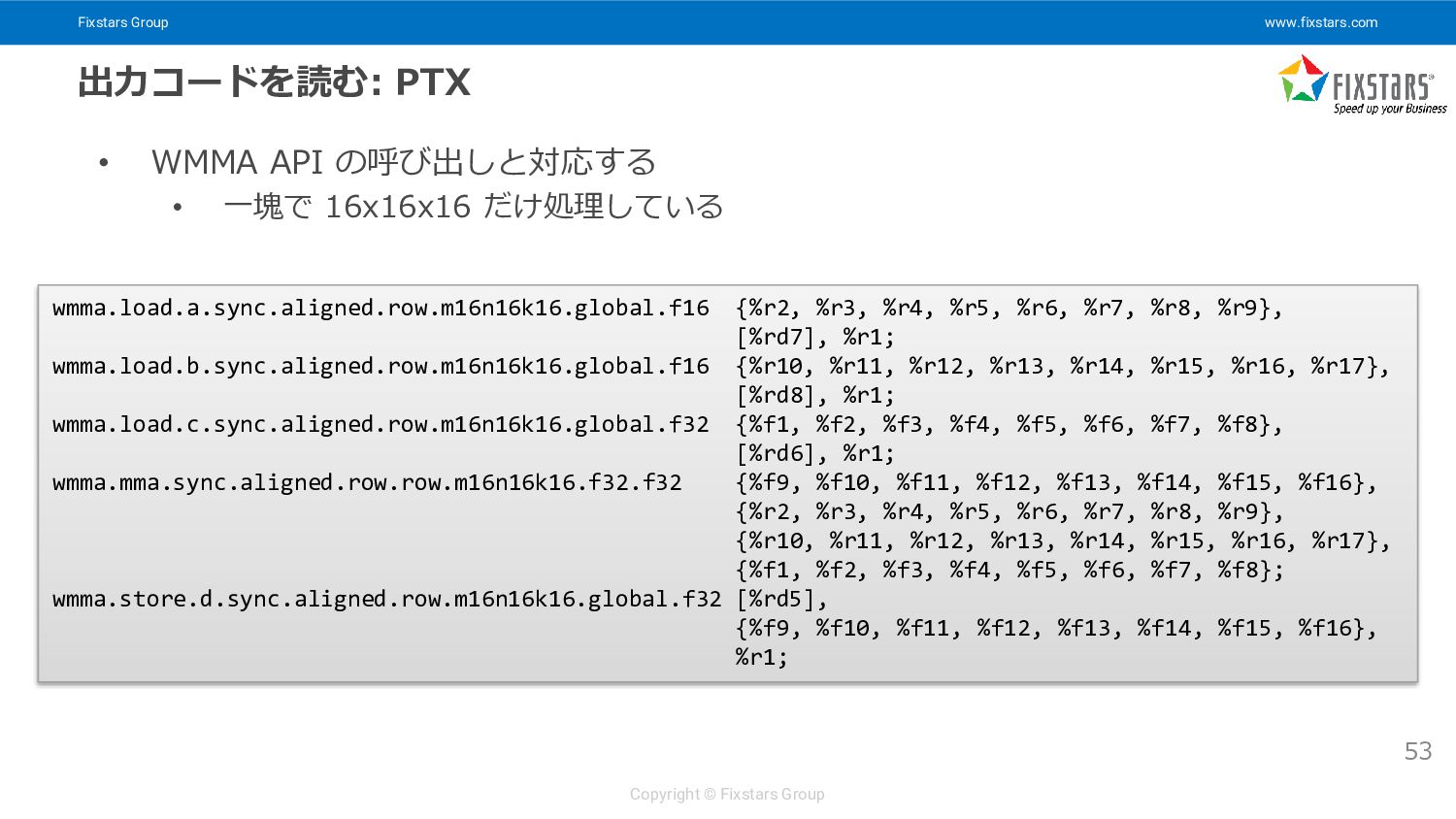
WMMA API の呼び出しと対応する • 一塊で 16x16x16 だけ処理している 53 wmma.load.a.sync.aligned.row.m16n16k16.global.f16 {%r2, %r3, %r4, %r5, %r6, %r7, %r8, %r9}, [%rd7], %r1; wmma.load.b.sync.aligned.row.m16n16k16.global.f16 {%r10, %r11, %r12, %r13, %r14, %r15, %r16, %r17}, [%rd8], %r1; wmma.load.c.sync.aligned.row.m16n16k16.global.f32 {%f1, %f2, %f3, %f4, %f5, %f6, %f7, %f8}, [%rd6], %r1; wmma.mma.sync.aligned.row.row.m16n16k16.f32.f32 {%f9, %f10, %f11, %f12, %f13, %f14, %f15, %f16}, {%r2, %r3, %r4, %r5, %r6, %r7, %r8, %r9}, {%r10, %r11, %r12, %r13, %r14, %r15, %r16, %r17}, {%f1, %f2, %f3, %f4, %f5, %f6, %f7, %f8}; wmma.store.d.sync.aligned.row.m16n16k16.global.f32 [%rd5], {%f9, %f10, %f11, %f12, %f13, %f14, %f15, %f16}, %r1;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
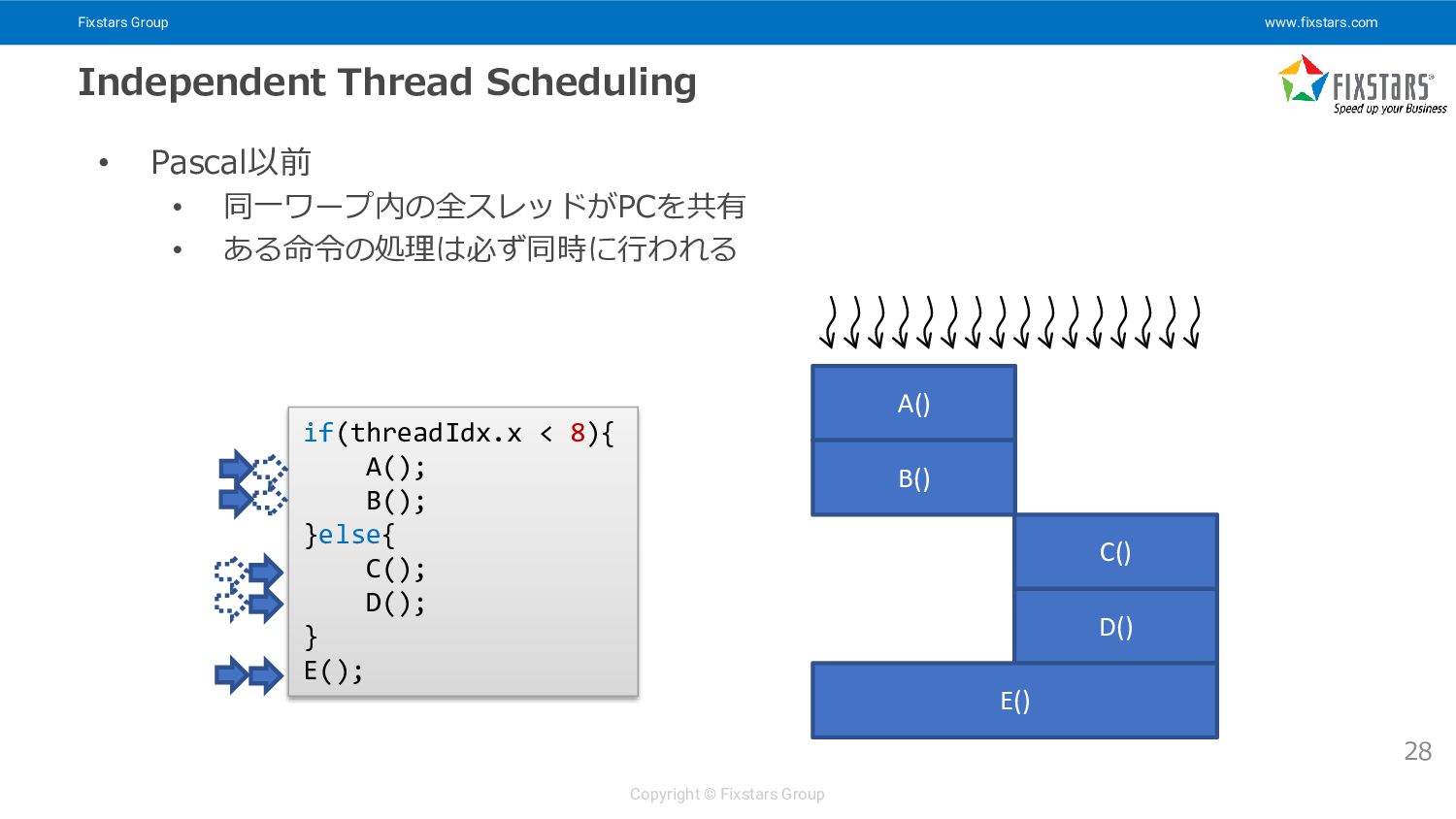{kind=link}
{kind=link}
{kind=link}
{kind=link}
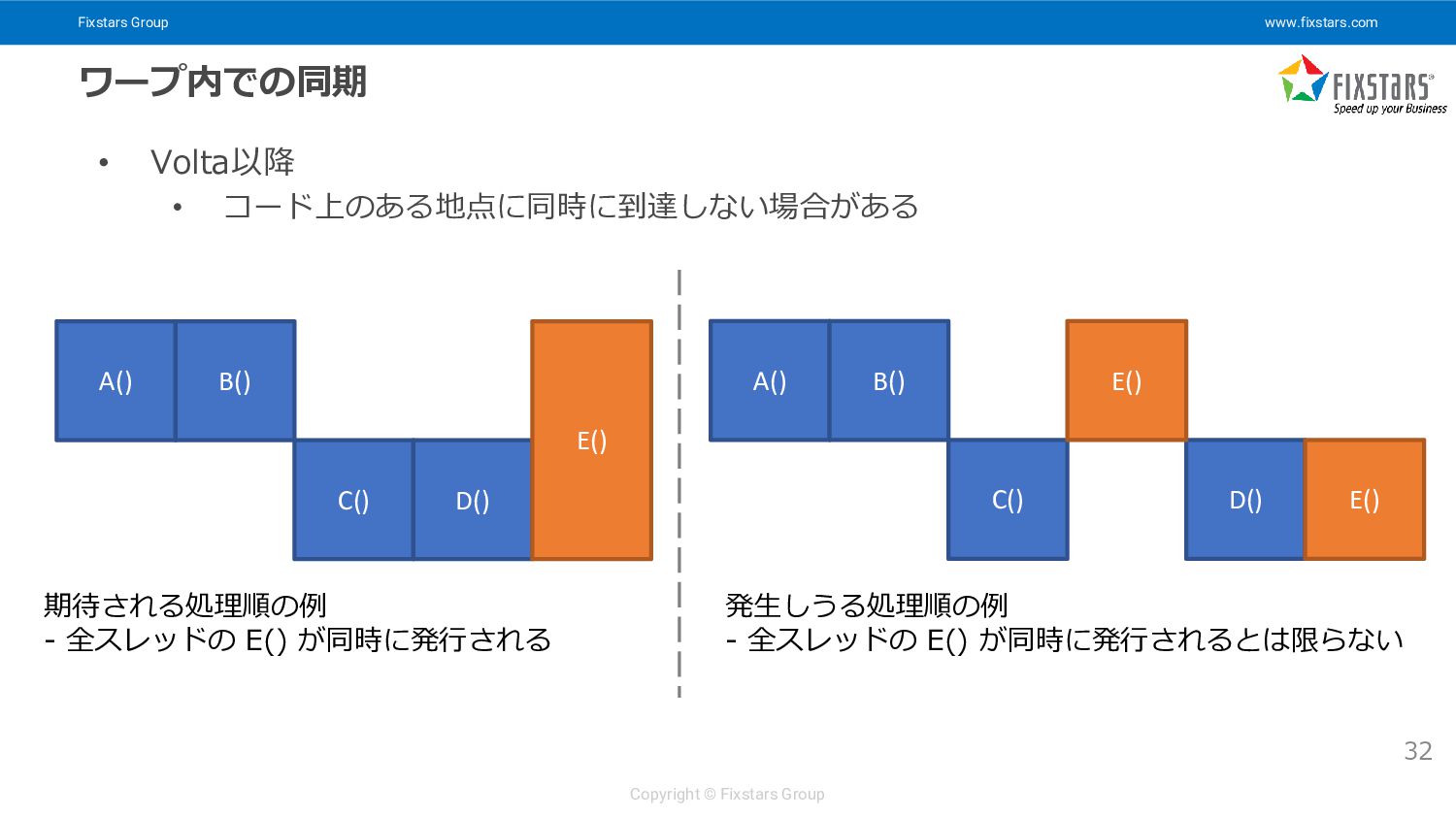{kind=link}
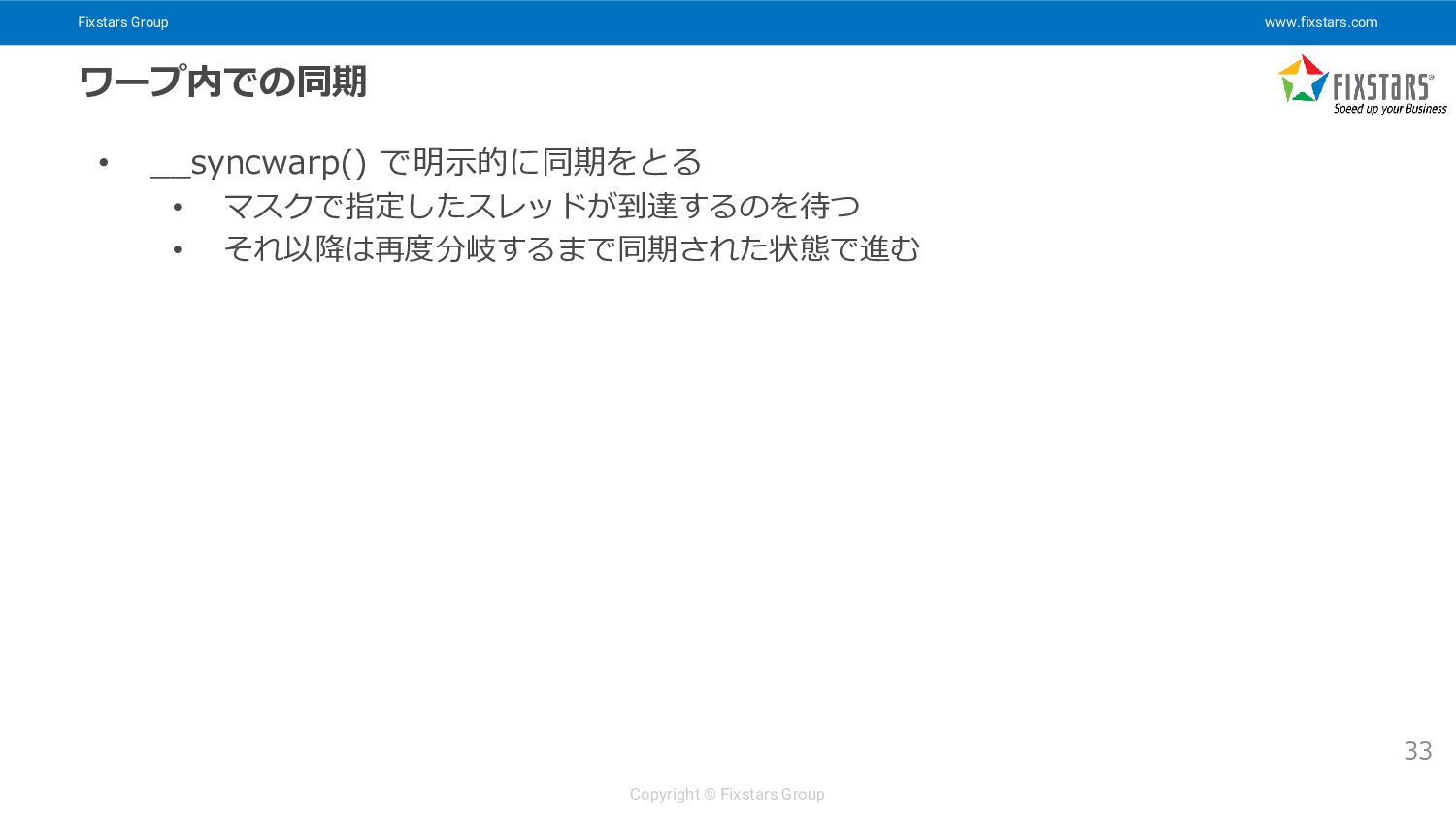{kind=link}
{kind=link}
{kind=link}
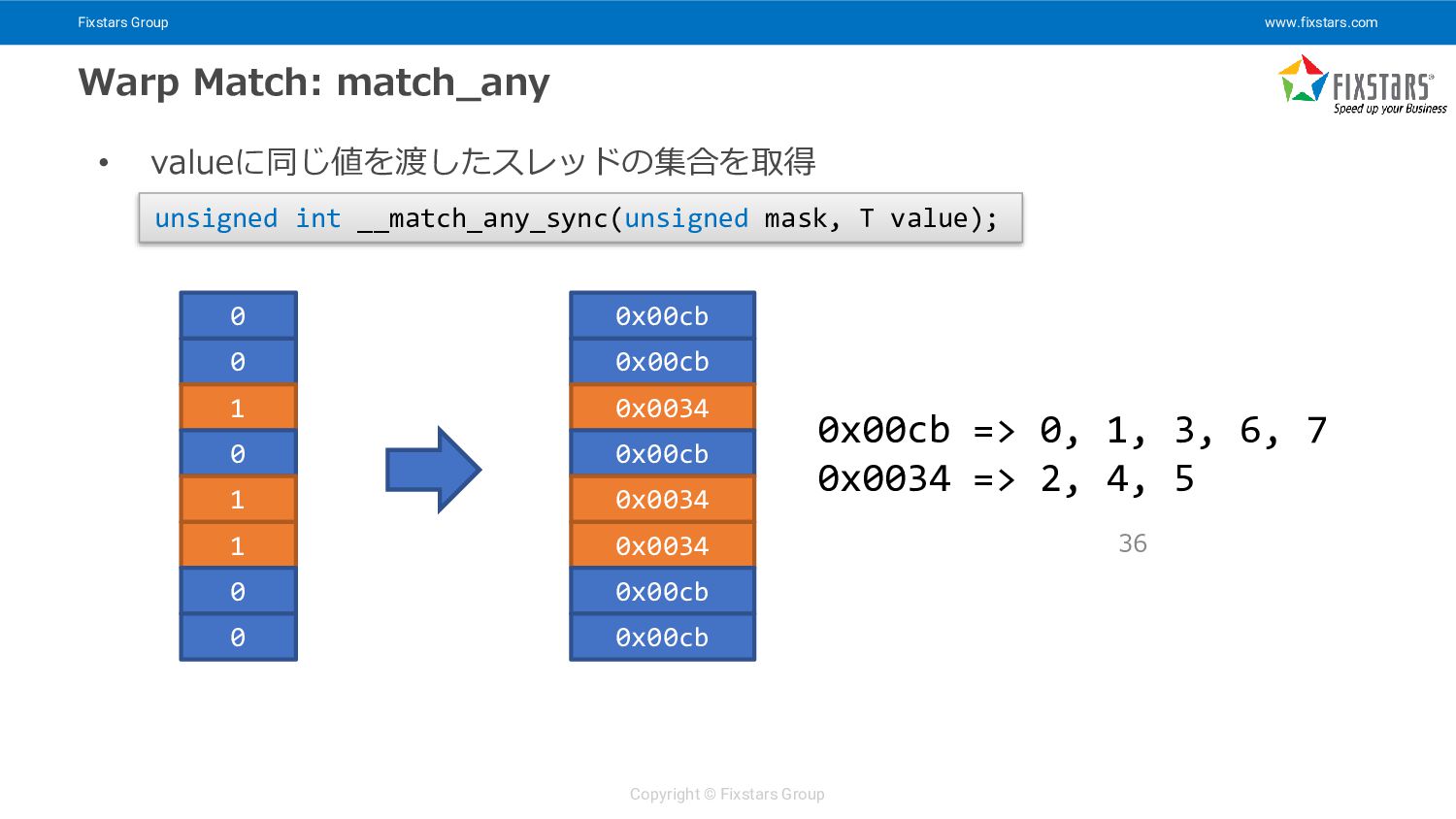{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
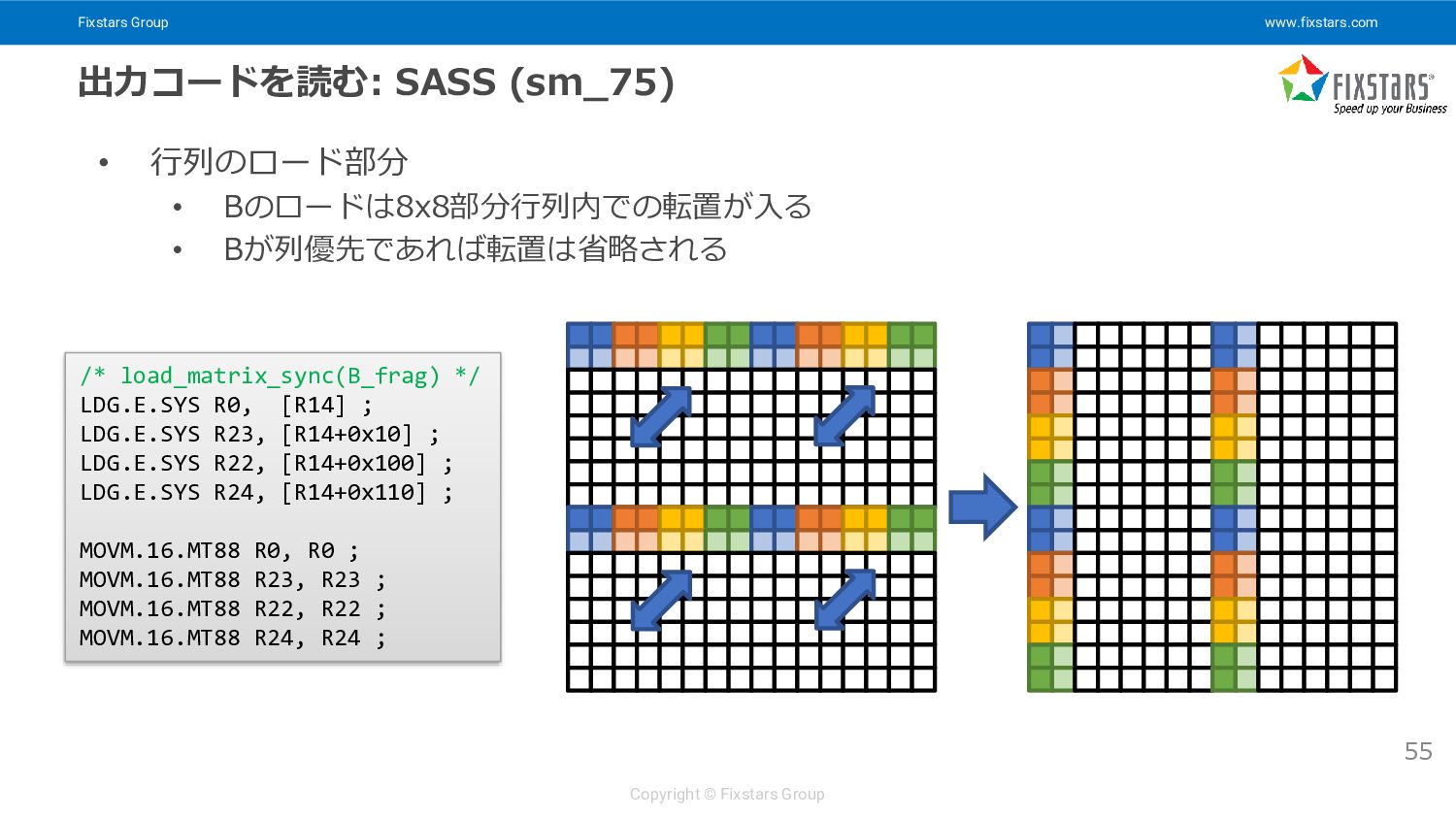{kind=link}
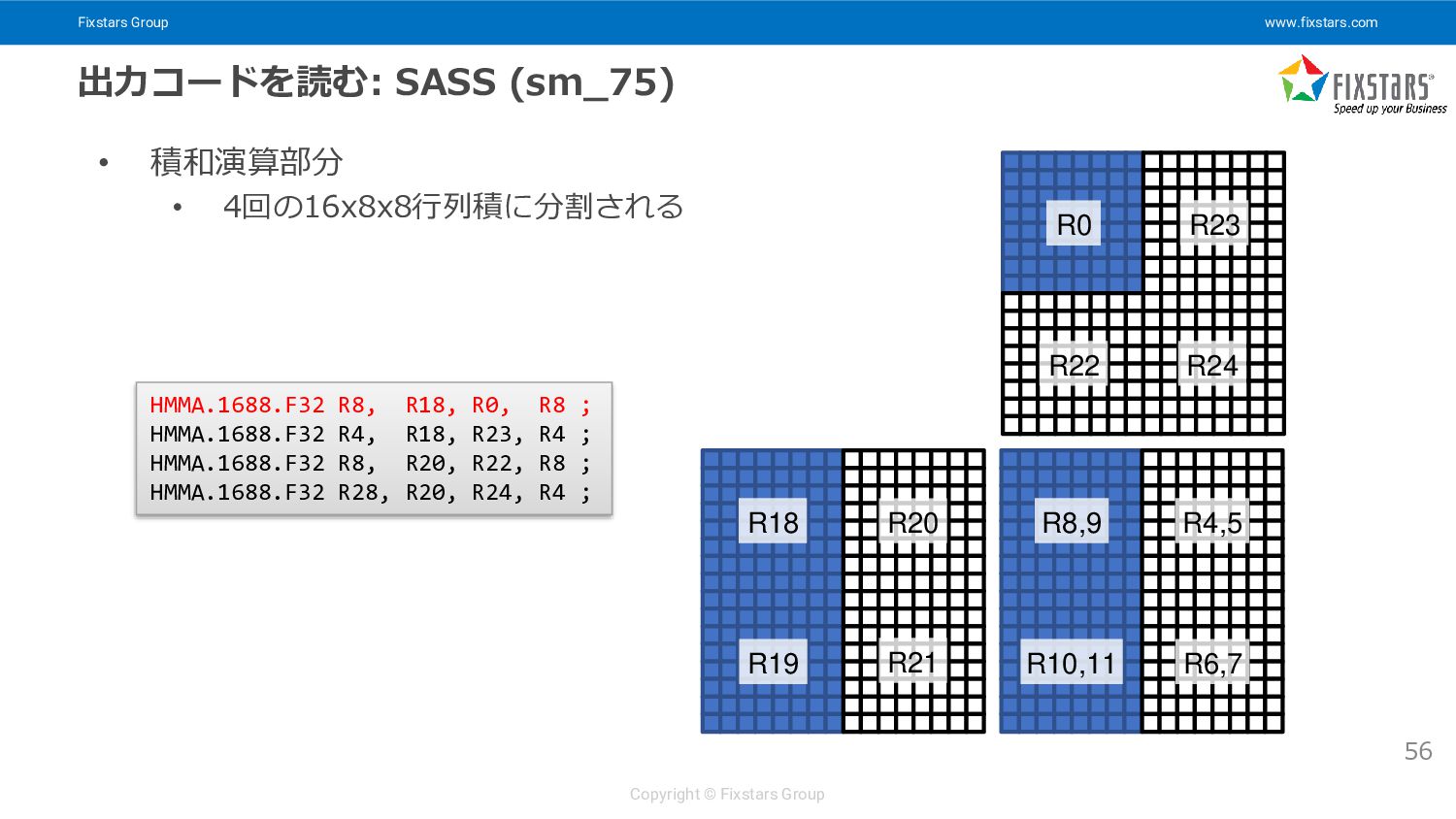{kind=link}
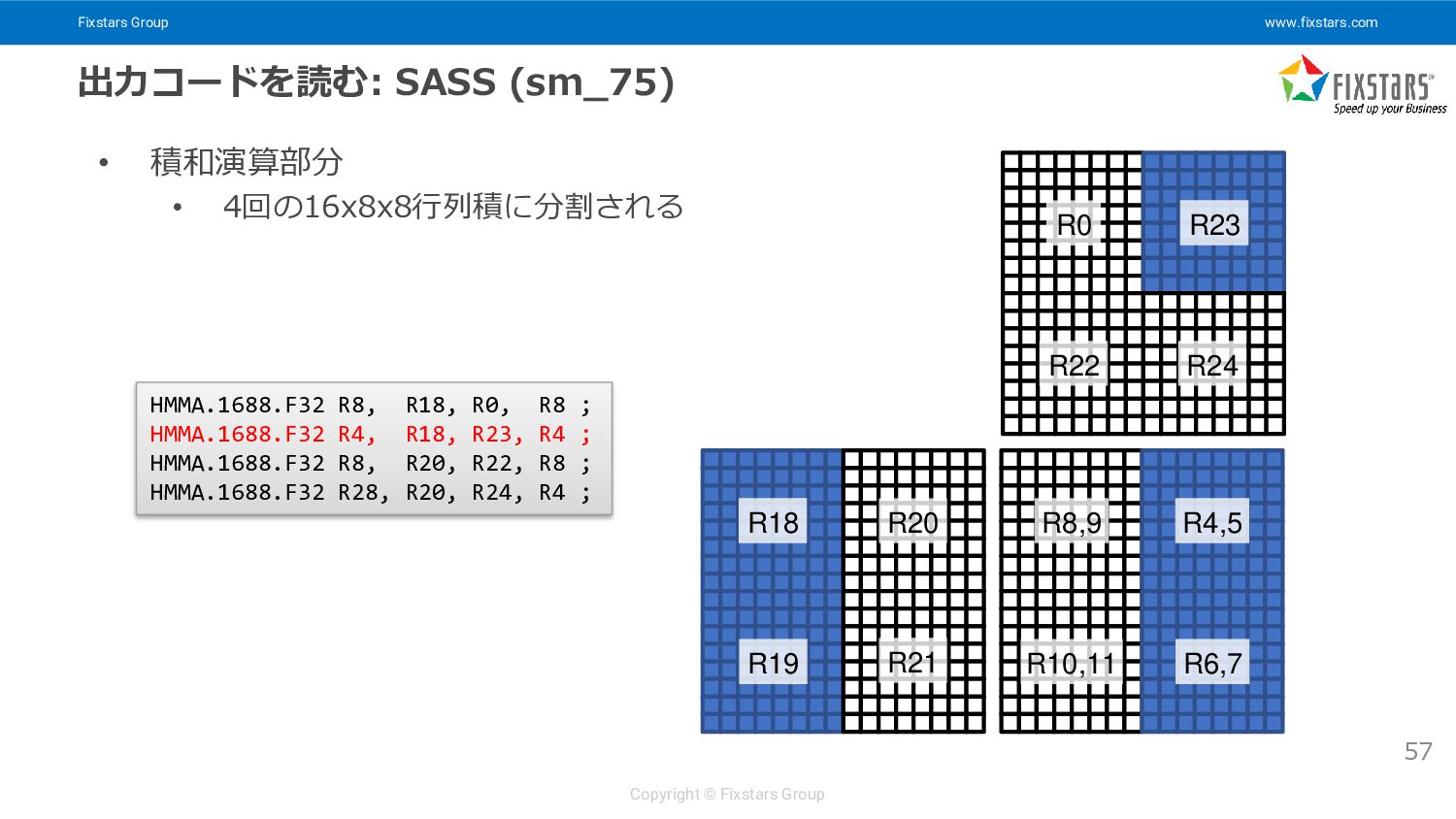{kind=link}
{kind=link}
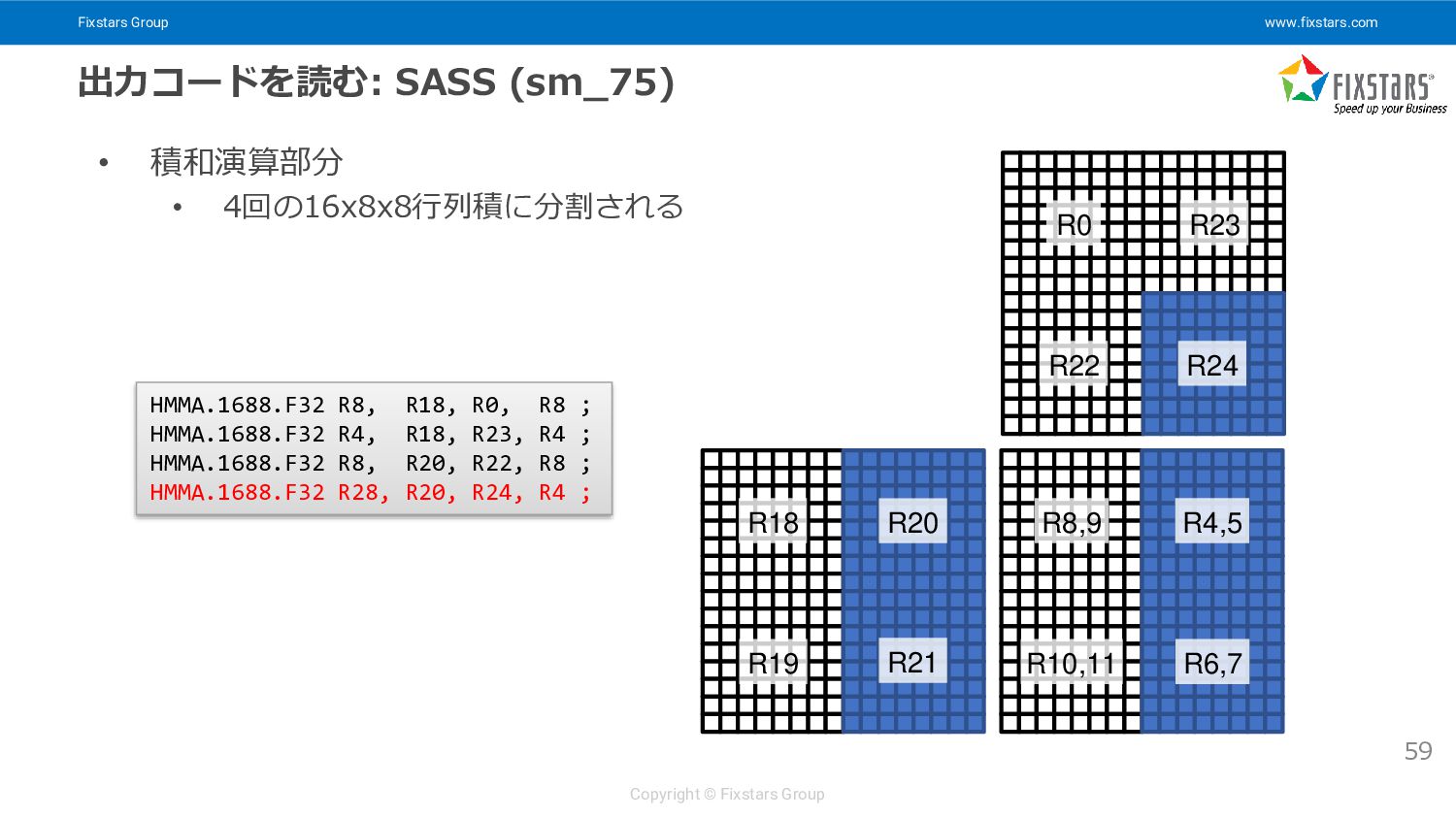{kind=link}
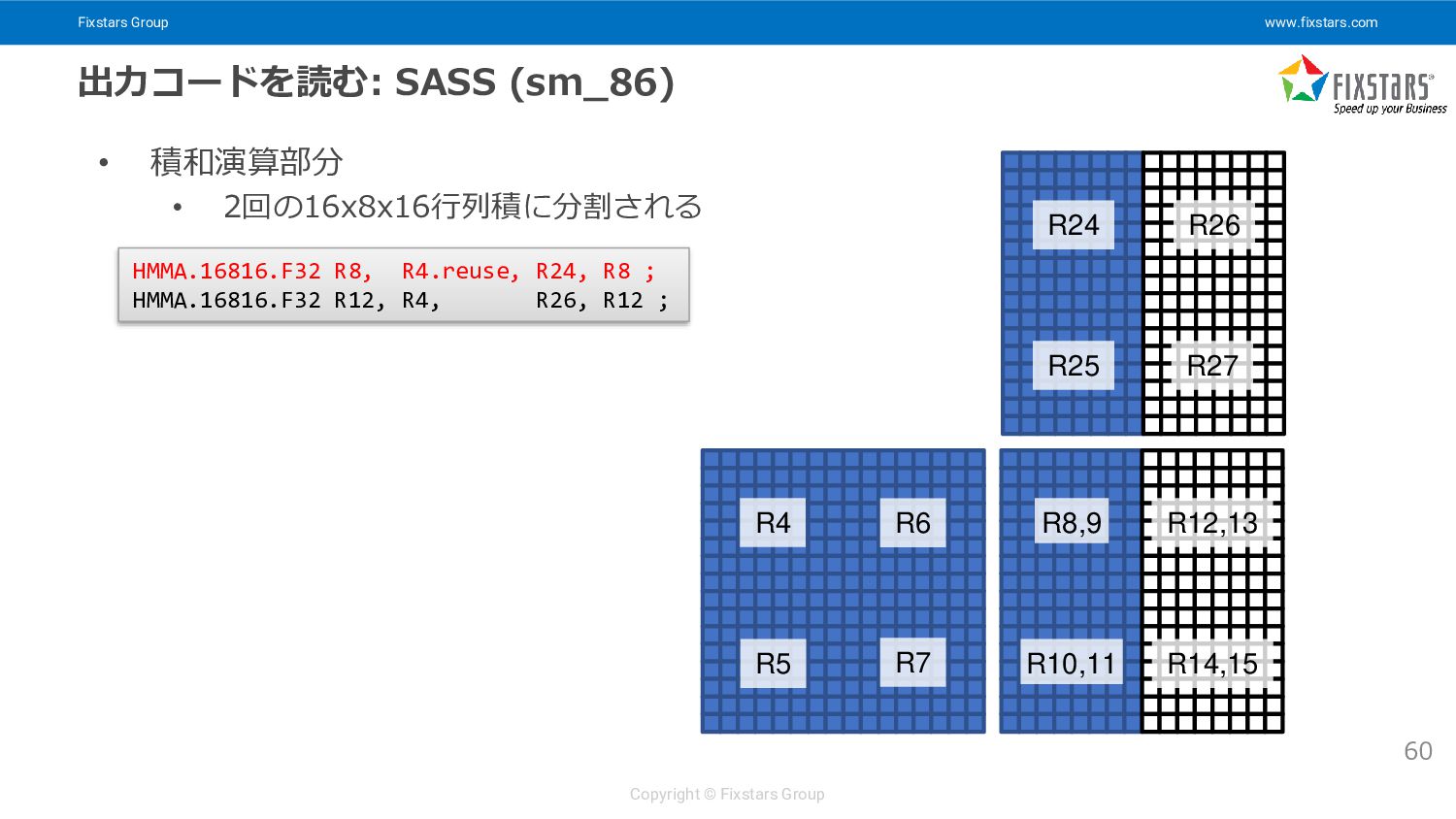{kind=link}
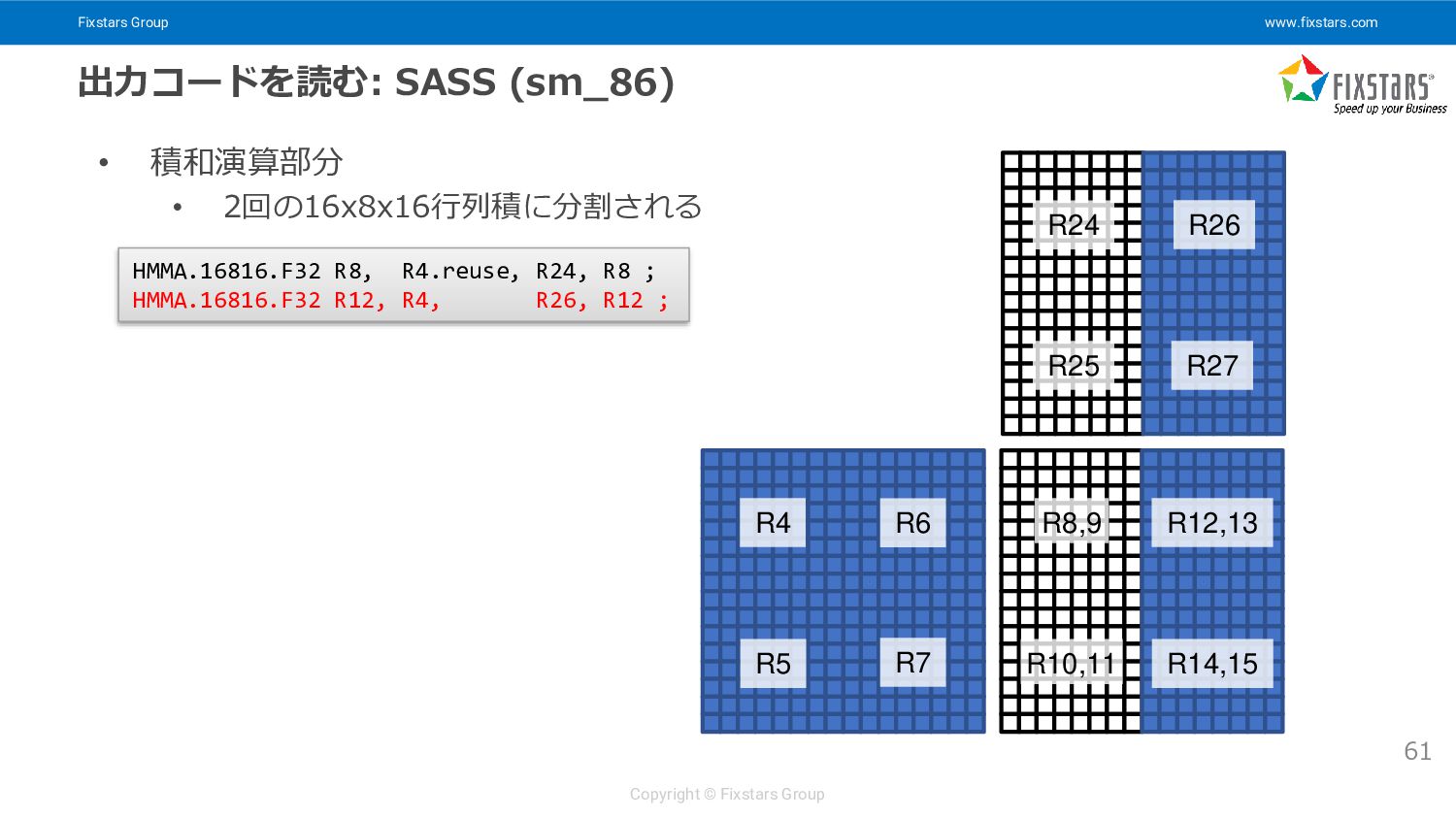{kind=link}
{kind=link}
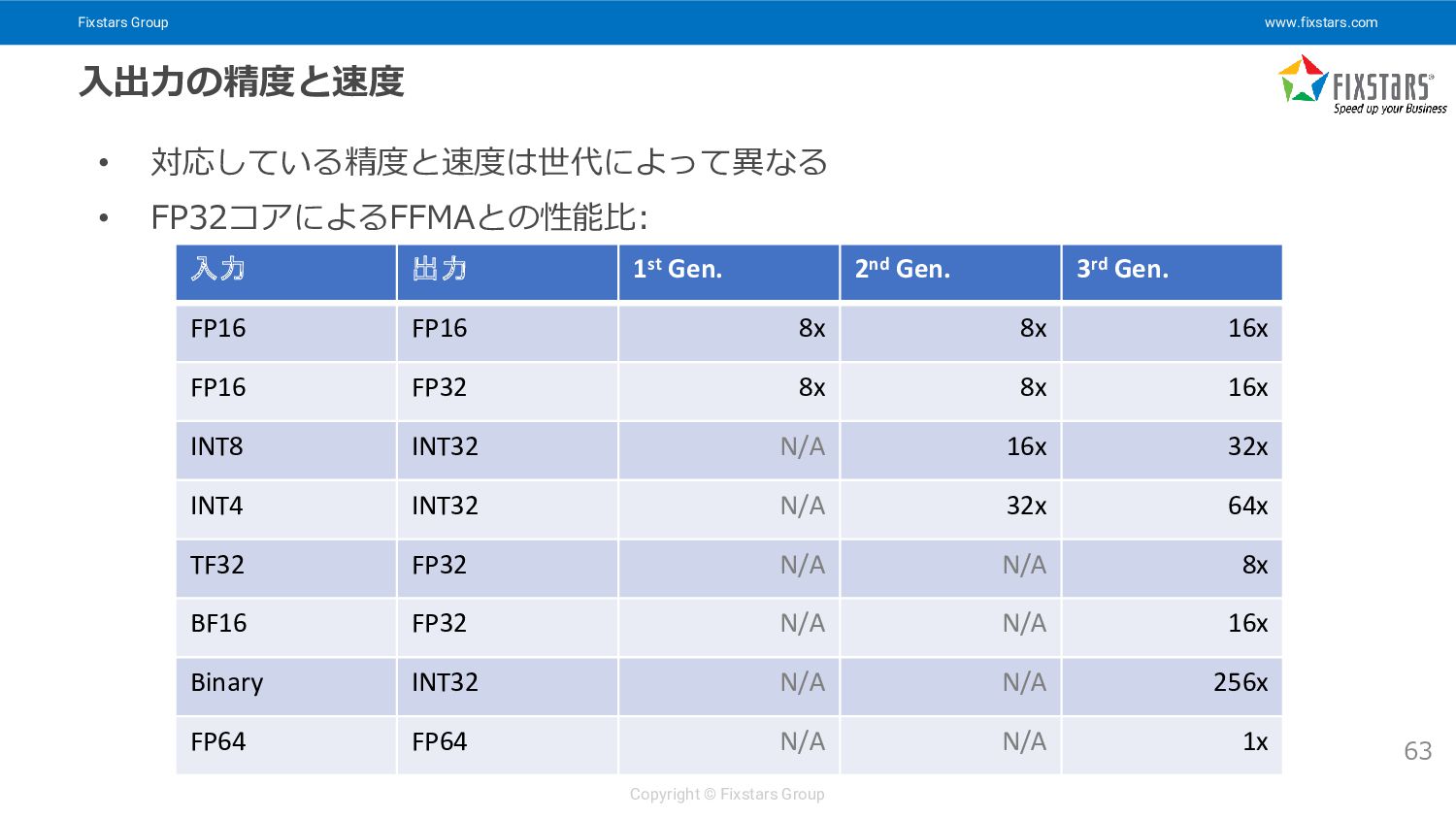{kind=link}
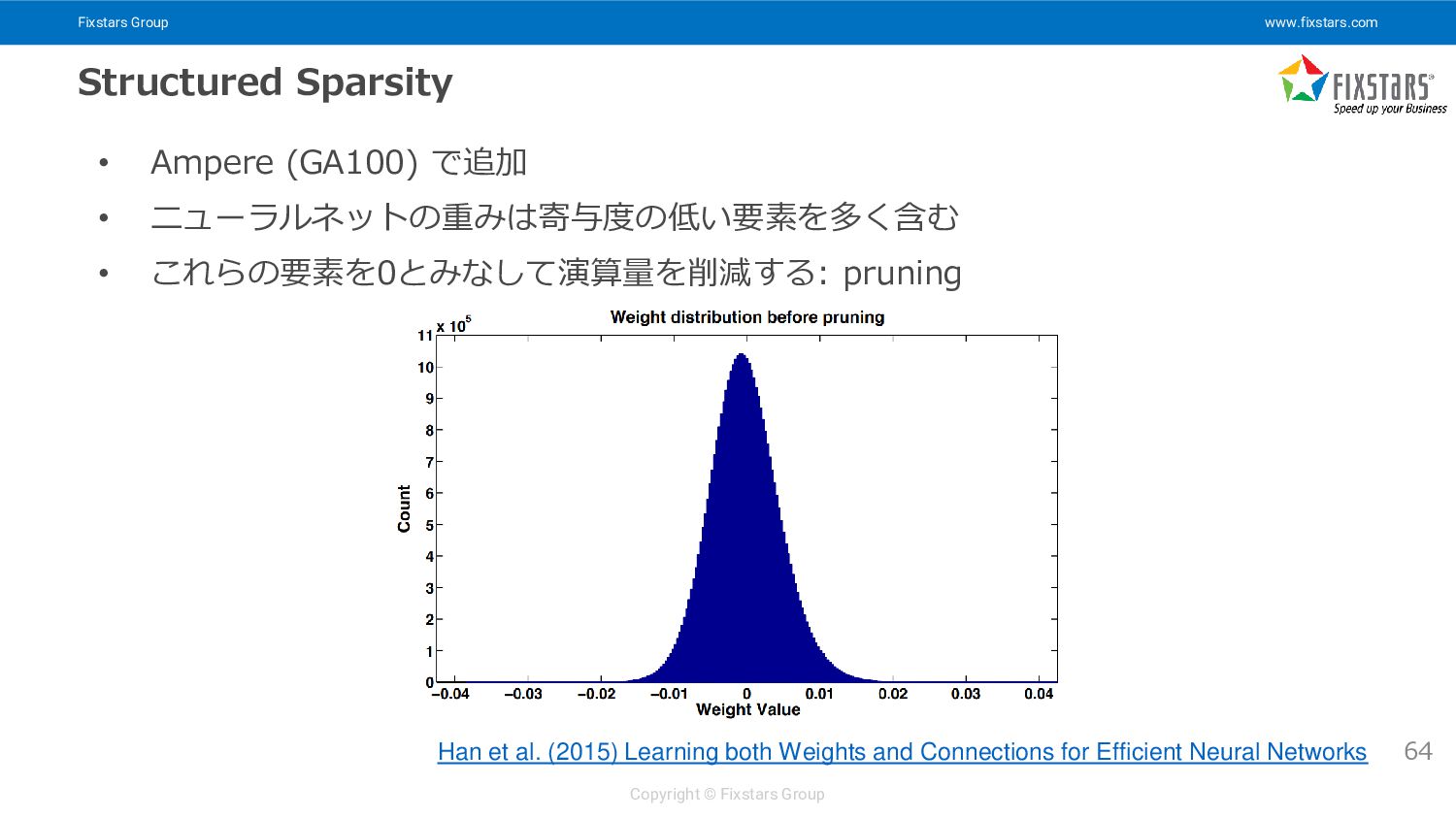{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
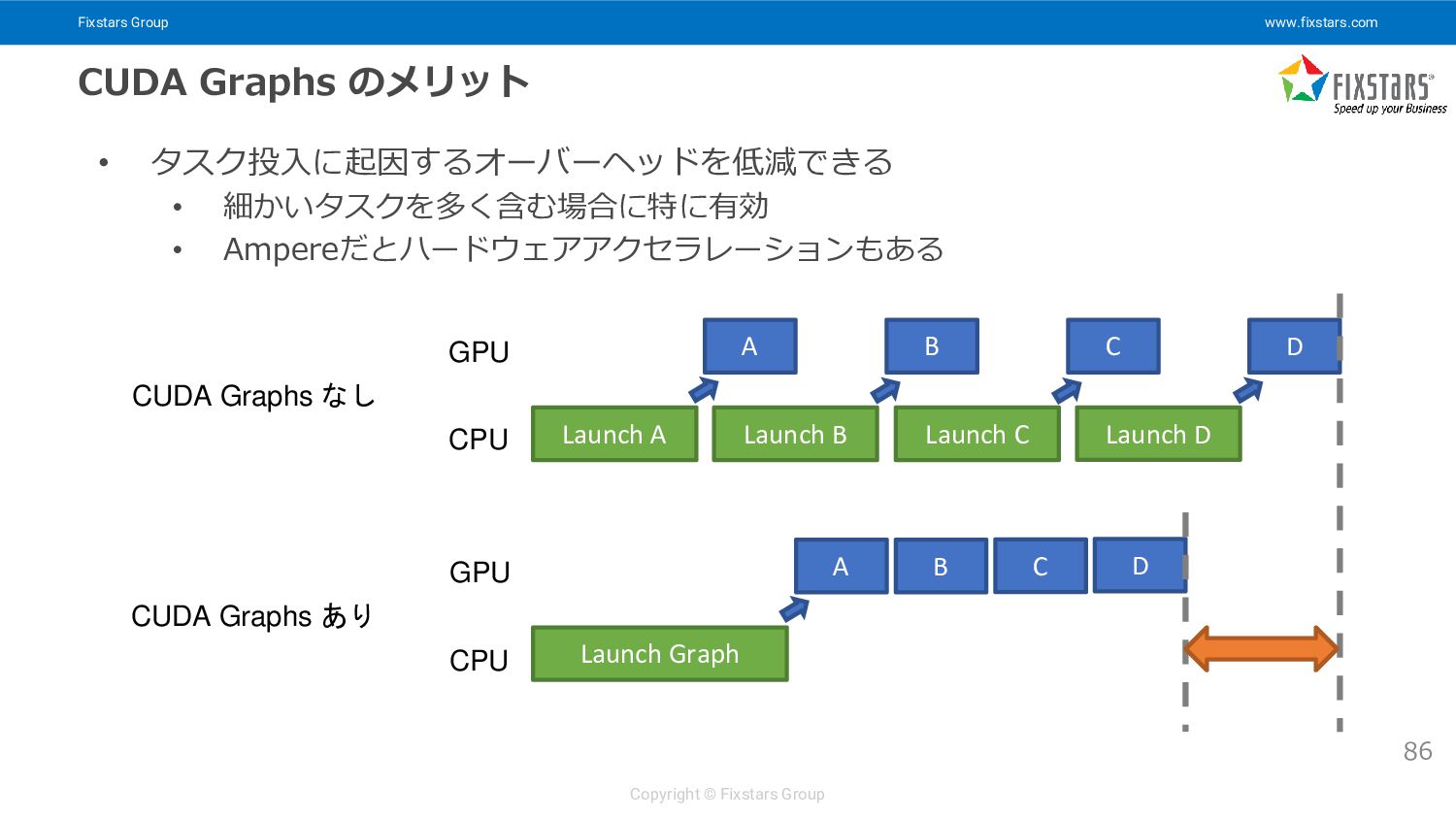{kind=link}
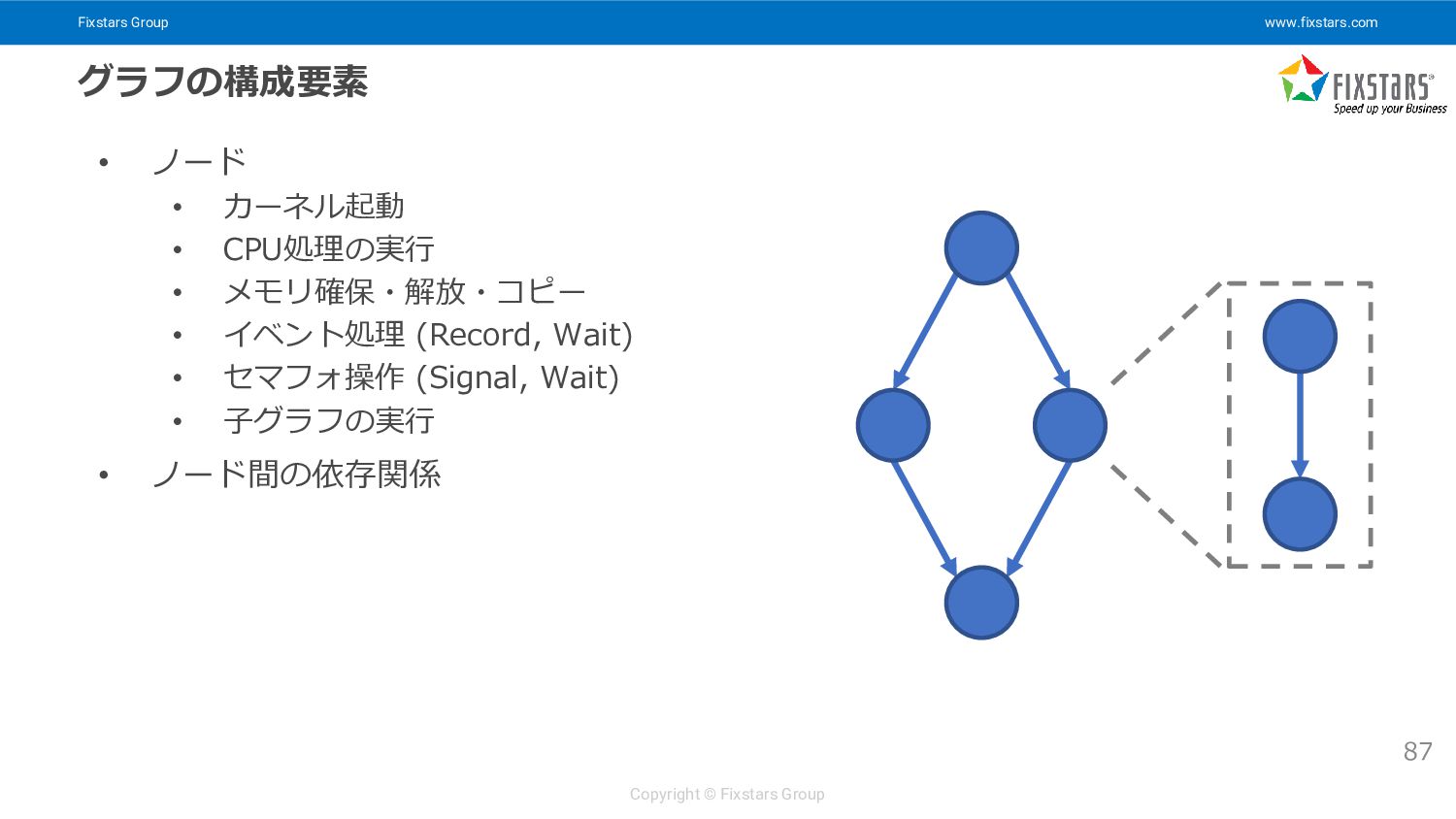{kind=link}
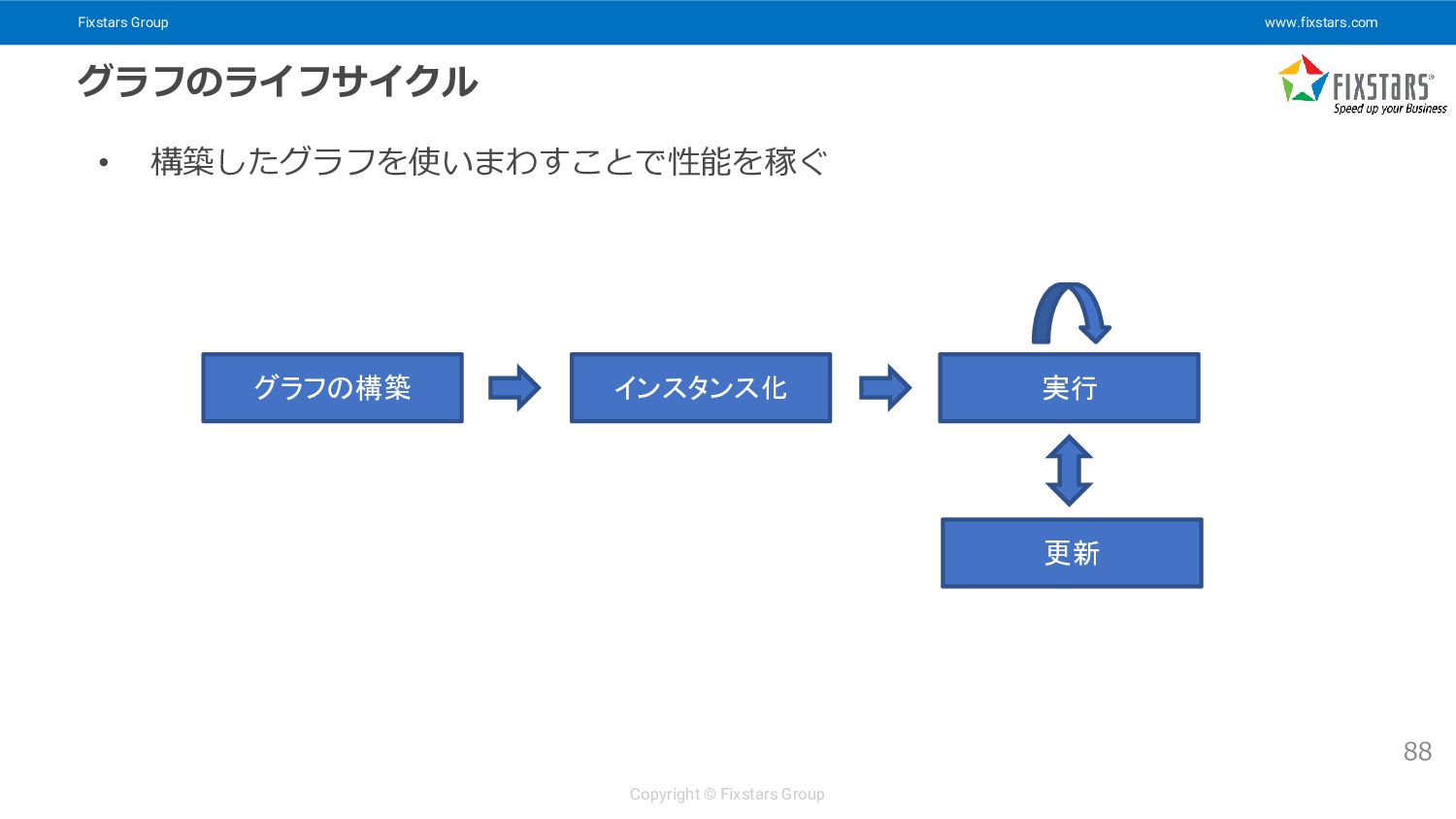{kind=link}
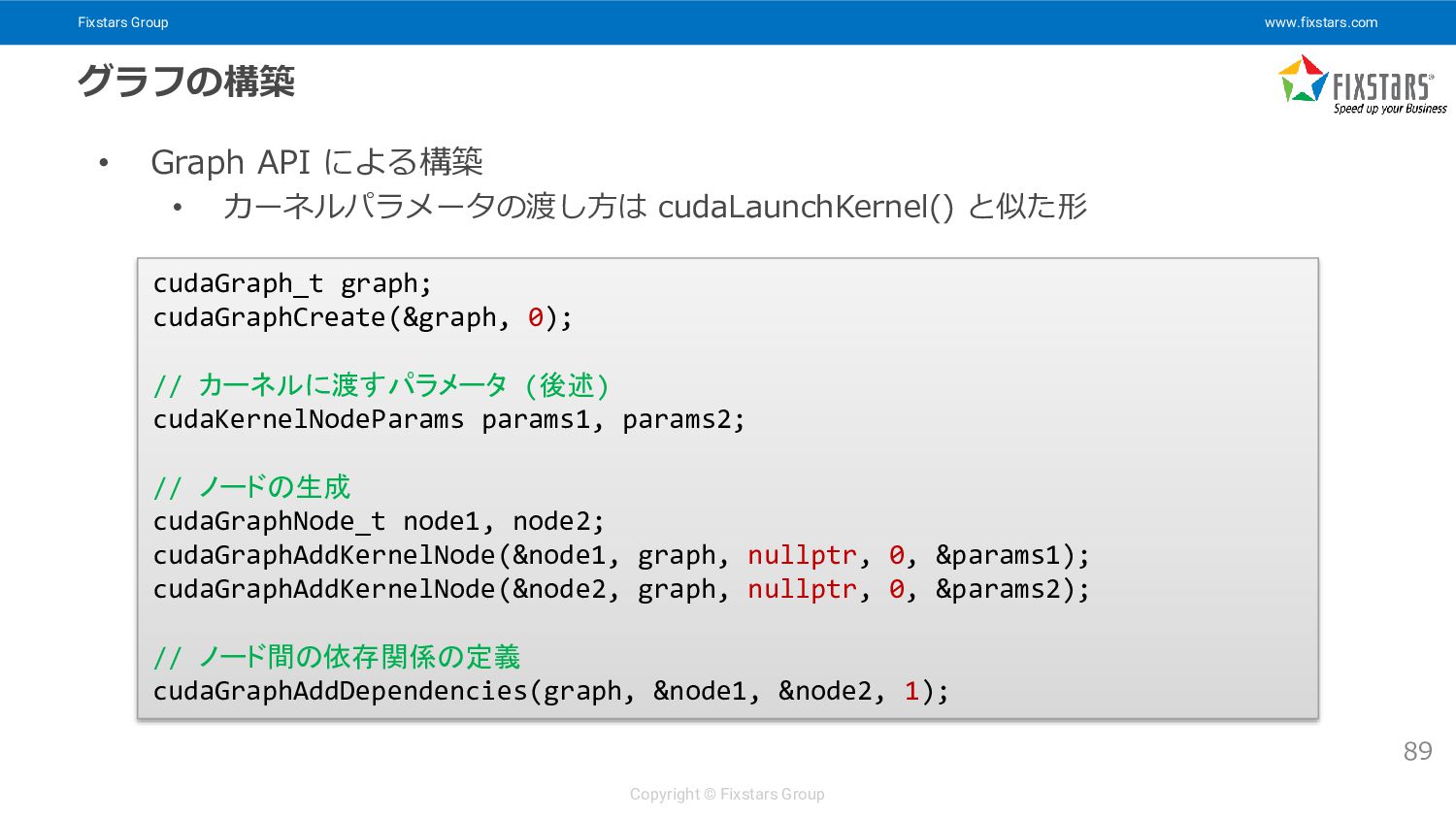{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
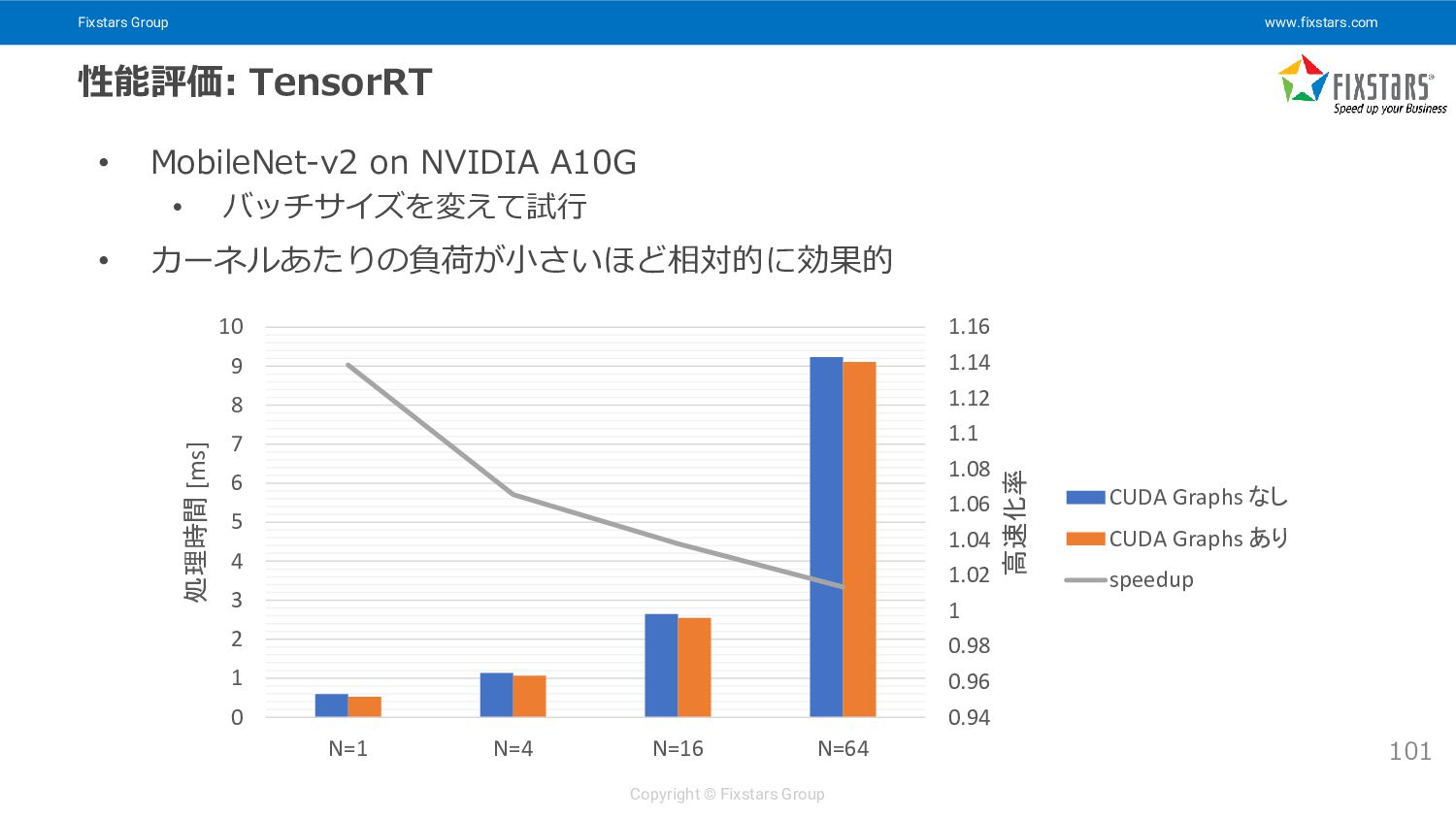{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}