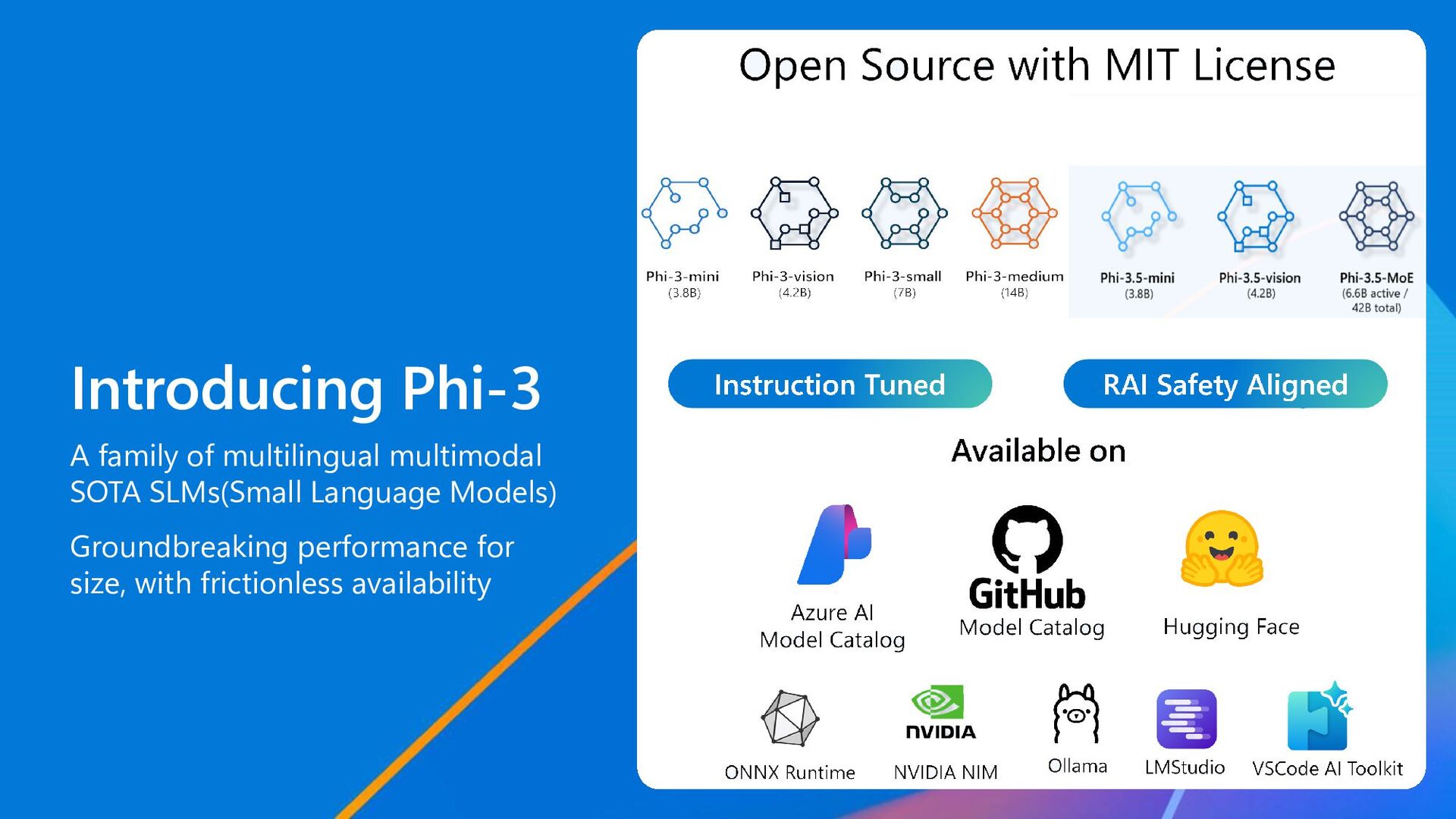
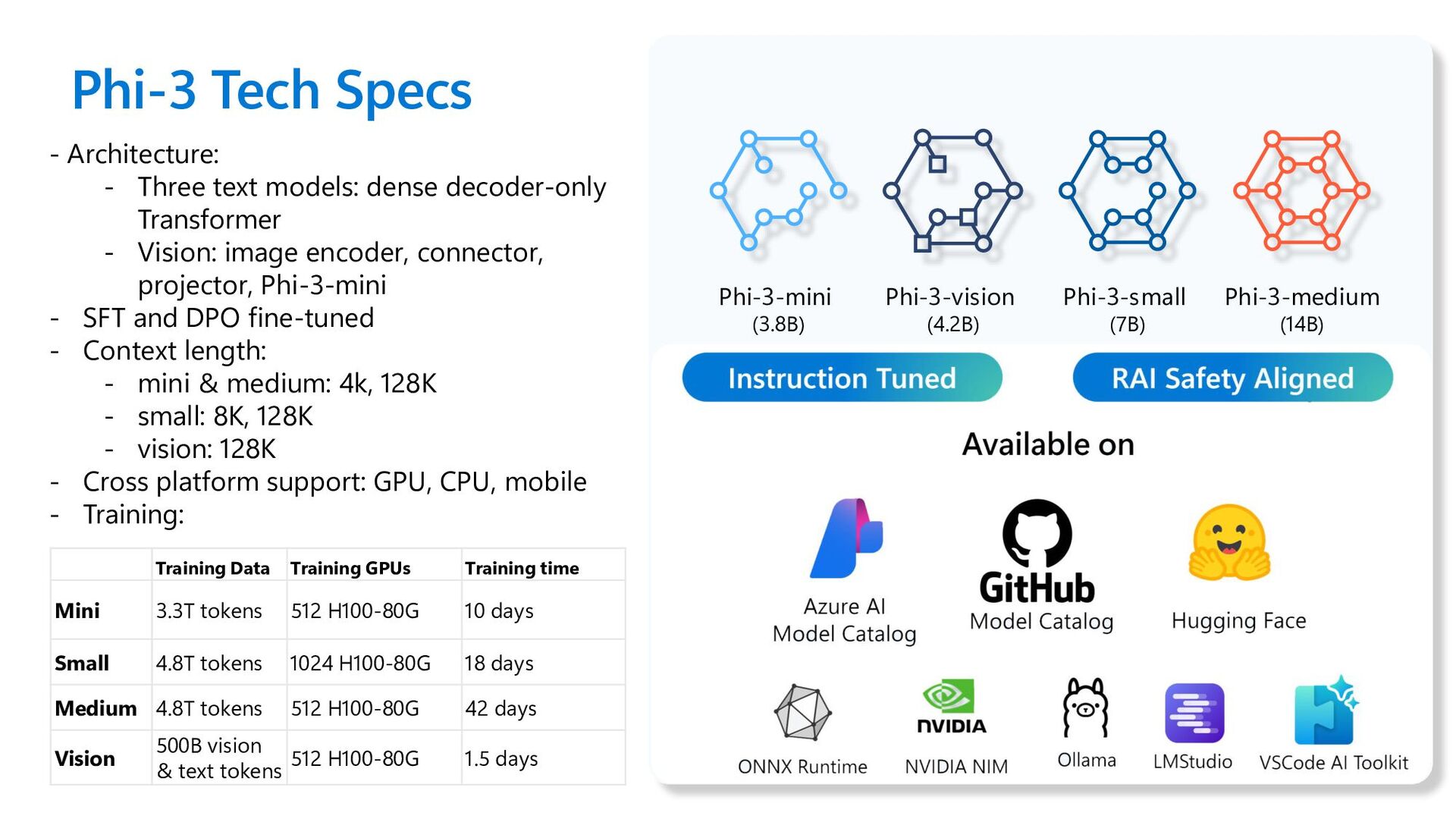
Vision: image encoder, connector, projector, Phi-3-mini - SFT and DPO fine-tuned - Context length: - mini & medium: 4k, 128K - small: 8K, 128K - vision: 128K - Cross platform support: GPU, CPU, mobile - Training: Phi-3-mini (3.8B) Phi-3-vision (4.2B) Phi-3-small (7B) Phi-3-medium (14B) Available on Azure AI Model Catalog Hugging Face Ollama NVIDIA NIM ONNX Runtime Training Data Training GPUs Training time Mini 3.3T tokens 512 H100-80G 10 days Small 4.8T tokens 1024 H100-80G 18 days Medium 4.8T tokens 512 H100-80G 42 days Vision 500B vision & text tokens 512 H100-80G 1.5 days Phi-3 Tech Specs
- Vision: image encoder, connector, projector, Phi-3.5-mini - MoE: mixture-of-expert decoder-only Transformer (16x3.8B with 6.6B active parameters when using 2 expert) - SFT and DPO fine-tuned - Context length: 128K - Cross platform support: GPU, CPU, mobile - Training: Available on Azure AI Model Catalog Hugging Face Ollama NVIDIA NIM ONNX Runtime Phi-3.5-mini (3.8B) Phi-3.5-vision (4.2B) Phi-3.5-MoE (6.6B active) Training Data Training GPUs Training time Mini 3.3T tokens 512 H100-80G 10 days Vision 500B vision & text tokens 256 A100-80G 6 days MoE 4.9T tokens 512 H100-80G 23 days
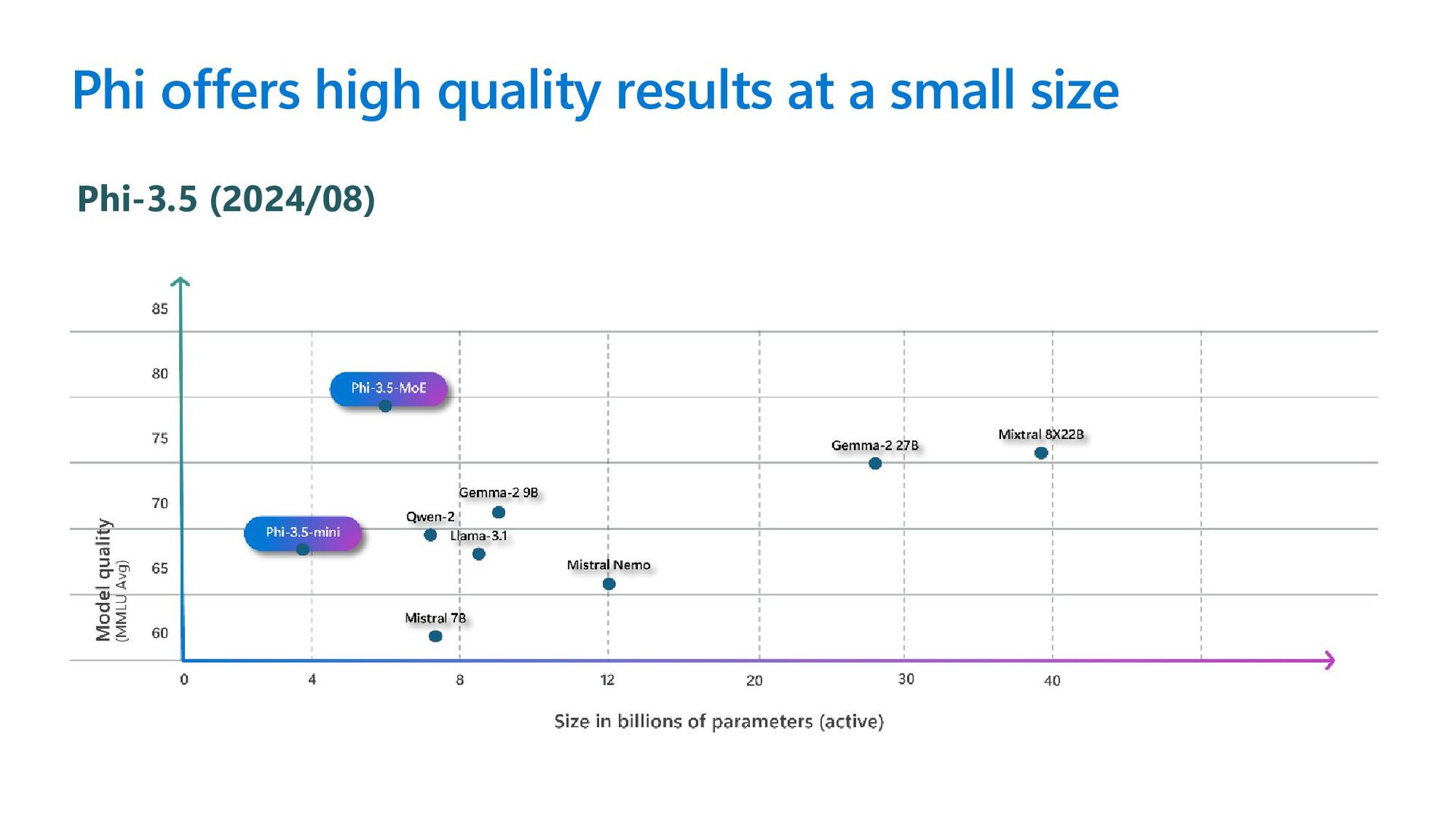
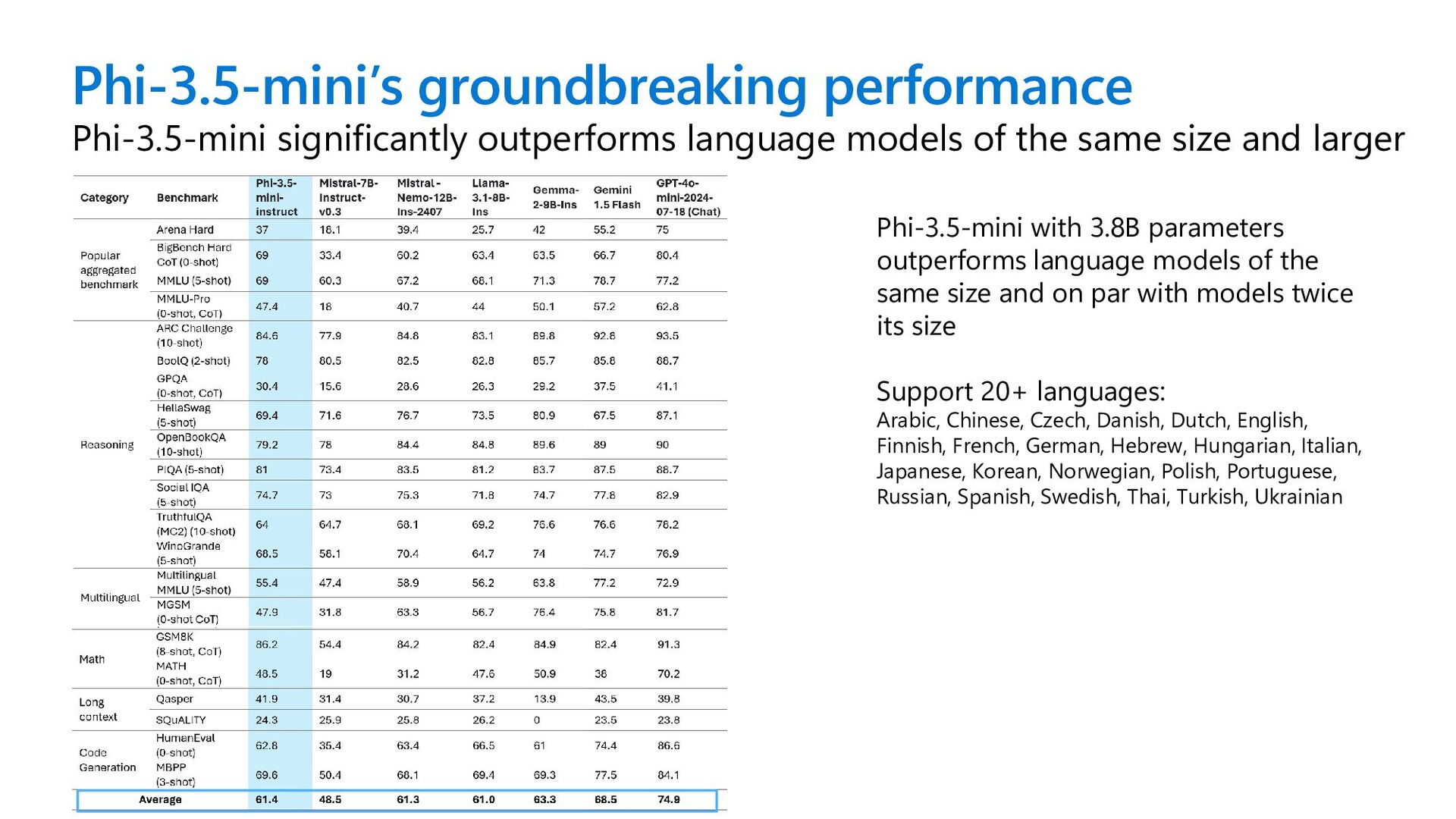
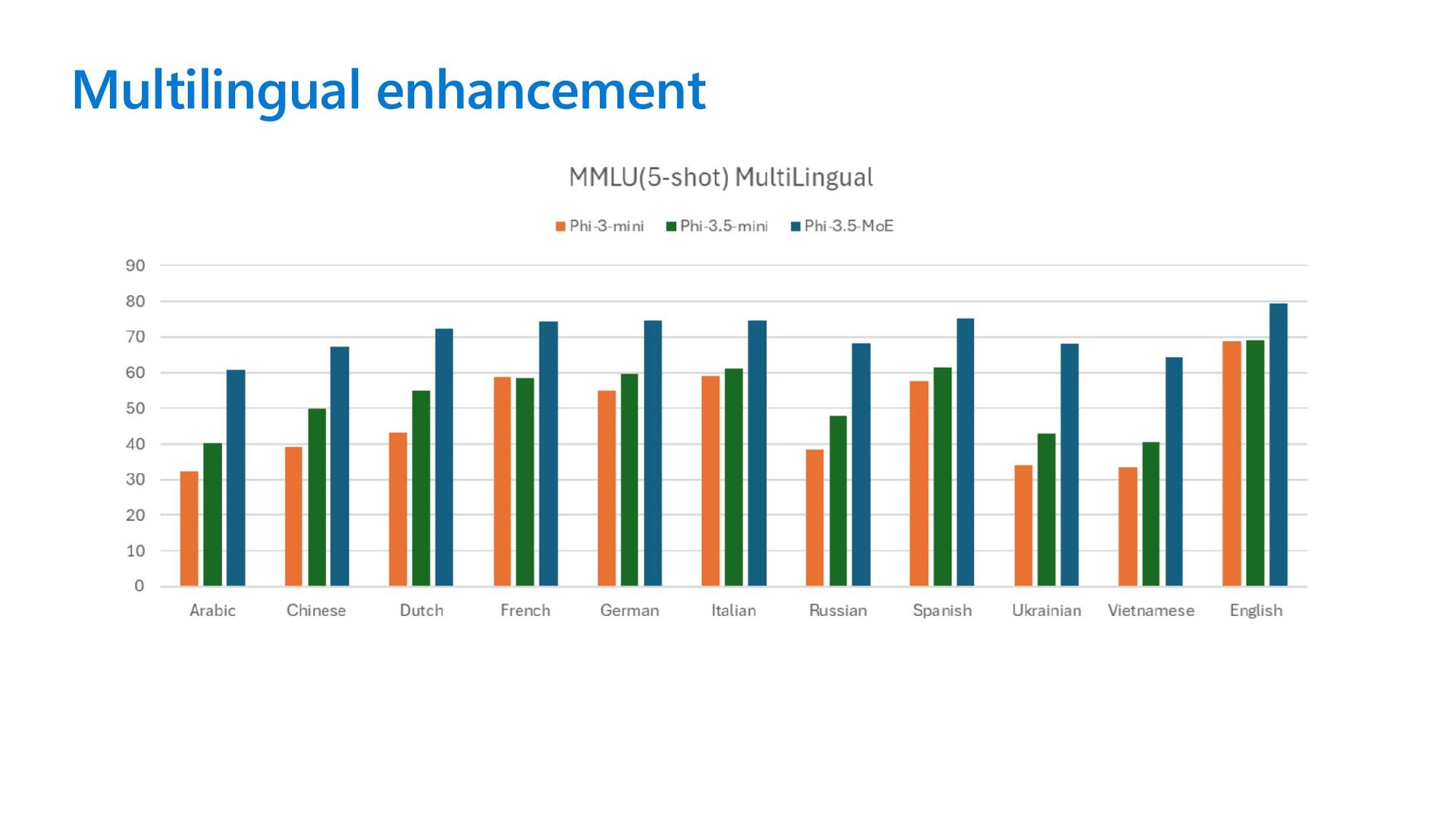
same size and larger Phi-3.5-mini with 3.8B parameters outperforms language models of the same size and on par with models twice its size Support 20+ languages: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
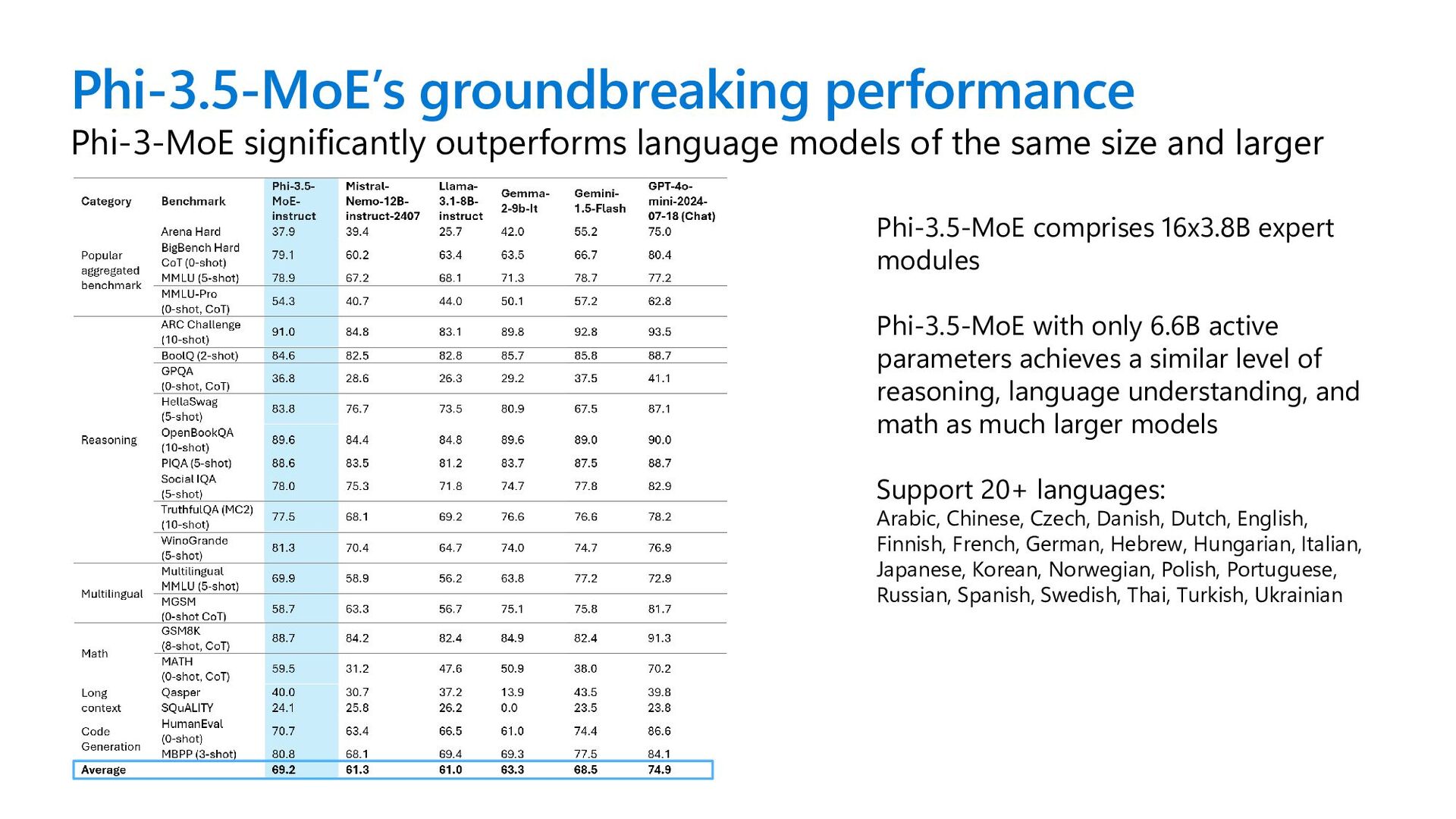
same size and larger Phi-3.5-MoE comprises 16x3.8B expert modules Phi-3.5-MoE with only 6.6B active parameters achieves a similar level of reasoning, language understanding, and math as much larger models Support 20+ languages: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
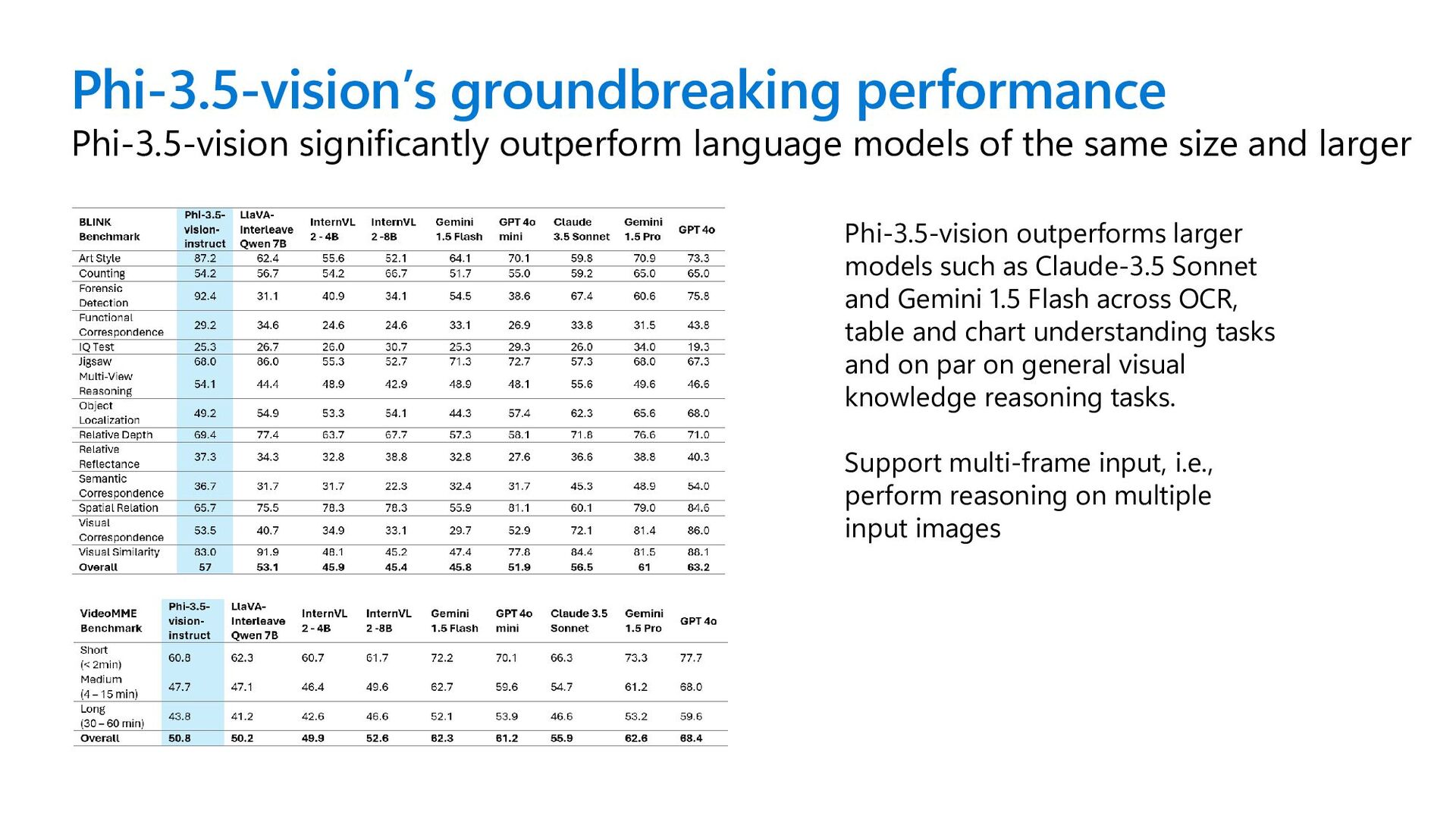
same size and larger Phi-3.5-vision outperforms larger models such as Claude-3.5 Sonnet and Gemini 1.5 Flash across OCR, table and chart understanding tasks and on par on general visual knowledge reasoning tasks. Support multi-frame input, i.e., perform reasoning on multiple input images
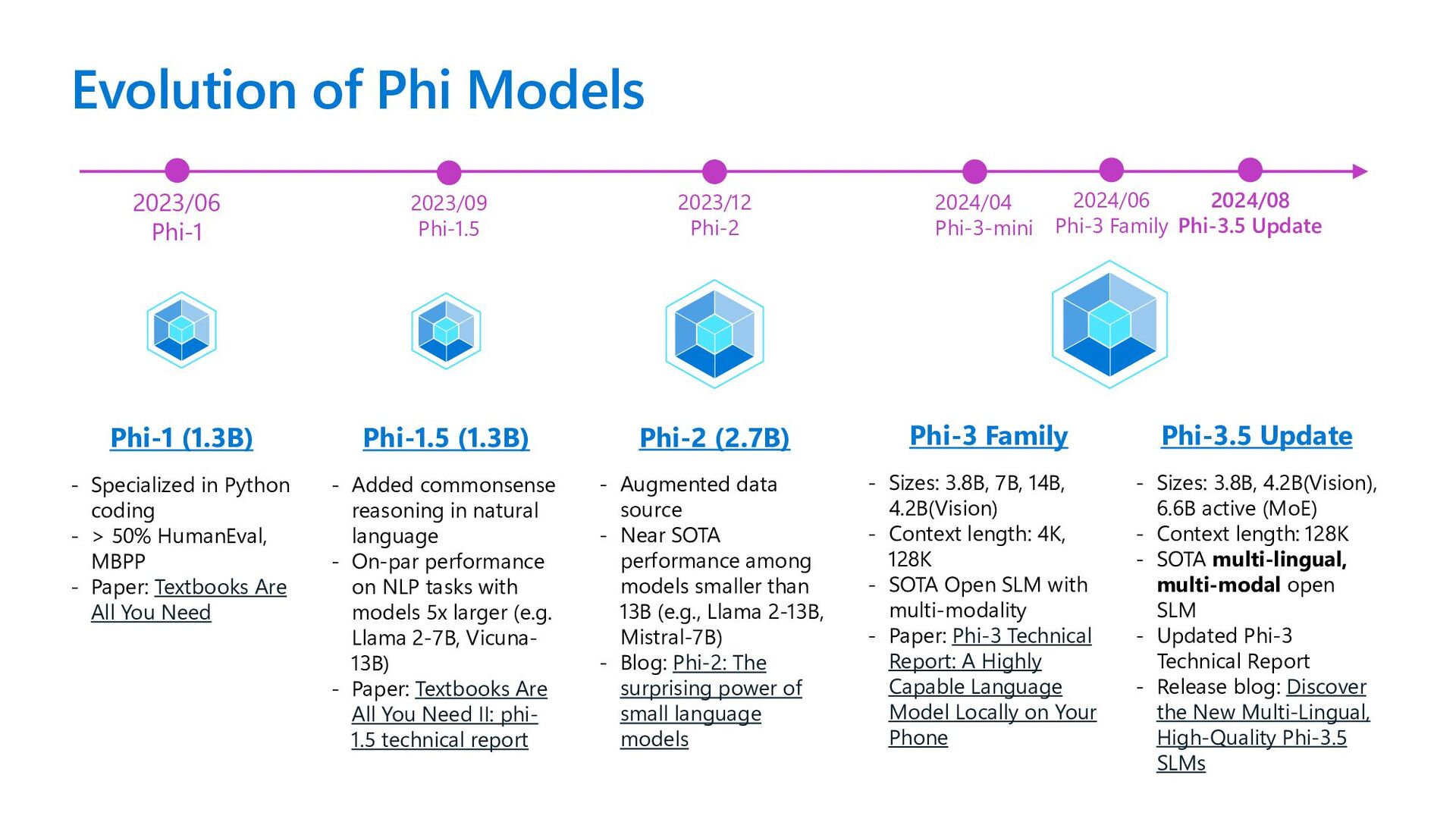
coding - > 50% HumanEval, MBPP - Paper: Textbooks Are All You Need Phi-1.5 (1.3B) - Added commonsense reasoning in natural language - On-par performance on NLP tasks with models 5x larger (e.g. Llama 2-7B, Vicuna- 13B) - Paper: Textbooks Are All You Need II: phi- 1.5 technical report Phi-2 (2.7B) - Augmented data source - Near SOTA performance among models smaller than 13B (e.g., Llama 2-13B, Mistral-7B) - Blog: Phi-2: The surprising power of small language models Phi-3 Family - Sizes: 3.8B, 7B, 14B, 4.2B(Vision) - Context length: 4K, 128K - SOTA Open SLM with multi-modality - Paper: Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone 2023/09 Phi-1.5 2023/06 Phi-1 2024/04 Phi-3-mini 2023/12 Phi-2 2024/06 Phi-3 Family Phi-3.5 Update - Sizes: 3.8B, 4.2B(Vision), 6.6B active (MoE) - Context length: 128K - SOTA multi-lingual, multi-modal open SLM - Updated Phi-3 Technical Report - Release blog: Discover the New Multi-Lingual, High-Quality Phi-3.5 SLMs 2024/08 Phi-3.5 Update
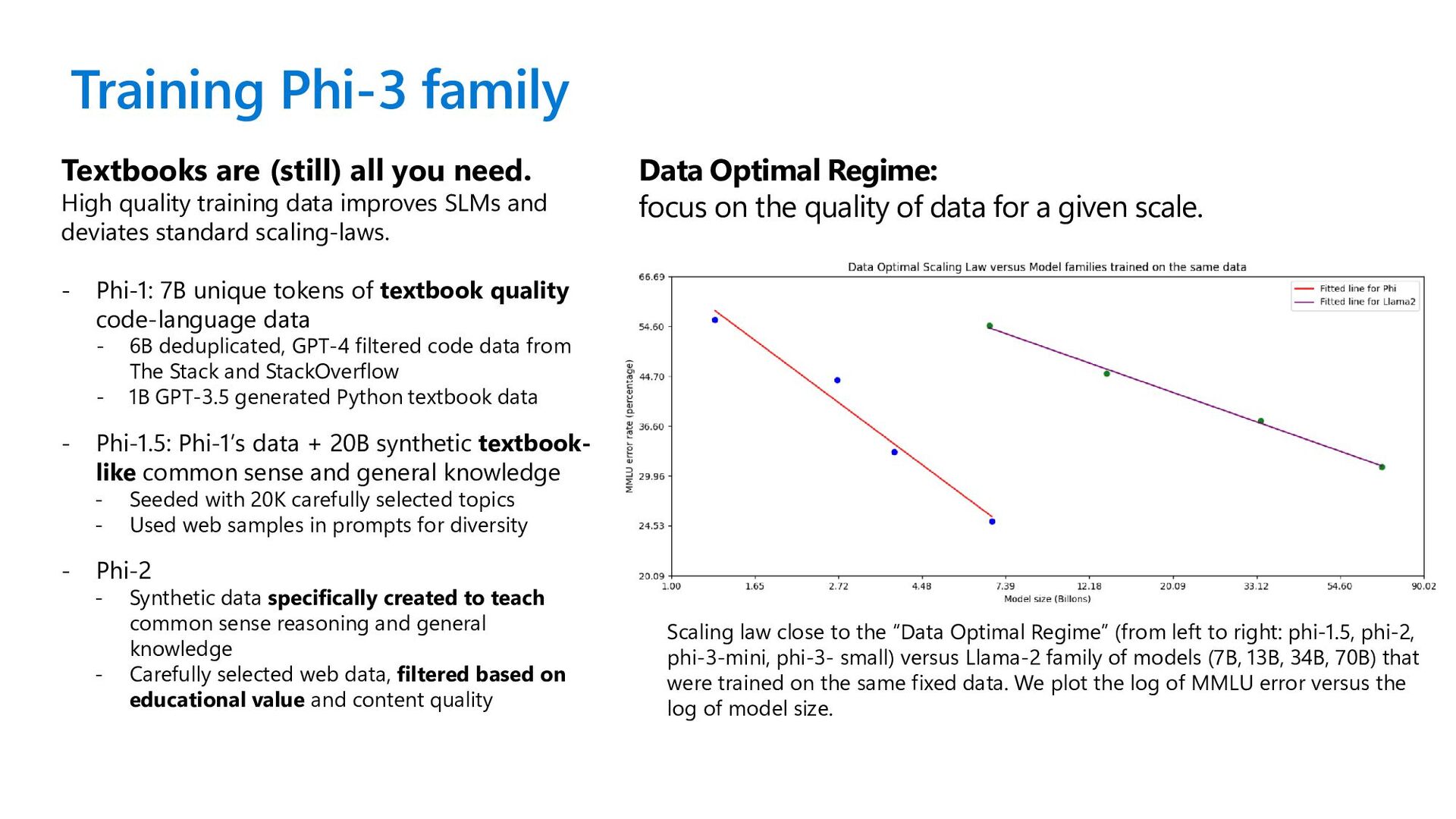
Regime” (from left to right: phi-1.5, phi-2, phi-3-mini, phi-3- small) versus Llama-2 family of models (7B, 13B, 34B, 70B) that were trained on the same fixed data. We plot the log of MMLU error versus the log of model size. Textbooks are (still) all you need. High quality training data improves SLMs and deviates standard scaling-laws. - Phi-1: 7B unique tokens of textbook quality code-language data - 6B deduplicated, GPT-4 filtered code data from The Stack and StackOverflow - 1B GPT-3.5 generated Python textbook data - Phi-1.5: Phi-1’s data + 20B synthetic textbook- like common sense and general knowledge - Seeded with 20K carefully selected topics - Used web samples in prompts for diversity - Phi-2 - Synthetic data specifically created to teach common sense reasoning and general knowledge - Carefully selected web data, filtered based on educational value and content quality Data Optimal Regime: focus on the quality of data for a given scale.
data according to educational level - Synthetic LLM generated data Two-phase pre-training - Phase 1: General Knowledge & Language Understanding • Data: Primarily web-based, highly filtered towards textbooks quality data • Goal: Teach general knowledge and language skills - Phase 2: Logical Reasoning & Niche Skills • Data : Filtered web data (subset of Phase 1) and synthetic data • Goal: Enhance logical reasoning, math, coding and specialized skills Two-stage post-training - Stage 1: Instruction following Supervised Finetuning (SFT) • Data: curated high-quality data across various domains (math, coding, reasoning, conversation, safety) • Goal: Improve domain-specific knowledge and ability to follow user instructions in various use cases - Stage 2: Direct Preference Optimization (DPO) • Data: Preference Chat format data, reasoning, and Responsible AI (RAI) efforts • Goal: Steer model away from unwanted behavior, enhance robustness, safety, and transform into an efficient AI assistant
perform well at simple tasks Offline environments, on-device or on-prem, where local inference may be needed Latency bound scenarios where fast response times are critical Cost constrained tasks/use cases, particularly those with simpler tasks Resource constrained environments Select tasks can see improved performance via fine-tuning (vs. large model out-of-box)
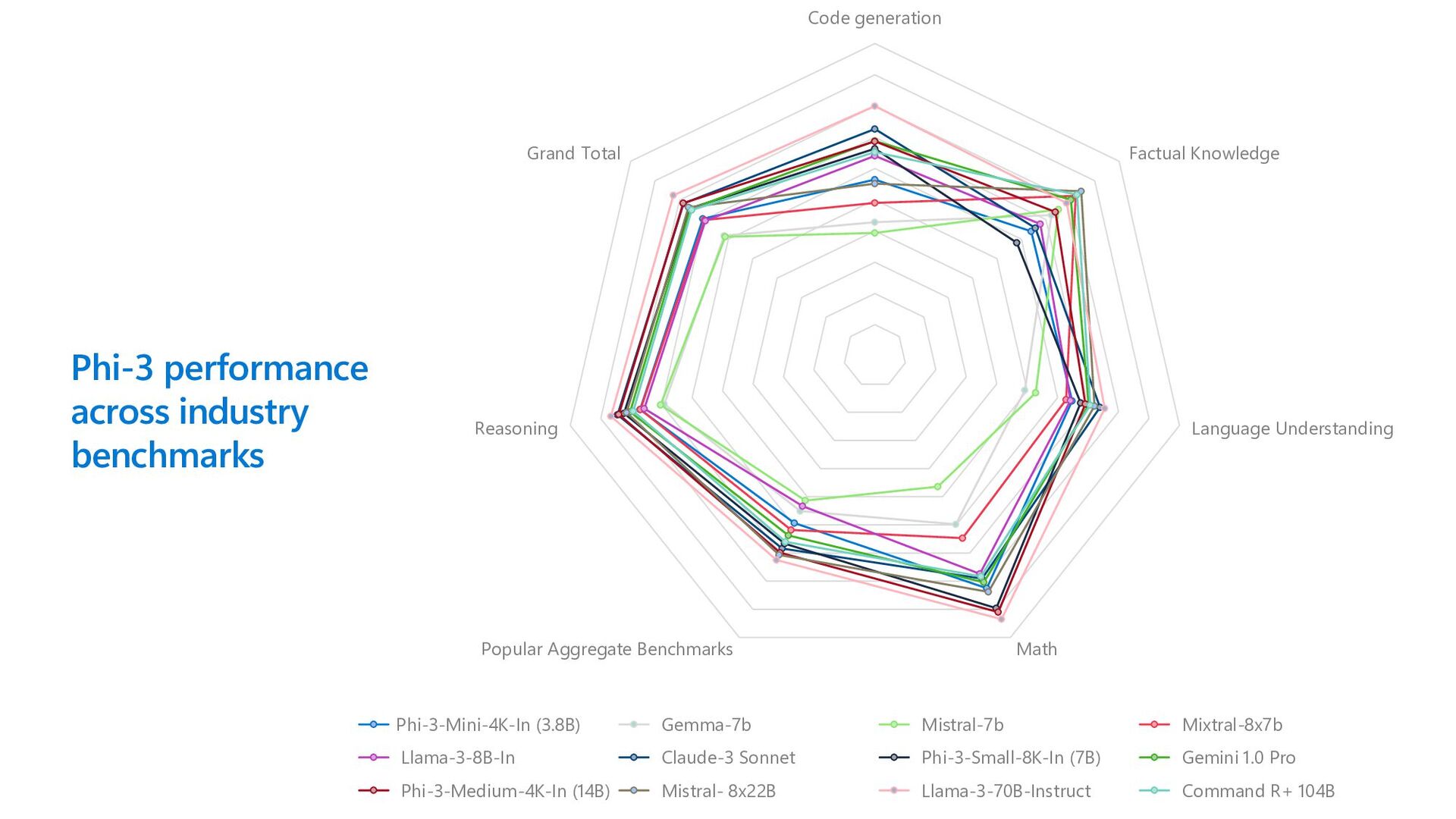
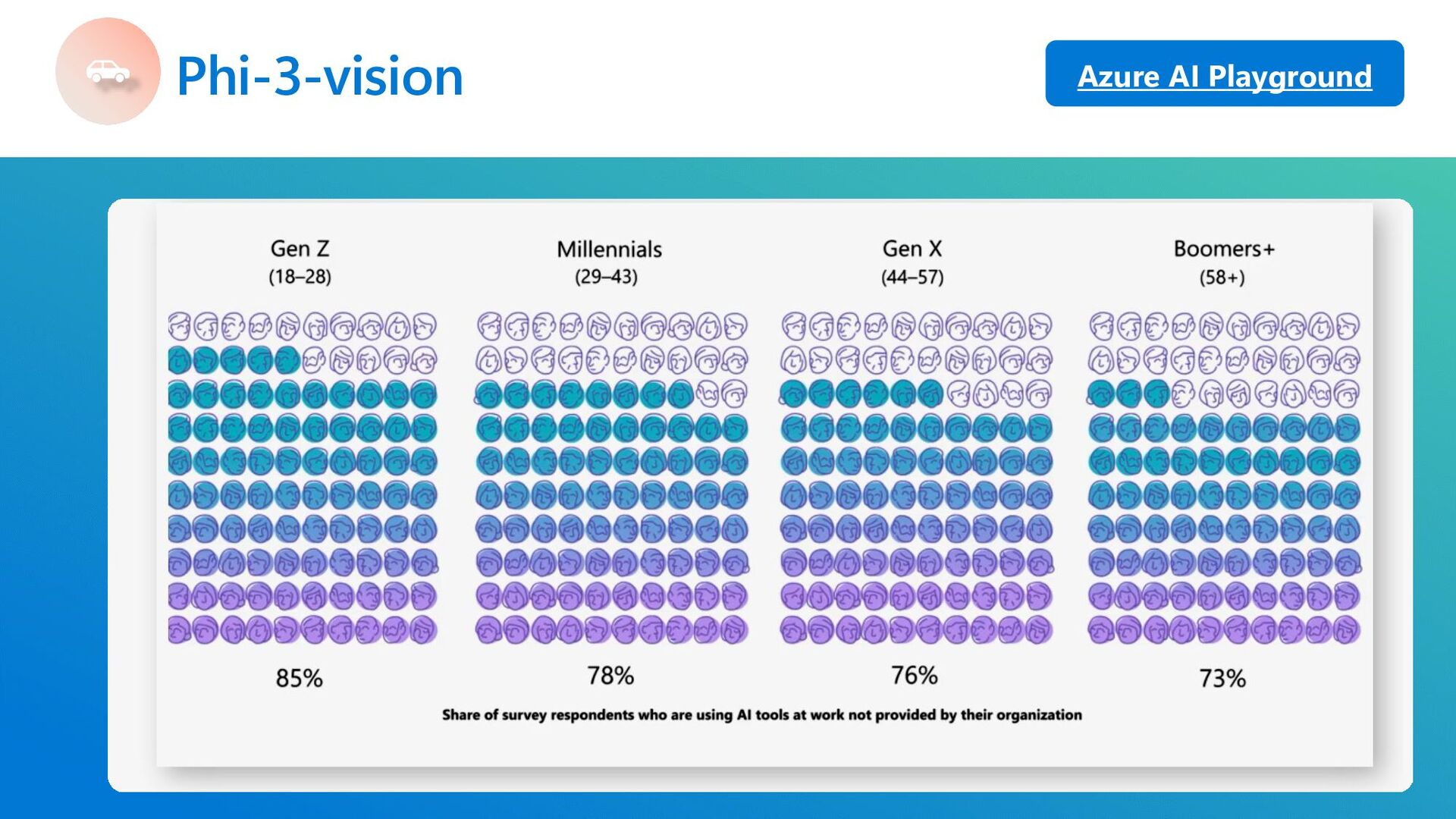
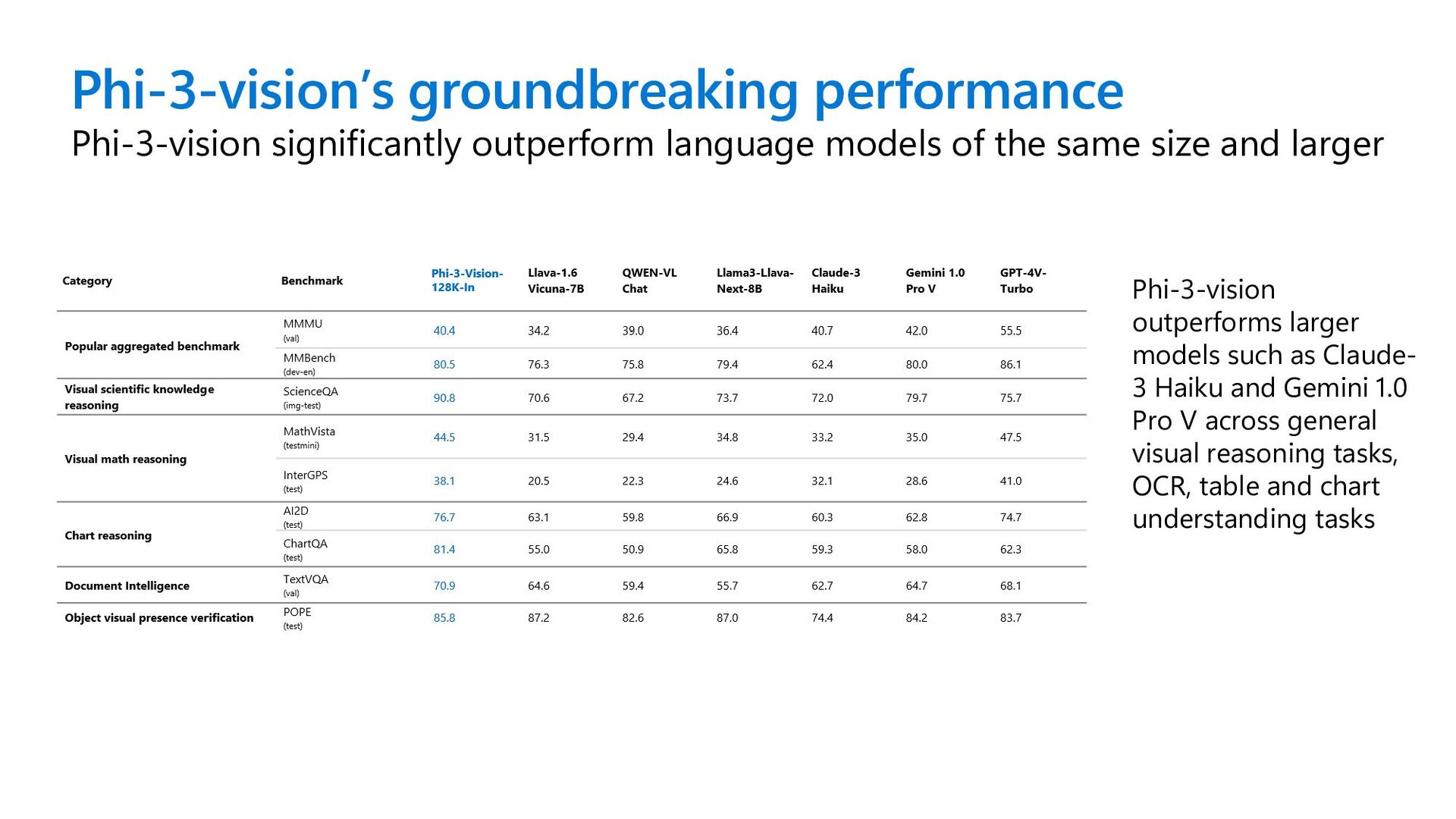
same size and larger Phi-3-vision outperforms larger models such as Claude- 3 Haiku and Gemini 1.0 Pro V across general visual reasoning tasks, OCR, table and chart understanding tasks
{kind=link}
{kind=link}
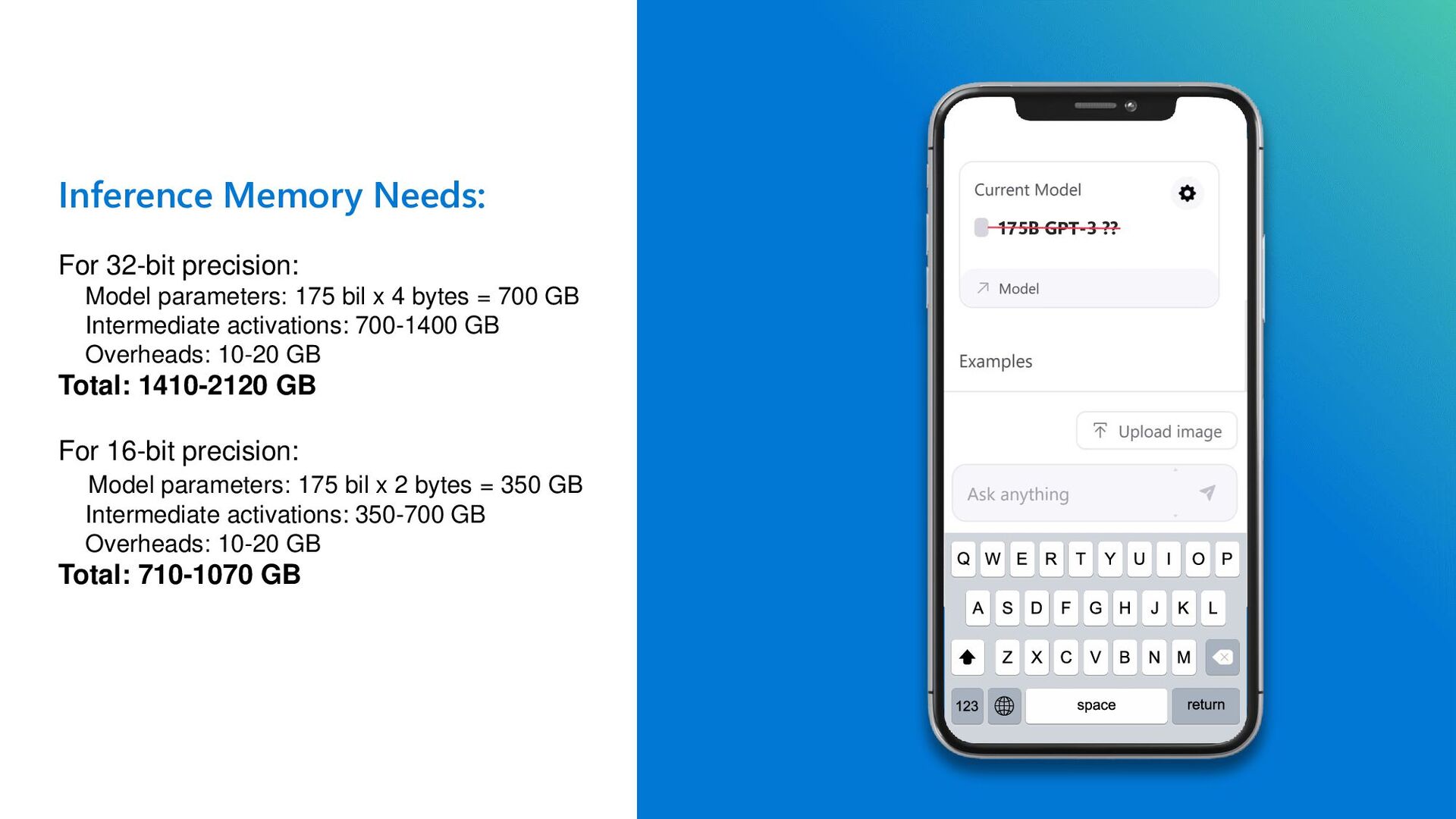{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}