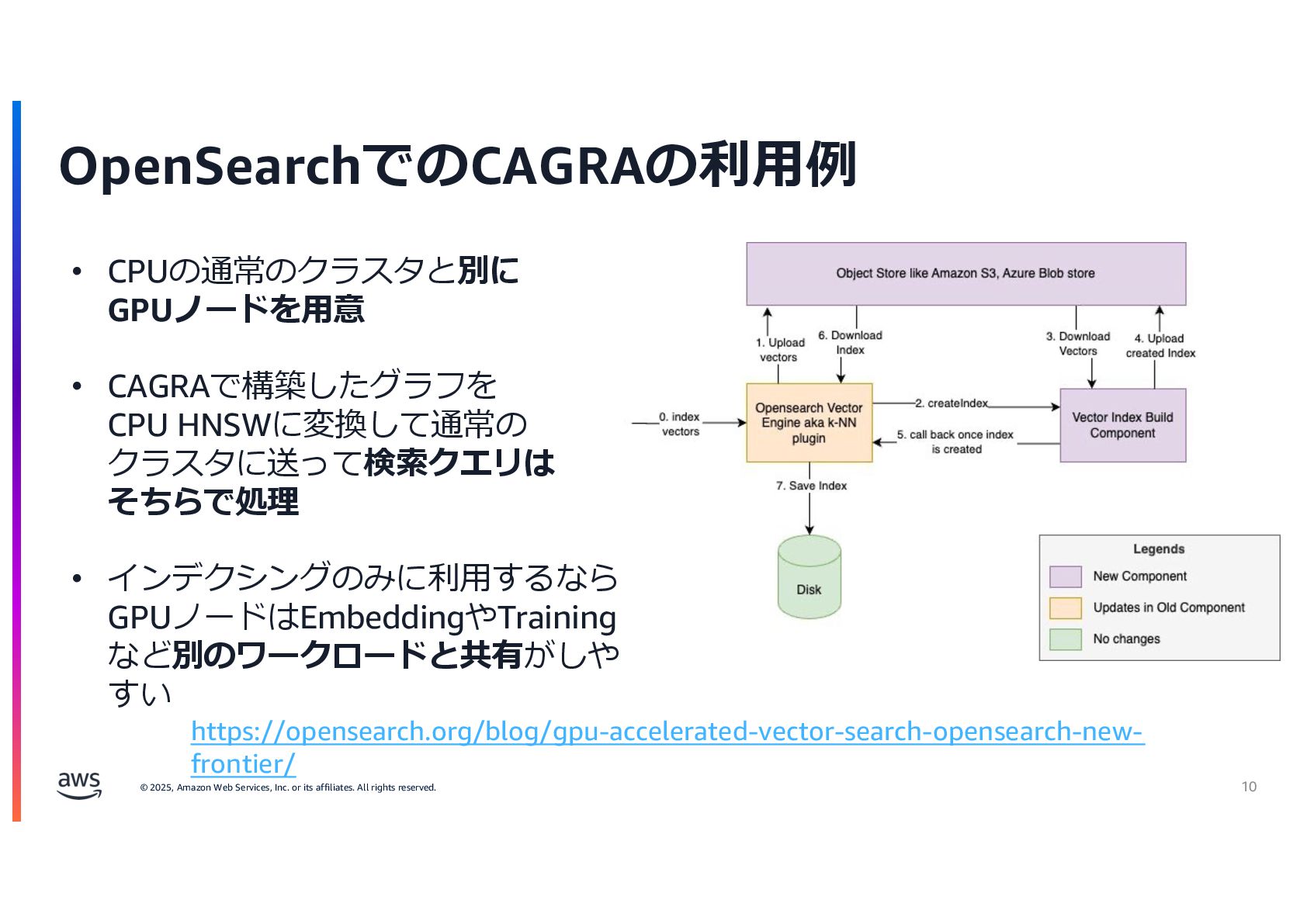
rights reserved. 2 Name︓ 深⾒修平(Shuhei Fukami) Title︓ Analytics Specialist Solutions Architect OpenSearch Tokyo User Group Co-Organizer ⾃⼰紹介 ご興味あればぜひご参加ください︕ OpenSearch Con NorthAmerica 2025 https://youtu.be/uCbc7iFM3RE?si=9VMyPnELLS7D9m36 OpenSearch x Icebergの話
{kind=link}
{kind=link}
{kind=link}
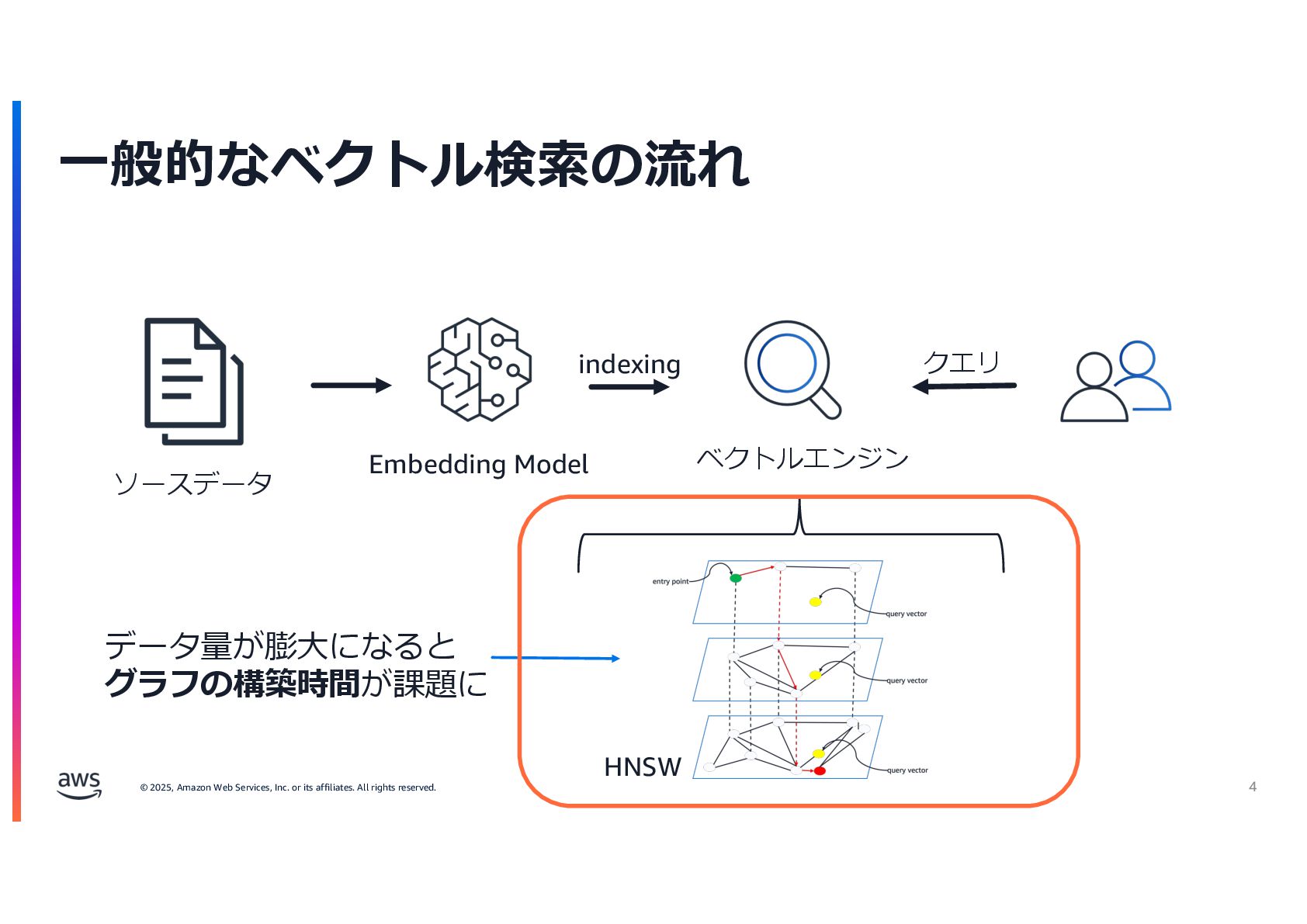{kind=link}
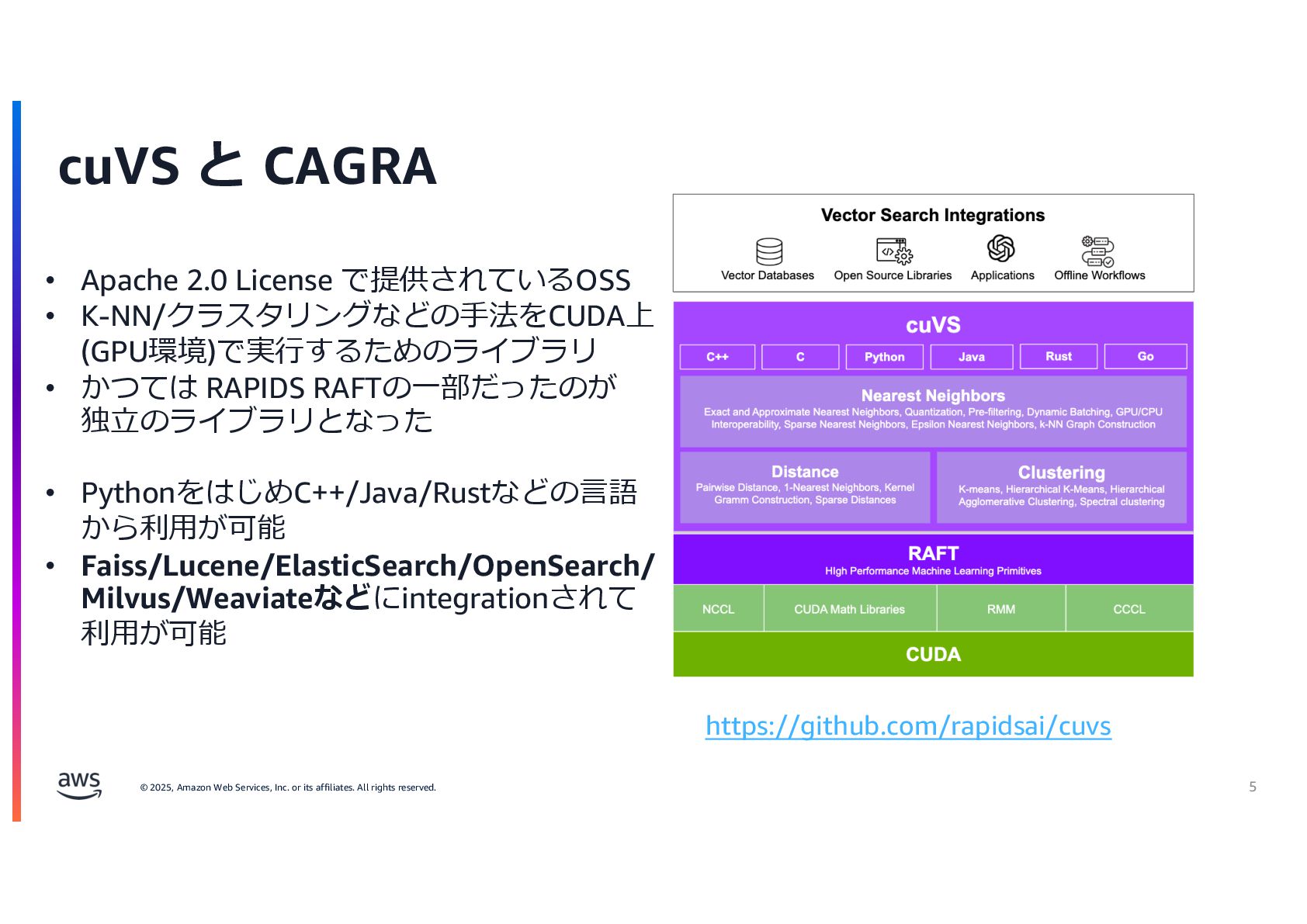{kind=link}
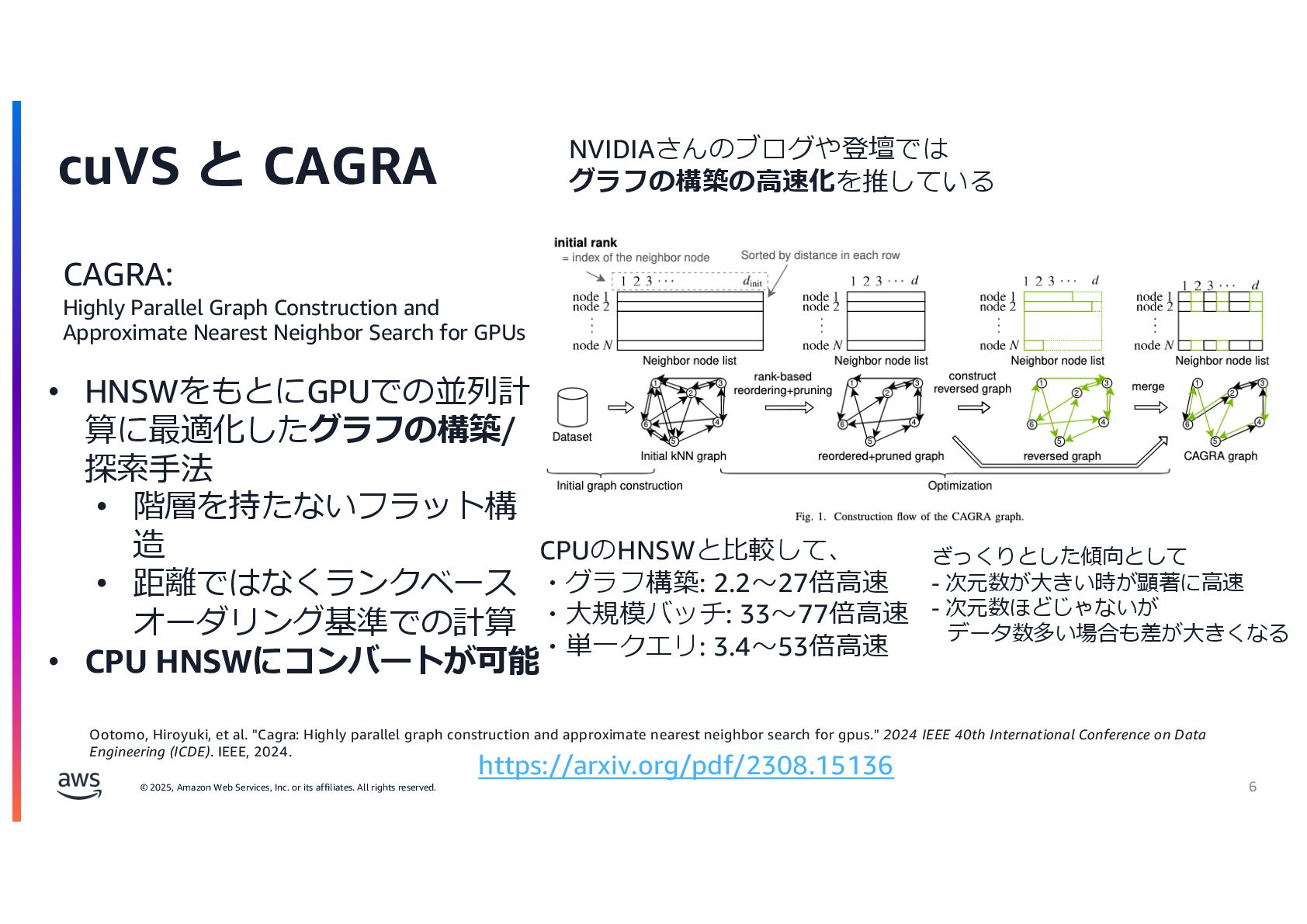{kind=link}
{kind=link}
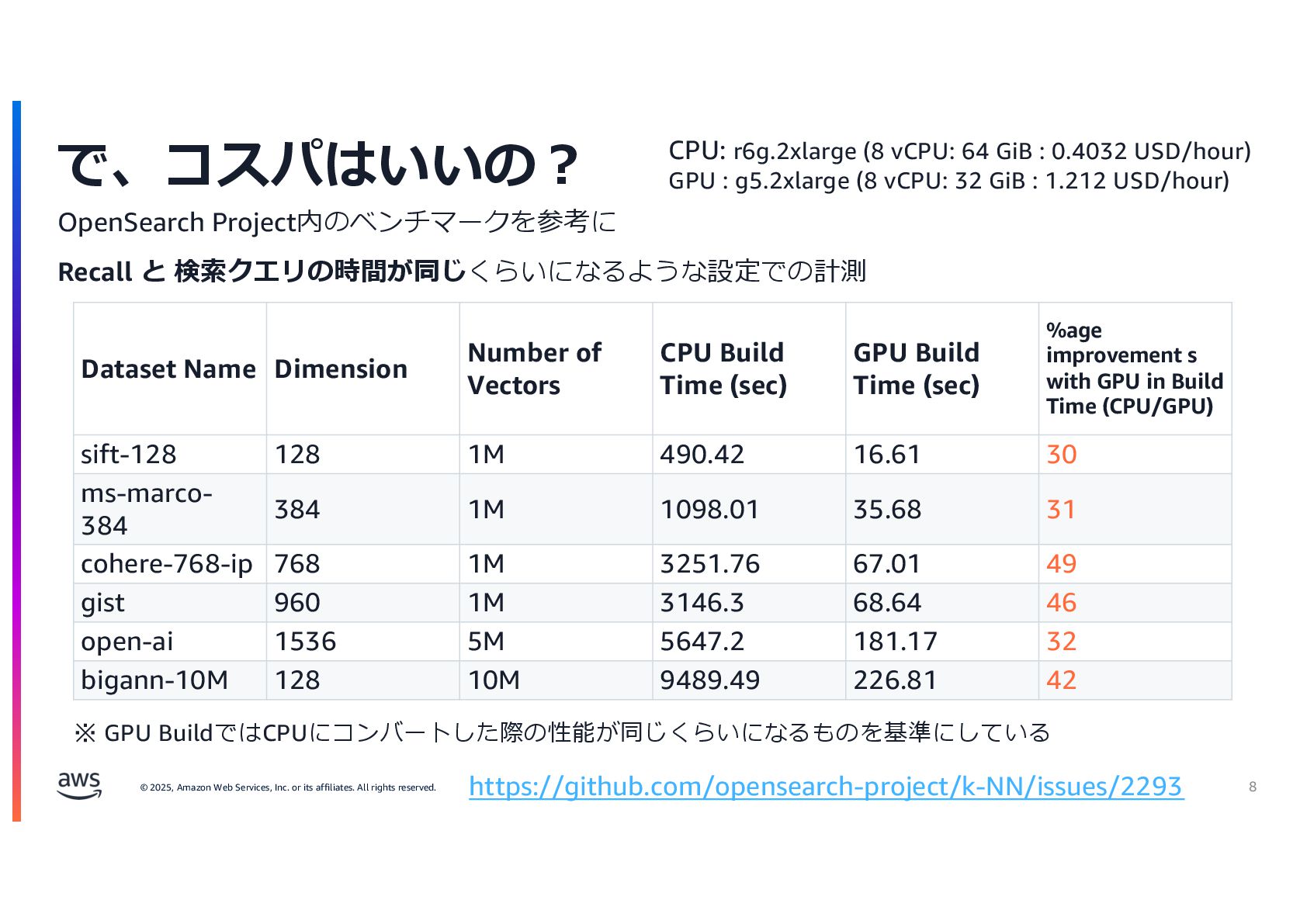{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}