Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DSB2019 10th Solutionの一部とShakeについて
Search
pao
February 29, 2020
Technology
810
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DSB2019 10th Solutionの一部とShakeについて
pao
February 29, 2020
More Decks by pao
See All by pao
JOAI2026 講評
go5paopao
0
390
いろんなものと両立する Kaggleの向き合い方
go5paopao
3
2.6k
データサイエンティストとは何か論争にAI(gpt-2)で終止符を打とうとした話
go5paopao
0
260
短期間コンペの戦い方
go5paopao
13
14k
atmaCup#9 1st place solution
go5paopao
6
3.8k
Kaggle Malware competition 2th→1485th solution
go5paopao
2
9.8k
Other Decks in Technology
See All in Technology
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
400
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
230
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
170
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
SRE Lounge Hiroshimaへの招待
grimoh
0
420
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
430
記録をかんたんに、提案をパーソナルに ── AIであすけんが目指すもの
oprstchn
0
170
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
そのタスクオンスケですか?
poropinai1966
0
140
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.3k
Featured
See All Featured
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Typedesign – Prime Four
hannesfritz
42
3.1k
Transcript
Shake と 10th Place Solutionの一部 pao DataScienceBowl2019 振り返り
• 名前 ◦ Pao • 所属 ◦ JTC(もうすぐ卒業予定) • 悩み
◦ 子供がかわいすぎる • 特技 ◦ Shake 自己紹介
Solutionの一部とShakeについて話します ↓に概要書いてます https://www.kaggle.com/c/data-science-bowl-2019/discussion/127332 183 => 10位でSolo Gold!! ShakeUpするとは思っていたが、どれくらい上がるかは分かってなかった 結果
• 10th Place Solutionの一部 • Shakeについて
• 10th Place Solutionの一部 • Shakeについて
• Model: LightGBM x 6 average • Validation ◦ StratifiedGroupKFold
◦ 50個のTruncatedしたSubSet作成し、その平均をCVスコアとした ◦ EarlyStoppingは別の1つのSubSetに対して実施 • QWK Threshold ◦ 固定値 (Optimizationして出た値を丸めたもの) ▪ TrainへのOverfitをさけた • Feature ◦ よかったもの:標準化した過去の成績(センター試験のニュース見て思いついた) ◦ 累積系は基本入れず、比率系の特徴だけを入れた(過去の Play回数に出来るだけ依存しない) ◦ Feature Selection(次ページ) • Other ◦ FeatureFraction 1.0 (Titleの列が必須だった?) ◦ Testデータを入れる Solution概要
• Feature Importance上位300件くらいを利用 ◦ CVだけあげないようにするために、 Validation使う系のSelectionは避けた • 懸念:普通に学習すると、TruncatedされてないTrainデータでのImportanceになって しまう ◦
Trainのほうが過去Play回数が多いデータが多い ◦ Play回数が多いデータに効く特徴が上位に来やすくなる • 対策:TruncatedされたTrainデータで学習したときのImportanceを利用する ◦ Submit時とは別の特徴選択用の学習 ◦ 5iteration毎に新しくTruncatedしたデータセットに変更して学習 ▪ LightGBMのinit_modelパラメータを使用 →比較していないので効果は分からなかったが意味があったと信じてる Feature Selection
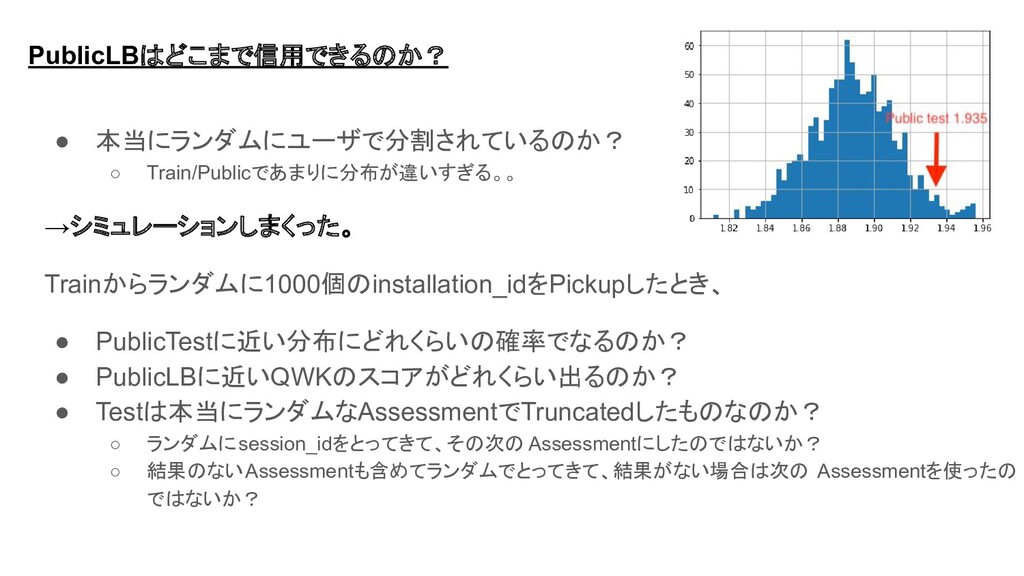
• 本当にランダムにユーザで分割されているのか? ◦ Train/Publicであまりに分布が違いすぎる。。 →シミュレーションしまくった。 Trainからランダムに1000個のinstallation_idをPickupしたとき、 • PublicTestに近い分布にどれくらいの確率でなるのか? • PublicLBに近いQWKのスコアがどれくらい出るのか?
• Testは本当にランダムなAssessmentでTruncatedしたものなのか? ◦ ランダムにsession_idをとってきて、その次の Assessmentにしたのではないか? ◦ 結果のないAssessmentも含めてランダムでとってきて、結果がない場合は次の Assessmentを使ったの ではないか? PublicLBはどこまで信用できるのか?
• 10th Place Solutionの一部 • Shakeについて
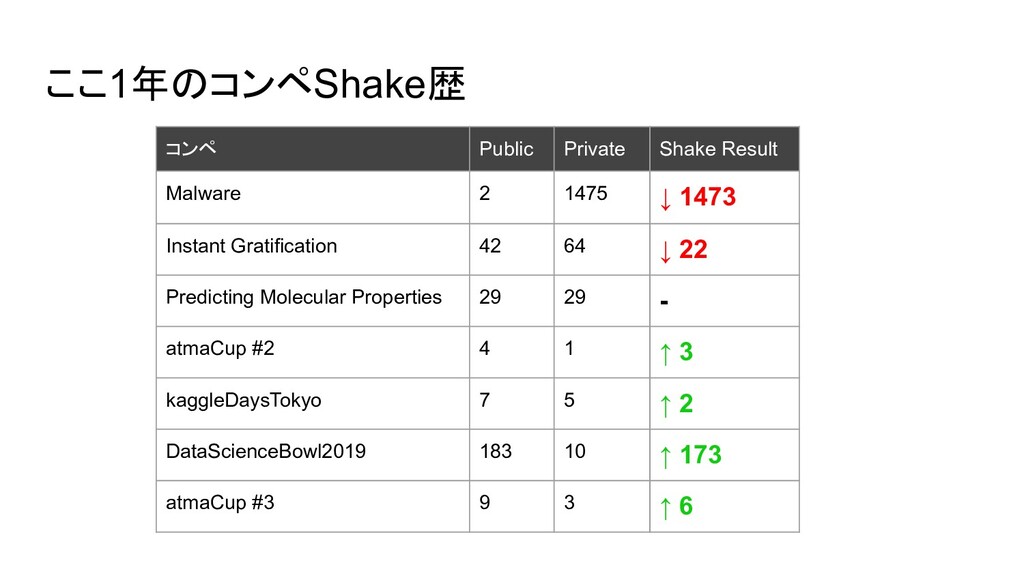
ここ1年のコンペShake歴 コンペ Public Private Shake Result Malware 2 1475 ↓
1473 Instant Gratification 42 64 ↓ 22 Predicting Molecular Properties 29 29 - atmaCup #2 4 1 ↑ 3 kaggleDaysTokyo 7 5 ↑ 2 DataScienceBowl2019 183 10 ↑ 173 atmaCup #3 9 3 ↑ 6
調子乗って書いていますが、 Shakeは運ゲーなところも、かなりあると思います。 (これを書いた翌週にはatmaCupでShakeDownしてるかも)
ShakeUp/ Downにはいろんな要因がある • コンペ自体の性質によるもの ◦ 評価指標が不安定 ◦ Publicのデータ量が少ない ◦ PublicとPrivateでデータの質が違う
▪ 相関がある時系列的なもの ▪ 相関がないもの • 参加者要因 ◦ ハイスコアカーネル&コピー勢 • 個人要因 ◦ PublicにOverfitした特徴量・モデルを作る
ShakeUp/ Downにはいろんな要因がある • コンペ自体の性質によるもの ◦ 評価指標が不安定 ←努力できるが仕方ない部分も多い ◦ Publicのデータ量が少ない ←多少努力できるが仕方ない部分も多い ◦ PublicとPrivateでデータの質が違う
▪ 相関がある時系列的なもの ←頑張れる ▪ 相関がないもの ←仕方ない(クソコンペ) • 参加者要因 ◦ ハイスコアカーネル&コピー勢 ←気をつけれる • 個人要因 ◦ PublicにOverfitした特徴量・モデルを作る ←気をつけれる
ShakeUp/ Downにはいろんな要因がある • コンペ自体の性質によるもの ◦ 評価指標が不安定 ←努力できるが仕方ない部分も多い ◦ Publicのデータ量が少ない ←多少努力できるが仕方ない部分も多い ◦ PublicとPrivateでデータの質が違う
▪ 相関がある時系列的なもの ←頑張れる ▪ 相関がないもの ←仕方ない(クソコンペ) • 参加者要因 ◦ ハイスコアカーネル&コピー勢 ←気をつけれる • 個人要因 ◦ PublicにOverfitした特徴量・モデルを作る ←気をつけれる DSB2019での主な要因
ハイスコアカーネル&コピー勢 • 相関の高い類似SubmissionがLBを占める ◦ Privateでその集団に勝てるかどうかで一気に順位が変わる • ハイスコアカーネルはPublicLBにOverfitting気味である ◦ 毒入りのときもある ◦
謎の特徴量、ハイパーパラメータ、後処理など注意 参考にするのは解釈ができる部分だけにしたほうがいい DSBはまさにこれ
PublicにOverfitした特徴量・モデルを作る • CV気にせずサブミットしまくり、LBをあげる • 何か分からないけど、スコアが上がった ◦ 解釈できない場合、危険(特にテーブルデータ) よくある要因 個人的に気をつけていること •
出来るだけ仮説ベースで実験する ◦ 「何かわからんがやってみた!」は危険 ▪ 頭回っていないときにやりがちなので注意 • 自分の信じる指標・方針を最初に決めておく ◦ 終盤にTrustLBからTrustCVに切り替えても手遅れだったりする ◦ TrustLBかTrustCVの二択だけでなく、両方使うことも含めて決める • 最終サブ選択 ◦ 状況次第だが、Shakeしそうなときは出来るだけ相関の低い2つのものを選ぶ
その他 • ShakeDownして自ら辛い経験をすることで次から気を つけられるようになる ◦ Malware以降、異常に考えるようになった ShakeDownの数だけ強くなれる
End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}