Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
聚类分析在短小文本上的应用
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
greenmoon55
June 24, 2014
Technology
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
聚类分析在短小文本上的应用
毕业论文
greenmoon55
June 24, 2014
Other Decks in Technology
See All in Technology
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
2
1.1k
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
150
AIエージェントとPhysical AIが拓く製造業の変革(ハノーバーメッセリキャップ)
iotcomjpadmin
0
170
Fabricをフル活用する AI Agent Hub -製造業特化AIエージェントの設計
iotcomjpadmin
0
160
Microsoft のサポートとフィードバック総まとめ
murachiakira
PRO
0
120
どうして今サーバーサイドKotlinを選択したのか
nealle
0
120
Hatena Engineer Seminar 37 jj1uzh
jj1uzh
0
190
AIチャットの改善から見えた、良いAI体験とは / What Constitutes a Good AI Experience: Insights from Improving AI Chat
kubode
0
130
Multi-Agent並列開発を 安全に回すための技術 / Technology for Safely Multi-Agent Parallel Development
tooppoo
0
220
AI時代のコスト管理を考えよう〜明日から使える実践AWSノウハウ~
yoshimi0227
0
970
感情と身体を置き去りにしない、エンジニアの生きのこり方 ──いまから、ここから「自分の状態」を扱うという選択
saorimurooka
0
390
#エンジニアBooks 30分でわかる 「技術記事を書く技術」 / engineer-books 2026-06-30
jnchito
1
130
Featured
See All Featured
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
450
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
140
Side Projects
sachag
455
43k
Abbi's Birthday
coloredviolet
3
8.3k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
We Have a Design System, Now What?
morganepeng
55
8.2k
Ethics towards AI in product and experience design
skipperchong
2
320
Large-scale JavaScript Application Architecture
addyosmani
515
110k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
How GitHub (no longer) Works
holman
316
150k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Transcript
聚类分析在短小文本上的应用
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
研究背景 • 聚类分析 • 短文本通常指长度比较短,一般不超过两百个字 符的文本形式。 • 短文本关键词词频很低,样本特征非常稀疏,形 式不规范,趋向口语化。 ▫
Was about to go to the gym buuuttt...you know...rain...eh. ▫ looks like heavy rain but not much convection :-( https://twitter.com/kdennis1122/status/476029813090557955 https://twitter.com/Legwynis/status/476030781350244352
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
文本聚类框架 • 预处理 ▫ Was about to go to the
gym buuuttt...you know...rain...eh. ▫ gym, rain 文本信息的 预处理 文本表示模 型的建立 使用聚类算 法 评估聚类结 果
文本聚类框架 • 文本表示模型的建立 ▫ 传统文本:向量空间模型等 文本信息的 预处理 文本表示模 型的建立 使用聚类算
法 评估聚类结 果
文本聚类框架 • 使用聚类算法 ▫ K-means ▫ 层次聚类 ▫ 谱聚类 文本信息的
预处理 文本表示模 型的建立 使用聚类算 法 评估聚类结 果
文本聚类框架 • 评估聚类结果 ▫ 人工评价 ▫ 聚类评价指标 文本信息的 预处理 文本表示模
型的建立 使用聚类算 法 评估聚类结 果
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
短文本相似度 • 单词之间的相似度 ▫ Wikipedia ▫ Google ▫ WordNet •
多个单词构成的短文本之间的相似度
单词之间的相似度(WordNet) Path ℎ, = 1 5 Hao Chen. String metrics
and word similarity applied to information retrieval[D]. University of Eastern Finland, 2012.
单词之间的相似度(WordNet) • 基于路径的相似度算法 ▫ Path ▫ Wu & Palmer •
基于信息内容的相似度算法 ▫ Resnik ▫ Jiang & Conrath
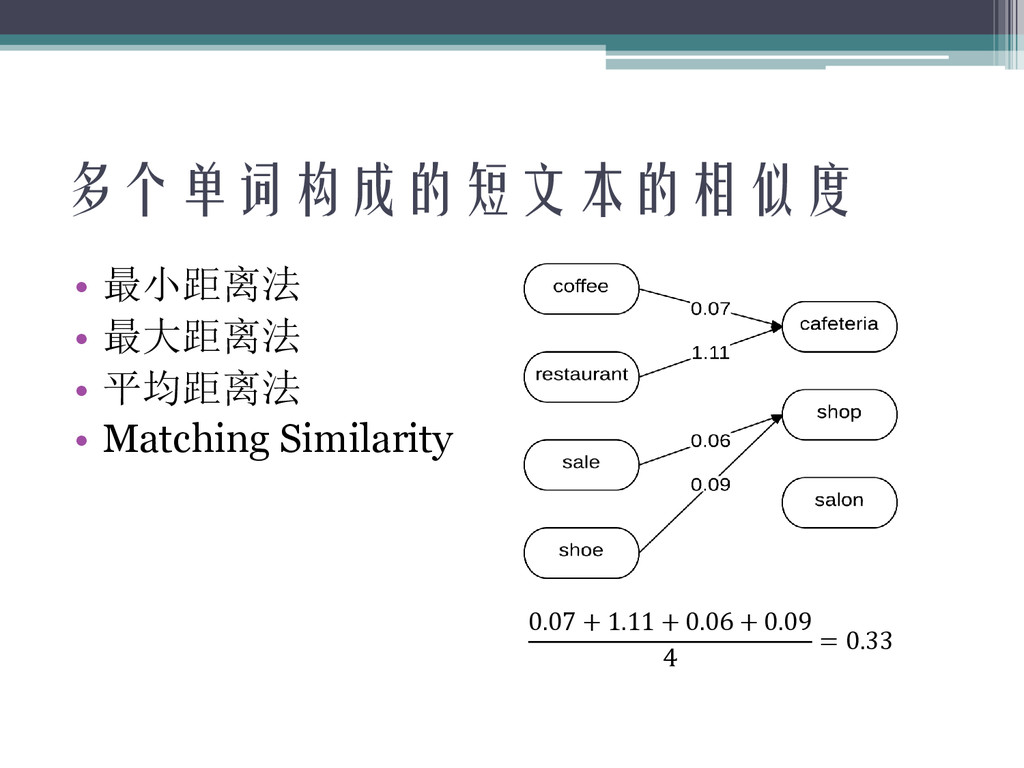
多个单词构成的短文本的相似度 • 最小距离法 • 最大距离法 • 平均距离法 • Matching Similarity
0.07 + 1.11 + 0.06 + 0.09 4 = 0.33
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
短文本聚类算法 • 输入为预处理后的短文本数据,以及某种短文本 相似度计算方法 • 算法: ▫ 层次聚类法 ▫ 谱聚类
短文本聚类算法 • 聚类结果评价 ▫ 聚类内紧密度SSW 数据点和聚类中心的相似度 ▫ 聚类间分离度SSB
不同的聚类中心之间的差异度 ▫ 基于SSW和SSB的评价准则 Ball & Hall Index Calinski & Harabasz Index Hartigan Index WB-index
目录 • 研究背景 • 文本聚类框架 • 短文本相似度 • 短文本聚类算法 •
实验内容
实验 • 实验一:比较相似度算法 ▫ 使用层次聚类法和谱聚类算法对两个人造数据进行 聚类 ▫ 比较三种基于WordNet的相似度计算方法:Path、 Wu &
Palmer和Jiang & Conrath。 ▫ 结论是基于信息内容的Jiang & Conrath算法结果较 好
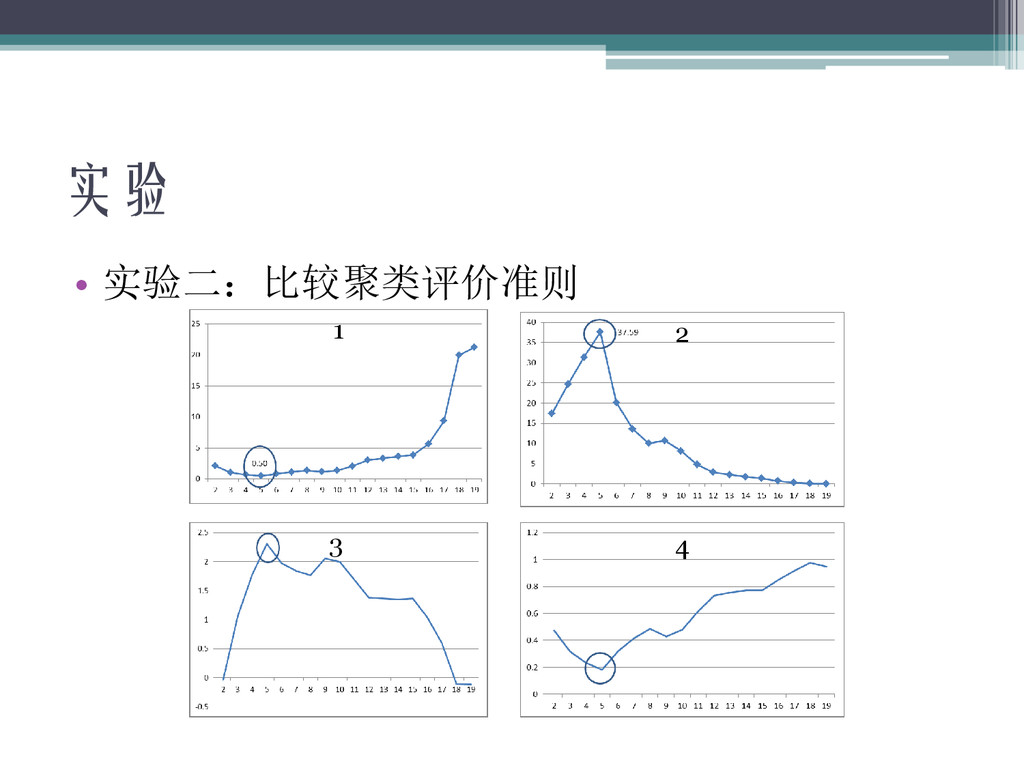
实验 • 实验二:比较聚类评价准则 ▫ 人造数据 ▫ 层次聚类法 ▫ Jiang &
Conrath相似度算法 ▫ 比较四种相似度准则 ▫ 结果差异不大,和人工判断相同
实验 • 实验二:比较聚类评价准则 1 2 3 4
实验 • 实验三:Mopsi项目数据的聚类 ▫ Mopsi项目数据(共122条) fruit,vegetable Department,Shop,store
Church,witness ice,cream Shop,clock,gift,jewelry cafe,bakery,pastry,shop http://cs.uef.fi/mopsi/
实验 • 实验三:Mopsi项目数据的聚类 ▫ 根据聚类评价准则,最佳聚类数目为48 ▫ Mopsi项目数据的聚类结果经过人工评价基本符合 需求 ▫ 文本中的主题有餐厅、商店、医疗、运动等等
▫ 论文中有部分结果展示
总结 • 研究内容 ▫ 概括文本聚类的框架(传统文本和短文本) ▫ 研究短文本相似度算法 ▫ 深入学习并实现几种文本聚类算法 ▫
通过实验对选择适当的相似度算法和聚类算法,对 Mopsi项目的真实数据进行聚类 • 展望 ▫ 并行计算 ▫ 更准确的文本相似度
谢谢
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}