Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
C/C++コードの SX-Aurora TSUBASA高速化技法~機械学習の前処理を題材として~
Search
株式会社フィックスターズ
April 12, 2022
Programming
510
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
C/C++コードの SX-Aurora TSUBASA高速化技法~機械学習の前処理を題材として~
2022年3月24日に日本電気株式会社様と共催した、「機械学習・AI処理を高速化するSX-Aurora TSUBASA」セミナーにて弊社が登壇したパートの資料です。
株式会社フィックスターズ
April 12, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
240
symfony/aiとlaravel/boost
77web
0
130
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
210
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
3.9k
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
3
1.5k
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
280
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
180
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
Foundation Models frameworkで画像分析
ryodeveloper
1
120
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
140
Featured
See All Featured
Navigating Team Friction
lara
192
16k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
4 Signs Your Business is Dying
shpigford
187
22k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
RailsConf 2023
tenderlove
30
1.5k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
The SEO identity crisis: Don't let AI make you average
varn
0
520
Transcript
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group C/C++コードの SX-Aurora TSUBASA高速化技法 機械学習の前処理を題材として 株式会社フィックスターズ ソリューション第二事業部 𠮷藤尚生
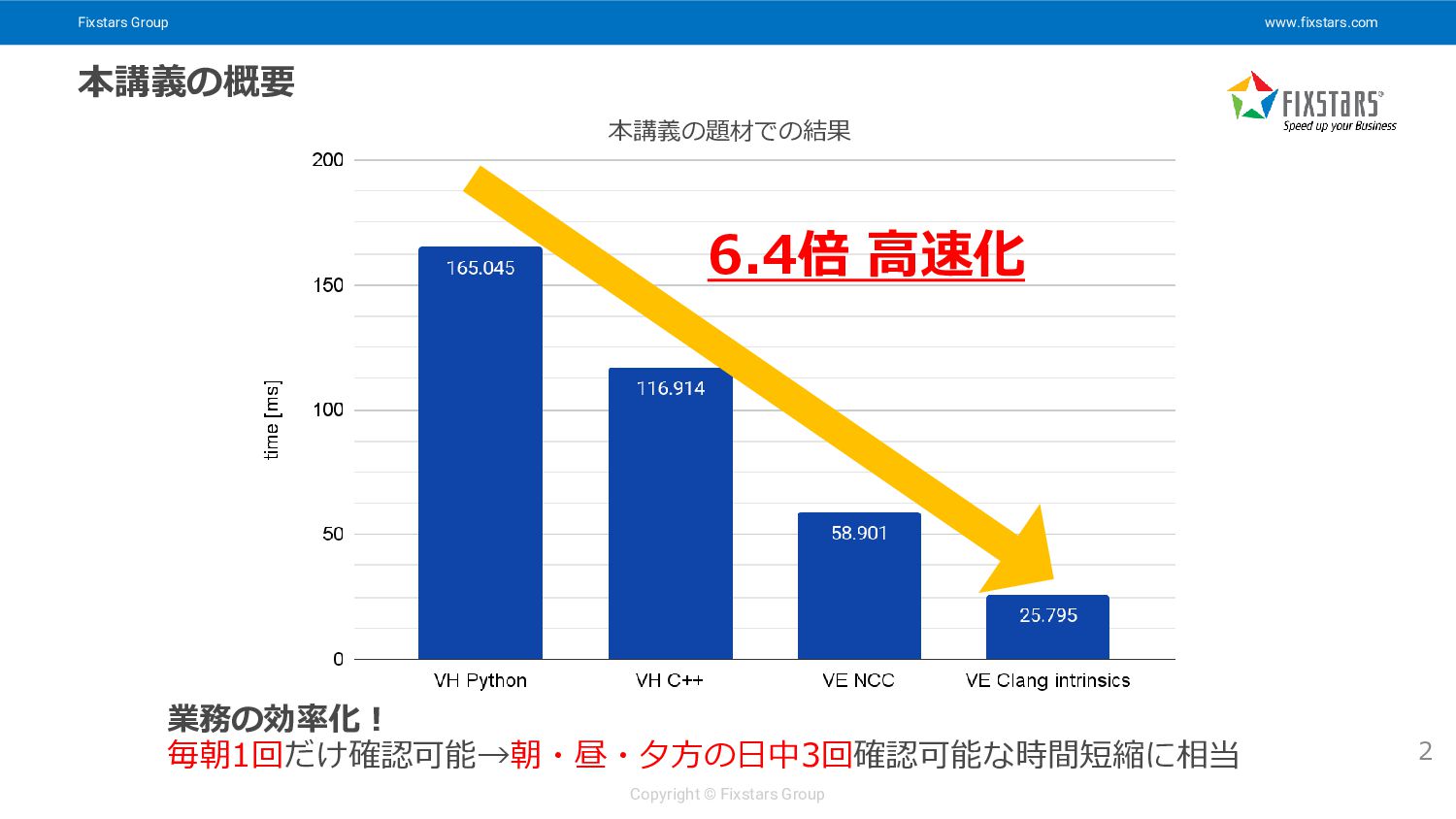
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義の概要 2 業務の効率化!
毎朝1回だけ確認可能→朝・昼・夕方の日中3回確認可能な時間短縮に相当 6.4倍 高速化 本講義の題材での結果
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答
Fixstars Group www.fixstars.com Copyright © Fixstars Group 講師紹介 5 名前
𠮷藤 尚生 (YOSHIFUJI, Naoki) 所属・役職 ソリューション第二事業部・リードエンジニア 社歴 2013年新卒(9年目) 専門分野 土木工学・計算力学・水理学・海岸工学 GPGPU・HPC・CAE やってきたこと 組み込みからHPCまで、なんでも高速化屋さん NANDコントローラ、車載、DSP、機械学習 HPCG on PEZY、ChainerMN、OpenFOAMスレッド並列化 Online ID: @LWisteria
Fixstars Group www.fixstars.com Copyright © Fixstars Group フィックスターズとは コンピュータの性能を最大限に引き出す、ソフトウェア高速化のエキスパート集団 低レイヤ
ソフトウェア技術 アルゴリズム 実装力 各産業・研究 分野の知見 6
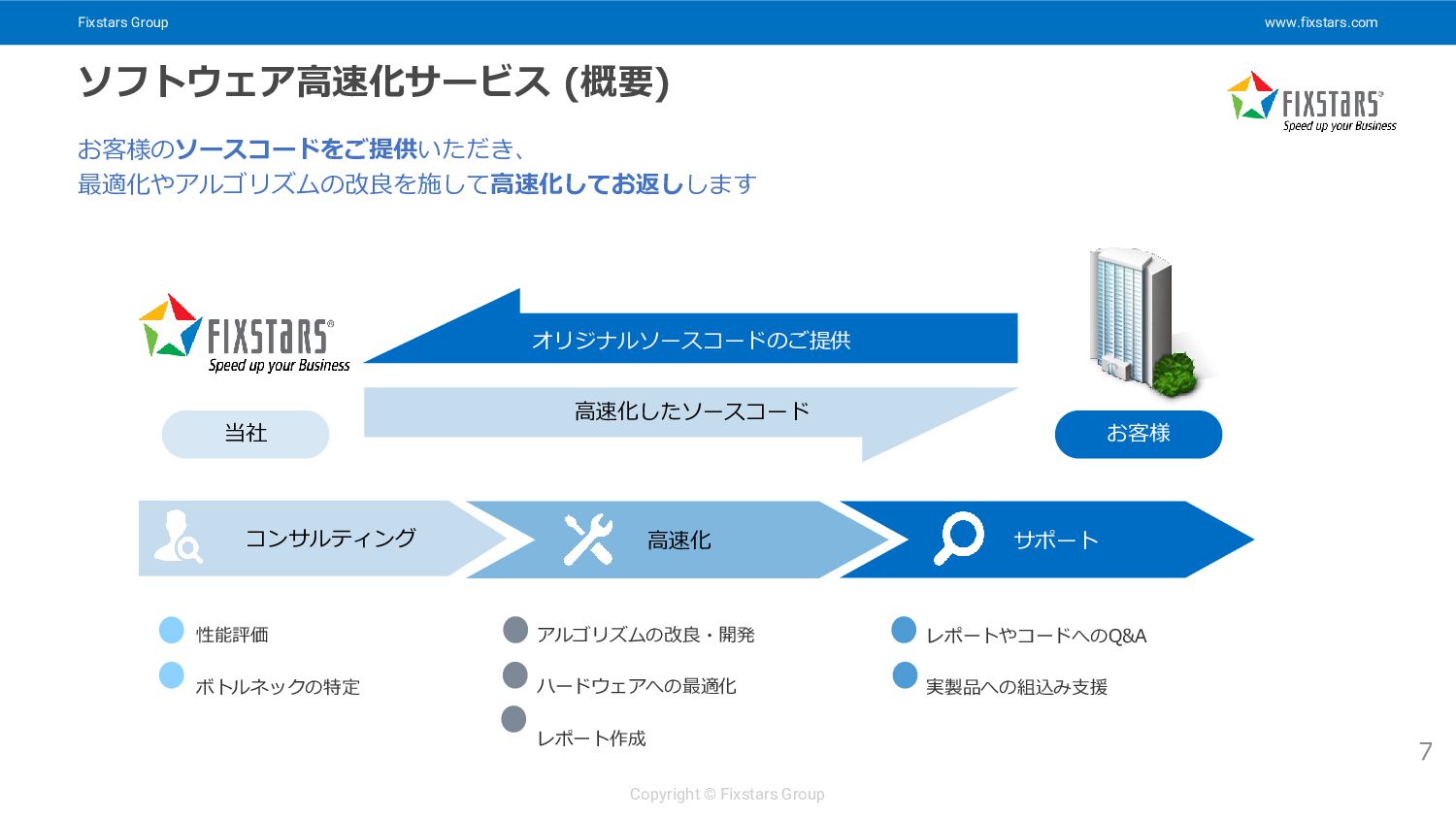
Fixstars Group www.fixstars.com Copyright © Fixstars Group ソフトウェア高速化サービス (概要) お客様のソースコードをご提供いただき、
最適化やアルゴリズムの改良を施して高速化してお返しします 当社 お客様 オリジナルソースコードのご提供 高速化したソースコード コンサルティング 高速化 サポート 性能評価 ボトルネックの特定 アルゴリズムの改良・開発 ハードウェアへの最適化 レポート作成 レポートやコードへのQ&A 実製品への組込み支援 7
Fixstars Group www.fixstars.com Copyright © Fixstars Group ソフトウェア高速化サービスの領域 様々な領域でソフトウェア高速化サービスを提供しています 大量データの高速処理は、お客様の製品競争力の源泉となっています
・NAND型フラッシュメモリ向けファー ムウェア開発 ・次世代AIチップ向け開発環境基盤開発 Semiconductor ・デリバティブシステムの高速化 ・HFT(アルゴリズムトレード)の高速化 Finance ・自動運転の高性能化、実用化 ・次世代パーソナルモビリティの研究開発 Mobility ・ゲノム解析の高速化 ・医用画像処理の高速化 ・AI画像診断システムの研究開発 Life Science ・Smart Factory化支援 ・マシンビジョンシステムの高速化 Industrial 8
Fixstars Group www.fixstars.com Copyright © Fixstars Group ソフトウェア高速化サービスの例 お客様の課題 •
画像処理アルゴリズムの実機性能が確認できないと商品化に踏み切れない • 製品開発に取り組むための目標性能を達成できない • プロセッサが変わるたびに最適化する実装の作業コストが高い • 低スペックのプロセッサで処理できるようにしてハードウェアコストを下げたい 弊社の支援内容 • H/W選定に向けたコンサルティング • ターゲットH/Wに向けたお客様アルゴリズムの移植 • ボトルネック調査、最適化方針提案、実施 • 目標性能未達の見込みの場合、アルゴリズム改善の提案 9
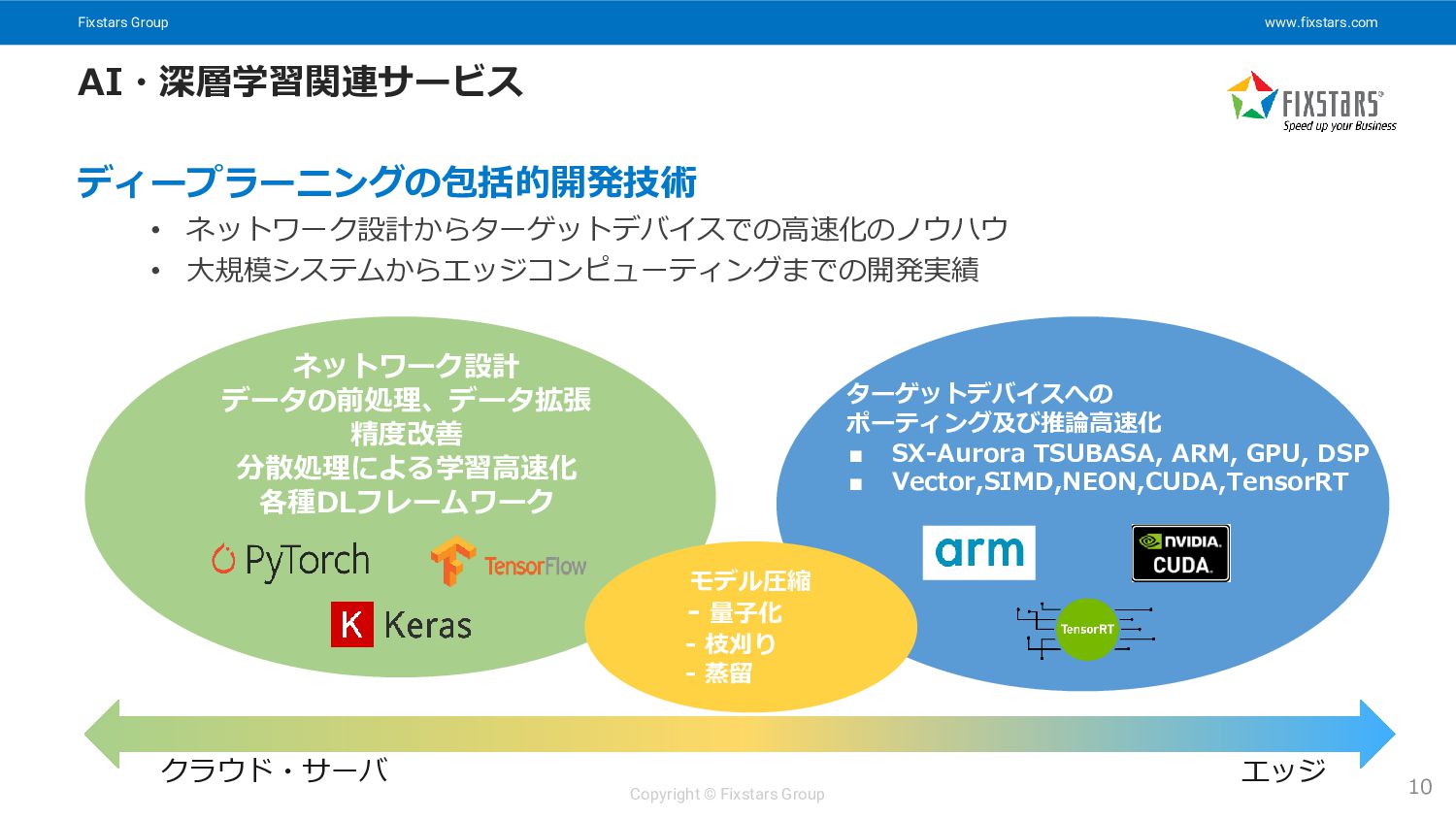
Fixstars Group www.fixstars.com Copyright © Fixstars Group AI・深層学習関連サービス 10 ディープラーニングの包括的開発技術
• ネットワーク設計からターゲットデバイスでの高速化のノウハウ • 大規模システムからエッジコンピューティングまでの開発実績 ネットワーク設計 データの前処理、データ拡張 精度改善 分散処理による学習高速化 各種DLフレームワーク クラウド・サーバ エッジ モデル圧縮 - 量子化 - 枝刈り - 蒸留 ターゲットデバイスへの ポーティング及び推論高速化 ▪ SX-Aurora TSUBASA, ARM, GPU, DSP ▪ Vector,SIMD,NEON,CUDA,TensorRT
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答
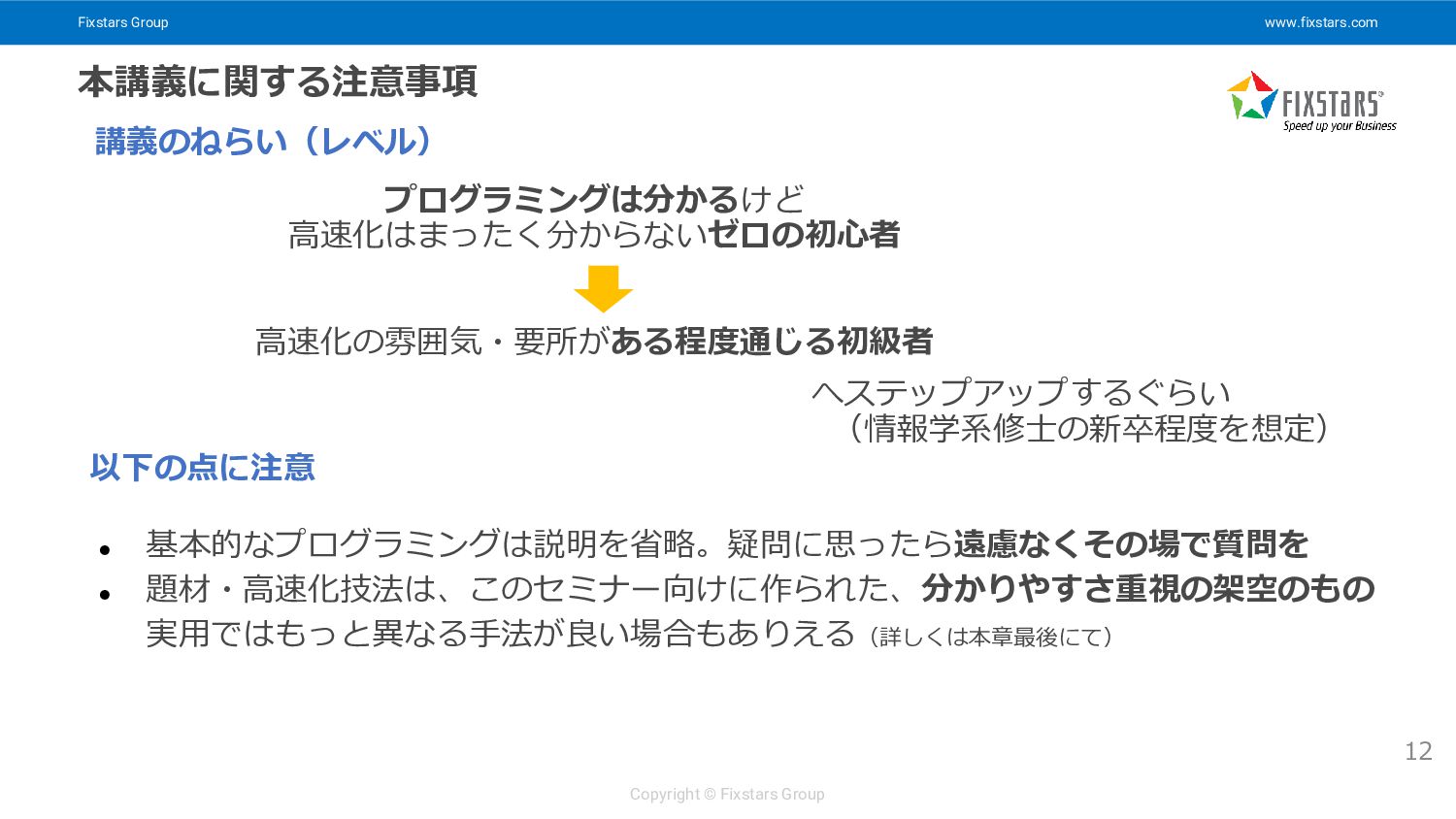
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義に関する注意事項 講義のねらい(レベル) 12
プログラミングは分かるけど 高速化はまったく分からないゼロの初心者 高速化の雰囲気・要所がある程度通じる初級者 へステップアップするぐらい (情報学系修士の新卒程度を想定) 以下の点に注意 • 基本的なプログラミングは説明を省略。疑問に思ったら遠慮なくその場で質問を • 題材・高速化技法は、このセミナー向けに作られた、分かりやすさ重視の架空のもの 実用ではもっと異なる手法が良い場合もありえる(詳しくは本章最後にて)
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義で取り上げる題材事例 画像の雑音低減処理(ノイズリダクション) 13
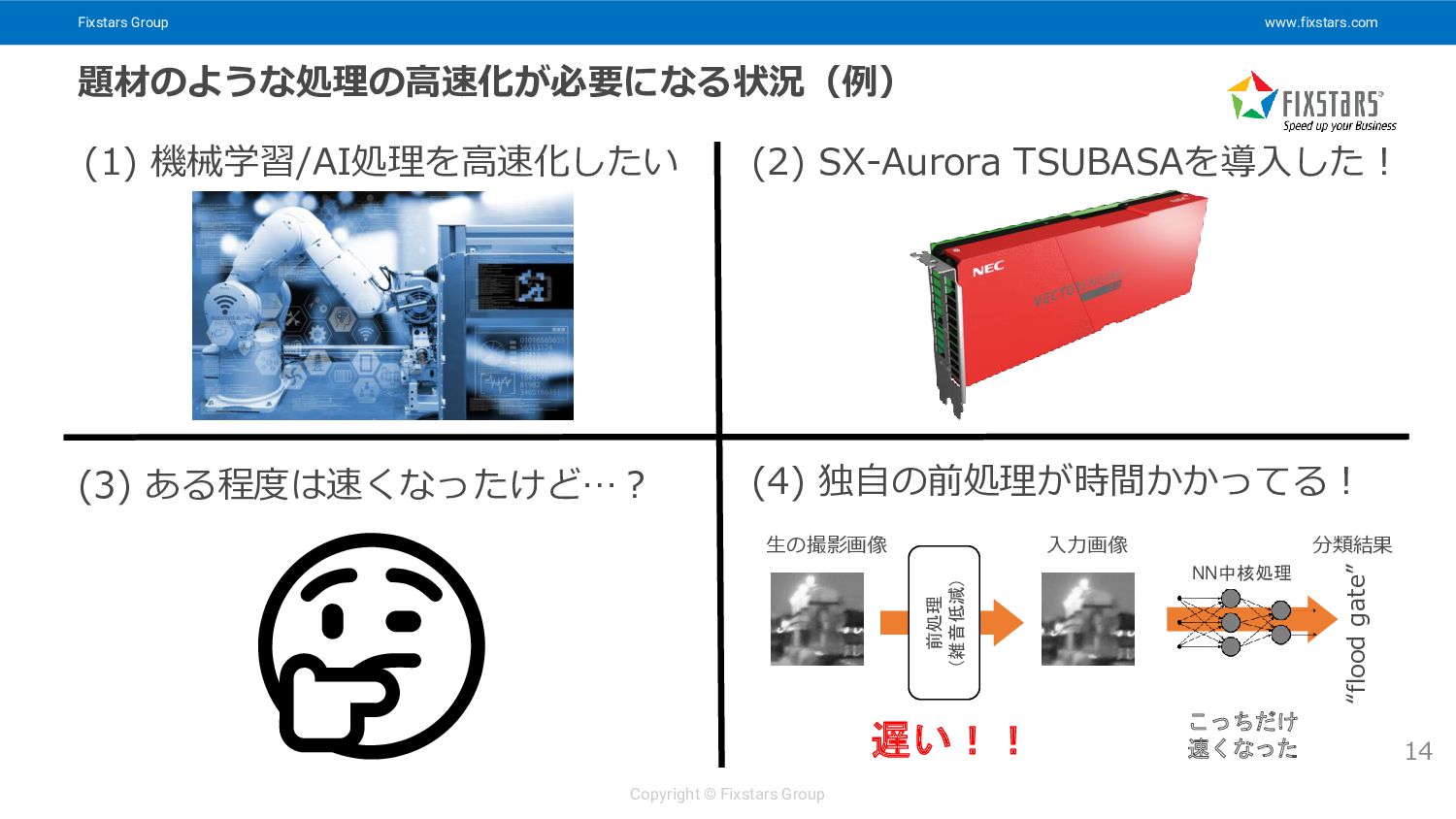
Fixstars Group www.fixstars.com Copyright © Fixstars Group 題材のような処理の高速化が必要になる状況(例) 14 (1)
機械学習/AI処理を高速化したい (2) SX-Aurora TSUBASAを導入した! (3) ある程度は速くなったけど…? 🤔 (4) 独自の前処理が時間かかってる! “flood gate” 入力画像 生の撮影画像 分類結果 前処理 (雑音低減) 遅い!! こっちだけ 速くなった NN中核処理
Fixstars Group www.fixstars.com Copyright © Fixstars Group こんな状況は実用上よく起きてしまう 15 処理時間をもっともっと短くしたい
• 結果を得るまでの時間が短縮→作業効率が向上 • 同じ時間でより多くのデータを入力→高精度モデルにできる • 特に、AI/機械学習のような大量の演算と入力データで殴るような計算は、 数日かかるような場合もあるので需要が高い 最近は「ライブラリやフレームワークを使えば速い」も間違いではないが… • 高速化が不十分なことがある • ライブラリ製作者は「機能を提供する」面では確実にプロ。しかし 必ずしも高速化のプロではない • 特に大手主導PJでは、潤沢な費用で大量の計算機を使って処理時間を強引に短縮 という荒業が使えるのであまり高速化に興味がない場合がある • 用意されている典型的な処理以外は遅い • ImageNet/ResNetなどベンチマークでは性能が出るが、 自分の製品では性能が出ないこともよくある • そもそも典型的な処理だけで作れるような計算モデルに、ビジネス価値はない 題材のような前処理は、実用時にはほぼ必須 • 入力データの品質は変わりやすい(撮影カメラの違いなど) • そもそも入出力データの形式が違う(RGBではなくYUVなど)
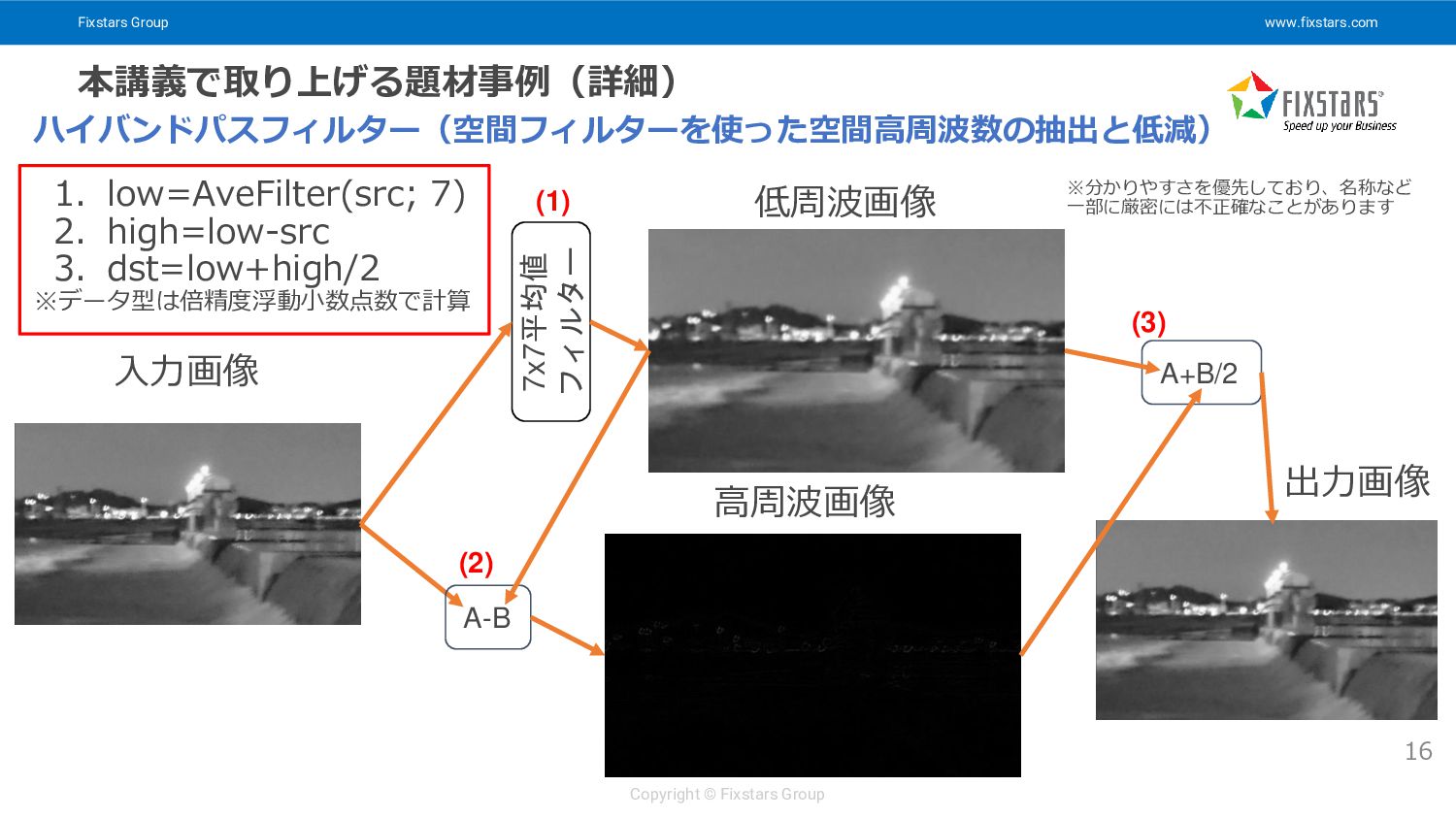
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義で取り上げる題材事例(詳細) ハイバンドパスフィルター(空間フィルターを使った空間高周波数の抽出と低減) 16
入力画像 出力画像 7x7平均値 フィルター 低周波画像 高周波画像 A-B A+B/2 (1) (2) (3) ※分かりやすさを優先しており、名称など 一部に厳密には不正確なことがあります 1. low=AveFilter(src; 7) 2. high=low-src 3. dst=low+high/2 ※データ型は倍精度浮動小数点数で計算
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義で取り上げる題材事例(擬似コード) 17 1.for
y = 0...height 2. for x = 0...width 3. sum = 0 // (1) begin 4. for ky = -3...3 5. for kx = -3...3 6. sum += src[y+ky][x+kx] 7. low = sum/49 // (1) end 8. high = src[y][x] - low // (2) 9. dst[y][x] = low + high/2 // (3) 1. low=AveFilter(src; 7) 2. high=low-src 3. dst=low+high/2 ※データ型は倍精度浮動小数点数で計算
Fixstars Group www.fixstars.com Copyright © Fixstars Group 中級者以上への課題(初級者以下の方は飛ばしてOK!) 18 フィックスターズの高速化業務では、以下程度は真っ先に考え、ご提案しています
並列化手法 • 横方向に並列化ではなく、縦方向に並列化したほうが良いかも • スレッド(コア)並列化しよう • より適した命令やループ展開などによって、さらに高速化しよう • プロファイラーなどを使って、最初に性能分析をしてボトルネックを見つけておこう • Python/C++スカラーコードも、そのままCPU向けに高速化して比較しよう • NCCコンパイラの気持ちを理解して、より自動ベクトル化しやすく変形してみよう 演算量の削減 • 倍精度ではなく、単精度もしくは固定小数や8bit整数のままで演算してみよう • 愚直に畳み込まず、差分だけ読み込んで計算しよう • フィルターサイズを大きくするなら、積分画像を使おう 処理自体の実用性 • 高周波成分をより効果的に取るために、より複雑な画像処理技法も考えよう • 雑音除去には、入力画像の雑音性質(ホワイト/ピンク/etc)を考慮し、 かつ、SX-Aurora TSUBASAで速度が出そうな手法を選択しよう
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答質疑応答
Fixstars Group www.fixstars.com Copyright © Fixstars Group 計測環境など 20 ハードウェア
• SX-Aurora TSUBASAモデル: A300-4 • CPUモデル: Intel Xeon Gold 6126 (Skylake) • VectorEngineモデル: 10B ソフトウェア • OS: CentOS 8.3.2011 • Python: 3.10.3 • NumPy: 1.22.3 • opencv-python: 4.5.5.64 • Clang (VH): 12.0.1 • NEC Compiler (NCC): 3.1.1 • LLVM-VE: 1.19.0 入力画像 • 幅: 5333px • 高さ: 3000px • 色形式: グレイスケール • データ型:倍精度浮動小数点数 (double, float64) 以降に出てくる処理時間などは、以下の環境で計測したものです
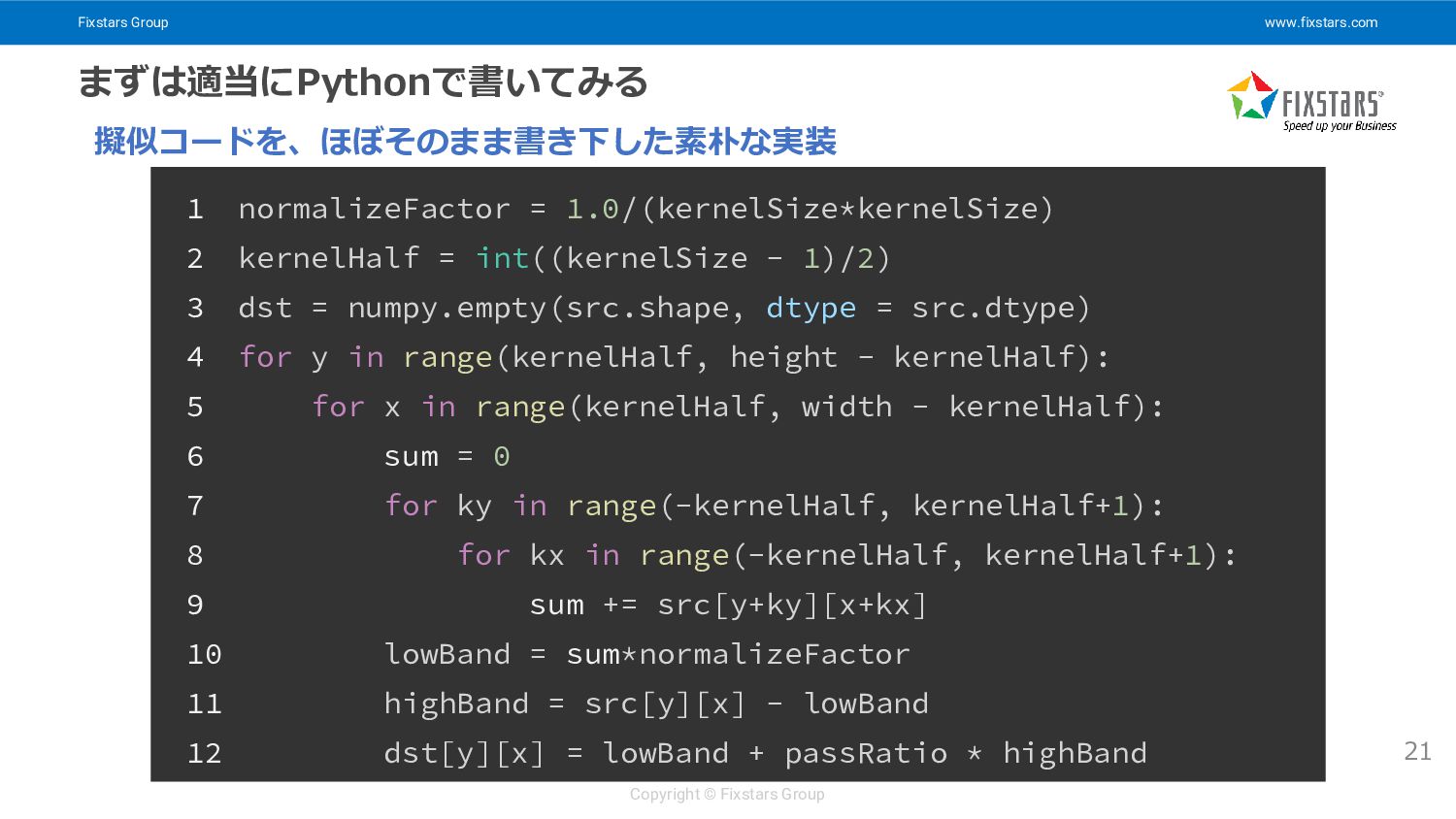
Fixstars Group www.fixstars.com Copyright © Fixstars Group まずは適当にPythonで書いてみる 21 1
normalizeFactor = 1.0/(kernelSize*kernelSize) 2 kernelHalf = int((kernelSize - 1)/2) 3 dst = numpy.empty(src.shape, dtype = src.dtype) 4 for y in range(kernelHalf, height - kernelHalf): 5 for x in range(kernelHalf, width - kernelHalf): 6 sum = 0 7 for ky in range(-kernelHalf, kernelHalf+1): 8 for kx in range(-kernelHalf, kernelHalf+1): 9 sum += src[y+ky][x+kx] 10 lowBand = sum*normalizeFactor 11 highBand = src[y][x] - lowBand 12 dst[y][x] = lowBand + passRatio * highBand 擬似コードを、ほぼそのまま書き下した素朴な実装
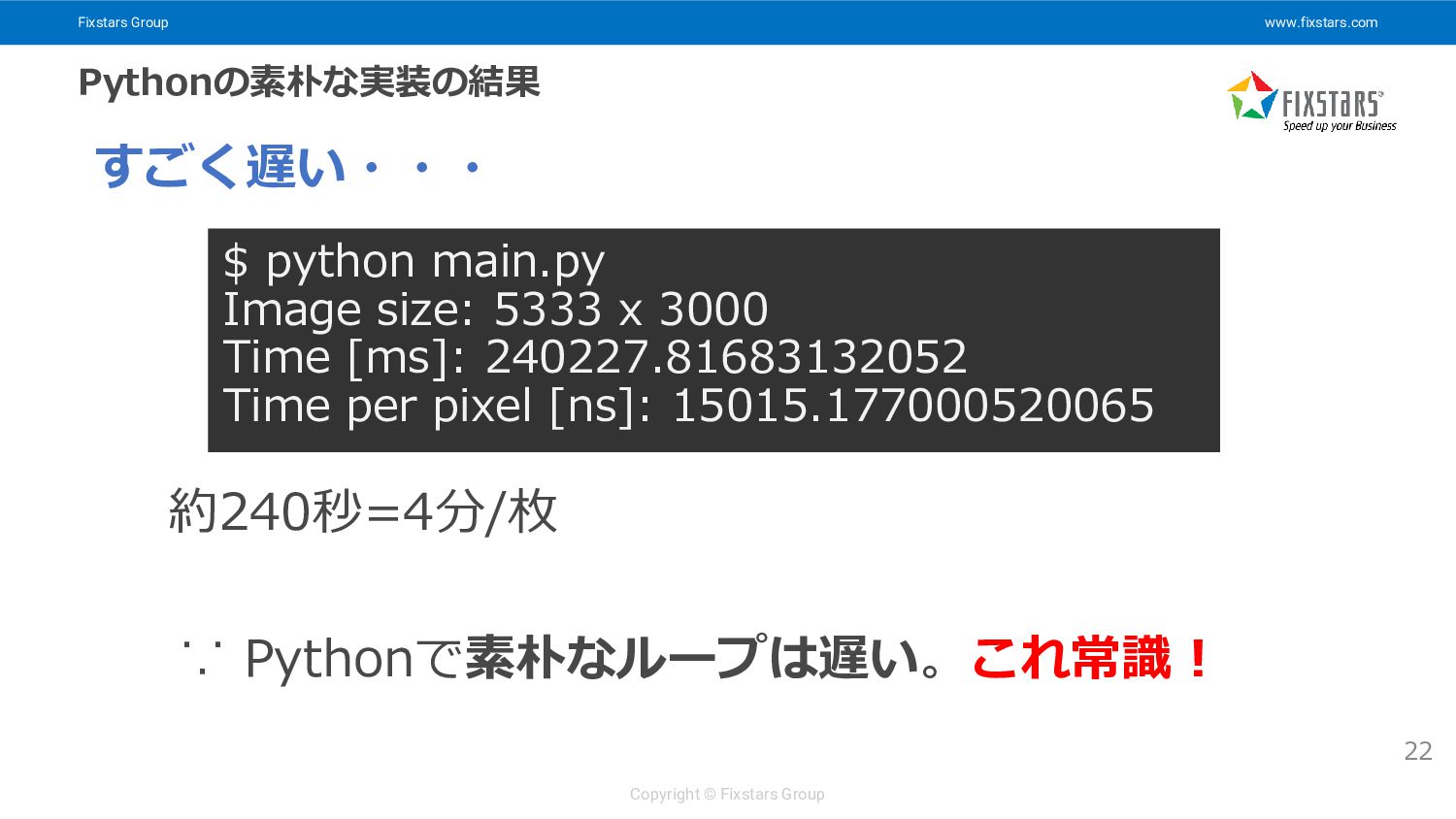
Fixstars Group www.fixstars.com Copyright © Fixstars Group Pythonの素朴な実装の結果 22 すごく遅い・・・
$ python main.py Image size: 5333 x 3000 Time [ms]: 240227.81683132052 Time per pixel [ns]: 15015.177000520065 ∵ Pythonで素朴なループは遅い。これ常識! 約240秒=4分/枚
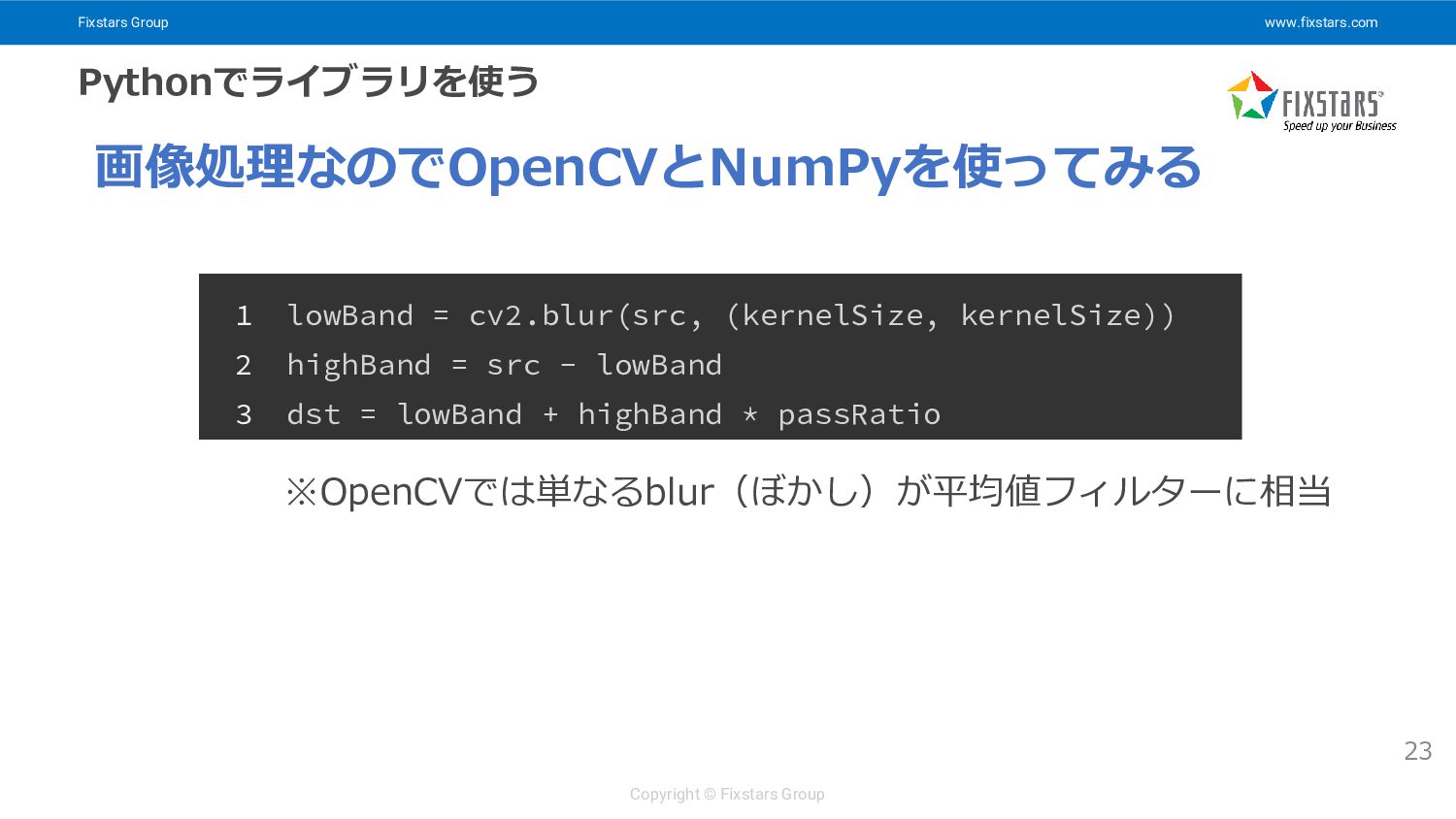
Fixstars Group www.fixstars.com Copyright © Fixstars Group Pythonでライブラリを使う 23 画像処理なのでOpenCVとNumPyを使ってみる
1 lowBand = cv2.blur(src, (kernelSize, kernelSize)) 2 highBand = src - lowBand 3 dst = lowBand + highBand * passRatio ※OpenCVでは単なるblur(ぼかし)が平均値フィルターに相当
Fixstars Group www.fixstars.com Copyright © Fixstars Group Python/OpenCV+NumPyの結果 24 それなりに常識的な処理時間になった
実装方法 処理時間 [ms/枚] Python Naive 240228 Python OpenCV+NumPy 165
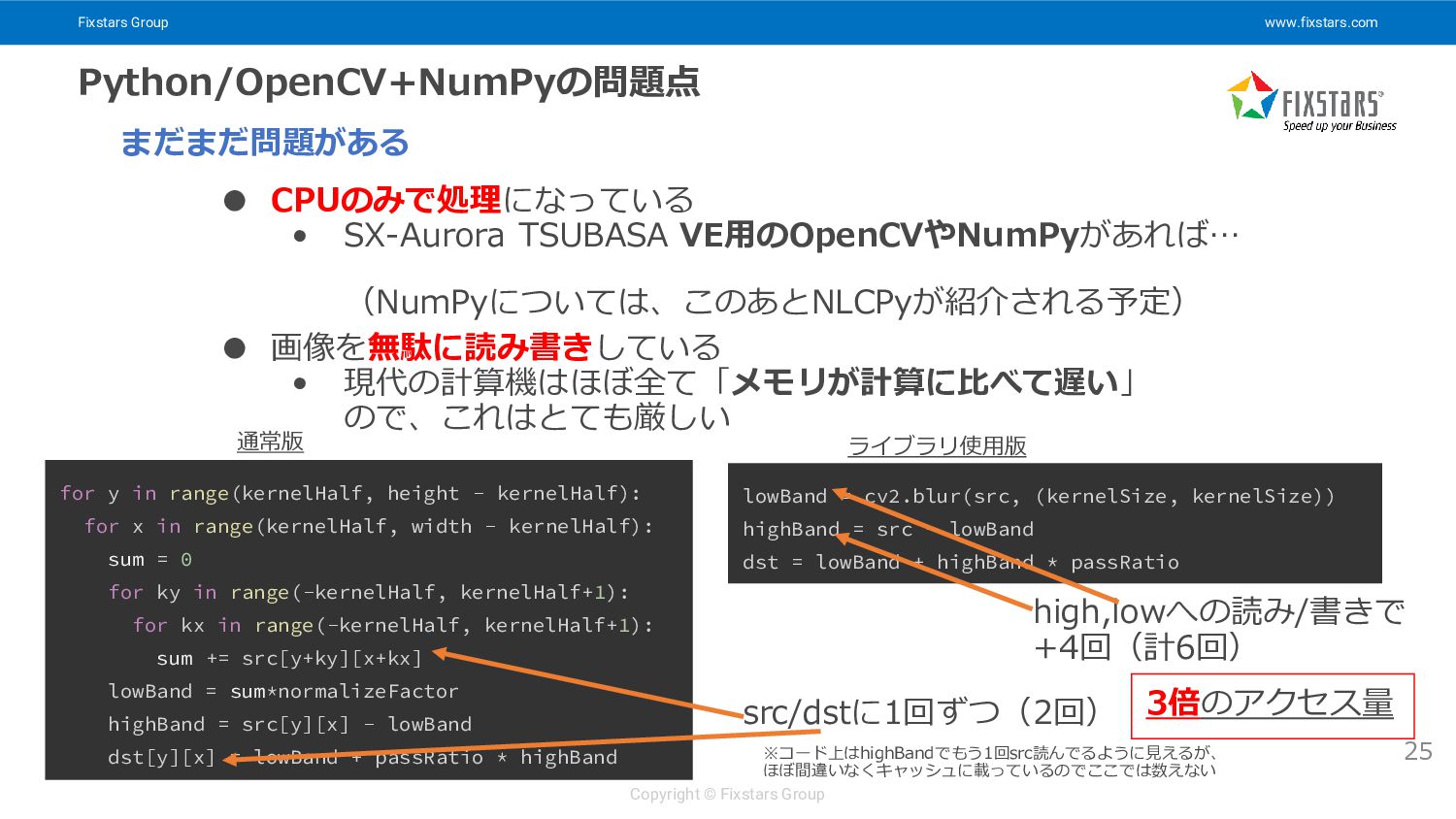
Fixstars Group www.fixstars.com Copyright © Fixstars Group Python/OpenCV+NumPyの問題点 25 •
CPUのみで処理になっている • SX-Aurora TSUBASA VE用のOpenCVやNumPyがあれば… (NumPyについては、このあとNLCPyが紹介される予定) • 画像を無駄に読み書きしている • 現代の計算機はほぼ全て「メモリが計算に比べて遅い」 ので、これはとても厳しい まだまだ問題がある for y in range(kernelHalf, height - kernelHalf): for x in range(kernelHalf, width - kernelHalf): sum = 0 for ky in range(-kernelHalf, kernelHalf+1): for kx in range(-kernelHalf, kernelHalf+1): sum += src[y+ky][x+kx] lowBand = sum*normalizeFactor highBand = src[y][x] - lowBand dst[y][x] = lowBand + passRatio * highBand lowBand = cv2.blur(src, (kernelSize, kernelSize)) highBand = src - lowBand dst = lowBand + highBand * passRatio src/dstに1回ずつ(2回) high,lowへの読み/書きで +4回(計6回) 3倍のアクセス量 通常版 ライブラリ使用版 ※コード上はhighBandでもう1回src読んでるように見えるが、 ほぼ間違いなくキャッシュに載っているのでここでは数えない
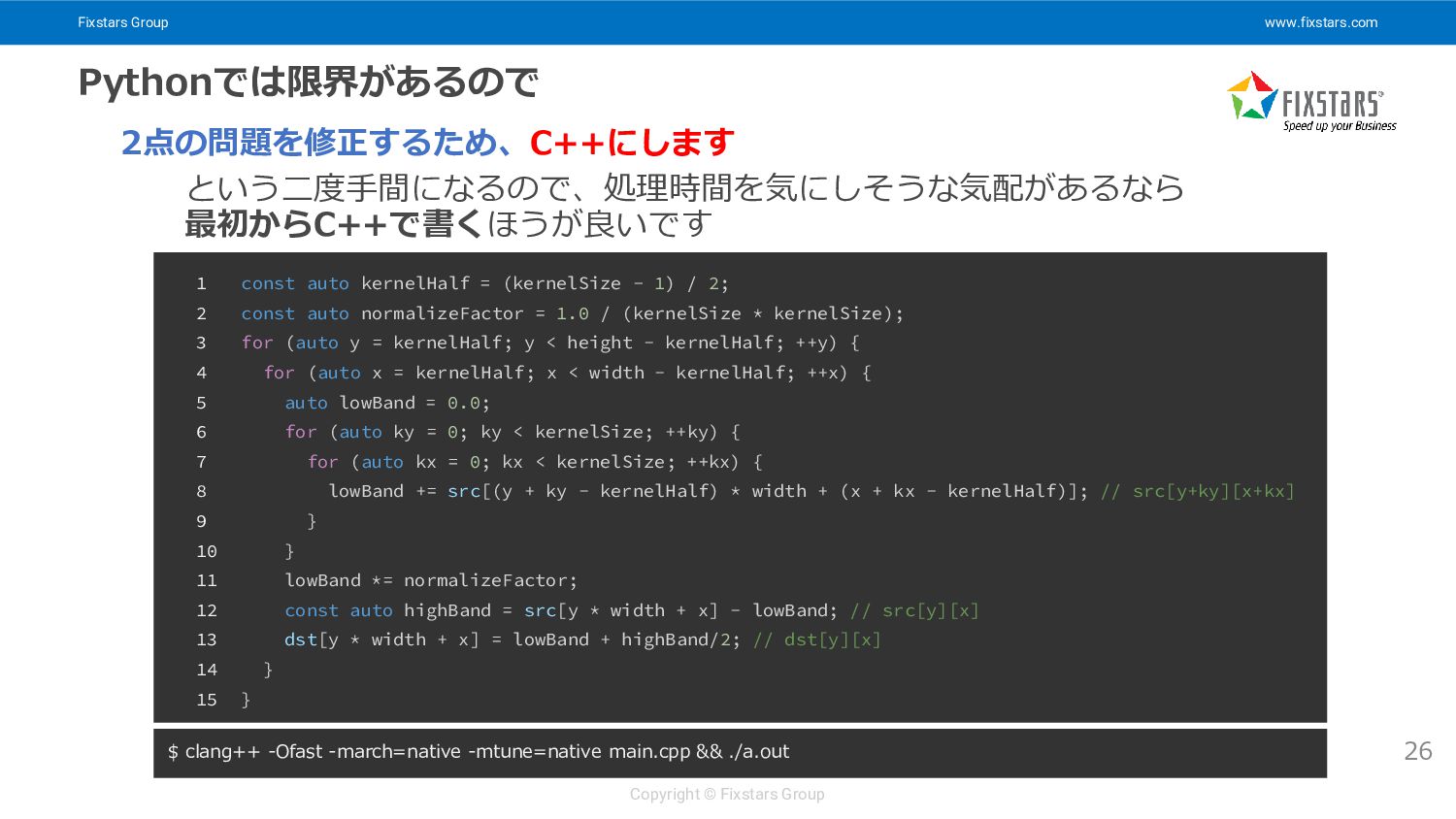
Fixstars Group www.fixstars.com Copyright © Fixstars Group Pythonでは限界があるので 26 2点の問題を修正するため、C++にします
という二度手間になるので、処理時間を気にしそうな気配があるなら 最初からC++で書くほうが良いです 1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto ky = 0; ky < kernelSize; ++ky) { 7 for (auto kx = 0; kx < kernelSize; ++kx) { 8 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 9 } 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } $ clang++ -Ofast -march=native -mtune=native main.cpp && ./a.out
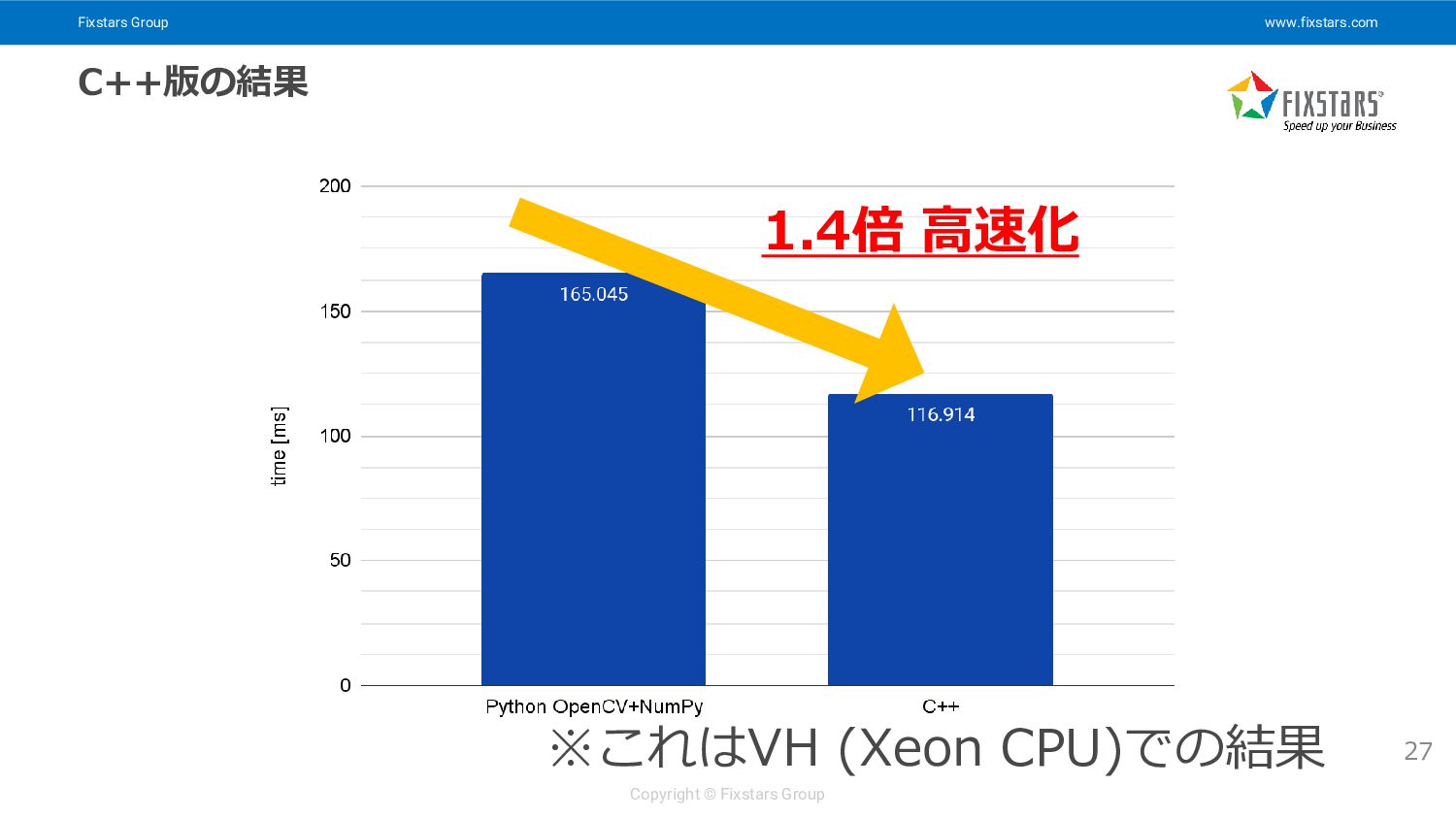
Fixstars Group www.fixstars.com Copyright © Fixstars Group C++版の結果 27 1.4倍
高速化 ※これはVH (Xeon CPU)での結果
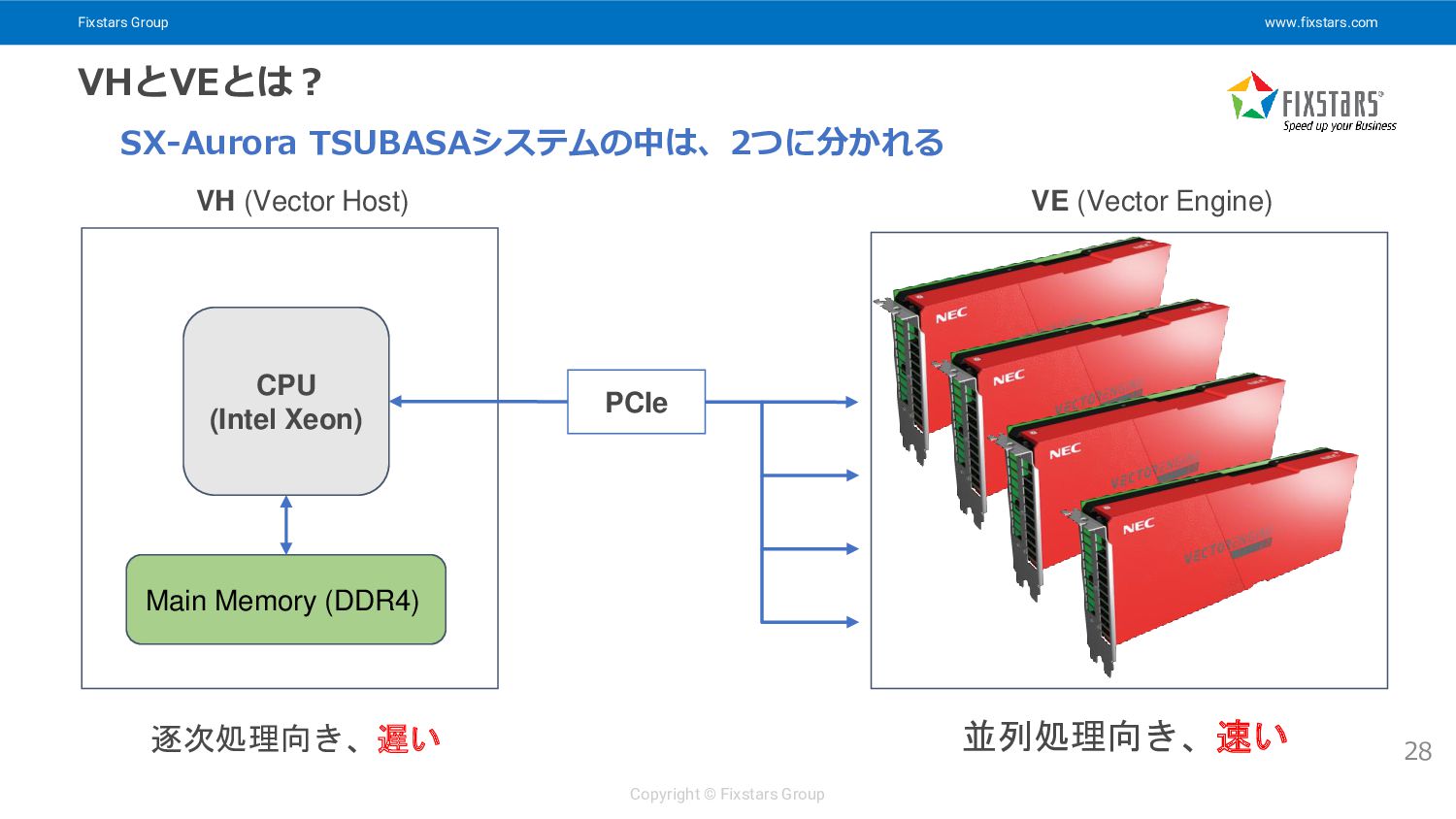
Fixstars Group www.fixstars.com Copyright © Fixstars Group VHとVEとは? 28 SX-Aurora
TSUBASAシステムの中は、2つに分かれる CPU (Intel Xeon) Main Memory (DDR4) PCIe VH (Vector Host) VE (Vector Engine) 逐次処理向き、遅い 並列処理向き、速い
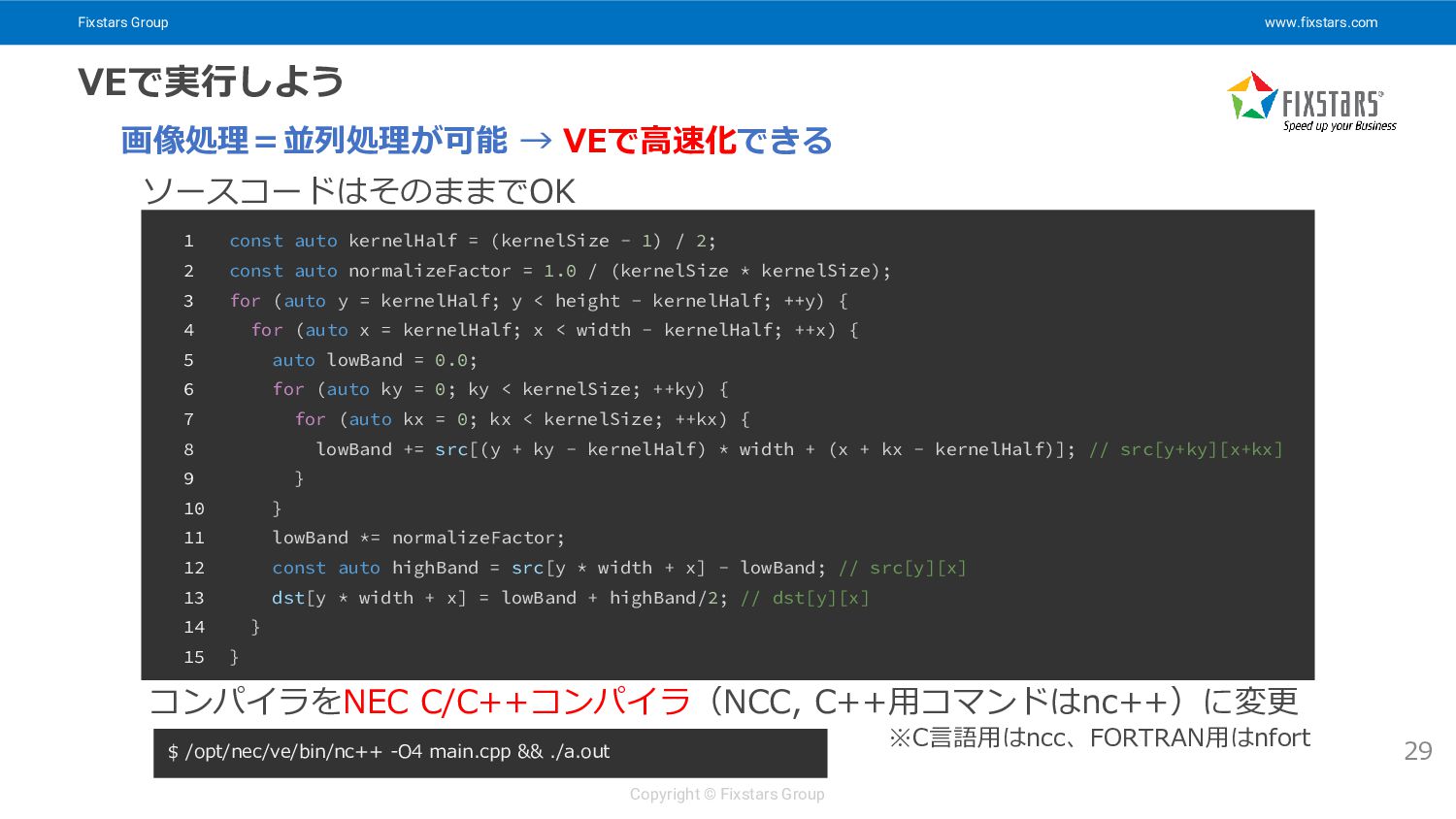
Fixstars Group www.fixstars.com Copyright © Fixstars Group VEで実行しよう 29 画像処理=並列処理が可能
→ VEで高速化できる ソースコードはそのままでOK 1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto ky = 0; ky < kernelSize; ++ky) { 7 for (auto kx = 0; kx < kernelSize; ++kx) { 8 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 9 } 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } $ /opt/nec/ve/bin/nc++ -O4 main.cpp && ./a.out コンパイラをNEC C/C++コンパイラ(NCC, C++用コマンドはnc++)に変更 ※C言語用はncc、FORTRAN用はnfort
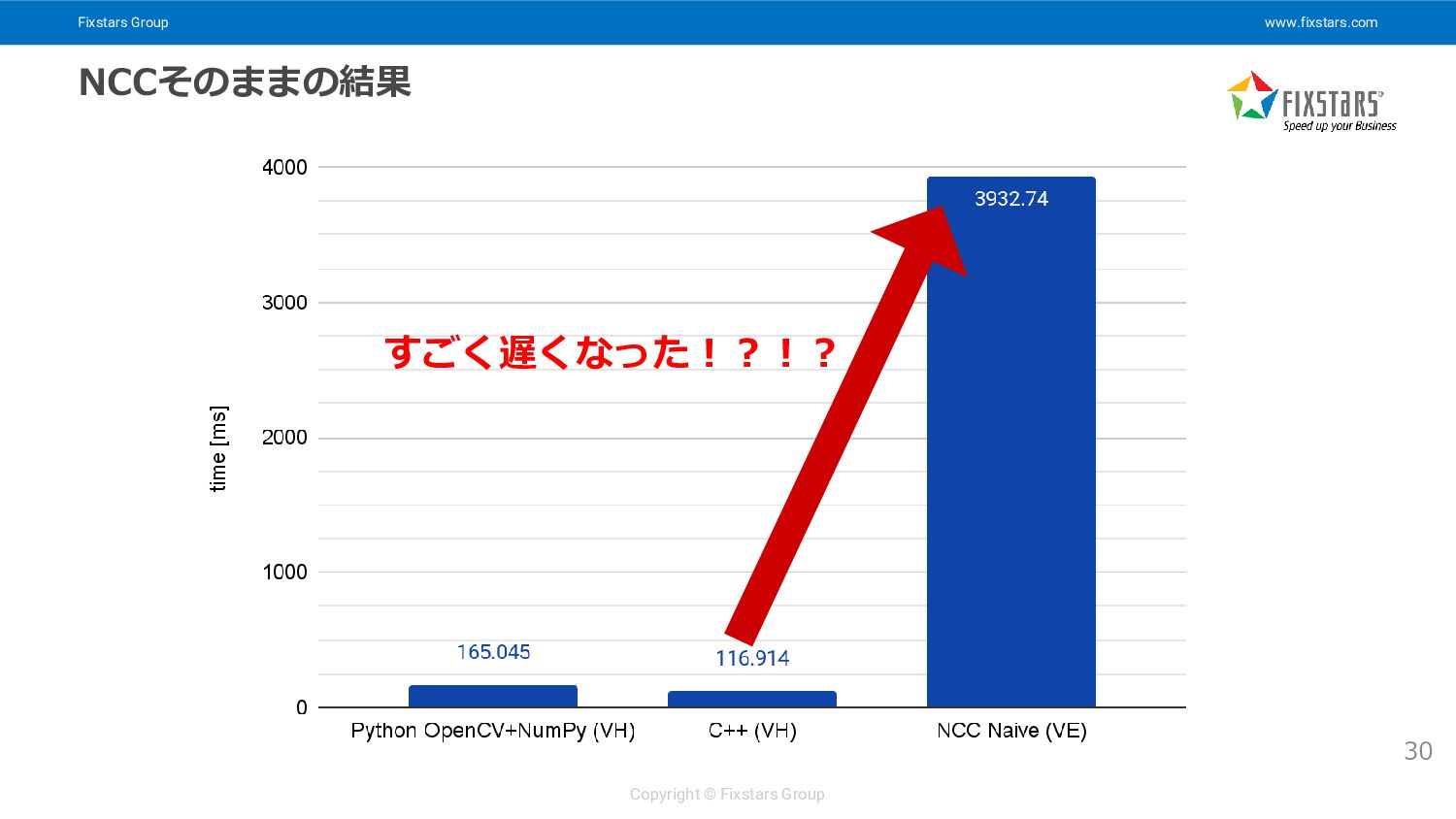
Fixstars Group www.fixstars.com Copyright © Fixstars Group NCCそのままの結果 30 すごく遅くなった!?!?
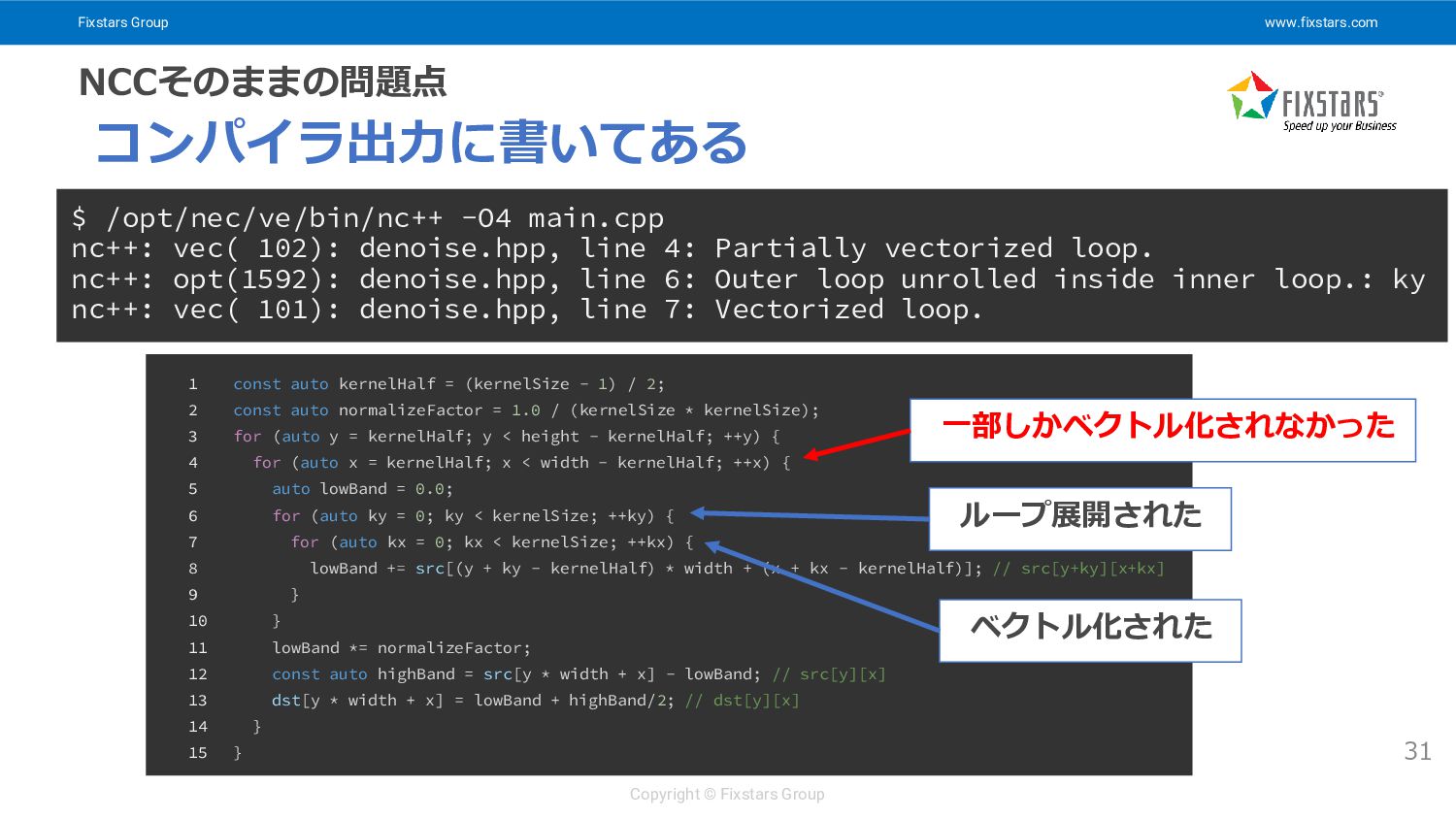
Fixstars Group www.fixstars.com Copyright © Fixstars Group NCCそのままの問題点 31 コンパイラ出力に書いてある
$ /opt/nec/ve/bin/nc++ -O4 main.cpp nc++: vec( 102): denoise.hpp, line 4: Partially vectorized loop. nc++: opt(1592): denoise.hpp, line 6: Outer loop unrolled inside inner loop.: ky nc++: vec( 101): denoise.hpp, line 7: Vectorized loop. 1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto ky = 0; ky < kernelSize; ++ky) { 7 for (auto kx = 0; kx < kernelSize; ++kx) { 8 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 9 } 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } ベクトル化された ループ展開された 一部しかベクトル化されなかった
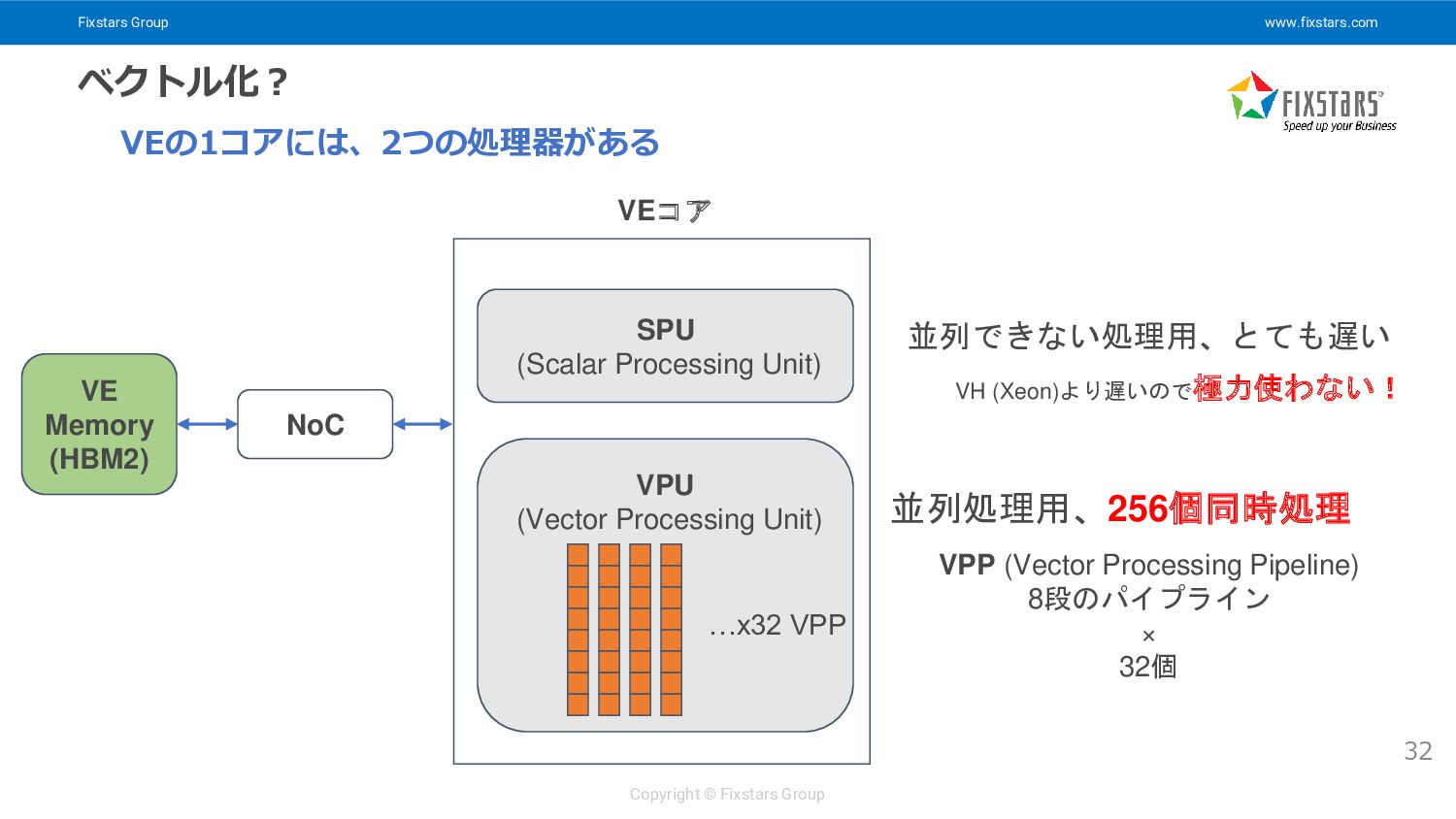
Fixstars Group www.fixstars.com Copyright © Fixstars Group ベクトル化? 32 VEの1コアには、2つの処理器がある
SPU (Scalar Processing Unit) 並列できない処理用、とても遅い 並列処理用、256個同時処理 VPU (Vector Processing Unit) VEコア NoC VE Memory (HBM2) …x32 VPP VPP (Vector Processing Pipeline) 8段のパイプライン × 32個 VH (Xeon)より遅いので極力使わない!
Fixstars Group www.fixstars.com Copyright © Fixstars Group 改めて問題点を見てみる 33 2つ問題がある
1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto ky = 0; ky < kernelSize; ++ky) { 7 for (auto kx = 0; kx < kernelSize; ++kx) { 8 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 9 } 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } • ベクトル化された。が、7個しかない(ベクトル長が不足) • 一部だけベクトル化された=とても遅いSPUが混ざる(ベクトル命令が不足)
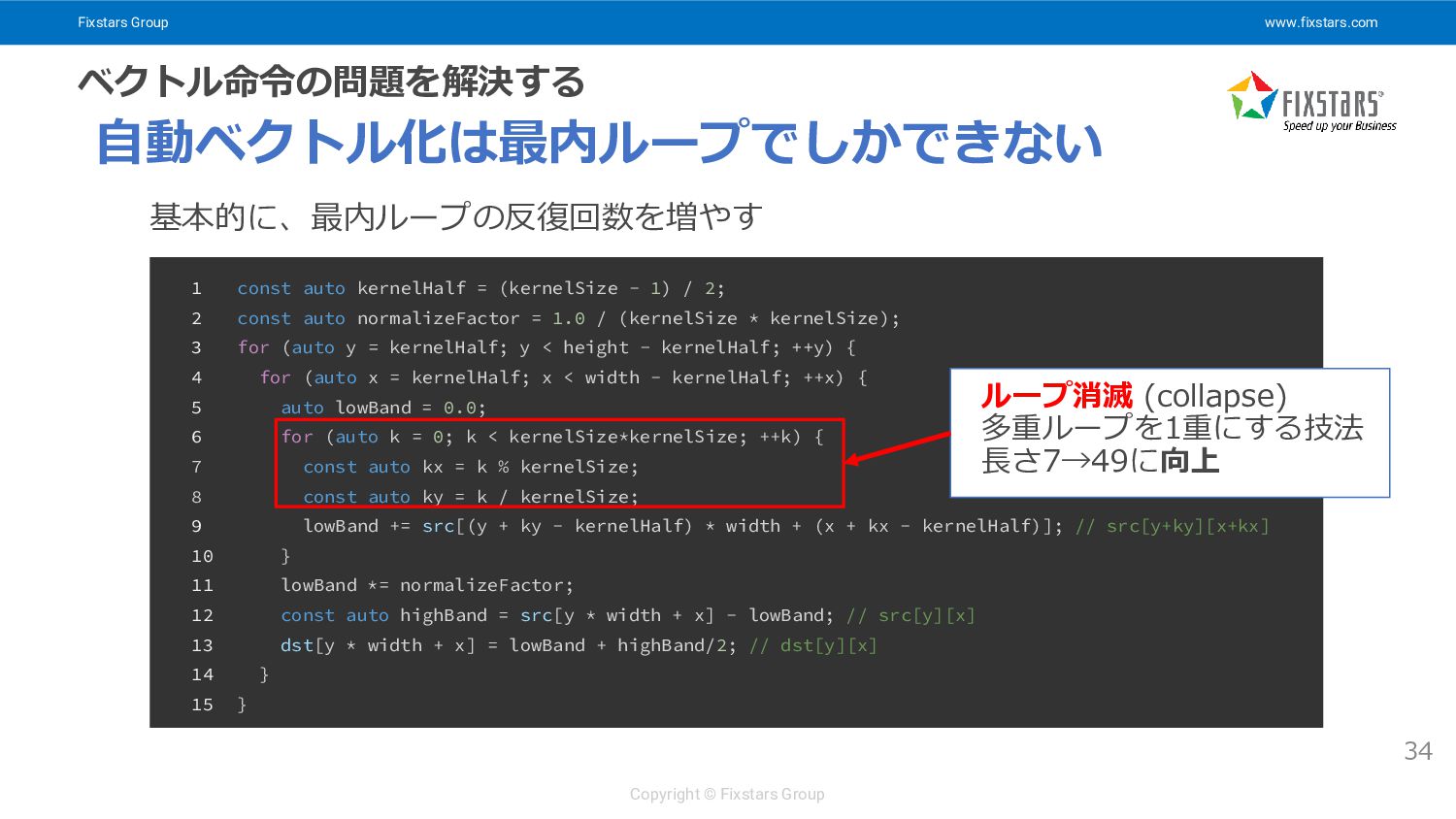
Fixstars Group www.fixstars.com Copyright © Fixstars Group ベクトル命令の問題を解決する 34 自動ベクトル化は最内ループでしかできない
基本的に、最内ループの反復回数を増やす 1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto k = 0; k < kernelSize*kernelSize; ++k) { 7 const auto kx = k % kernelSize; 8 const auto ky = k / kernelSize; 9 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } ループ消滅 (collapse) 多重ループを1重にする技法 長さ7→49に向上
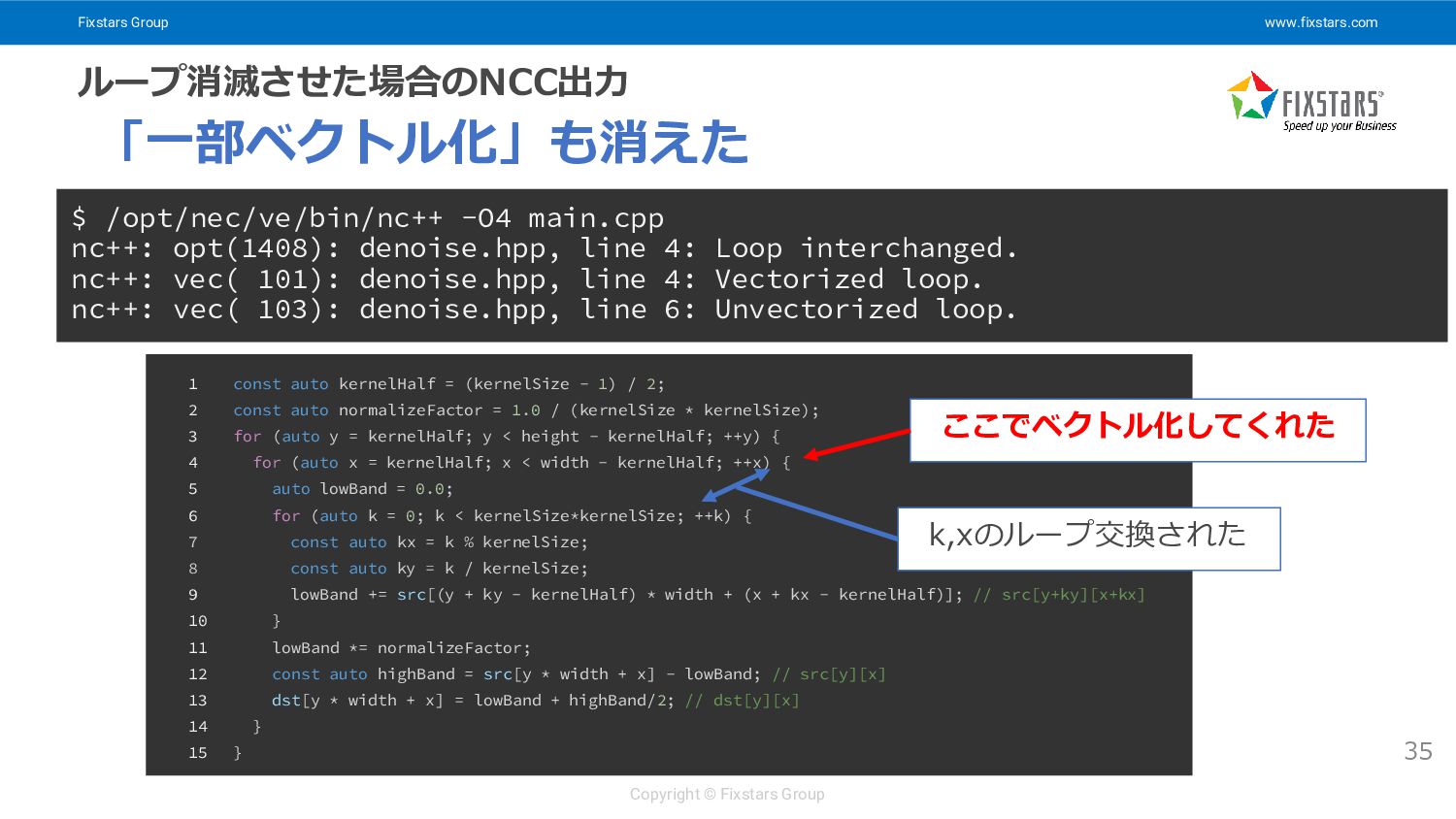
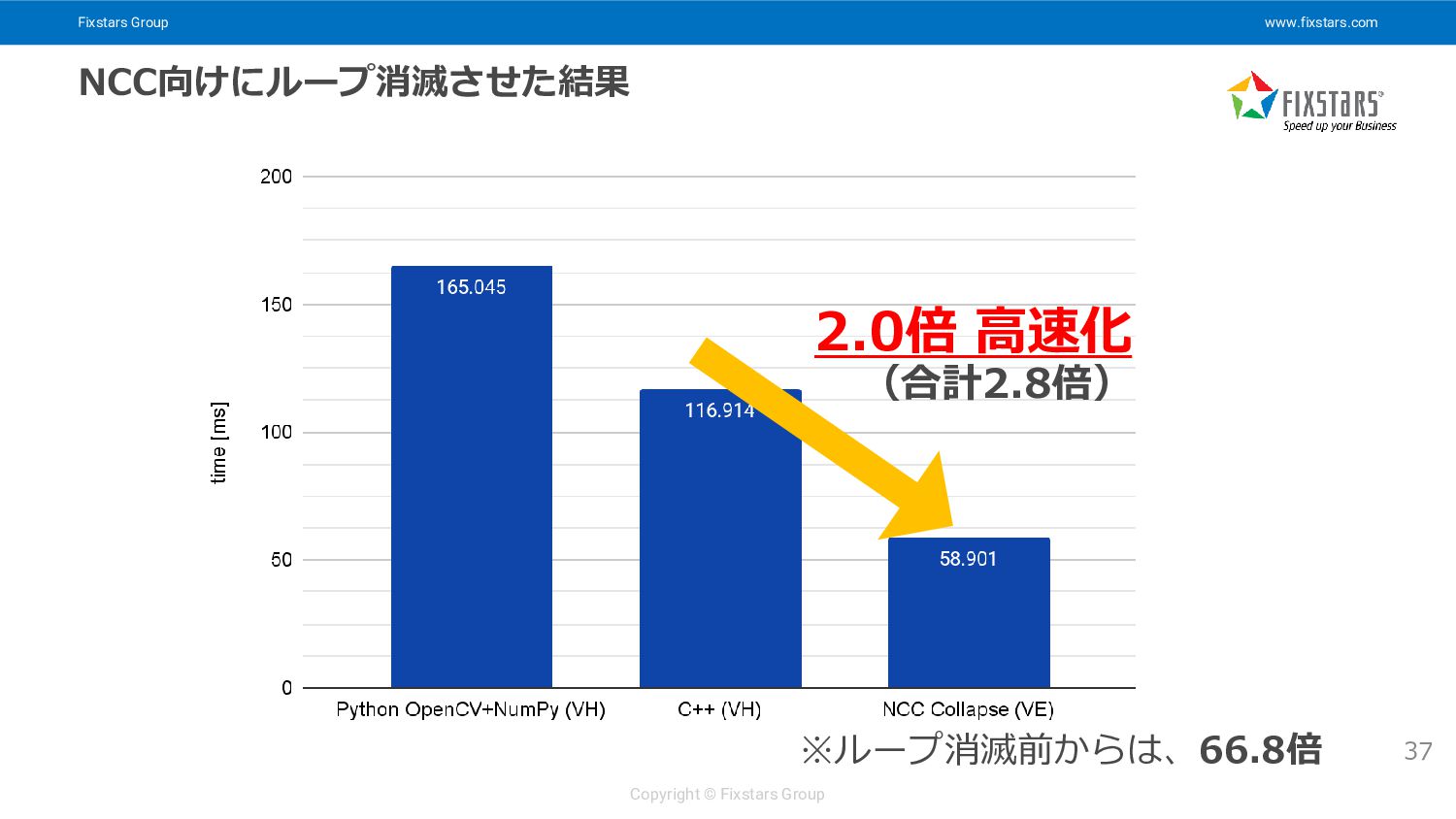
Fixstars Group www.fixstars.com Copyright © Fixstars Group ループ消滅させた場合のNCC出力 35 「一部ベクトル化」も消えた
$ /opt/nec/ve/bin/nc++ -O4 main.cpp nc++: opt(1408): denoise.hpp, line 4: Loop interchanged. nc++: vec( 101): denoise.hpp, line 4: Vectorized loop. nc++: vec( 103): denoise.hpp, line 6: Unvectorized loop. 1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 5 auto lowBand = 0.0; 6 for (auto k = 0; k < kernelSize*kernelSize; ++k) { 7 const auto kx = k % kernelSize; 8 const auto ky = k / kernelSize; 9 lowBand += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 10 } 11 lowBand *= normalizeFactor; 12 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 13 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 14 } 15 } k,xのループ交換された ここでベクトル化してくれた
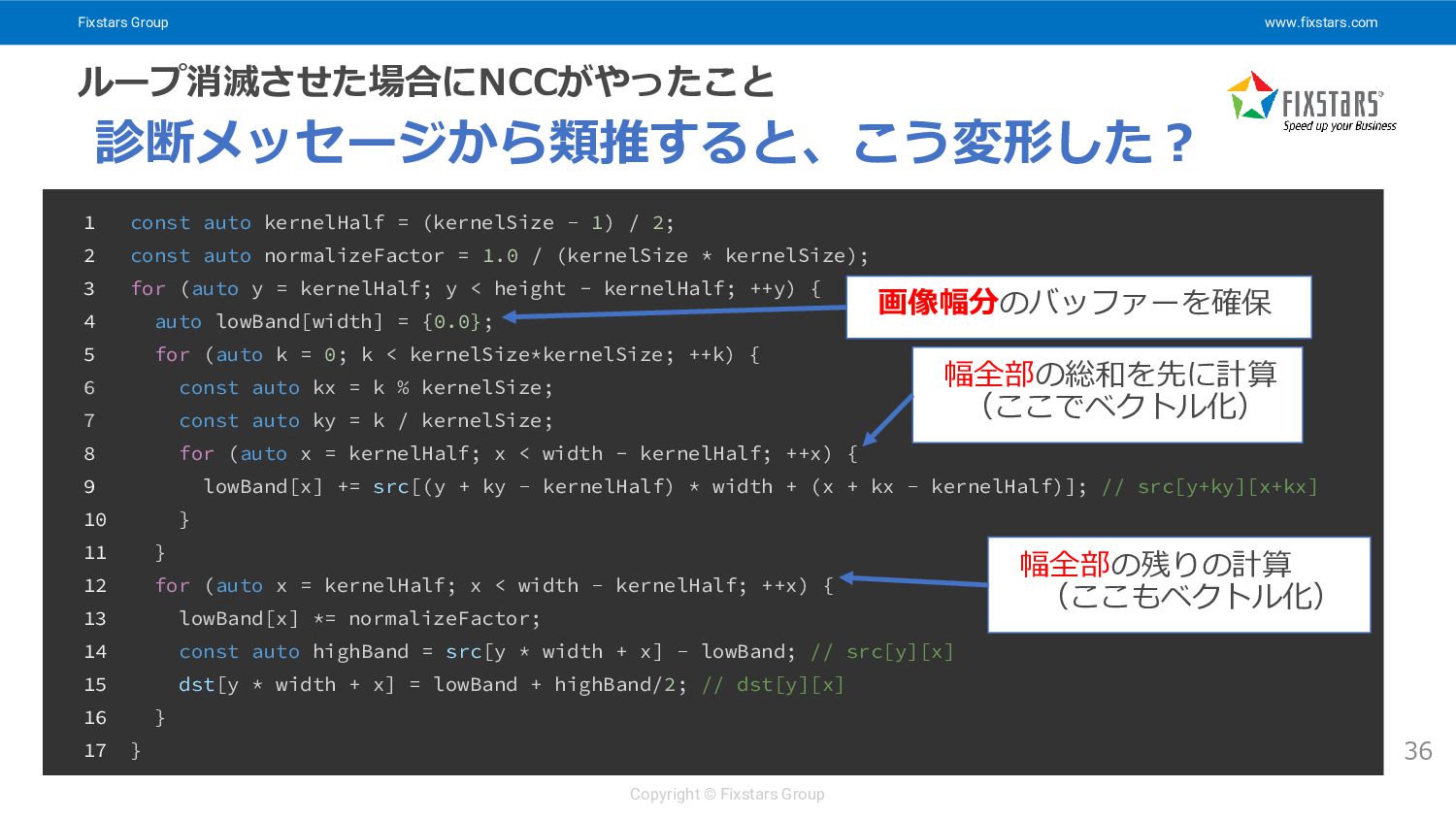
Fixstars Group www.fixstars.com Copyright © Fixstars Group ループ消滅させた場合にNCCがやったこと 36 診断メッセージから類推すると、こう変形した?
1 const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 auto lowBand[width] = {0.0}; 5 for (auto k = 0; k < kernelSize*kernelSize; ++k) { 6 const auto kx = k % kernelSize; 7 const auto ky = k / kernelSize; 8 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 9 lowBand[x] += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 10 } 11 } 12 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 13 lowBand[x] *= normalizeFactor; 14 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 15 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 16 } 17 } 幅全部の総和を先に計算 (ここでベクトル化) 幅全部の残りの計算 (ここもベクトル化) 画像幅分のバッファーを確保
Fixstars Group www.fixstars.com Copyright © Fixstars Group NCC向けにループ消滅させた結果 37 2.0倍
高速化 (合計2.8倍) ※ループ消滅前からは、66.8倍
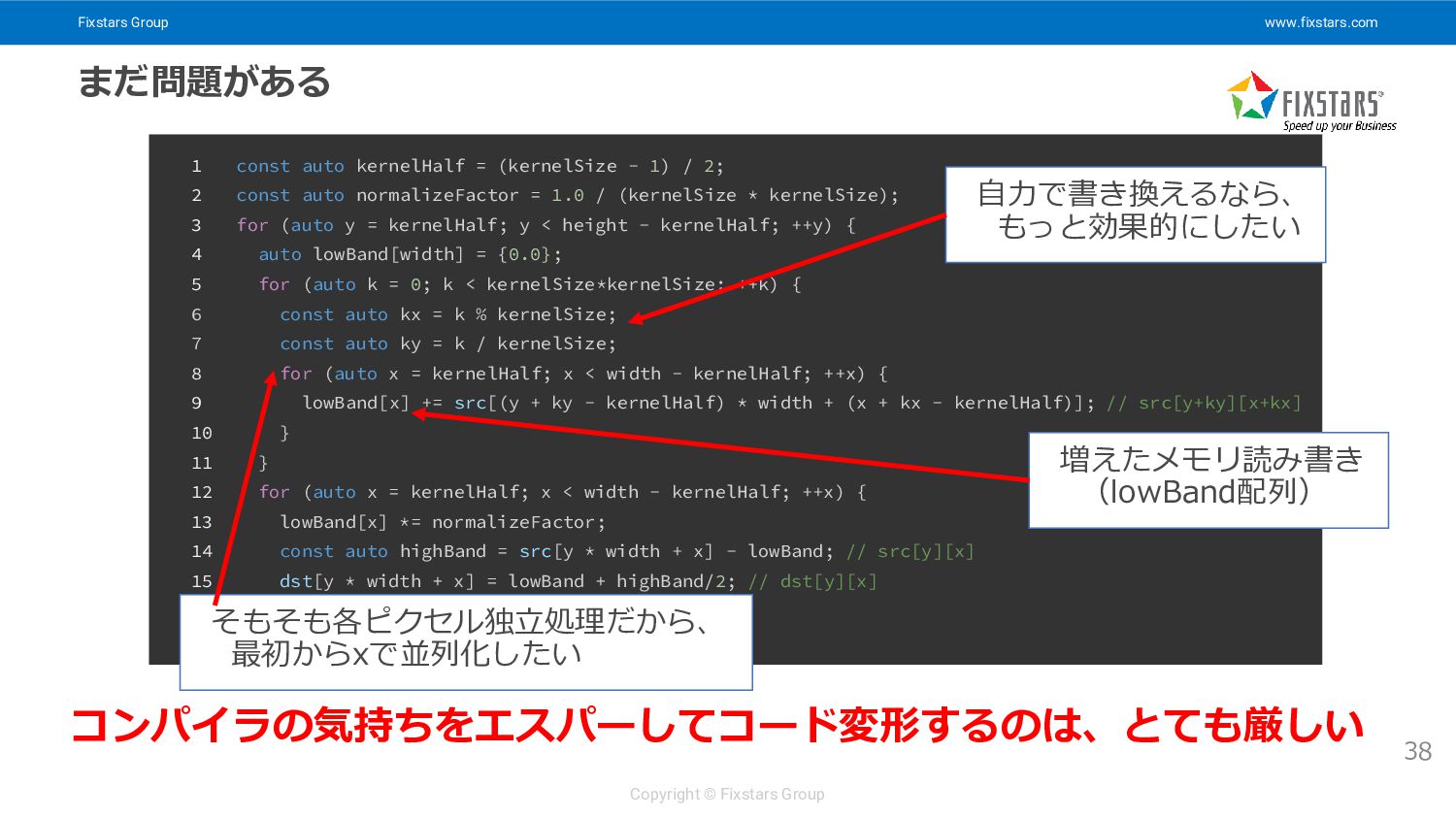
Fixstars Group www.fixstars.com Copyright © Fixstars Group まだ問題がある 38 1
const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 4 auto lowBand[width] = {0.0}; 5 for (auto k = 0; k < kernelSize*kernelSize; ++k) { 6 const auto kx = k % kernelSize; 7 const auto ky = k / kernelSize; 8 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 9 lowBand[x] += src[(y + ky - kernelHalf) * width + (x + kx - kernelHalf)]; // src[y+ky][x+kx] 10 } 11 } 12 for (auto x = kernelHalf; x < width - kernelHalf; ++x) { 13 lowBand[x] *= normalizeFactor; 14 const auto highBand = src[y * width + x] - lowBand; // src[y][x] 15 dst[y * width + x] = lowBand + highBand/2; // dst[y][x] 16 } 17 } 増えたメモリ読み書き (lowBand配列) 自力で書き換えるなら、 もっと効果的にしたい そもそも各ピクセル独立処理だから、 最初からxで並列化したい コンパイラの気持ちをエスパーしてコード変形するのは、とても厳しい
Fixstars Group www.fixstars.com Copyright © Fixstars Group Intrinsics(組み込み関数)を使う 39 コンパイラに任せず「どうしたいか」明記する
• VEだけでなく、Intel XeonのAVXなどでも広く使われる ◦ 命令アーキテクチャごとに、それぞれ用意される • 高速化するなら(どのアーキでも)最後はIntrinsicsに行き着く HW命令と1対1で対応する関数(Intrinsics) どこでどんな処理をしたいのか確実に指定できる (普通のC++に混ぜて一部だけ使うこともできる)
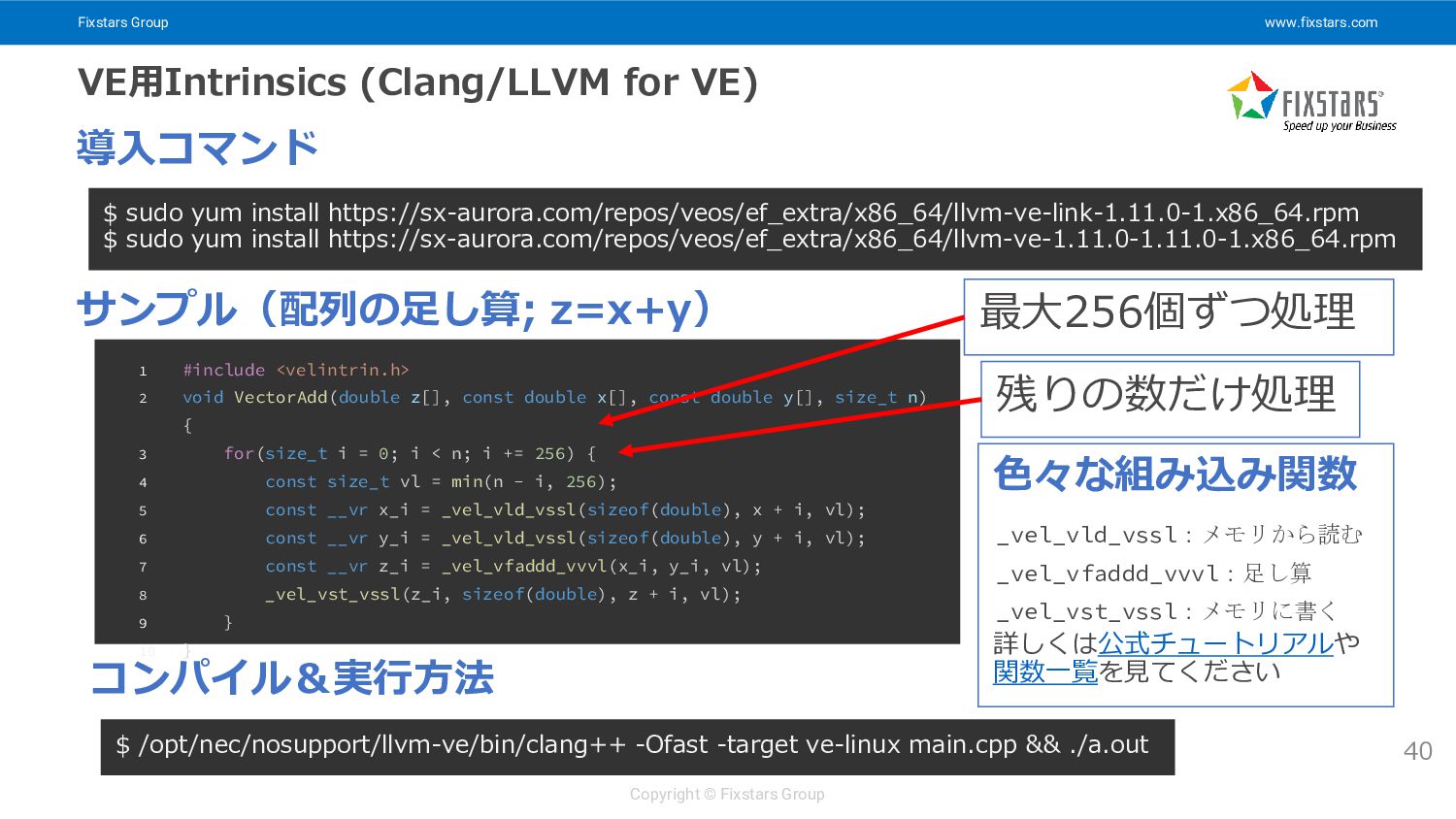
Fixstars Group www.fixstars.com Copyright © Fixstars Group VE用Intrinsics (Clang/LLVM for
VE) 40 $ sudo yum install https://sx-aurora.com/repos/veos/ef_extra/x86_64/llvm-ve-link-1.11.0-1.x86_64.rpm $ sudo yum install https://sx-aurora.com/repos/veos/ef_extra/x86_64/llvm-ve-1.11.0-1.11.0-1.x86_64.rpm 導入コマンド サンプル(配列の足し算; z=x+y) 1 #include <velintrin.h> 2 void VectorAdd(double z[], const double x[], const double y[], size_t n) { 3 for(size_t i = 0; i < n; i += 256) { 4 const size_t vl = min(n - i, 256); 5 const __vr x_i = _vel_vld_vssl(sizeof(double), x + i, vl); 6 const __vr y_i = _vel_vld_vssl(sizeof(double), y + i, vl); 7 const __vr z_i = _vel_vfaddd_vvvl(x_i, y_i, vl); 8 _vel_vst_vssl(z_i, sizeof(double), z + i, vl); 9 } 10 } コンパイル&実行方法 $ /opt/nec/nosupport/llvm-ve/bin/clang++ -Ofast -target ve-linux main.cpp && ./a.out _vel_vld_vssl:メモリから読む _vel_vfaddd_vvvl:足し算 _vel_vst_vssl:メモリに書く 最大256個ずつ処理 残りの数だけ処理 色々な組み込み関数 詳しくは公式チュートリアルや 関数一覧を見てください
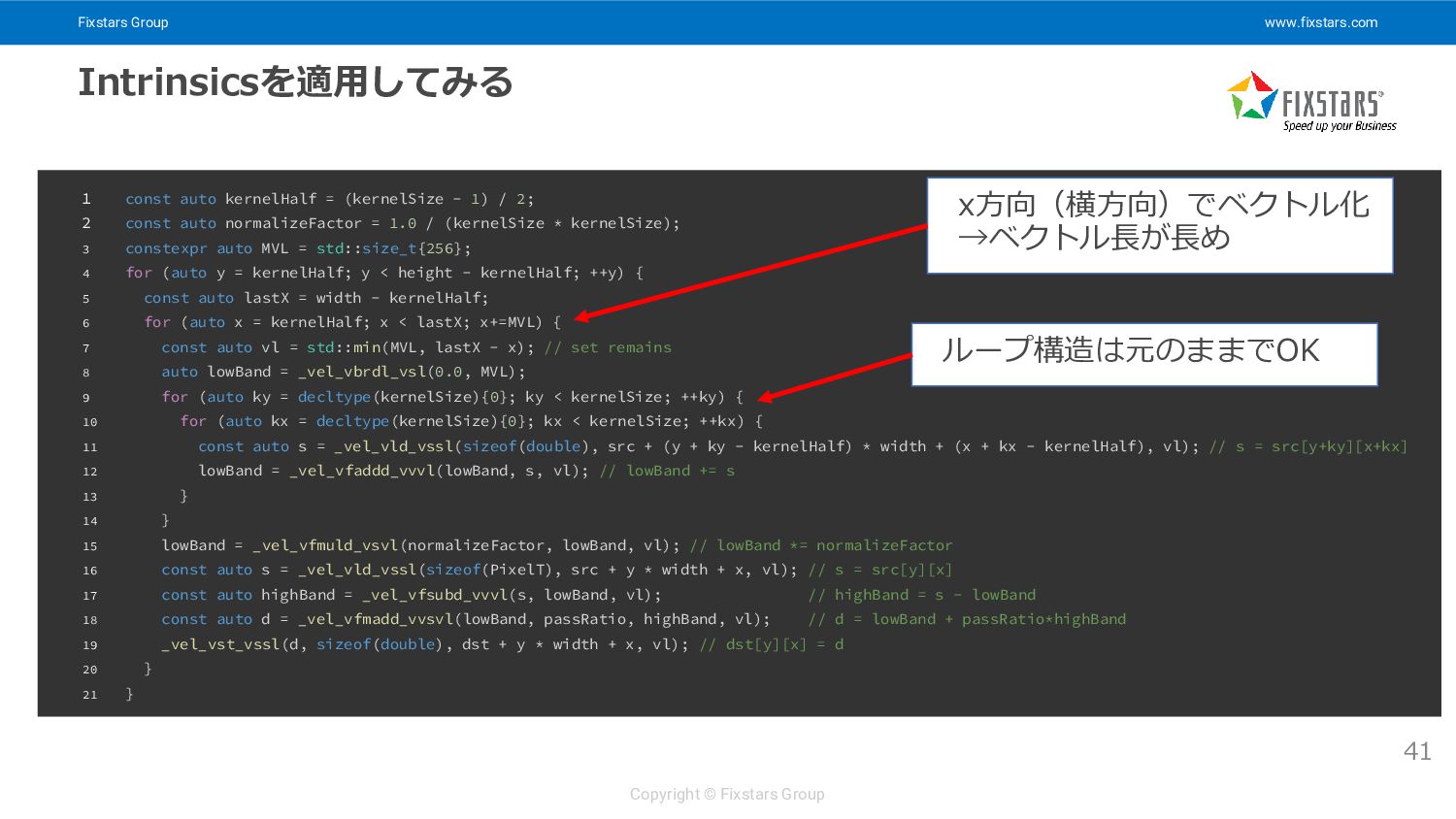
Fixstars Group www.fixstars.com Copyright © Fixstars Group Intrinsicsを適用してみる 41 1
const auto kernelHalf = (kernelSize - 1) / 2; 2 const auto normalizeFactor = 1.0 / (kernelSize * kernelSize); 3 constexpr auto MVL = std::size_t{256}; 4 for (auto y = kernelHalf; y < height - kernelHalf; ++y) { 5 const auto lastX = width - kernelHalf; 6 for (auto x = kernelHalf; x < lastX; x+=MVL) { 7 const auto vl = std::min(MVL, lastX - x); // set remains 8 auto lowBand = _vel_vbrdl_vsl(0.0, MVL); 9 for (auto ky = decltype(kernelSize){0}; ky < kernelSize; ++ky) { 10 for (auto kx = decltype(kernelSize){0}; kx < kernelSize; ++kx) { 11 const auto s = _vel_vld_vssl(sizeof(double), src + (y + ky - kernelHalf) * width + (x + kx - kernelHalf), vl); // s = src[y+ky][x+kx] 12 lowBand = _vel_vfaddd_vvvl(lowBand, s, vl); // lowBand += s 13 } 14 } 15 lowBand = _vel_vfmuld_vsvl(normalizeFactor, lowBand, vl); // lowBand *= normalizeFactor 16 const auto s = _vel_vld_vssl(sizeof(PixelT), src + y * width + x, vl); // s = src[y][x] 17 const auto highBand = _vel_vfsubd_vvvl(s, lowBand, vl); // highBand = s - lowBand 18 const auto d = _vel_vfmadd_vvsvl(lowBand, passRatio, highBand, vl); // d = lowBand + passRatio*highBand 19 _vel_vst_vssl(d, sizeof(double), dst + y * width + x, vl); // dst[y][x] = d 20 } 21 } x方向(横方向)でベクトル化 →ベクトル長が長め ループ構造は元のままでOK
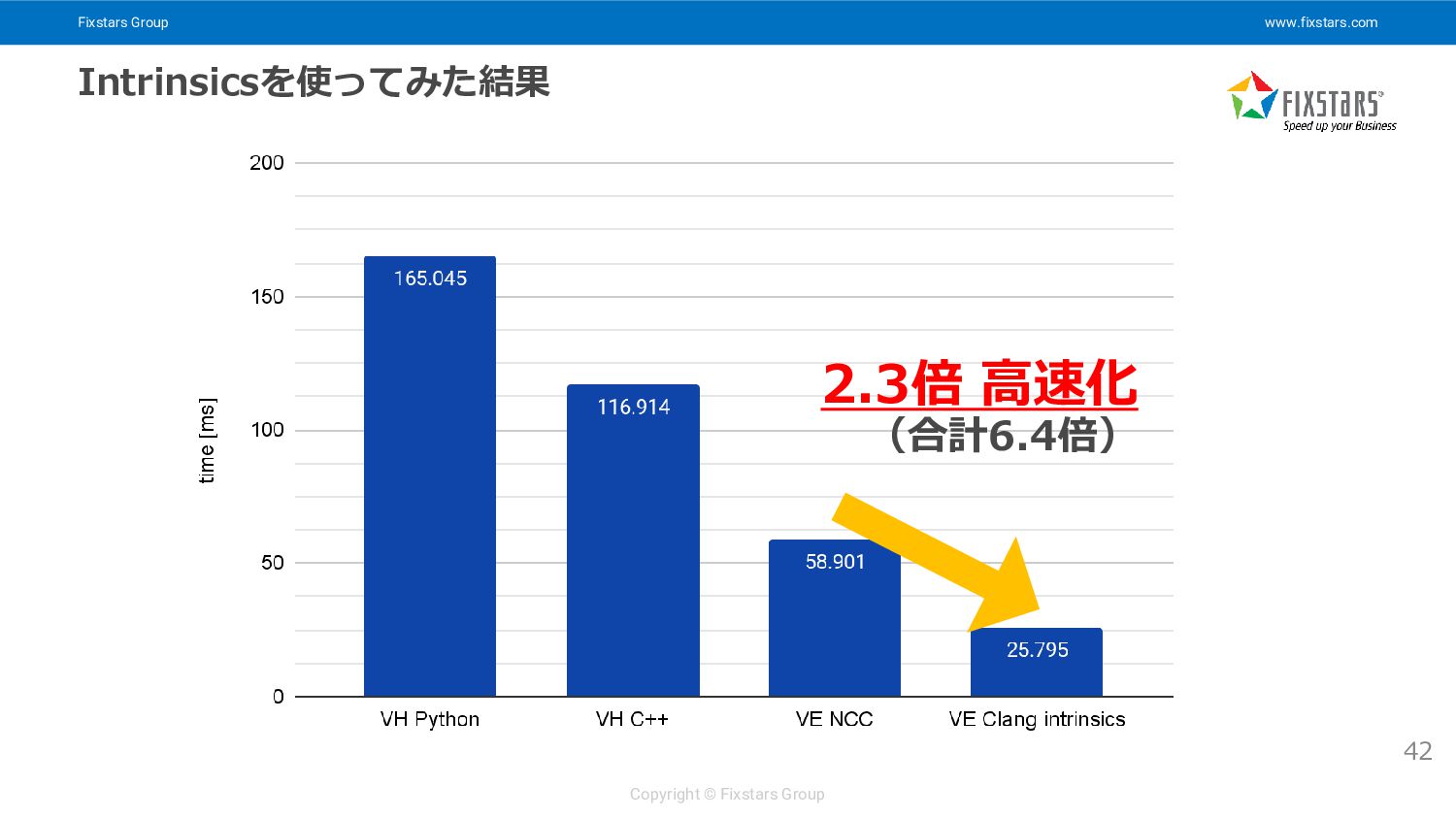
Fixstars Group www.fixstars.com Copyright © Fixstars Group Intrinsicsを使ってみた結果 42 2.3倍
高速化 (合計6.4倍)
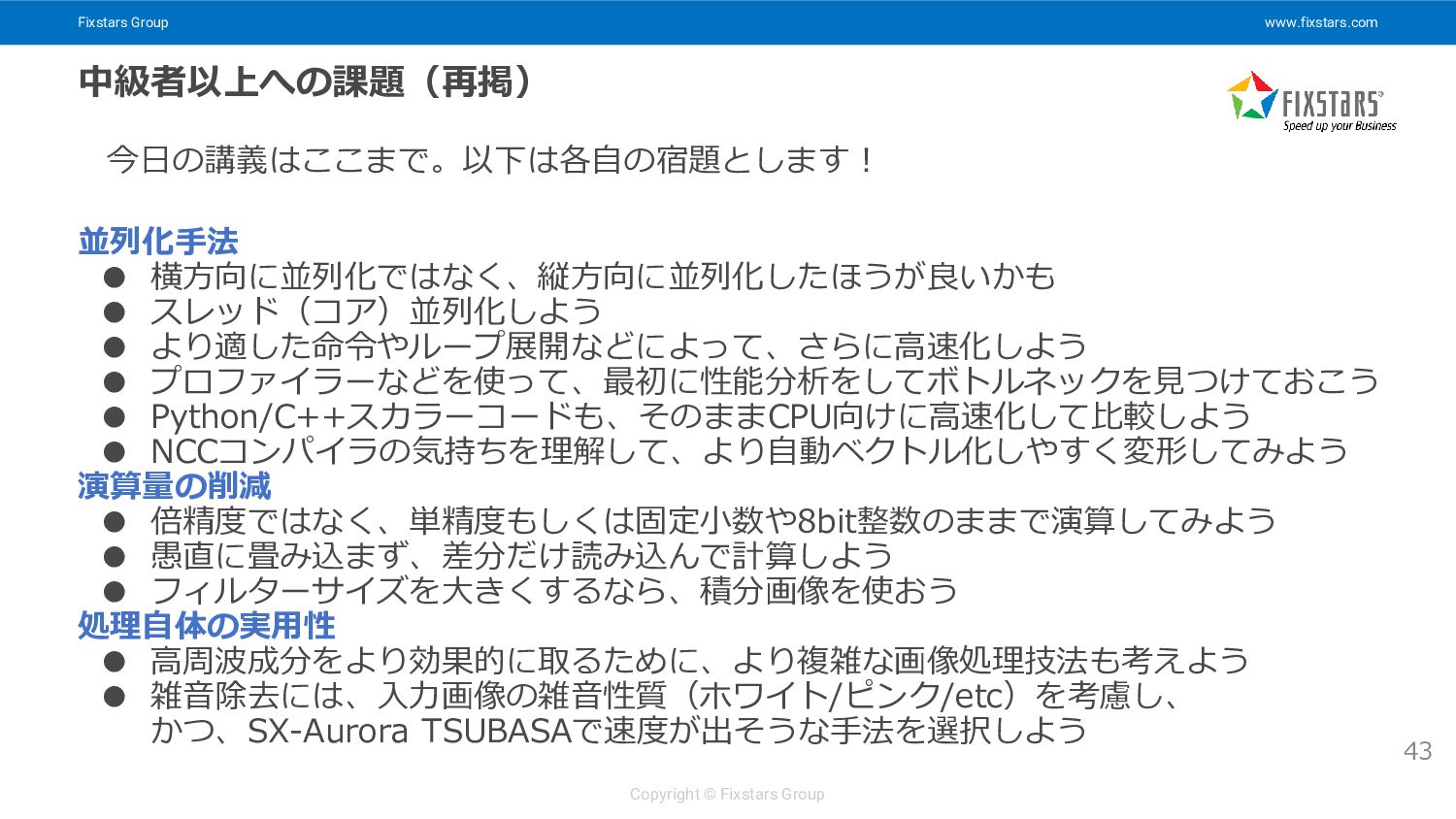
Fixstars Group www.fixstars.com Copyright © Fixstars Group 中級者以上への課題(再掲) 43 今日の講義はここまで。以下は各自の宿題とします!
並列化手法 • 横方向に並列化ではなく、縦方向に並列化したほうが良いかも • スレッド(コア)並列化しよう • より適した命令やループ展開などによって、さらに高速化しよう • プロファイラーなどを使って、最初に性能分析をしてボトルネックを見つけておこう • Python/C++スカラーコードも、そのままCPU向けに高速化して比較しよう • NCCコンパイラの気持ちを理解して、より自動ベクトル化しやすく変形してみよう 演算量の削減 • 倍精度ではなく、単精度もしくは固定小数や8bit整数のままで演算してみよう • 愚直に畳み込まず、差分だけ読み込んで計算しよう • フィルターサイズを大きくするなら、積分画像を使おう 処理自体の実用性 • 高周波成分をより効果的に取るために、より複雑な画像処理技法も考えよう • 雑音除去には、入力画像の雑音性質(ホワイト/ピンク/etc)を考慮し、 かつ、SX-Aurora TSUBASAで速度が出そうな手法を選択しよう
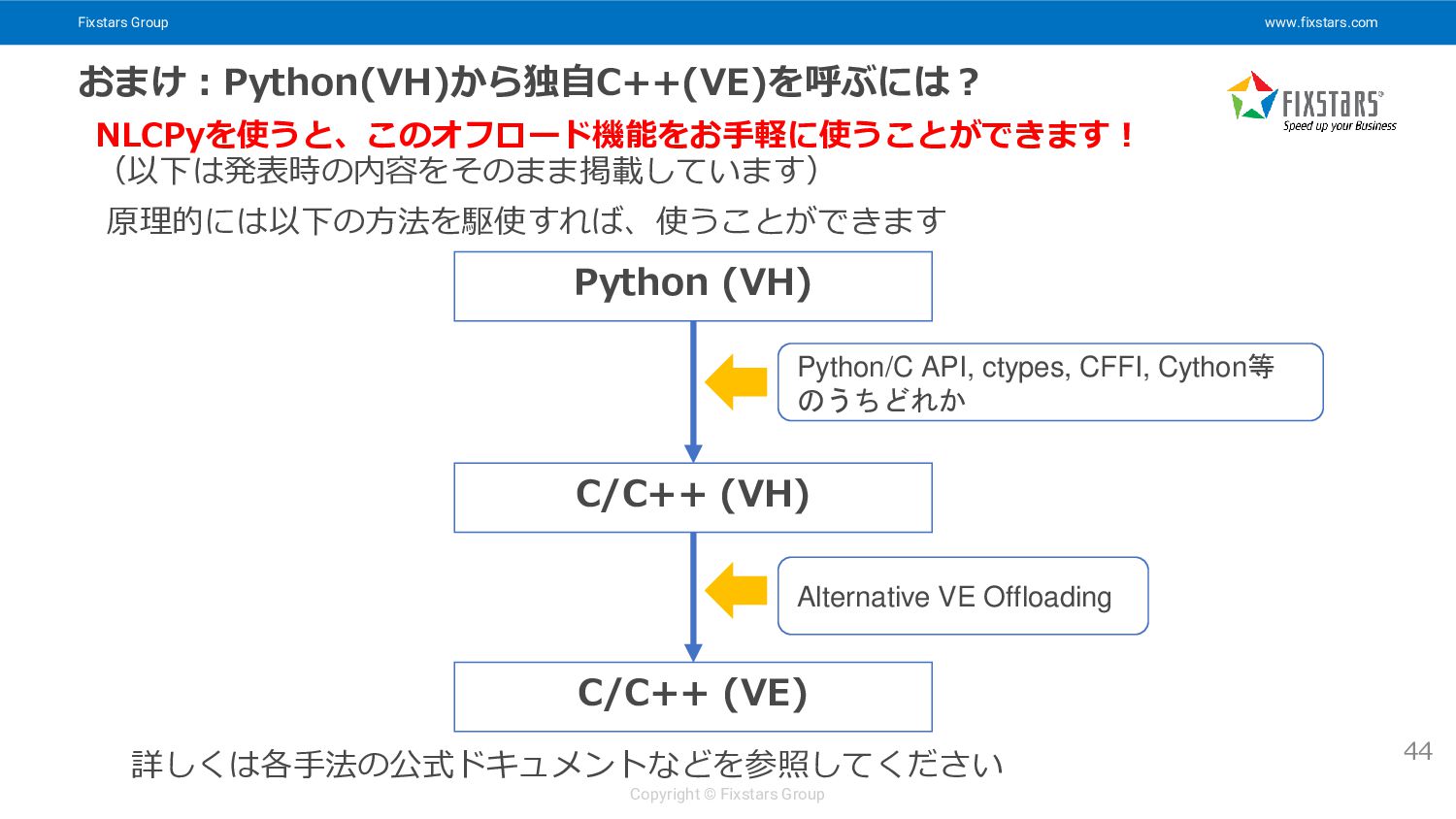
Fixstars Group www.fixstars.com Copyright © Fixstars Group おまけ:Python(VH)から独自C++(VE)を呼ぶには? 44 原理的には以下の方法を駆使すれば、使うことができます
詳しくは各手法の公式ドキュメントなどを参照してください Python (VH) C/C++ (VH) C/C++ (VE) Python/C API, ctypes, CFFI, Cython等 のうちどれか Alternative VE Offloading NLCPyを使うと、このオフロード機能をお手軽に使うことができます! (以下は発表時の内容をそのまま掲載しています)
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答質疑応答
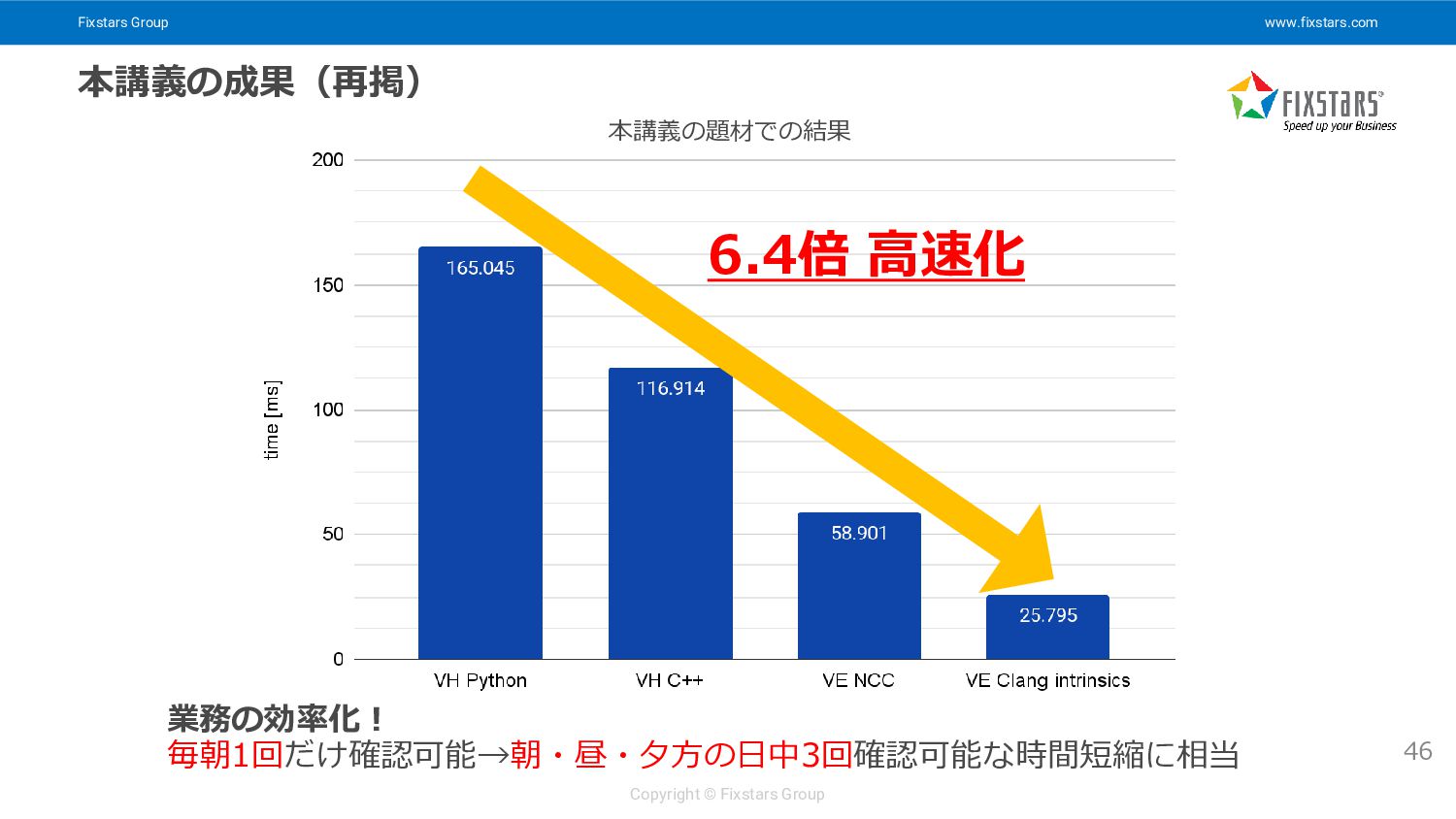
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本講義の成果(再掲) 46 業務の効率化!
毎朝1回だけ確認可能→朝・昼・夕方の日中3回確認可能な時間短縮に相当 6.4倍 高速化 本講義の題材での結果
Fixstars Group www.fixstars.com Copyright © Fixstars Group SX-Aurora TSUBASAの性能を引き出すためには 47
•C++(またはC言語)で書こう • メモリアクセス量を減らすループが書きやすい •NCCで自動ベクトル化を試してみよう • 複雑な処理ではうまくいかないことがある •最終的には、Clang intrinsicsを使おう • 明示的に指定して適切な場所でベクトル化させよう <宣伝> 高速化でお困りですか?
[email protected]
へお問い合わせください
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 1. 概要 2. 自己紹介 3. 講義で取り上げる題材 4. 高速化技法 a. Python OpenCV b. C++ c. NCCコンパイラによる自動ベクトル化 d. Clang intrinsicsによる確実な高速化 5. まとめ 6. アンケート回答・質疑応答
Fixstars Group www.fixstars.com Copyright © Fixstars Group return 0; お問い合わせ窓口
:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}