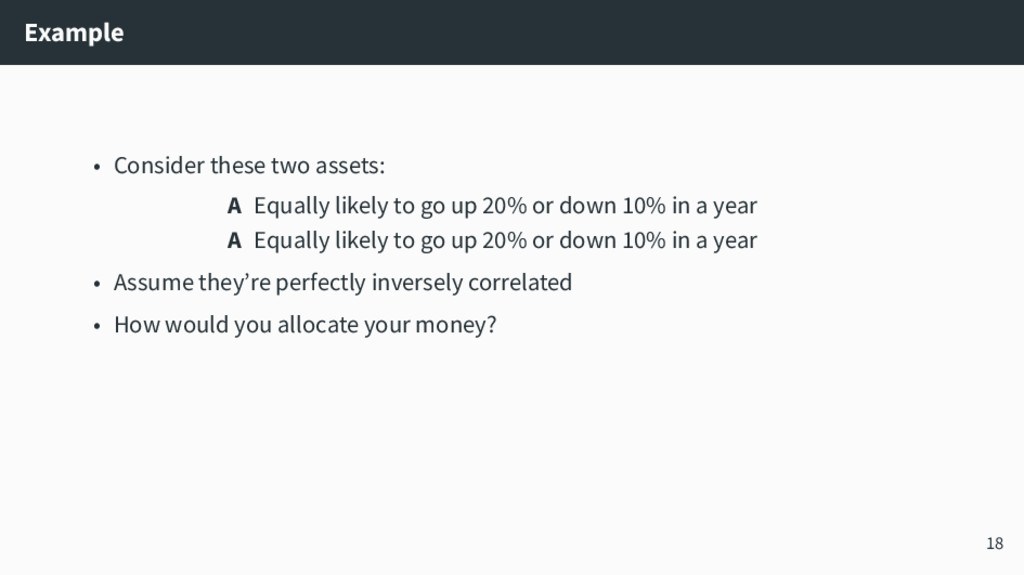
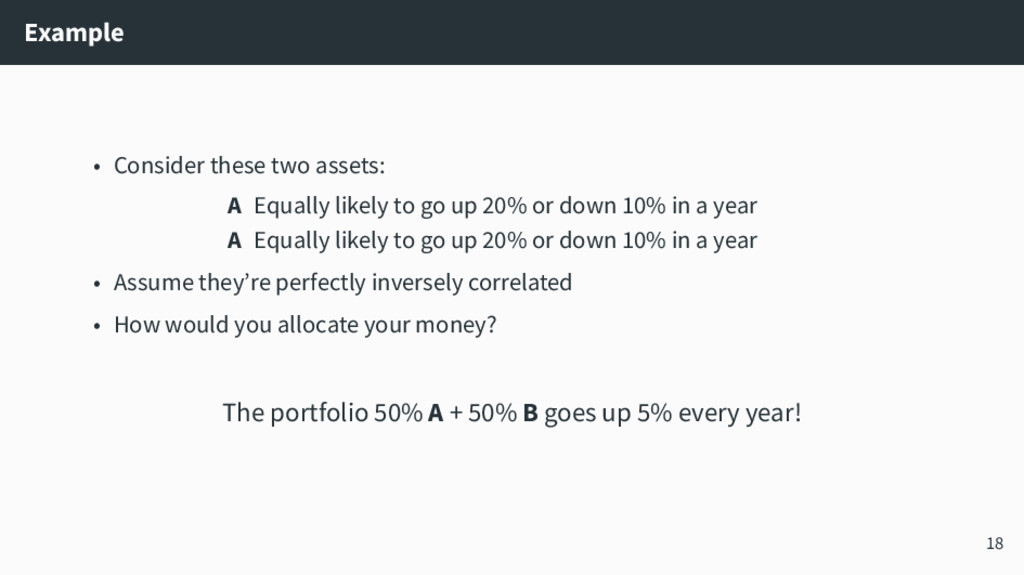
1] min x,u,v τ 1⊺ n u + (1 − τ)1⊺ n v s.t. Ax + u − v = b u, v ≥ 0 This is the τth quantile regression problem q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q q 0 10 20 30 0 25 50 75 100 x y 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
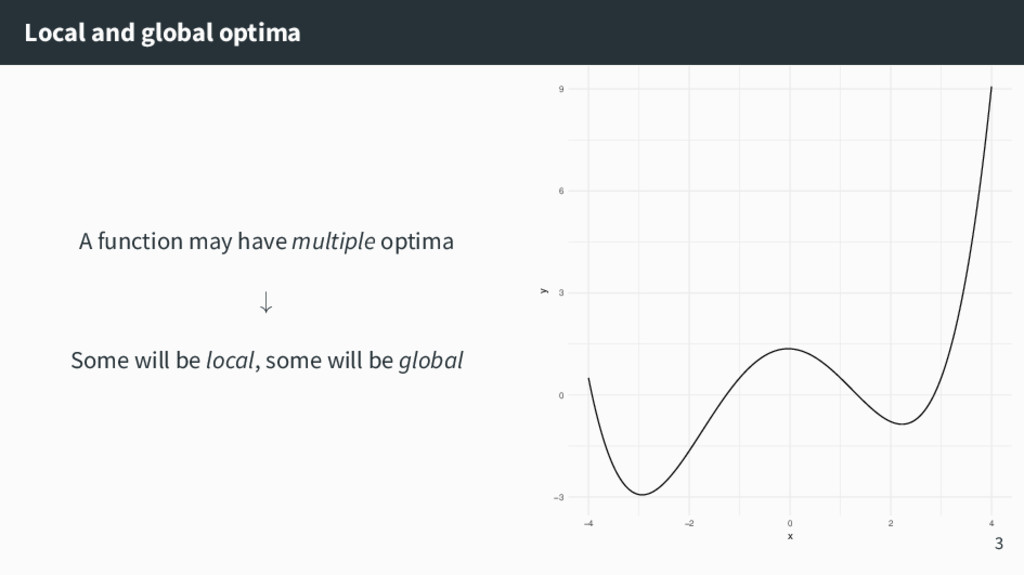{kind=link}
{kind=link}
{kind=link}
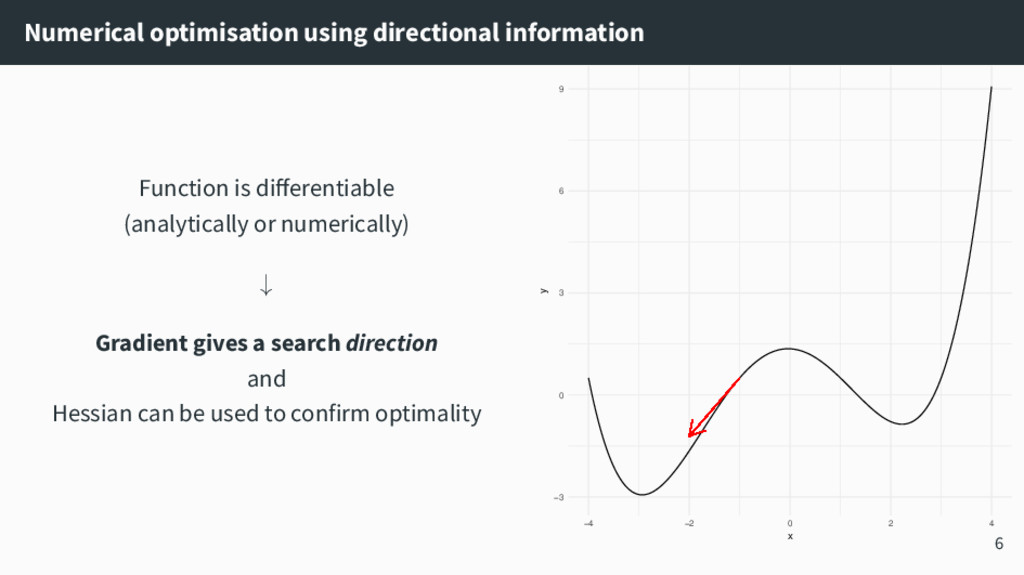{kind=link}
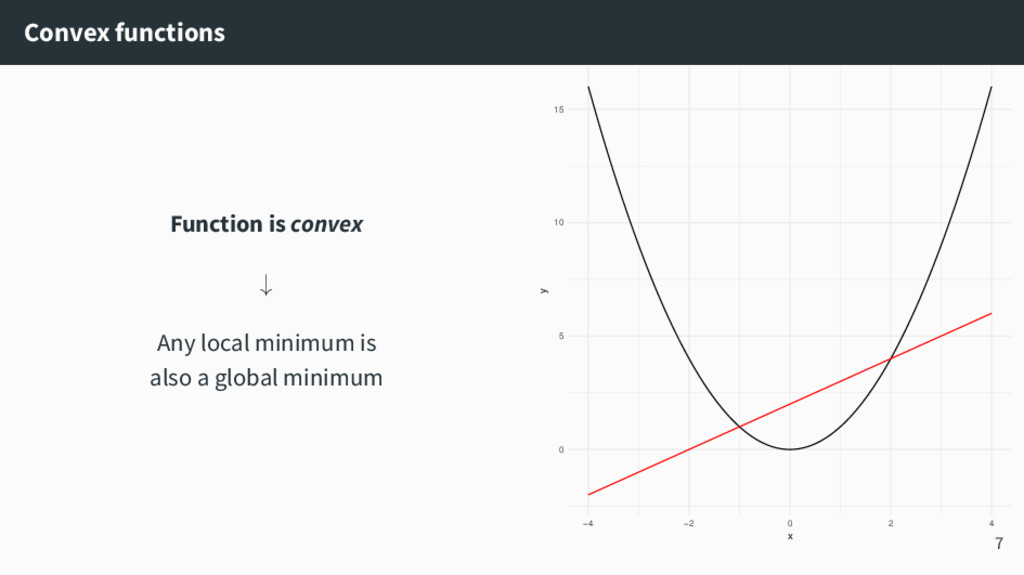{kind=link}
![Constrained optimisation What about g : [0, 1]100 → R?](https://files.speakerdeck.com/presentations/cc6bec5254ce46b4a5c0c0d612d4e093/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
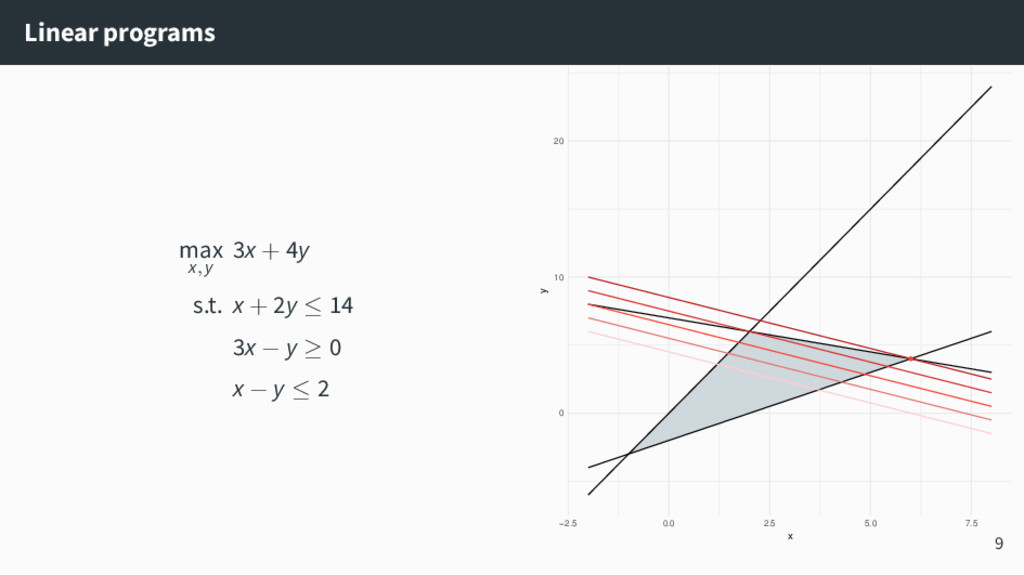{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}