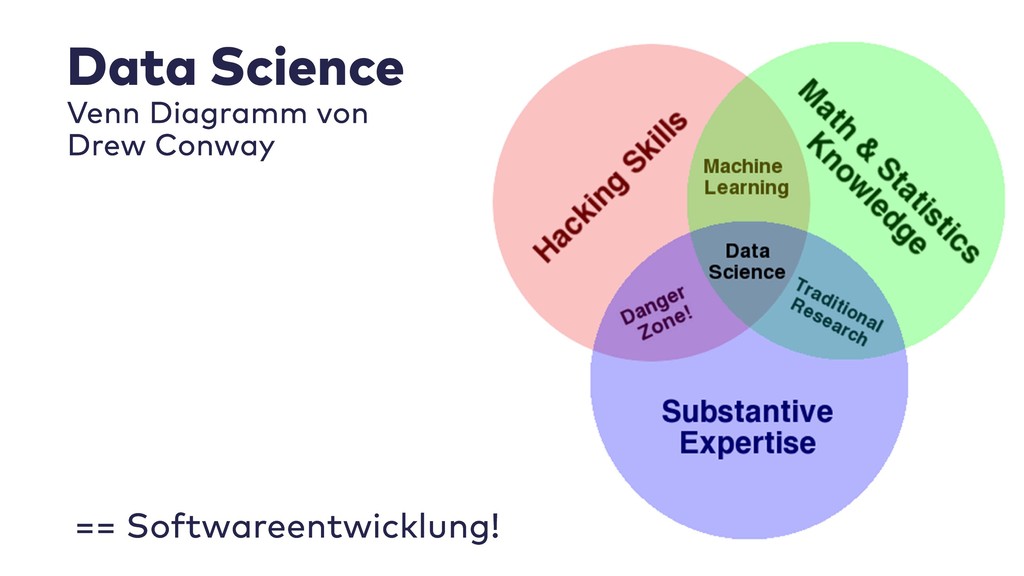
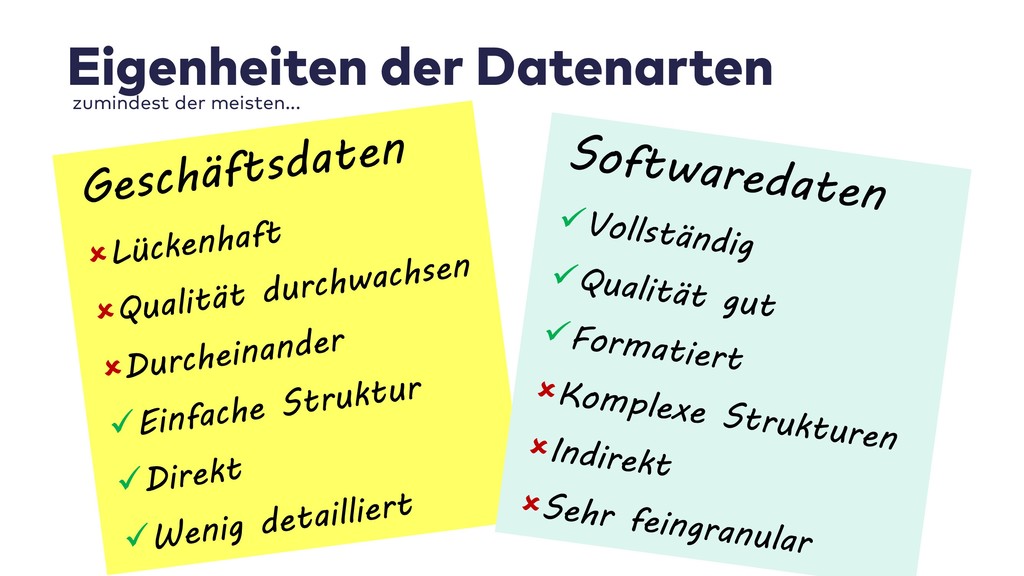
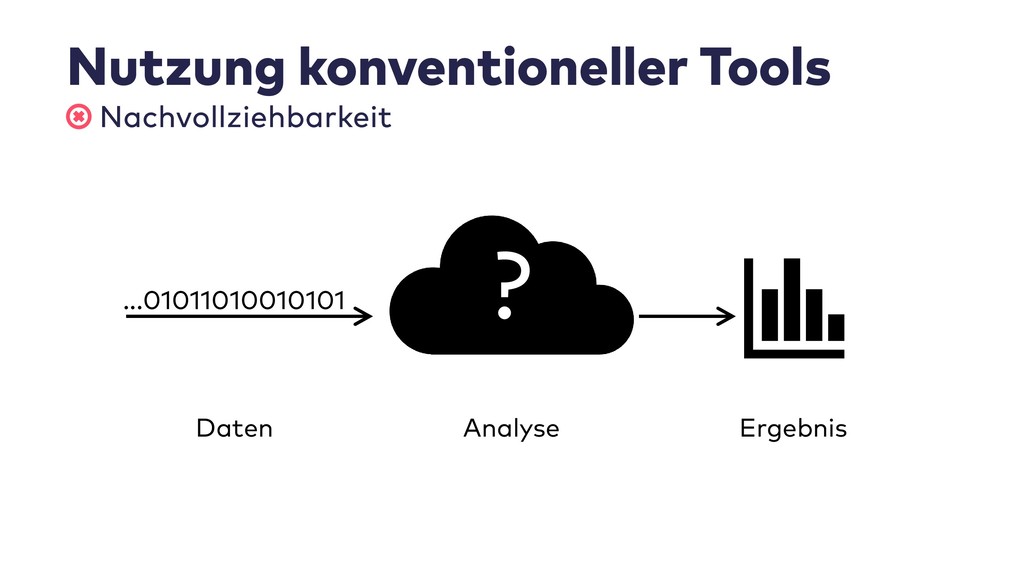
Data Science ist in aller Munde, wenn es darum geht, aus Geschäftsdaten neue Einsichten zu gewinnen. Warum nutzen wir als Softwareentwickler Data Science nicht auch für die Analyse unserer eigenen Daten?
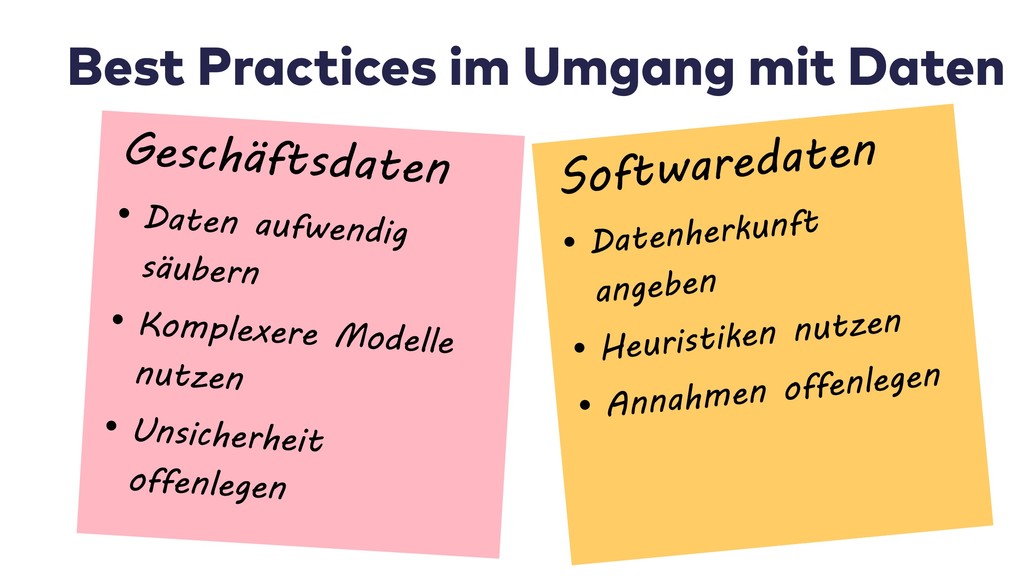
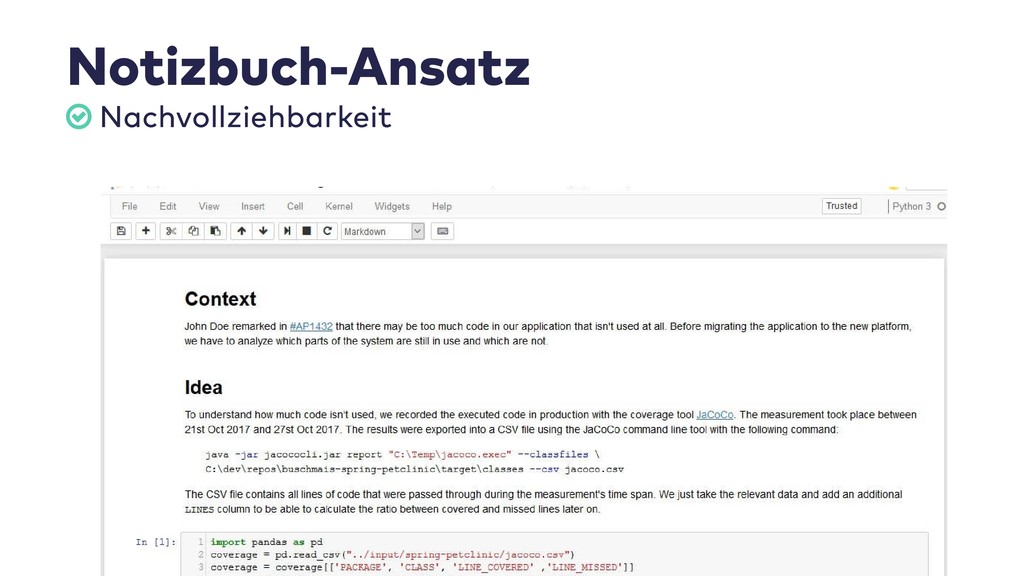
In dieser Session stelle ich Vorgehen und Best Practices von Data Scientists vor. Wir sehen uns die dazugehörigen Werkzeuge an, mit denen sich auch Probleme in der Softwareentwicklung zielgerichtet analysieren und kommunizieren lassen.
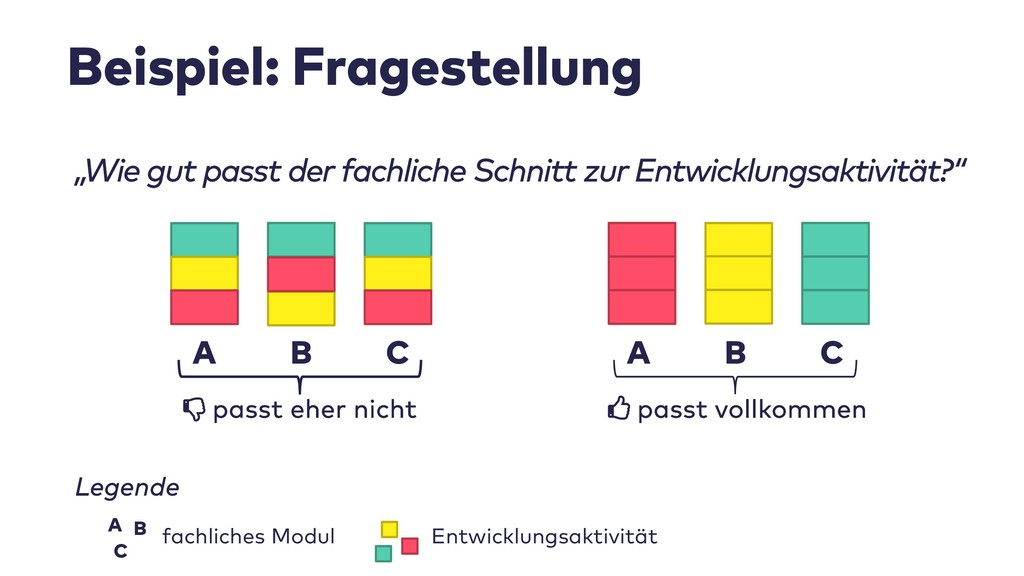
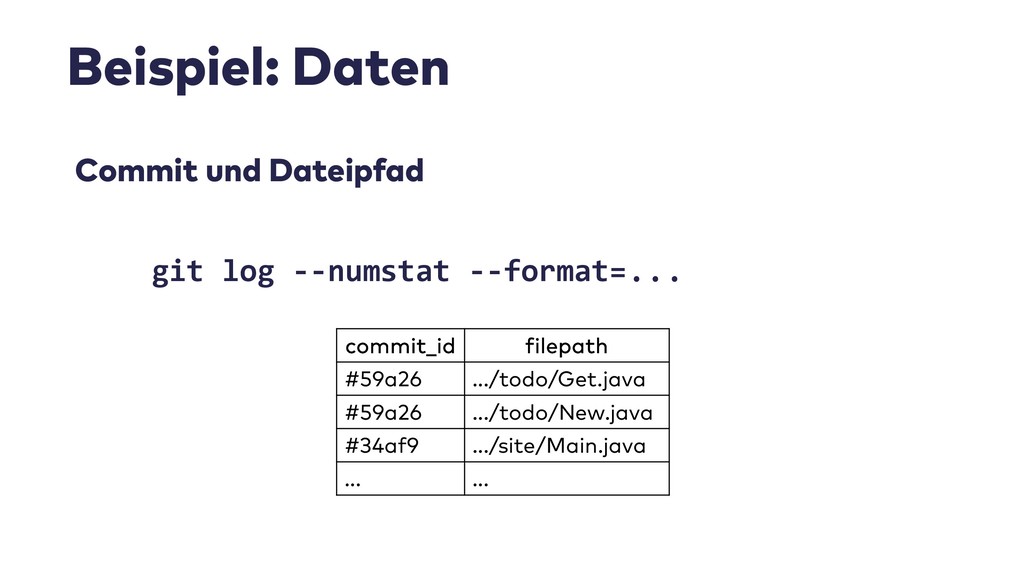
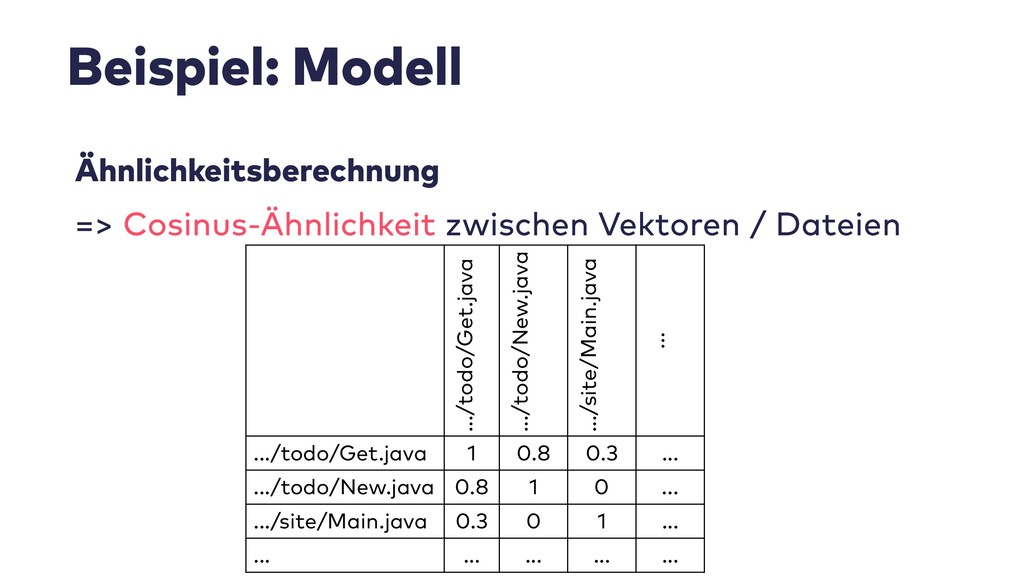
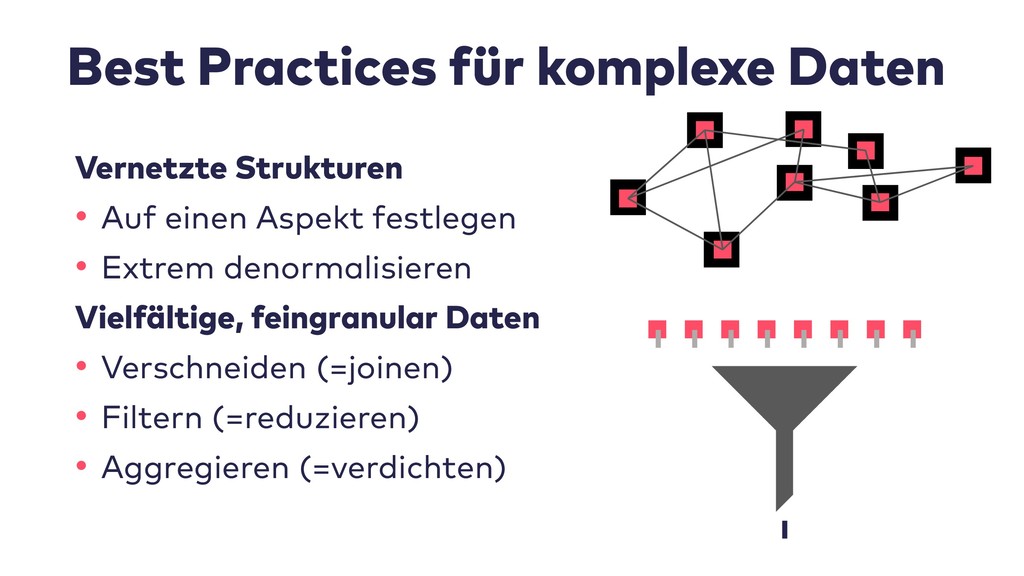
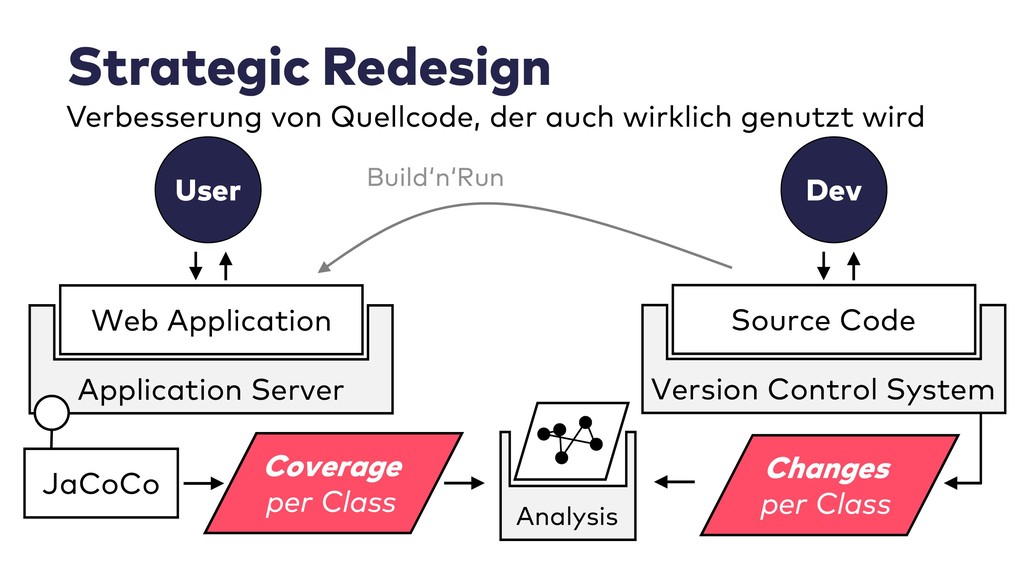
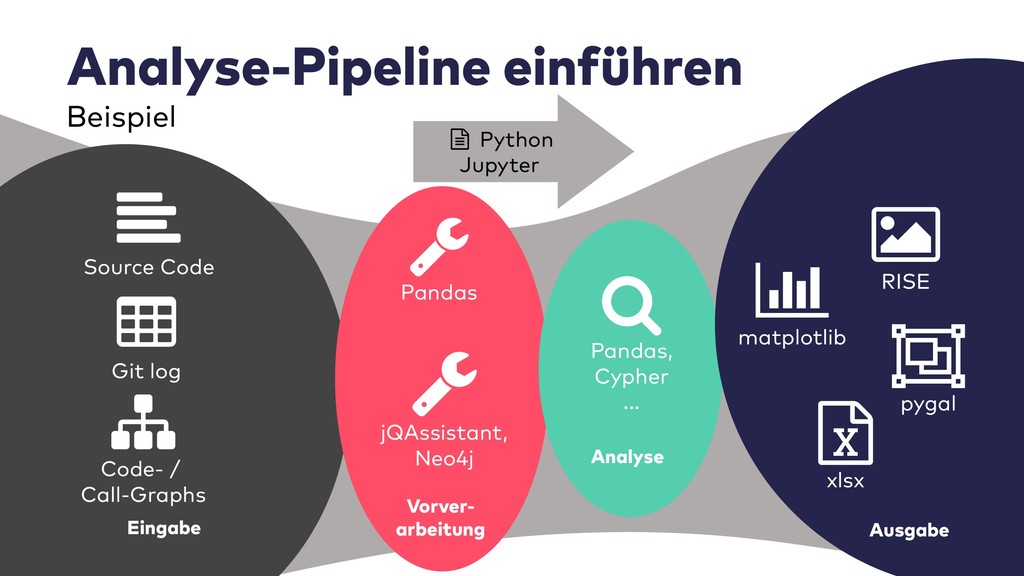
Im Live-Coding mit Jupyter, Pandas, jQAssistant, Neo4j und Co. zeige ich, welche neuen Einsichten sich aus Datenquellen wie Git-Repositories, Logfiles, Qualitätsberichten oder auch direkt aus Java-Programmcode gewinnen lassen. Wir suchen nach defektem Code, erschließen No-Go-Areas in Anwendungen und priorisieren Aufräumarbeiten.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}