Share
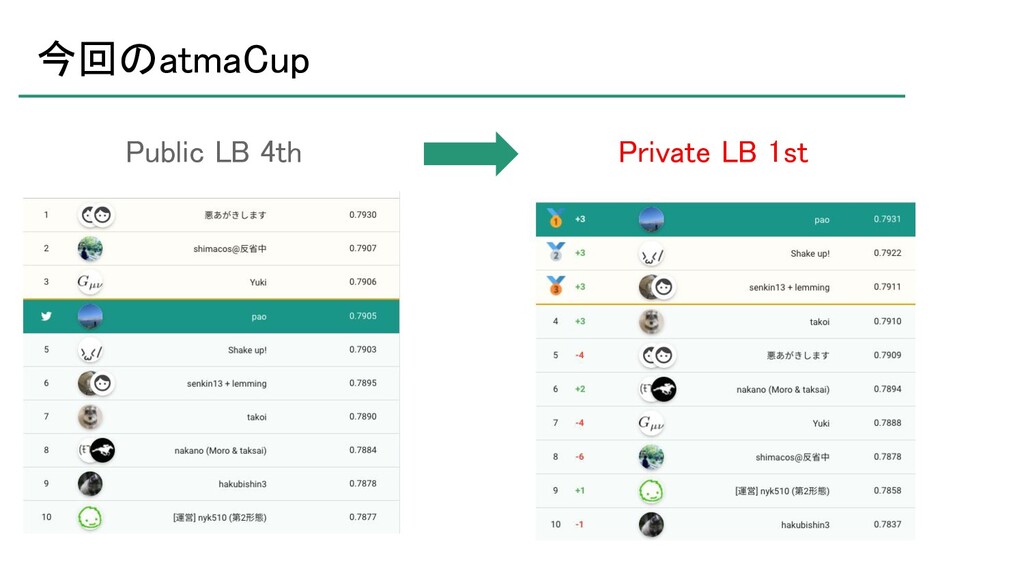
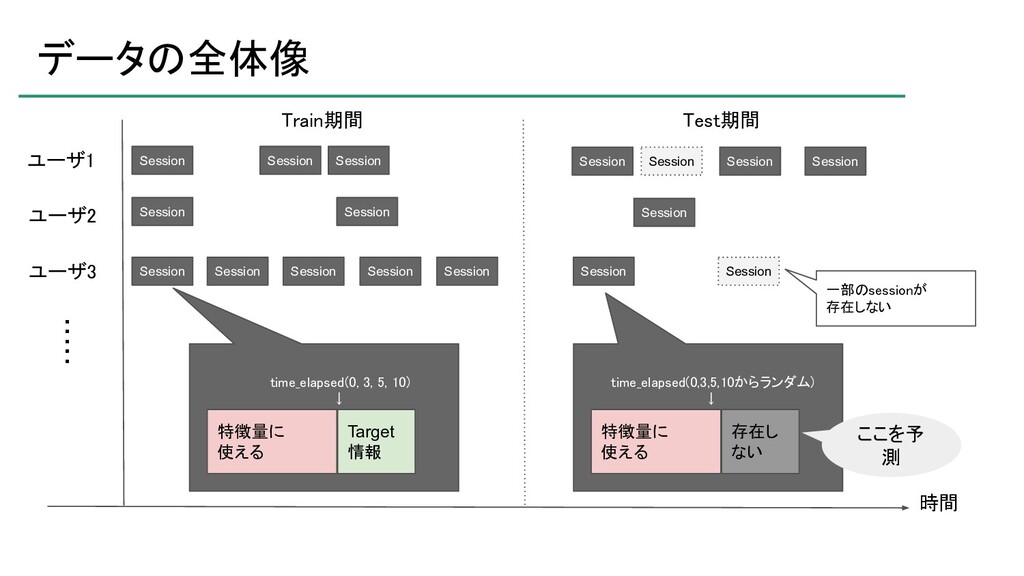
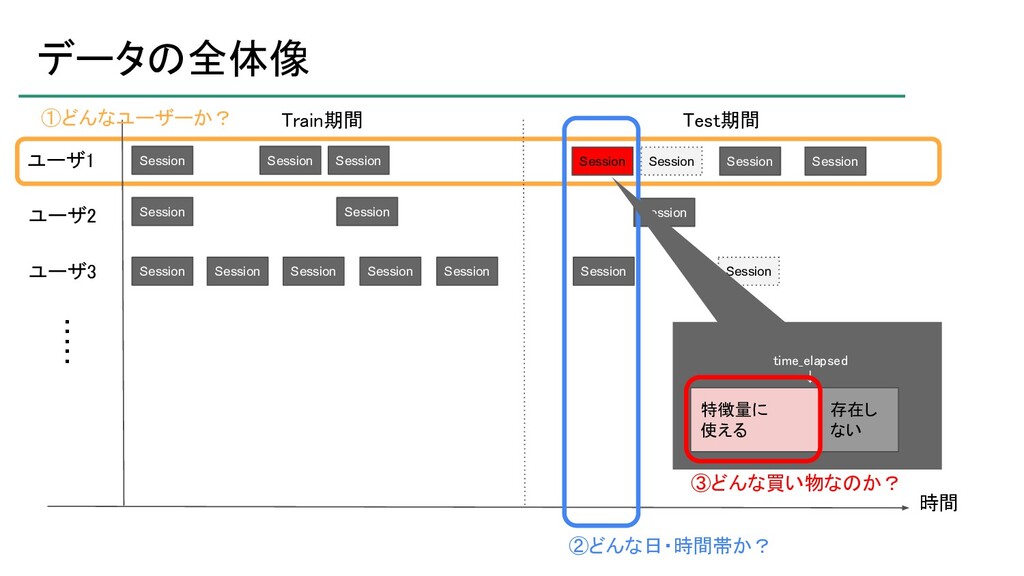
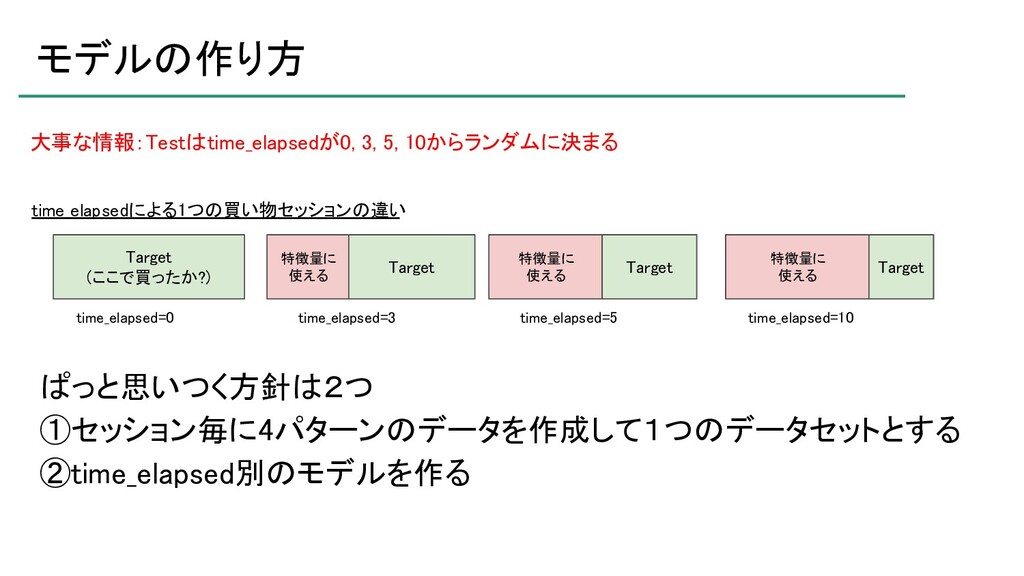
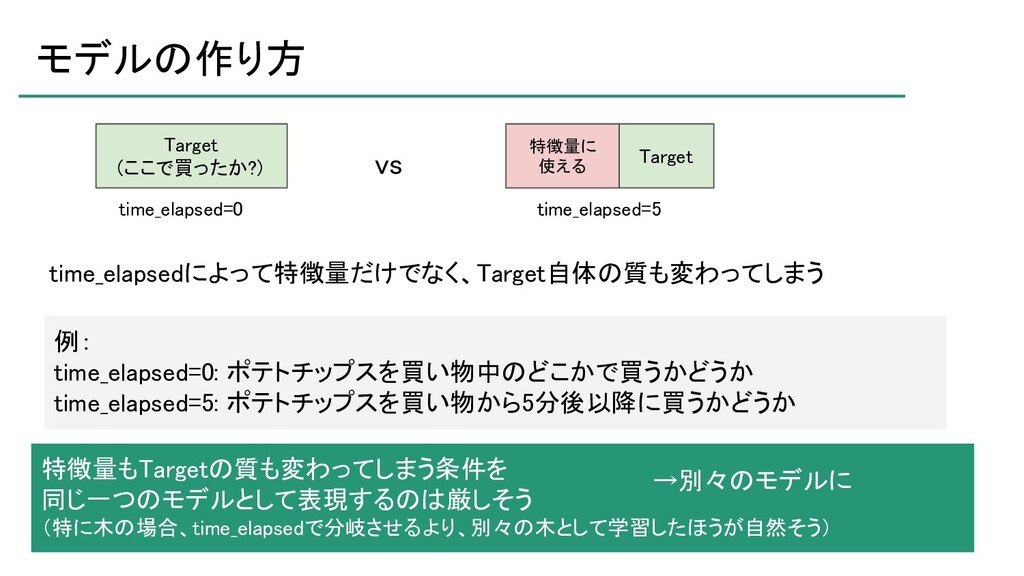
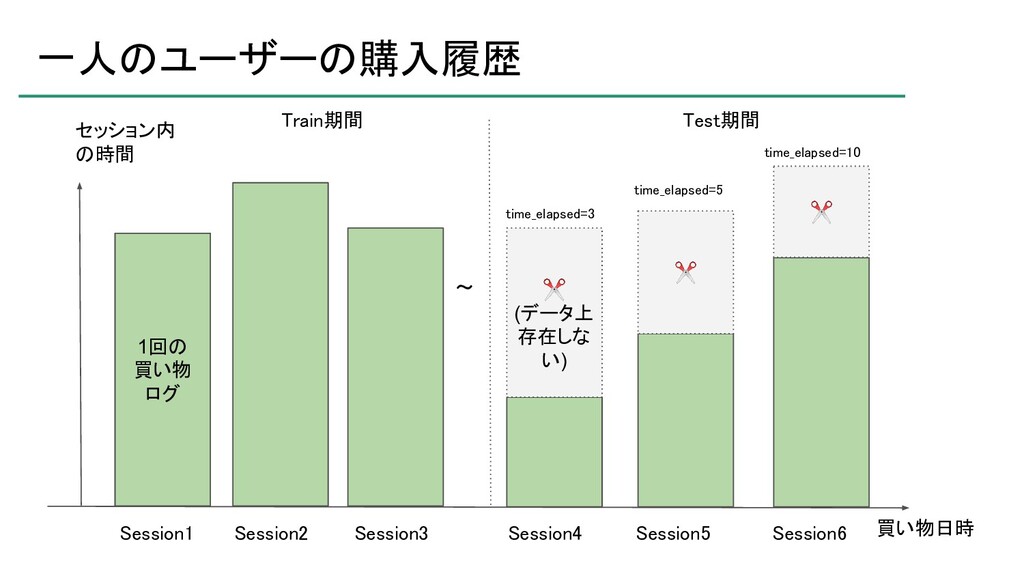
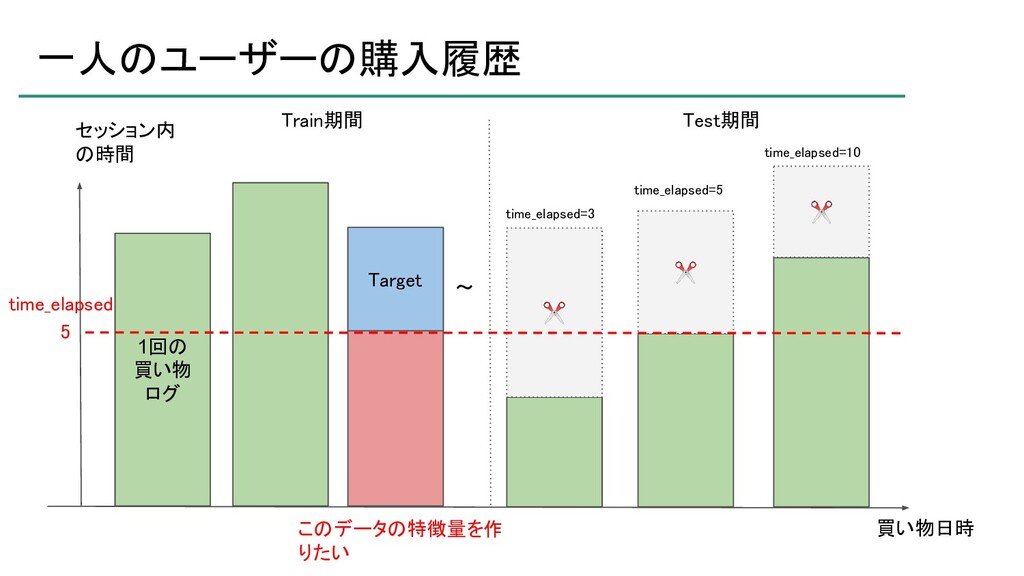
atma株式会社が主催するデータサイエンスコンペティション「atmaCup」の第9回において優勝したので、そのソリューションの紹介です。 ソリューションそのものというよりは、考え方について説明したスライドです。 ※コンペティションの内容を知らないとよく分からないかもしれません。 https://atma.connpass.com/event/199979/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
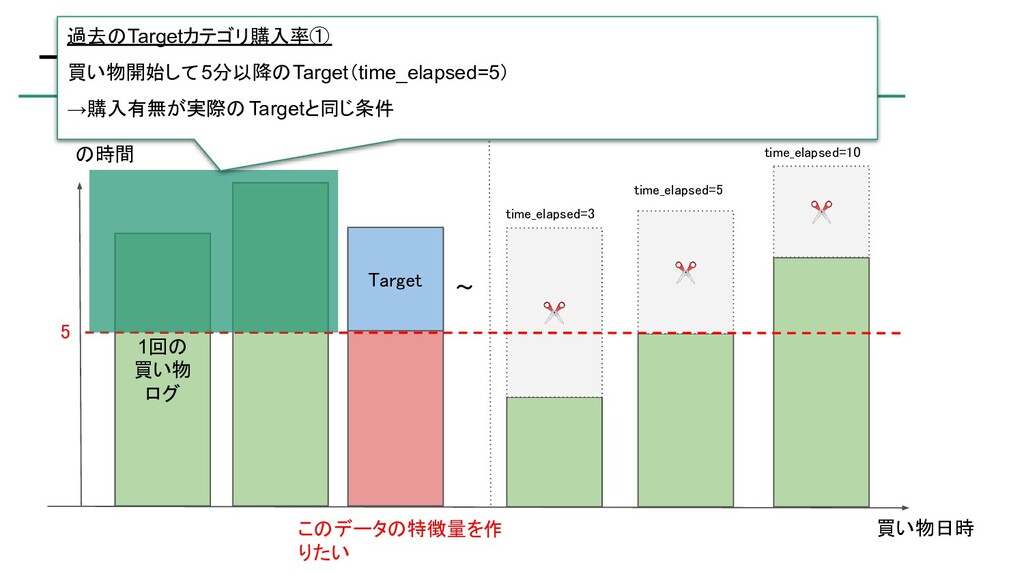{kind=link}
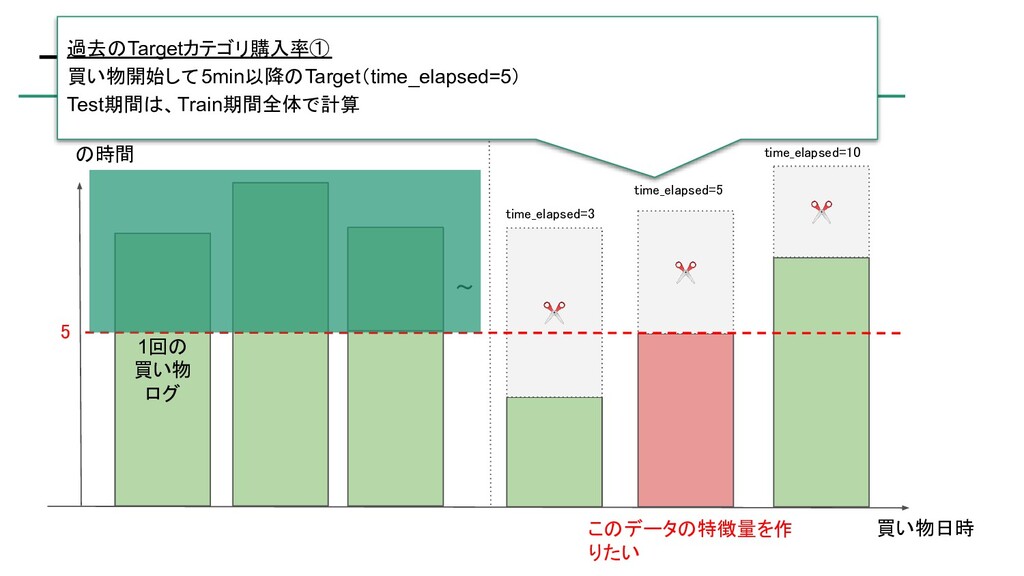{kind=link}
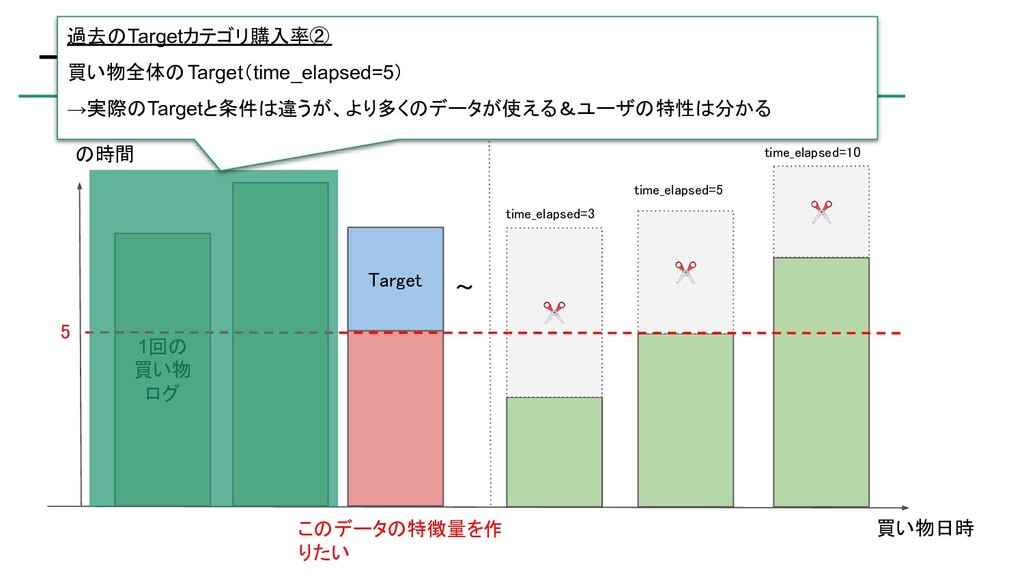{kind=link}
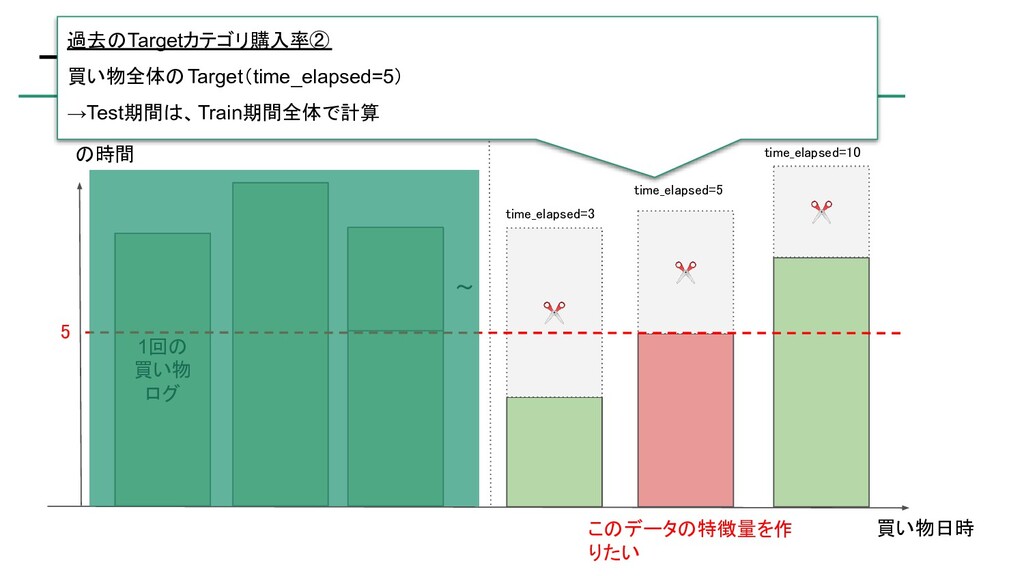{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}