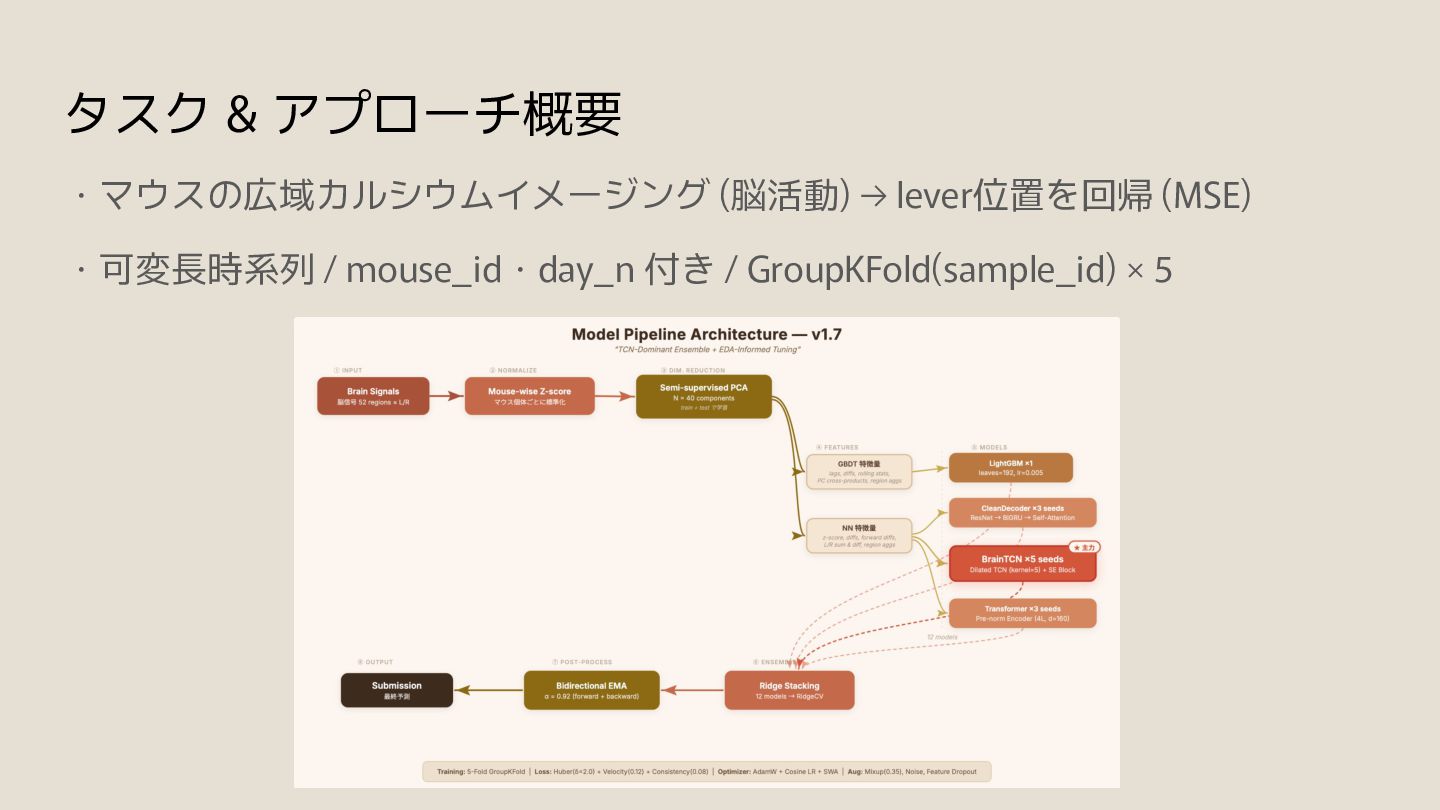
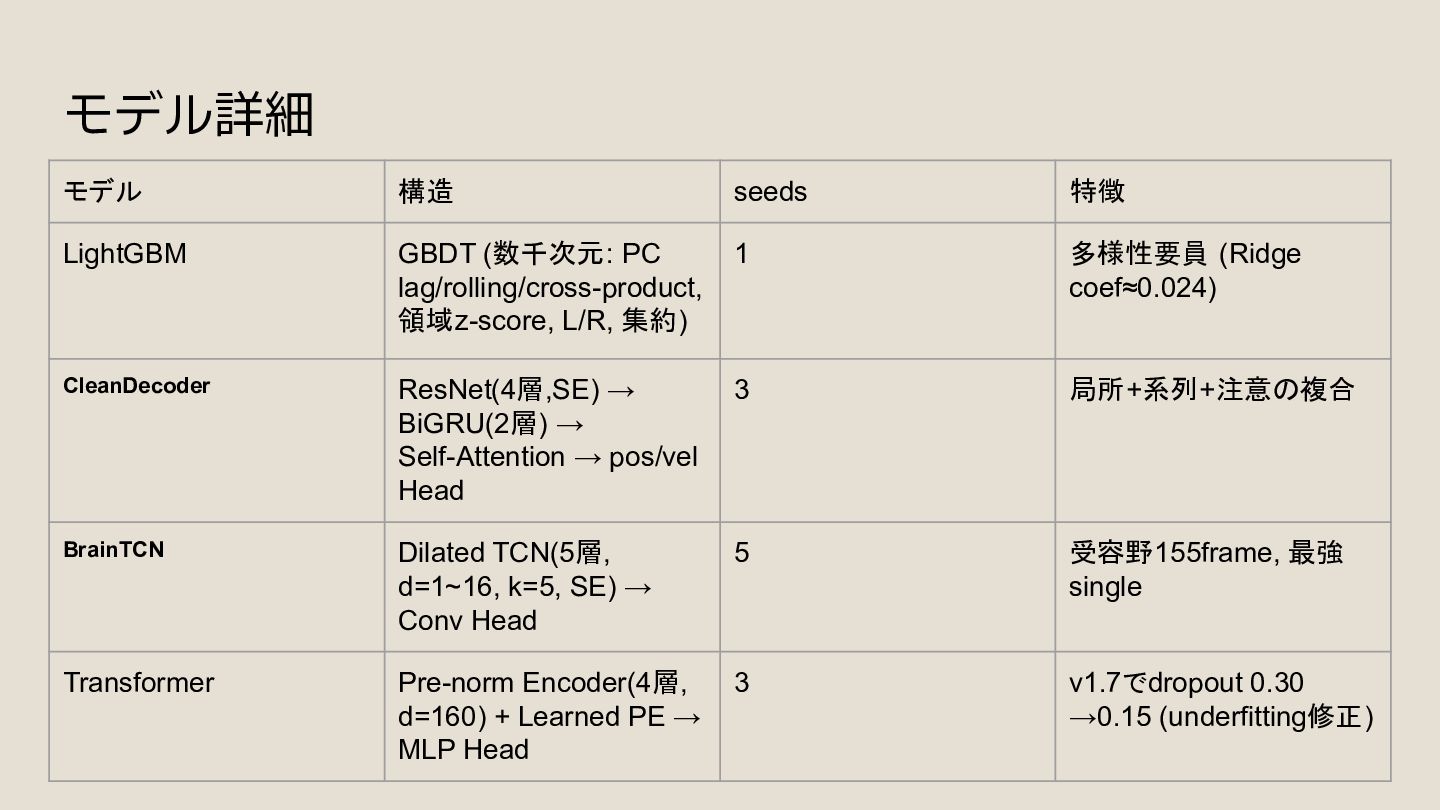
領域z-score, L/R, 集約) 1 多様性要員 (Ridge coef≈0.024) CleanDecoder ResNet(4層,SE) → BiGRU(2層) → Self-Attention → pos/vel Head 3 局所+系列+注意の複合 BrainTCN Dilated TCN(5層, d=1~16, k=5, SE) → Conv Head 5 受容野155frame, 最強 single Transformer Pre-norm Encoder(4層, d=160) + Learned PE → MLP Head 3 v1.7でdropout 0.30 →0.15 (underfitting修正)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
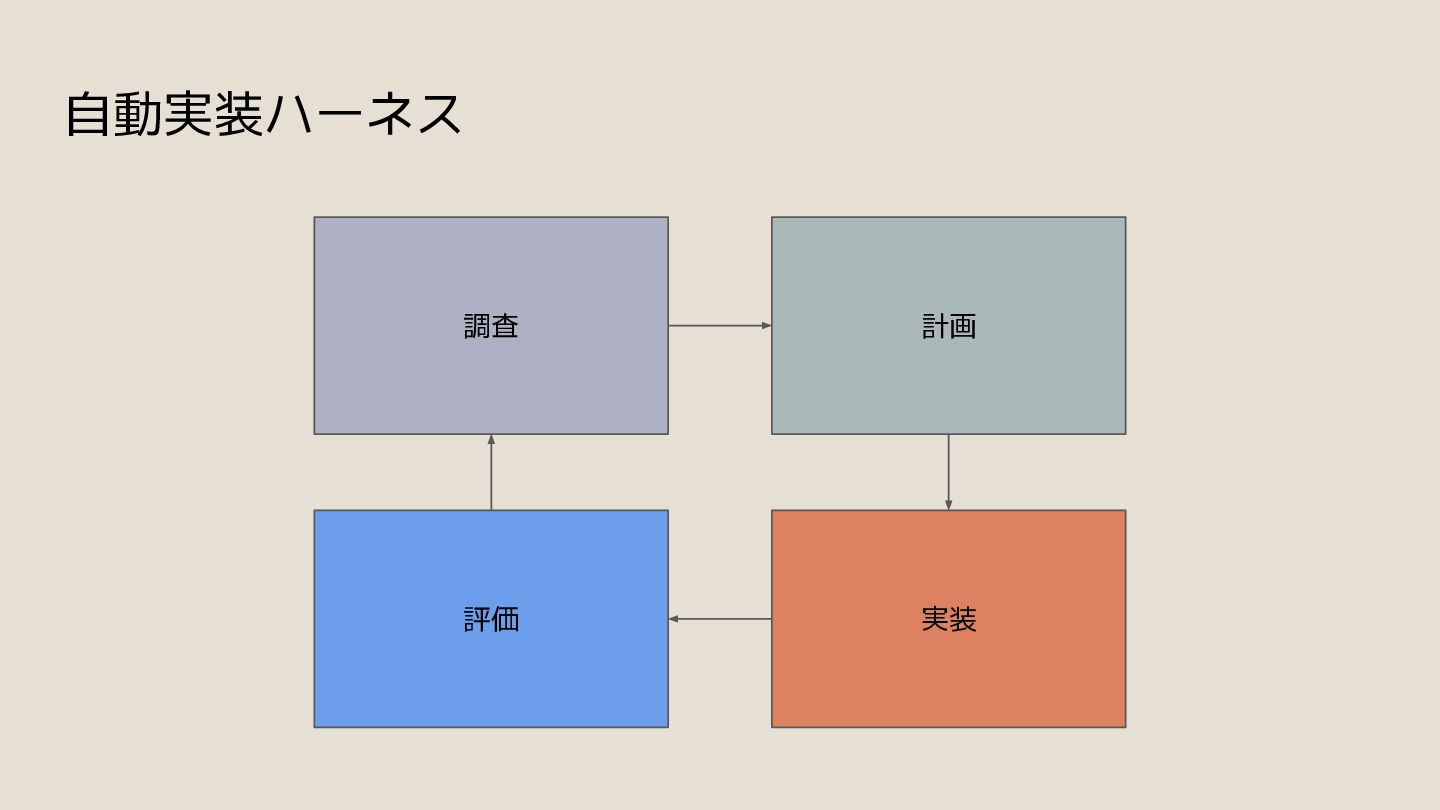{kind=link}
{kind=link}
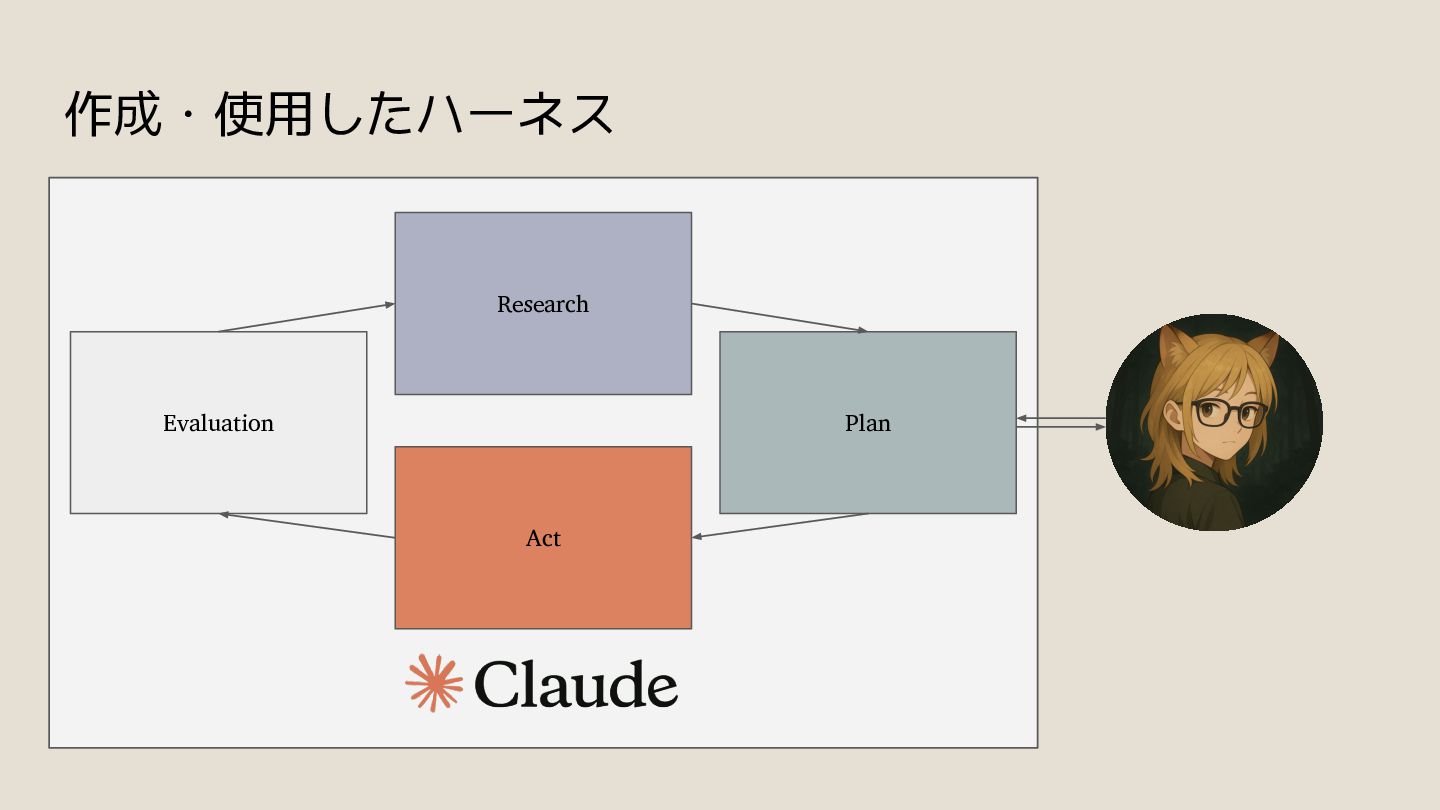{kind=link}
{kind=link}
{kind=link}
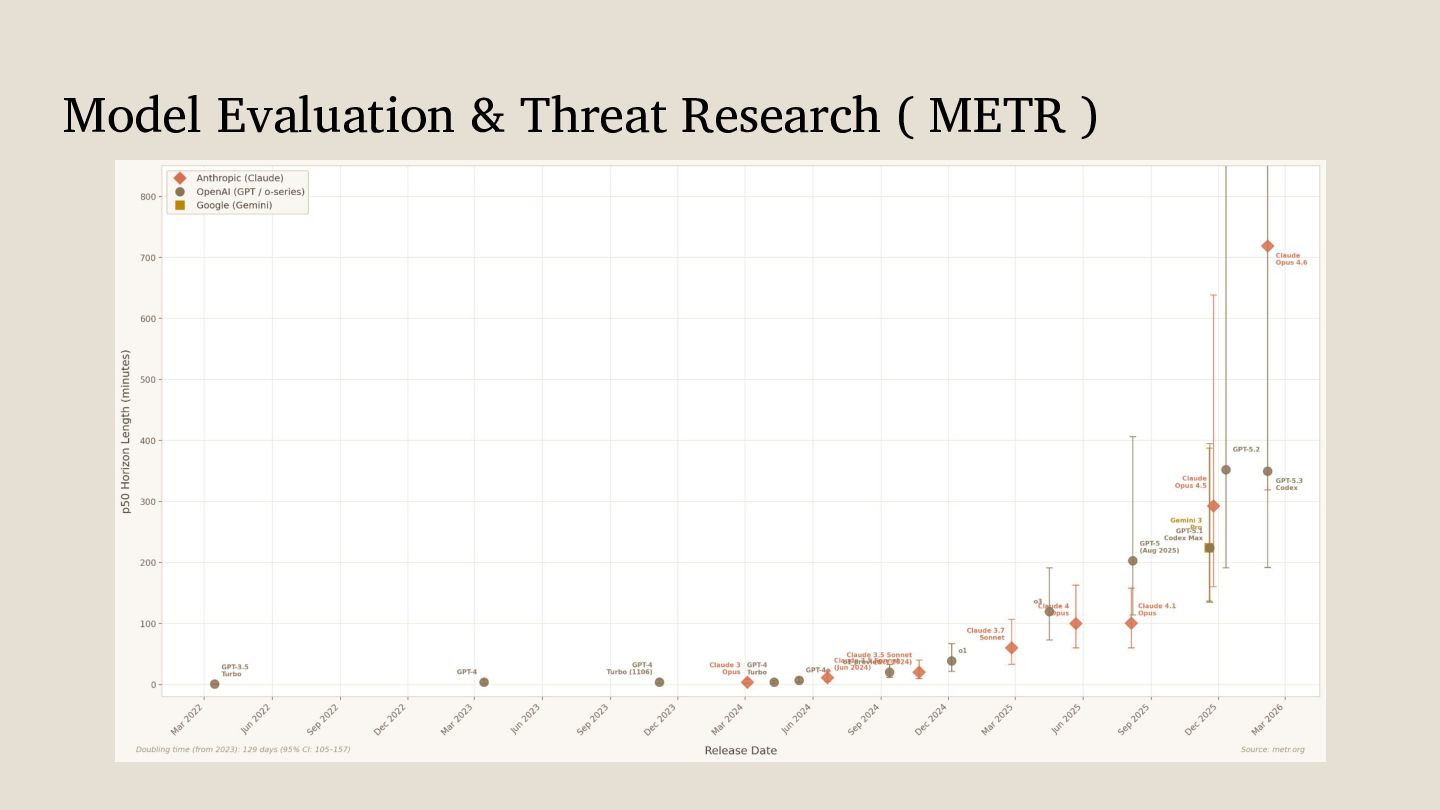{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}