promis) Viadeo en quelques chiffres Dis, c'était comment avant ? Mini zoom sur MySQL Replication Que choisir ? Le changement ? C'est... Zoom sur Master High Availability Quiz A retenir... (eh oui, ça fait déjà 1800 secondes)
@freshdaz http://dasini.net/blog/ Co-fondateur du MySQL User Group Francophone (LeMug.fr) • http://lemug.fr Co-auteur des livres Audit et optimisation – MySQL 5, Bonnes pratiques pour l’administrateur • Eyrolles, ISBN-13: 978-2212126341 MySQL 5 – Administration et optimisation • ENI, ISBN-13: 978-2-7460-5516-2 MySQL 5.6 – Administration et optimisation (février 2013)
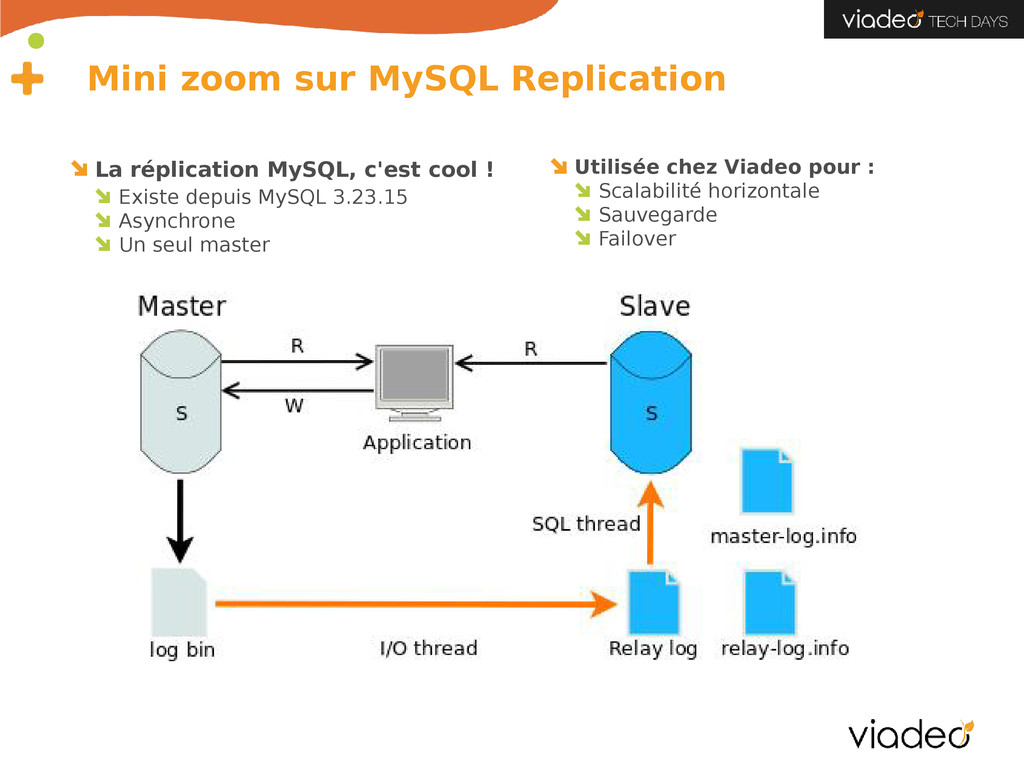
2 To de données Un certain nombre de « Grosses » tables • Jusqu'à 1 milliard d'enregistrements • Jusqu'à 350Go 23 serveurs en 5 shards qui se répartissent 20000 requêtes chaque seconde MySQL Replication sur chaque shard (1 master + N slaves) Plus des serveurs (slave) spécialisés (backup, besoin métier,...)
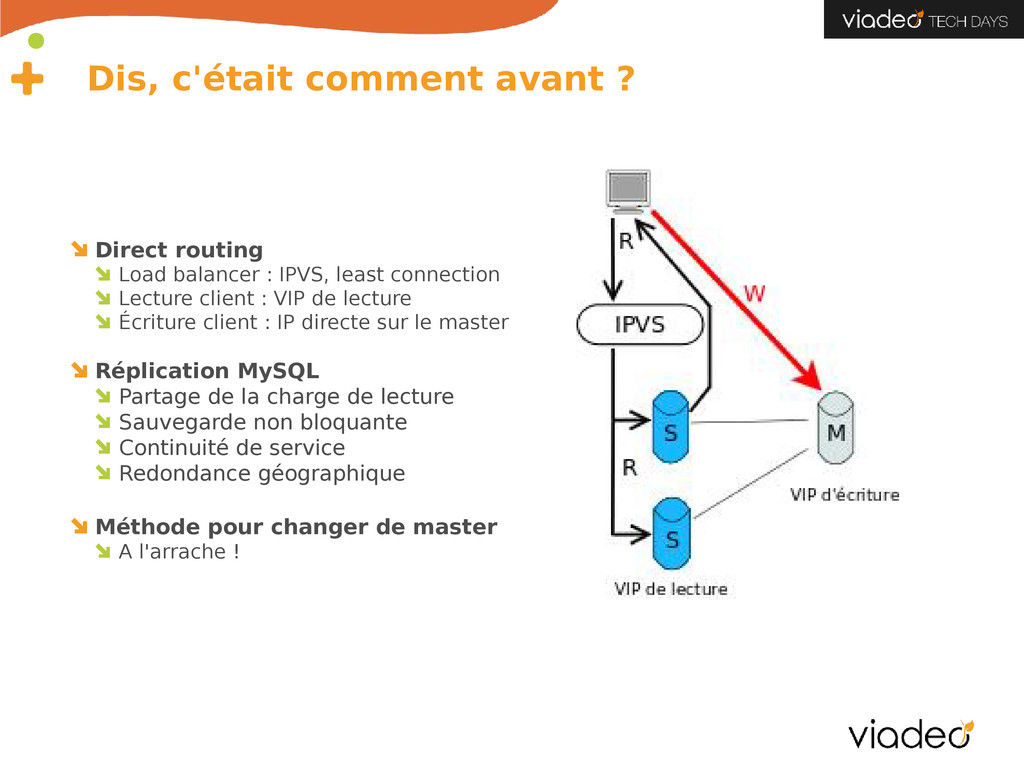
IPVS, least connection Lecture client : VIP de lecture Écriture client : IP directe sur le master Réplication MySQL Partage de la charge de lecture Sauvegarde non bloquante Continuité de service Redondance géographique Méthode pour changer de master A l'arrache !
L'architecture générale n'est pas vraiment problématique IPVS un peu « touchy » à configurer IPVS n'est pas la solution la plus souple Mais ce n'est clairement pas le problème Ce qui va moins bien La méthode de changement de master • Toute l'opération est manuelle • Demande de solides connaissance MySQL • Demande du sang froid (Dexter like) Les exceptions du workflow • Le problème des exceptions : « quand il y en a une ça va, c'est quand il y en a beaucoup qu'il y a des problèmes »
« spare » Risque d'incohérences entre le master & les slaves en cas de crash Risque d'incohérences entre les slaves en cas de crash Semi-Synchronous Replication MySQL 5.5+ Peut réduire les performances Risque d'incohérences entre le master & les slaves en cas de crash Risque d'incohérences entre les slaves en cas de crash Pacemaker + DRBD Durée du « crash recovery » Machines en « spare » MySQL Cluster Moteur de stockage NDB Global transaction ID MySQL 5.6+
si je t'écris aujourd'hui... une solution HA : Simple d'utilisation • Car à mon age on ne comprend plus les choses compliquées Facile à installer • Car à cause de Facebook je n'ai plus beaucoup de temps pour travailler Gratuite • Car j'aimerai avoir une augmentation ce coup ci ! Sans surcoût • Car mon chef est de toute façon un gros radin Qui fonctionne avec notre version de MySQL • Fatigué de corriger les bêtises de mes devs Qui ne m'oblige pas à changer d'architecture • Fatigué de corriger les bêtises de admins sys Performante • Je suis motard, j'aime quand ça va vite :) P.S. Cette année j'ai été sage... (lol)
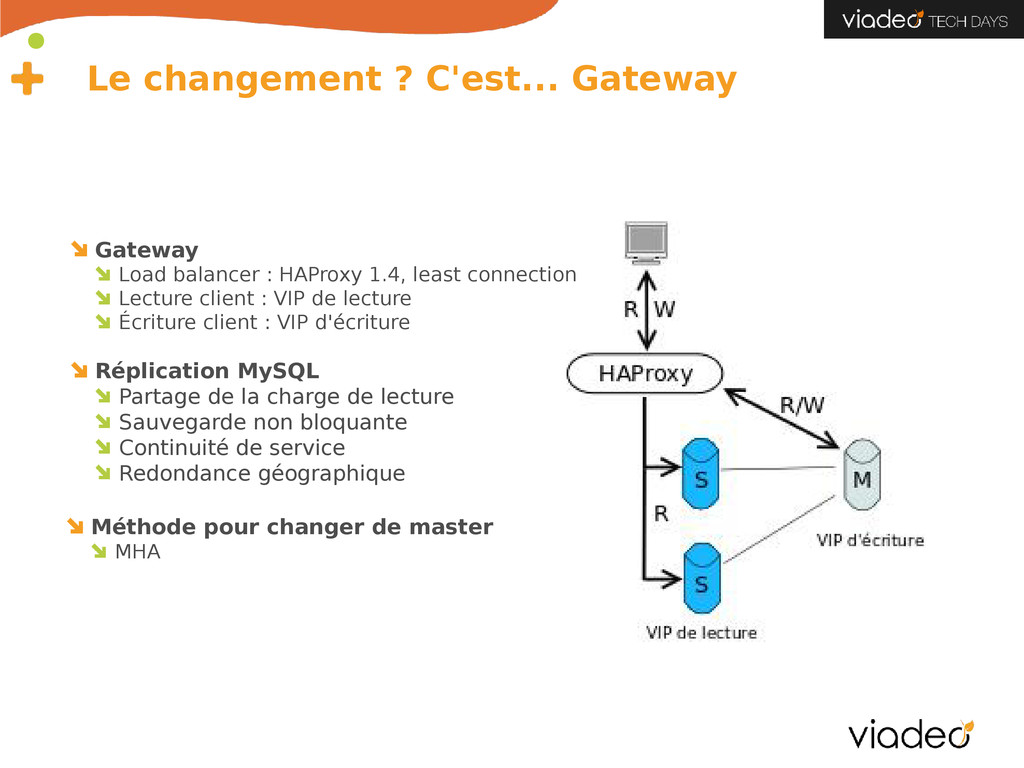
1.4, least connection Lecture client : VIP de lecture Écriture client : VIP d'écriture Réplication MySQL Partage de la charge de lecture Sauvegarde non bloquante Continuité de service Redondance géographique Méthode pour changer de master MHA
par HAProxy Test1 Service MySQL UP Serveur MySQL administrativement IN / OUT Serveur MySQL appartenant à la VIP d'écriture (Master) Test2 Service MySQL UP Serveur MySQL administrativement IN / OUT Serveur MySQL appartenant à la VIP de lecture (Slave)
Téléchargement de MHA http://code.google.com/p/mysql-master-ha/ .deb, rpm, tar.gz Buts de MHA Promouvoir un slave en master • Automatique : avec supervision du master (ping toutes les 3 secondes) • Manuel : c'est l'humain qui décide Reconfiguration automatique de la réplication • Les slaves pointent sur le nouveau master Minimiser la perte de données • Réduire les risques d'incohérences avec le master original • Rendre les slaves cohérents avec le nouveau master
Scripts PERL MySQL 5.0+ Indépendant du moteur de stockage Ne nécessite pas de changement d'architecture Pas de coûts supplémentaires (ou presque) Le manager à une faible empreinte Installé sur une machine virtuelle à Viadeo Performant Jusqu'à présent, la bascule n'a jamais dépassée 2 secondes Compatible avec la réplication asynchrone
doc ! http://code.google.com/p/mysql-master-ha/wiki/TableOfContents Sur le Manager node (MHA manager) : masterha_master_switch : basculement manuel masterha_manager : supervision du master & basculement auto en cas de crash Sur les slaves (MHA node) : save_binary_logs apply_diff_relay_logs purge_relay_logs • relay_log_purge = 0 dans my.cnf (nécessaire pour restaures les autres slaves) MHA effectue différentes vérifications en amont : Vérification de la connexion SSH Vérification de la réplication ... Scripts optionnels master_ip_online_change_script : script externe lancé lors de la bascule manuelle ...
Failover & bascule online • masterha_master_switch conf=/etc/mha/app1.conf master_state=alive • Tout les serveurs doivent être UP • Pas de retards de réplications • MHA n’éteint pas le master original lors du basculement • Pas de logs binaire à restaurer (MASTER_POS_WAIT()) En cas de crash du master • masterha_master_switch conf=/etc/mha/app1.conf master_state=dead dead_master_host=<FQDN>
de la bascule manuelle MHA propose une coque pré-remplie. Il faut finir le travail ! (Merci Xavier) $ less master_ip_online_change_script Objectif cohérence des données sub main { if ( $command eq "stop" ) { ## Gracefully killing connections on the current master # 1. Set read_only= 1 on the new master # 2. DROP USER so that no app user can establish new connections # 3. Set read_only= 1 on the current master # 4. Kill current queries # * Any database access failure will result in script die. + FLUSH TABLES WITH READ LOCK Mais ...
important (pour moi) MHA fait le nécessaire pour récupérer un maximum de données Cohérence du nouveau master avec le master original • Récupération des logs binaires du master si possible Cohérence des slaves avec le nouveau master • Rattrapage de l'éventuel retard des slaves
mets à jour les slaves puis en promeus un en master avec MHA b) Je l'exécute sur le master, en buvant un planteur de la Martinique c) J'utilise pt-online-schema-change
me sers un p'tit rhum agricole de la Guadeloupe b) J’attends que le besoin disparaisse c) Je mets à jour les slaves puis en promeus un en master avec MHA
master Assures la cohérences des slaves entre eux Reconfigure automatiquement la réplication Minimise l’arrêt (ou la dégradation) de service Simple • A utiliser • A comprendre • A installer Pas de changement • d'architectures • de moteurs de stockage (Idéal avec InnoDB) • de logiques métier Performant • Quelques secondes de downtime (moins de 2) Fonctionne à partir des version supérieures à MySQL 5.0.45 Open source
Sabri et son équipe Xavier Yorick ... Et toutes les « petites mains » Aux conférienciers Loïc Dias Da Silva Olivier Hory & Frédéric Perrin Amélie Boucher & Julien Hilion Pierre Killy Xavier Krantz Emanuele Pecorari François Le Lay Nicolas Tricot Damien Hardy Olivier Dasini A toi public Keynote Arnaud Devigne Jean-Marc Potdevin Stefan Fountain
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}