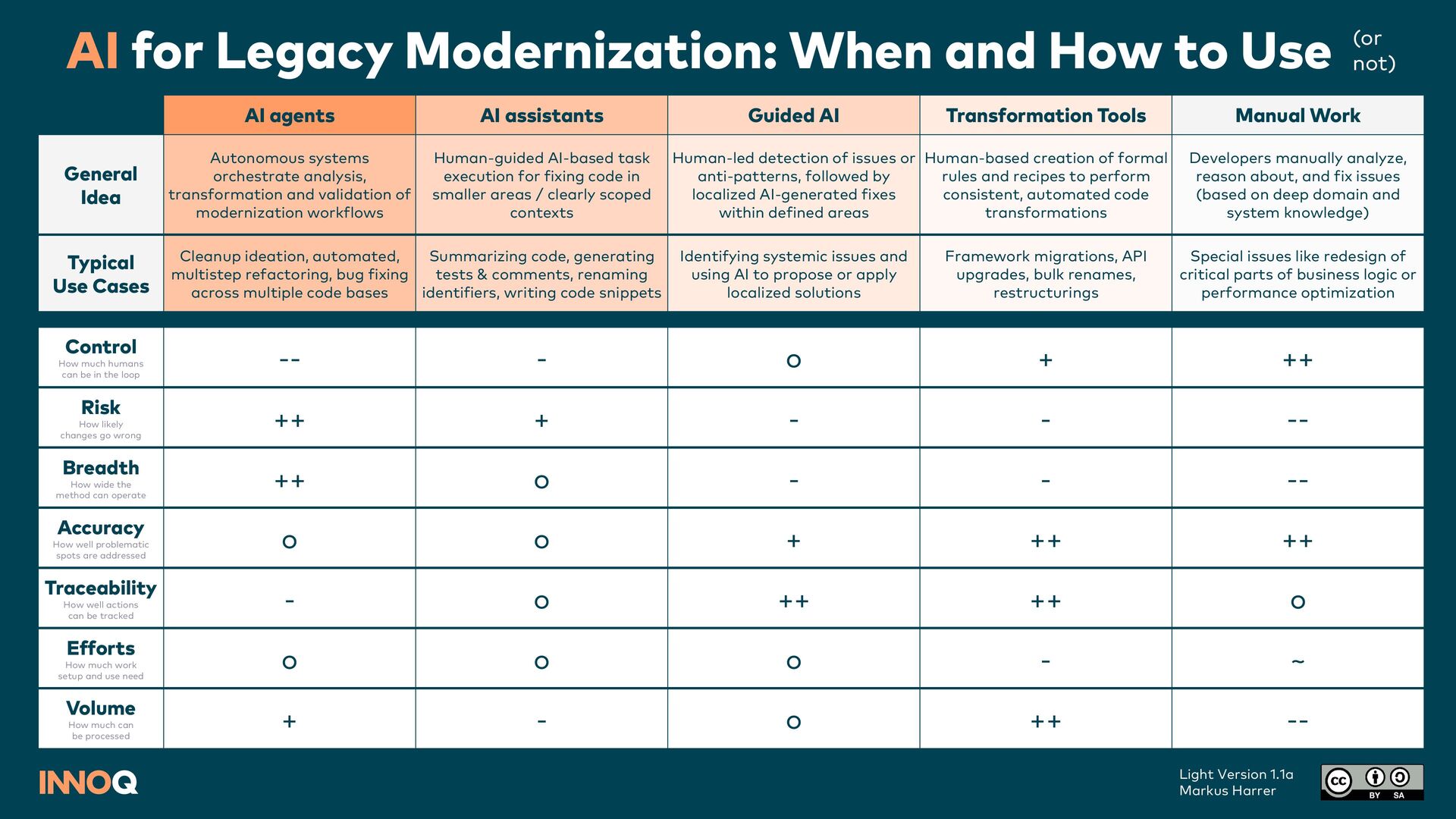
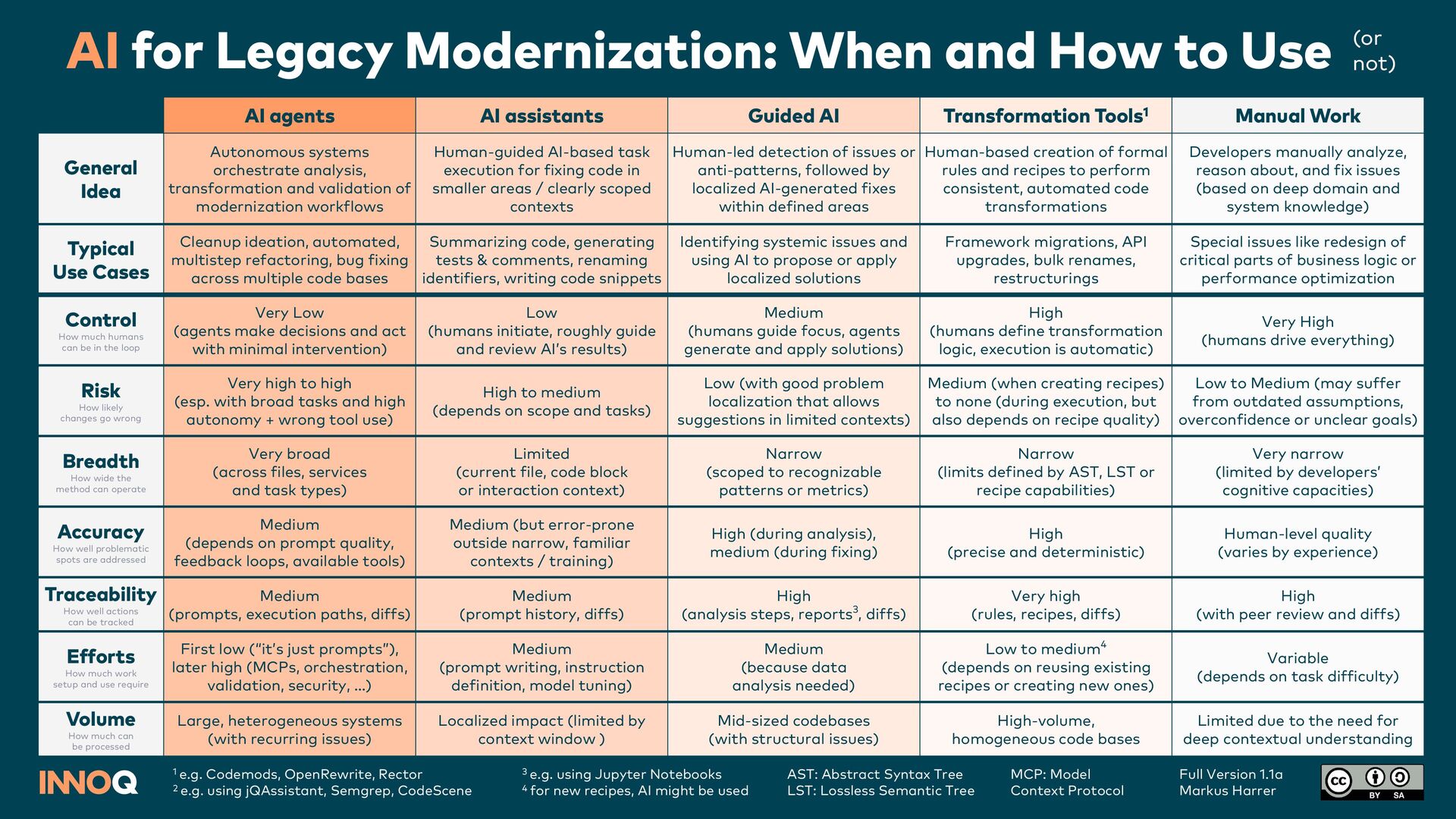
Developers manually analyze, reason about, and fix issues (based on deep domain and system knowledge) Human-based creation of formal rules and recipes to perform consistent, automated code transformations Human-led detection of issues or anti-patterns, followed by localized AI-generated fixes within defined areas Human-guided AI-based task execution for fixing code in smaller areas / clearly scoped contexts Autonomous systems orchestrate analysis, transformation and validation of modernization workflows General Idea Special issues like redesign of critical parts of business logic or performance optimization Framework migrations, API upgrades, bulk renames, restructurings Identifying systemic issues and using AI to propose or apply localized solutions Summarizing code, generating tests & comments, renaming identifiers, writing code snippets Cleanup ideation, automated, multistep refactoring, bug fixing across multiple code bases Possible Use Cases Very High (humans drive everything) High (humans define transformation logic, execution is automatic) Medium (humans guide focus, agents generate and apply solutions) Low (humans initiate, roughly guide and review AI’s results) Very Low (agents make decisions and act with minimal intervention) Control How much humans can be in the loop Low to Medium (may suffer from outdated assumptions, overconfidence or unclear goals) Medium (when creating recipes) to none (during execution, but also depends on recipe quality) Low (with good problem localization that allows suggestions in limited contexts) High to medium (depends on scope and tasks) Very high to high (esp. with broad tasks and high autonomy + wrong tool use) Risk How likely changes go wrong Very narrow (limited by developers’ cognitive capacities) Narrow (limits defined by AST, LST or recipe capabilities) Narrow (scoped to recognizable patterns or metrics) Limited (current file, code block or interaction context) Very broad (across files, services and task types) Breadth How wide the method can operate Human-level quality (varies by experience) High (precise and deterministic) High (during analysis), medium (during fixing) Medium (but error-prone outside narrow, familiar contexts / training) Medium (depends on prompt quality, feedback loops, available tools) Accuracy How well problematic spots are addressed High (with peer review and diffs) Very high (rules, recipes, diffs) High (analysis steps, reports3, diffs) Medium (prompt history, diffs) Medium (prompts, execution paths, diffs) Traceability How well actions can be tracked Variable (depends on task difficulty) Low to medium4 (depends on reusing existing recipes or creating new ones) Medium (because data analysis needed) Medium (prompt writing, instruction definition, model tuning) First low (“it’s just prompts”), later high (MCPs, skills, orches- tration, validation, security, …) Efforts How much work setup and use require Limited due to the need for deep contextual understanding High-volume, homogeneous code bases Mid-sized codebases (with structural issues) Localized impact (limited by context window ) Large, heterogeneous systems (with recurring issues) Volume How much can be processed 1 e.g. Codemods, OpenRewrite, Rector 2 e.g. using jQAssistant, Semgrep, CodeScene 3 e.g. using Jupyter Notebooks 4 for new recipes, AI might be used Full Version 1.2 Markus Harrer MCP: Model Context Protocol AST: Abstract Syntax Tree LST: Lossless Semantic Tree AI for Legacy Modernization: When and How to Use (or not)
{kind=link}
{kind=link}