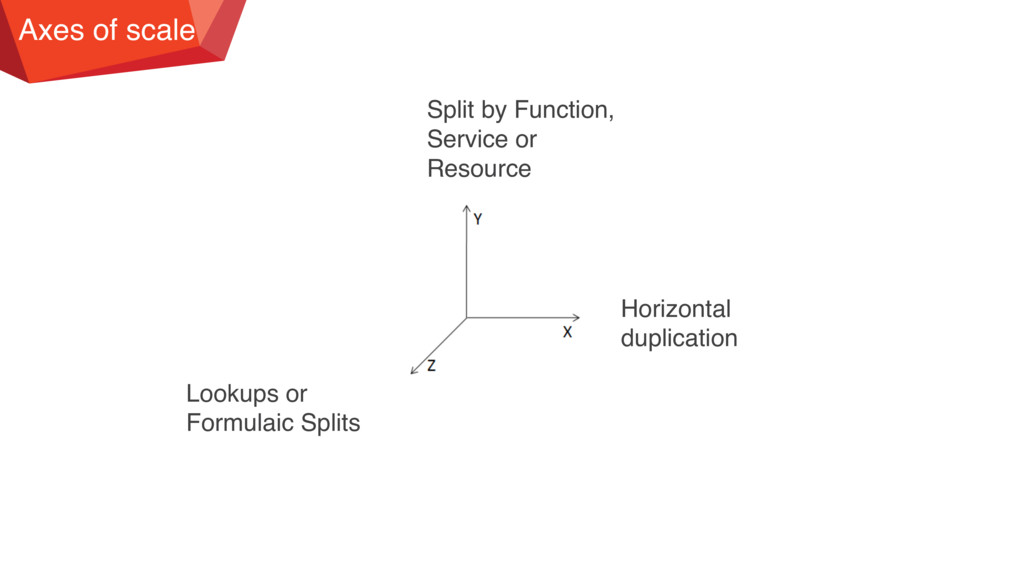
of services or databases to spread transaction load. • Why: Allows for fast scale of transactions at the cost of duplicated data and functionality. X-axis Clone things
resources, focuses on scaling data sets, transactions and engineering teams. • Why: Allows for efficient scaling of not only transactions, but very large data sets associated with those transactions. Y-axis Split different
unique aspect of the customer such as customer ID, name, geography and so on. • Why: Rapid customer growth exceeds other forms of data growth or you have the need to perform fault isolation between certain customer groups as you scale. Z-axis Split similar
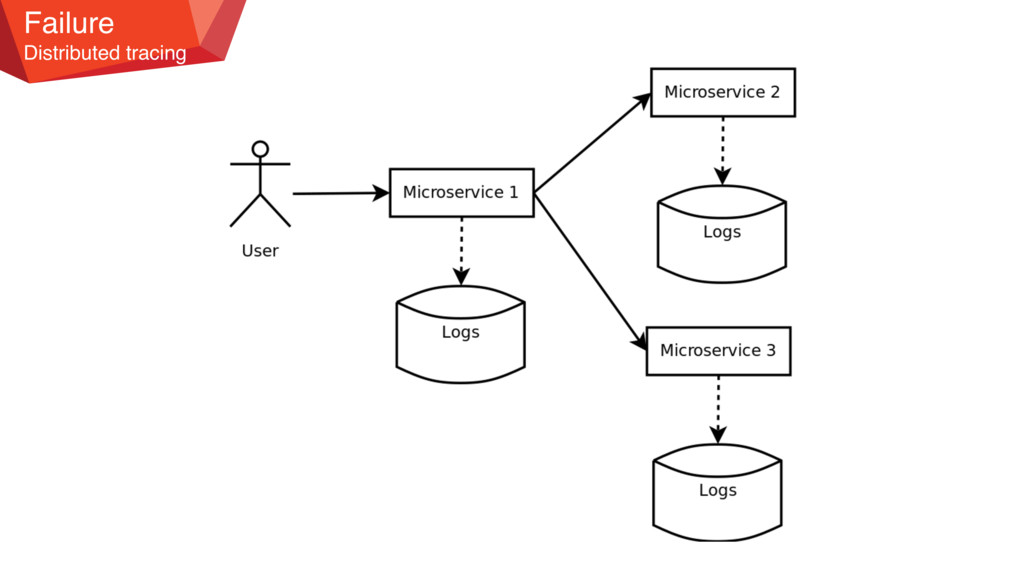
application and troubleshoot problems? • All Use a centralised logging service that aggregates logs from each service instance. The users can search and analyse the logs. They can configure alerts that are triggered when certain messages appear in the logs.
application and troubleshoot problems? • Report all exceptions to a centralised exception tracking service that aggregates and tracks exceptions and notifies developers.
ready for rollback; • Avoid irreversible releases; • Monitoring and metrics helps to measure and analyse result of the release; • Set up partial deployment.
Web Sites (Martin L. Abbott, Michael T. Fisher) Practical Object-Oriented Design in Ruby (Sandi Metz) Eloquent Ruby (Russ Olsen) Ruby Performance Optimization: Why Ruby is Slow, and How to Fix It (Alexander Dymo) Design Patterns in Ruby (Russ Olsen) Implementing SOA: Total Architecture in Practice By Paul C. Brown http://microservices.io/patterns/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}