Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
完全自動運転のモデル開発におけるデータ品質とは
Search
Kei
March 18, 2025
790
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
完全自動運転のモデル開発におけるデータ品質とは
Kei
March 18, 2025
More Decks by Kei
See All by Kei
Turing Tech Talk #12自動運転を支えるソフトウェア開発基盤 共通技術で実現する再現性と生産性
gusoku
0
310
Featured
See All Featured
Art, The Web, and Tiny UX
lynnandtonic
304
22k
How STYLIGHT went responsive
nonsquared
100
6.2k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Marketing to machines
jonoalderson
1
5.5k
Visualization
eitanlees
152
17k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
The browser strikes back
jonoalderson
0
1.4k
WENDY [Excerpt]
tessaabrams
11
38k
Transcript
完全⾃動運転のモデル開発におけるデータ品質とは Turing株式会社 松⽥和樹 Findy データ品質 どう担保する? 〜 複雑化を乗り越える品質管理のリアル 〜
• 松⽥ 和樹 • 所属 ◦ チューリング株式会社(2024/02〜) ◦ MLOps チーム
• 経歴 ◦ ネット広告の会社でインフラエンジニア ◦ ネット広告系のスタートアップで⾊々 ◦ AWS でスタートアップ専任の SA ⾃⼰紹介
Tokyo30 2025年末までに、カメラと AIだけで 東京エリアを30分以上介入なしで走行し続ける自 動運転モデルを開発します
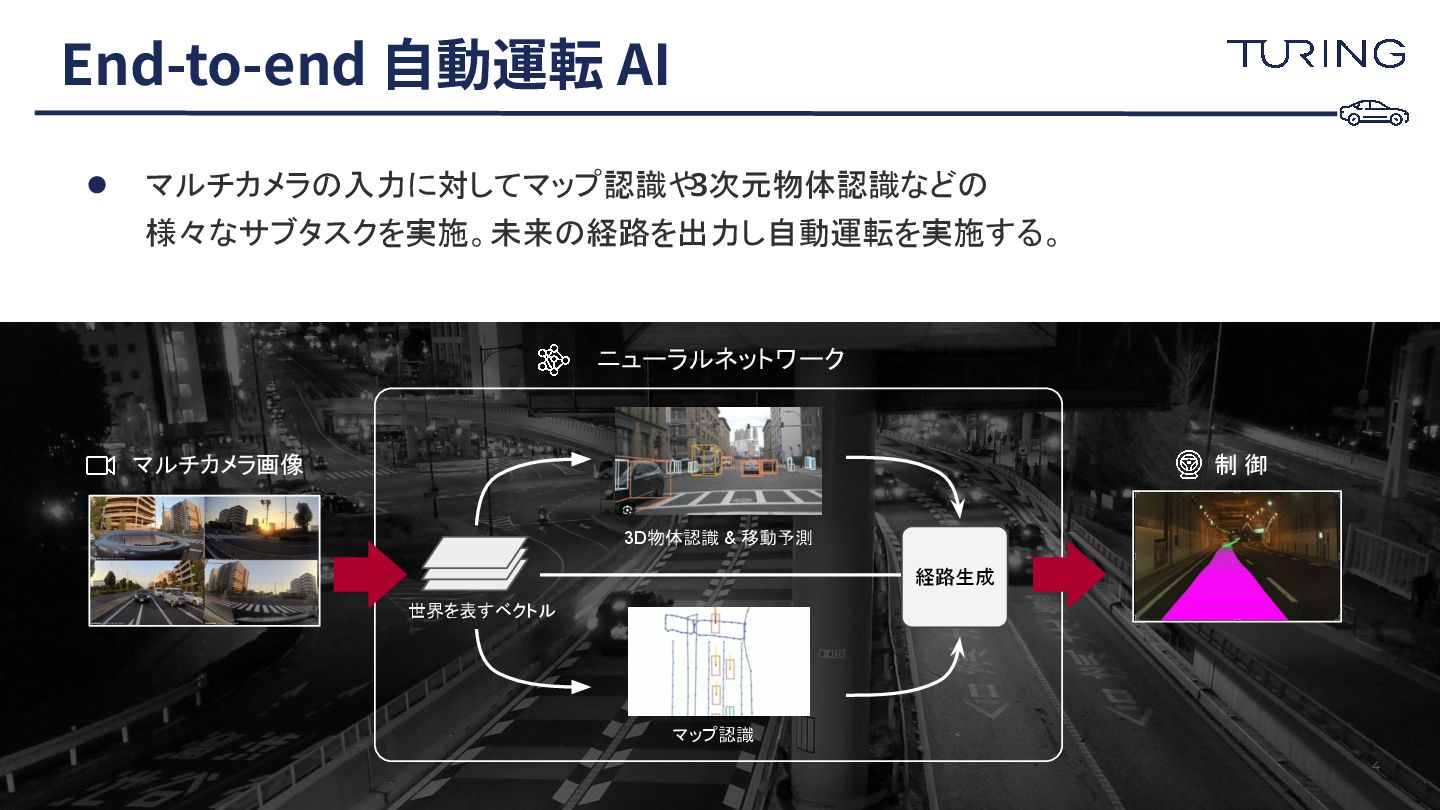
• マルチカメラの入力に対してマップ認識や 3次元物体認識などの 様々なサブタスクを実施。未来の経路を出力し自動運転を実施する。 End-to-end ⾃動運転 AI 4 ニューラルネットワーク
3D物体認識 & 移動予測 マップ認識 世界を表すベクトル 経路生成 マルチカメラ画像 制 御
• Turing における MLOps • 完全⾃動運転のモデル開発におけるデータ品質 • データ品質を⾼めるために アジェンダ
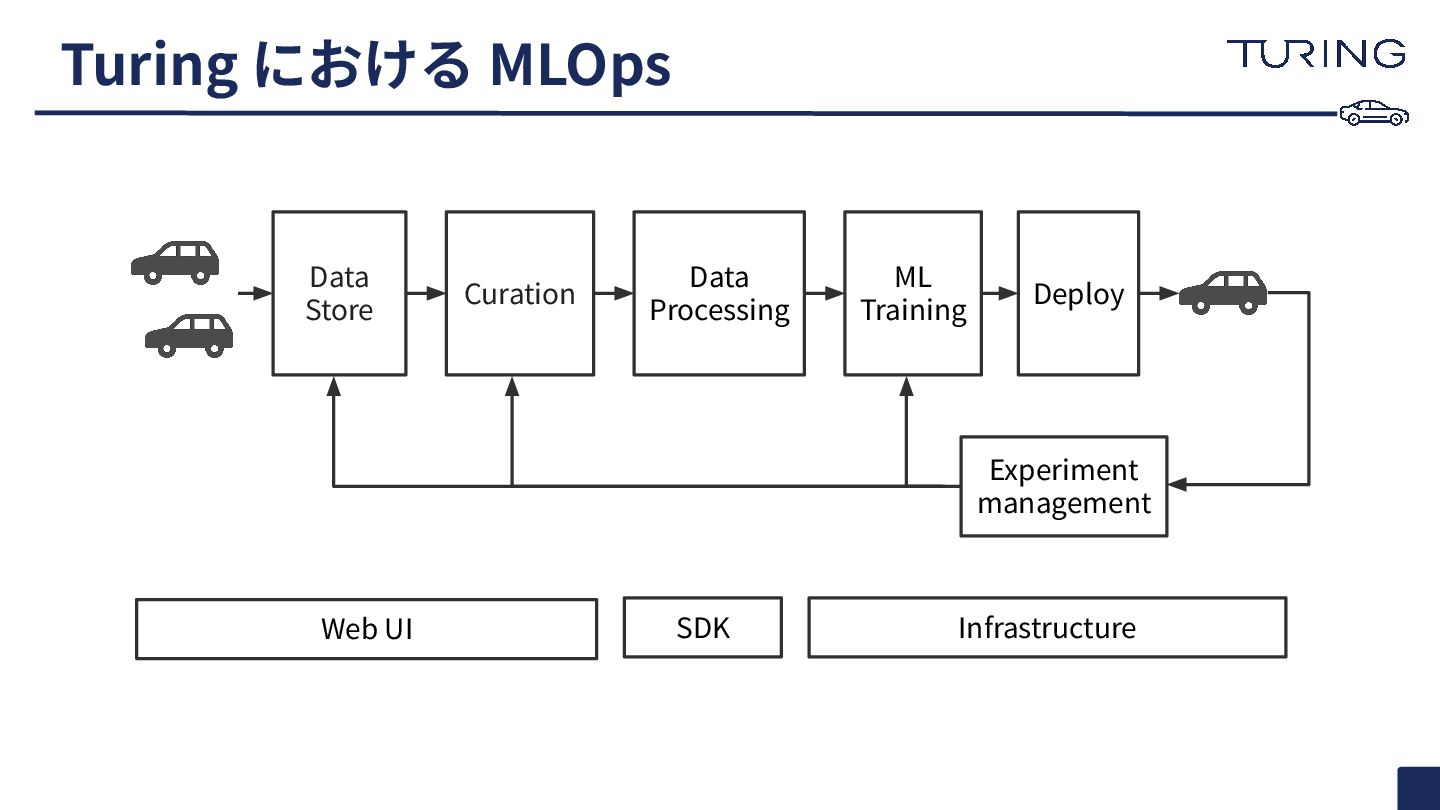
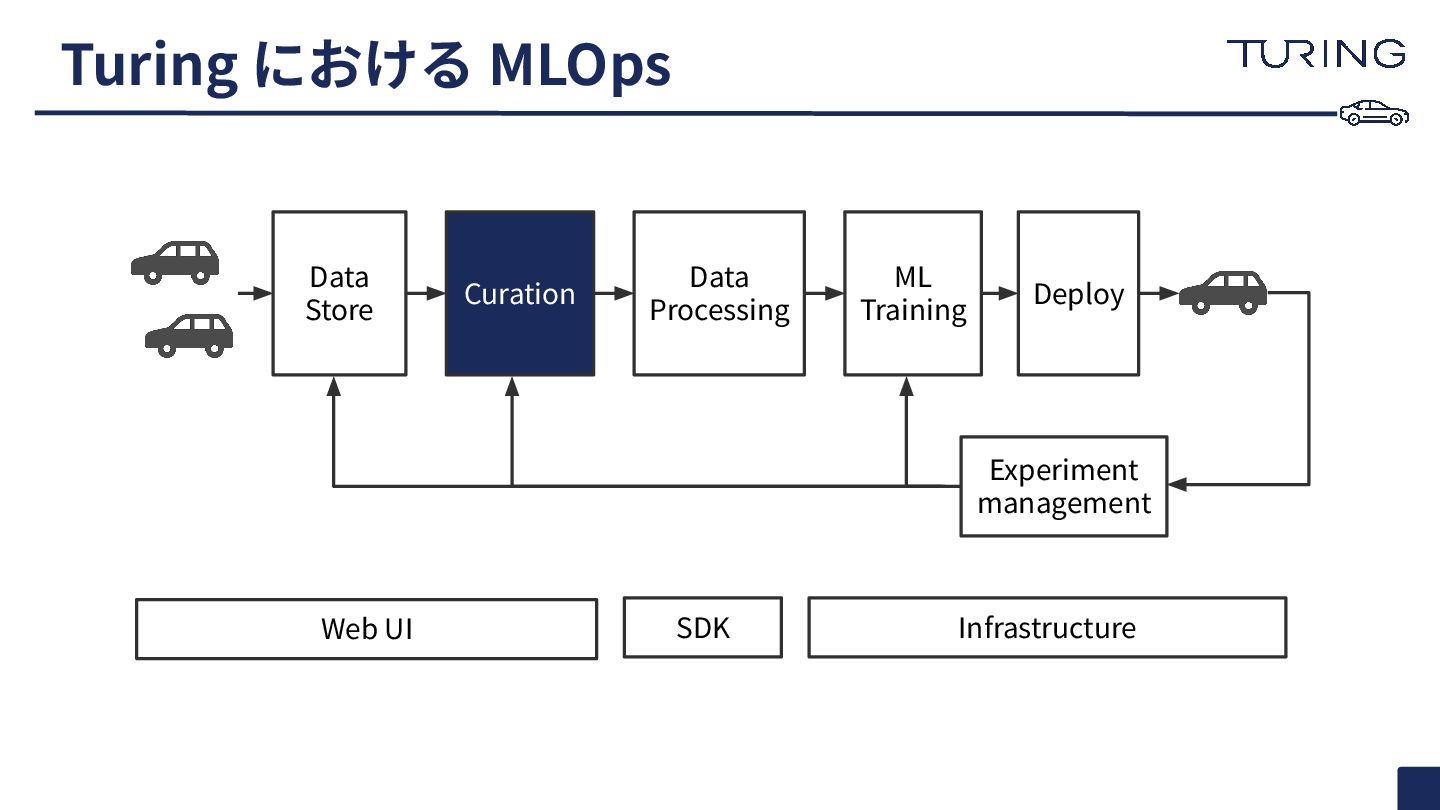
Turing における MLOps
Turing における MLOps Curation Data Processing ML Training Deploy Experiment
management Web UI SDK Infrastructure Data Store
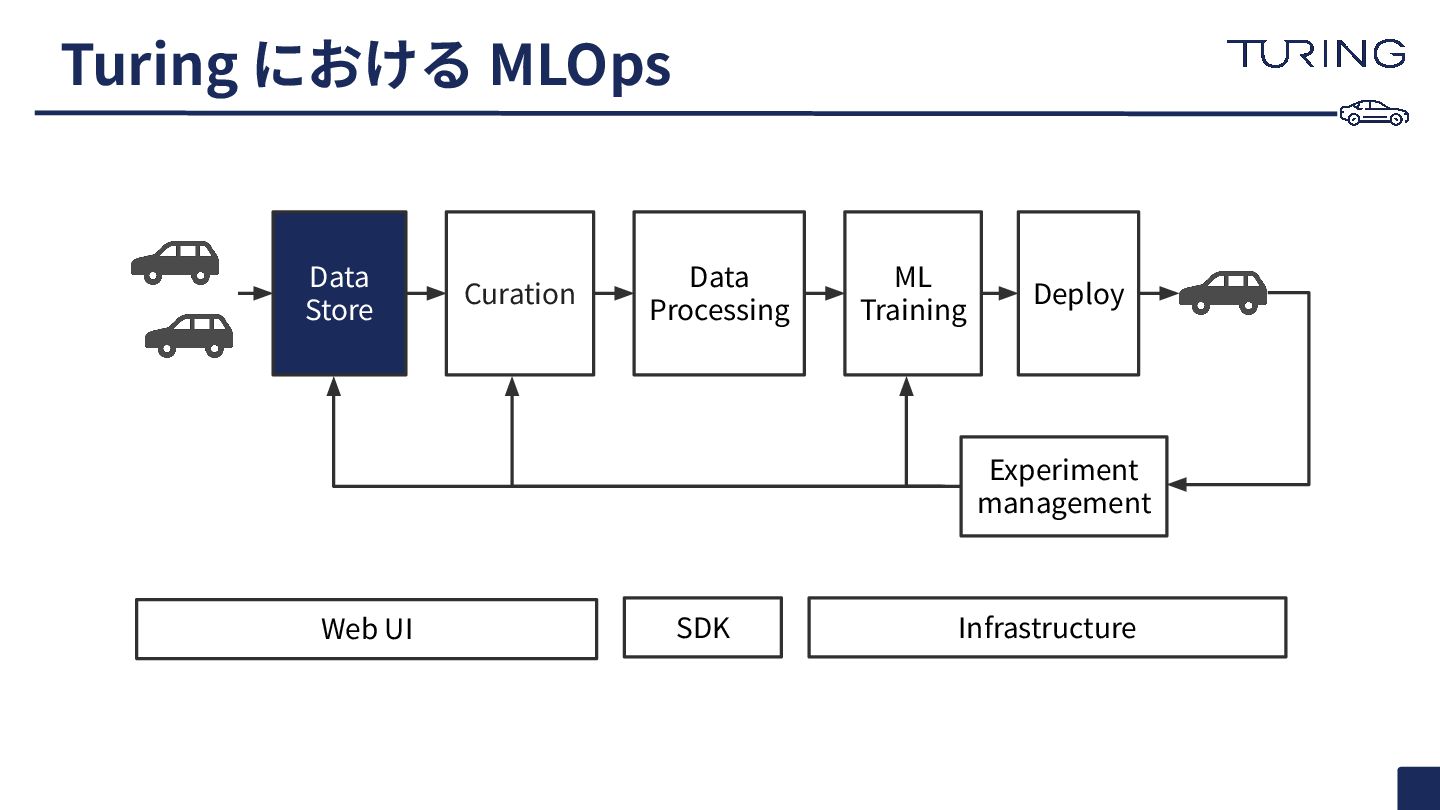
Turing における MLOps Curation Data Processing ML Training Deploy Experiment
management Web UI SDK Infrastructure Data Store
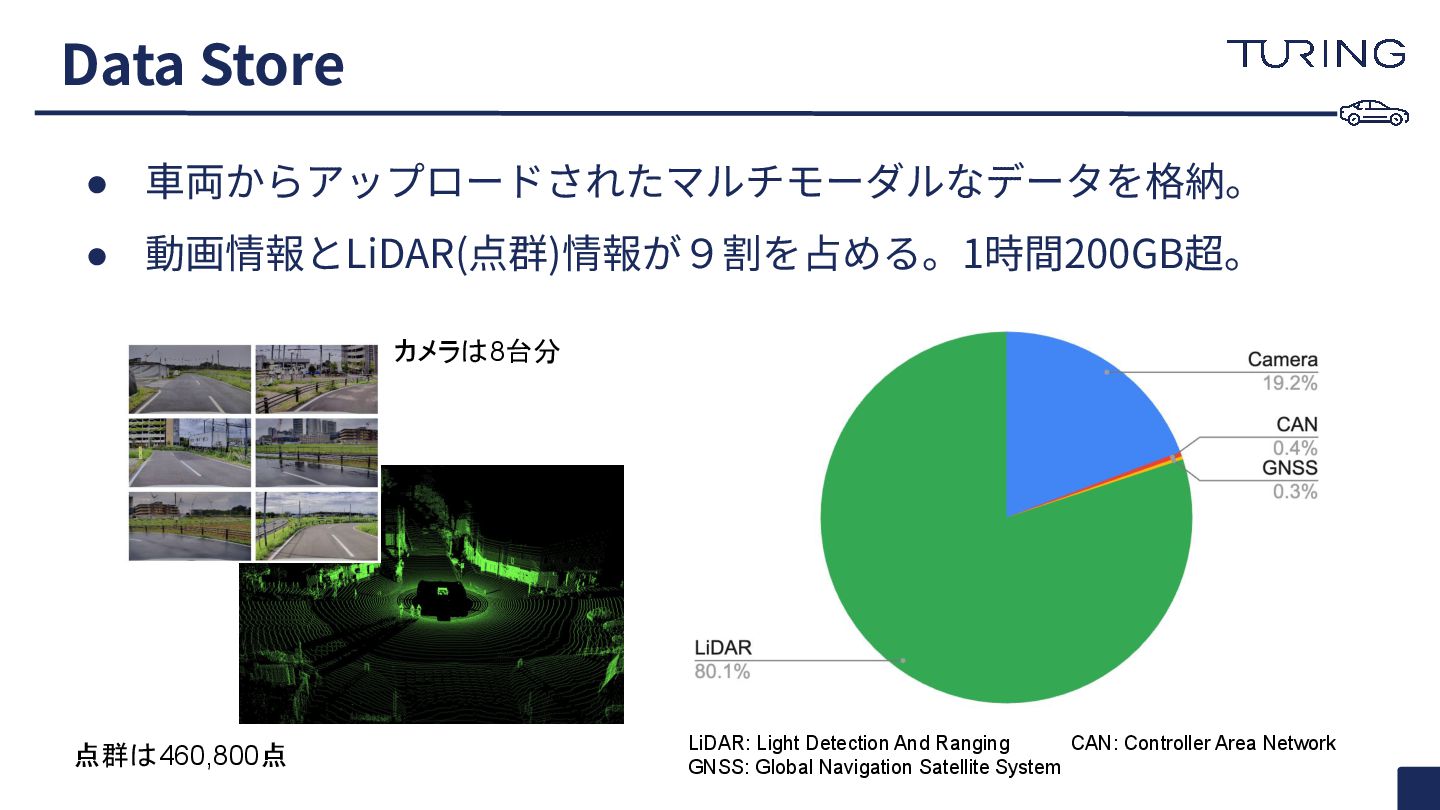
• ⾞両からアップロードされたマルチモーダルなデータを格納。 • 動画情報とLiDAR(点群)情報が9割を占める。1時間200GB超。 Data Store カメラは8台分 点群は460,800点 LiDAR: Light
Detection And Ranging CAN: Controller Area Network GNSS: Global Navigation Satellite System
Turing における MLOps Curation Data Processing ML Training Deploy Experiment
management Web UI SDK Infrastructure Data Store
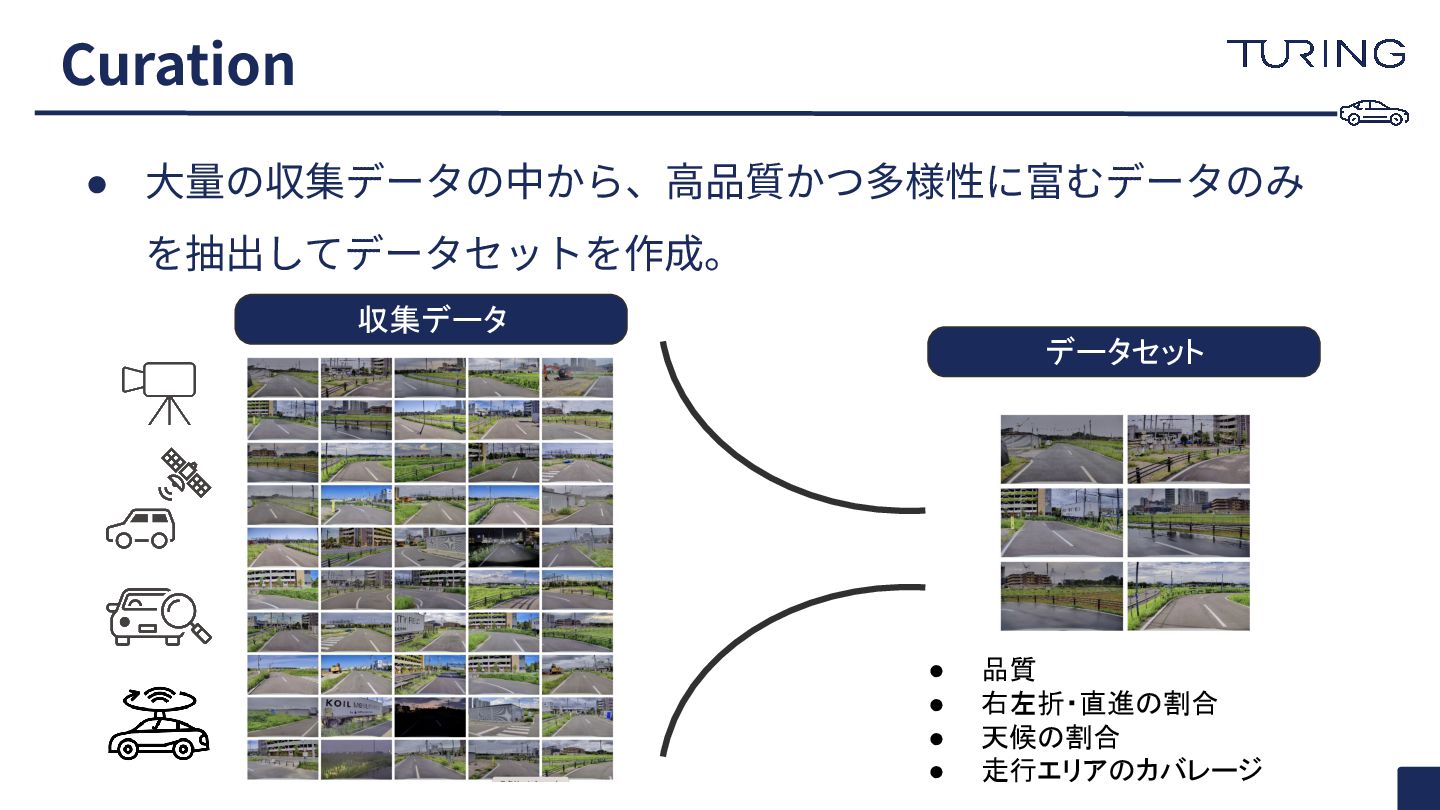
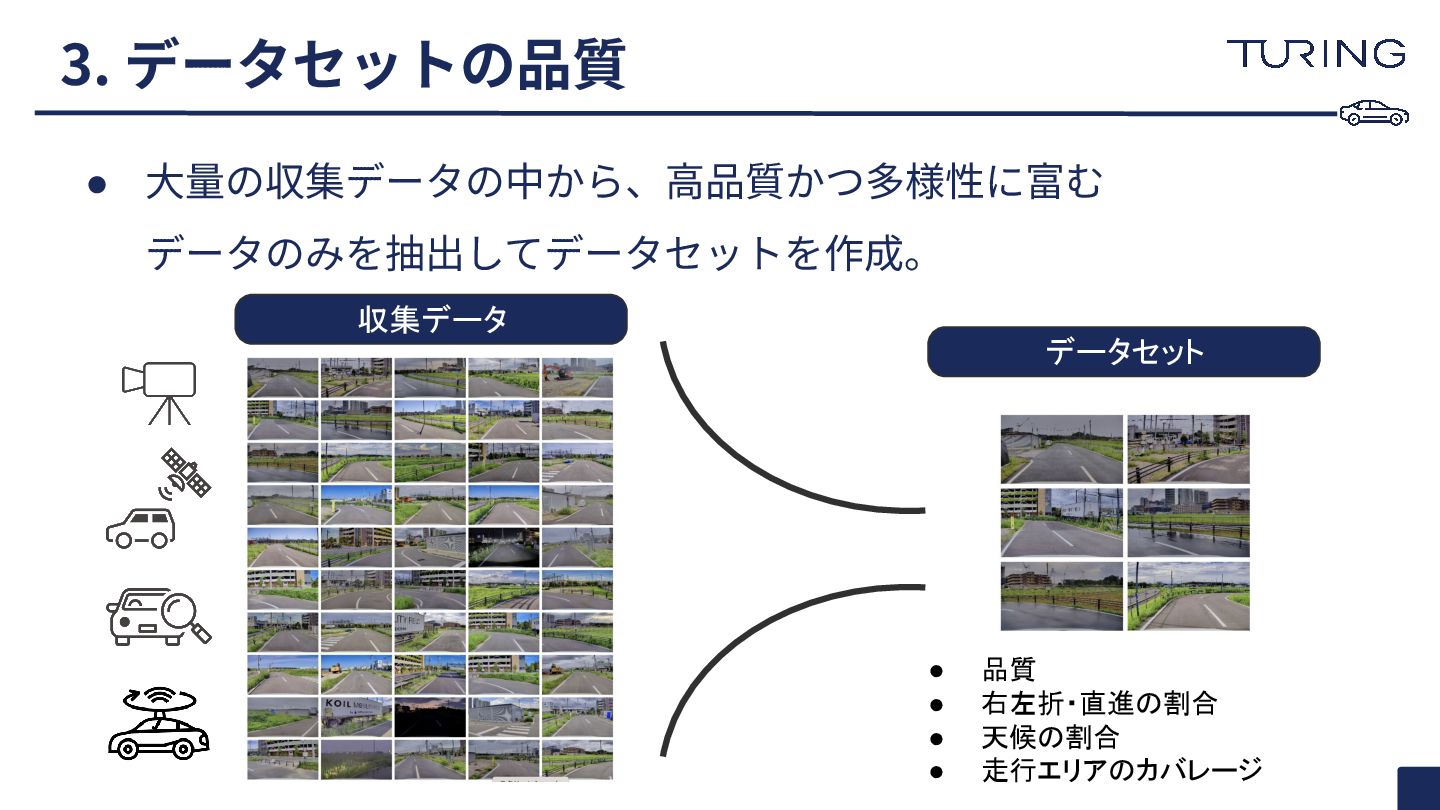
• ⼤量の収集データの中から、⾼品質かつ多様性に富むデータのみ を抽出してデータセットを作成。 Curation • 品質 • 右左折・直進の割合 • 天候の割合
• 走行エリアのカバレージ 収集データ データセット
• ⾛⾏データを⼀定の時間間隔でチャンク化し、各チャンク(シーン と呼ぶ)にメタデータを付与。メタデータを使ってシーンを検索。 Curation # お台場 # 交差点有り # 停⾞中
# 信号機が⾚ # 歩⾏者なし # 先⾏者なし # 昼 # 晴れ
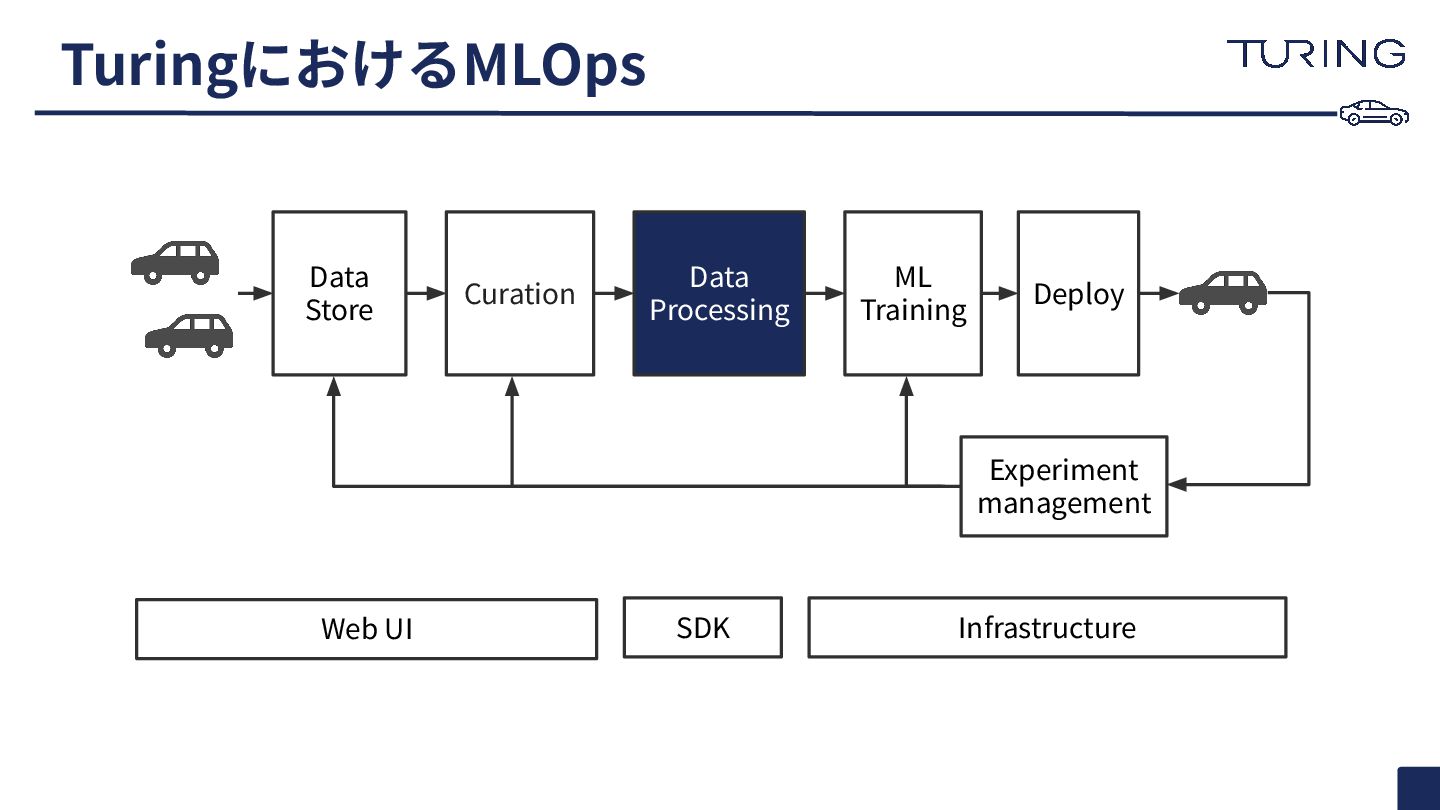
TuringにおけるMLOps Curation Data Processing ML Training Deploy Experiment management Web
UI SDK Infrastructure Data Store
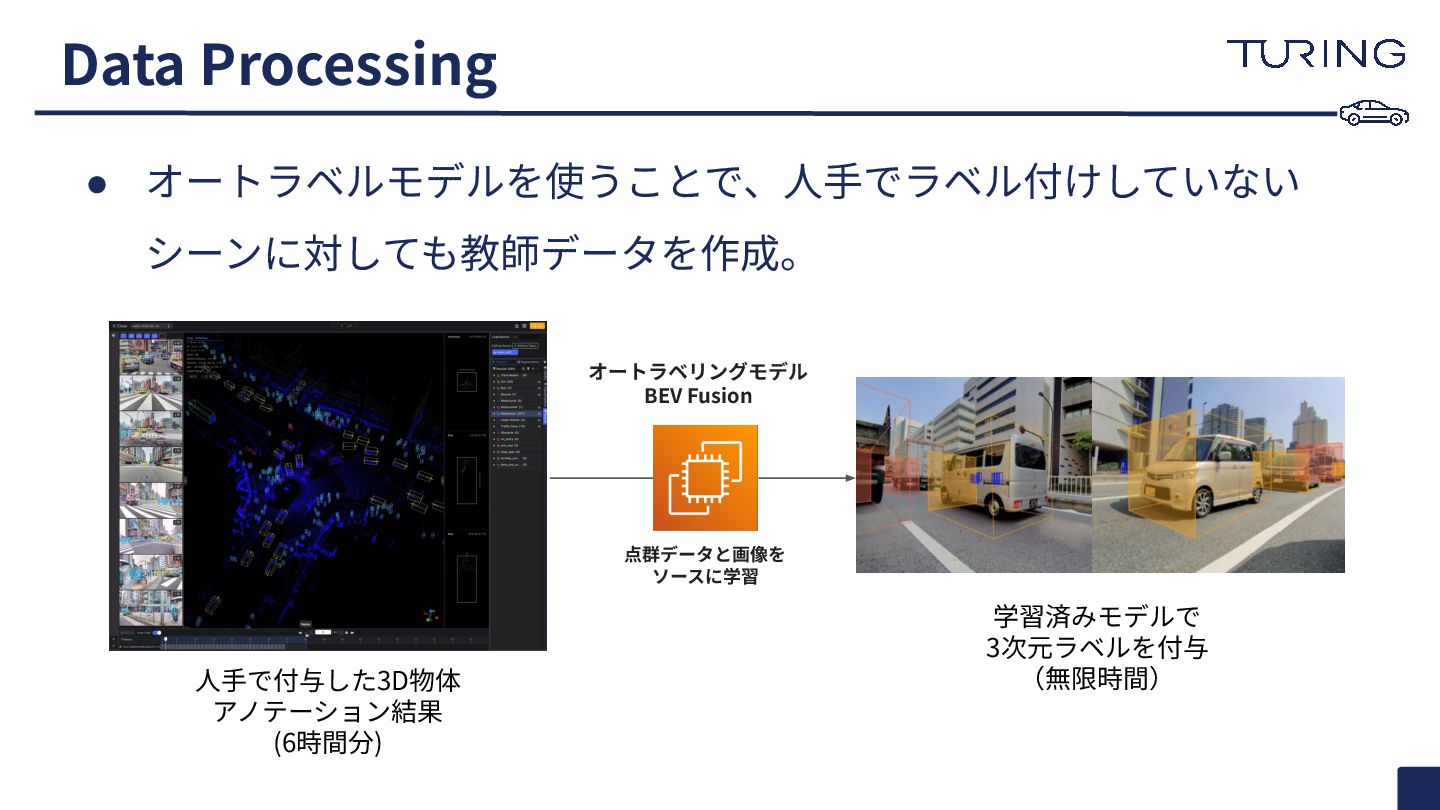
• オートラベルモデルを使うことで、⼈⼿でラベル付けしていない シーンに対しても教師データを作成。 Data Processing ⼈⼿で付与した3D物体 アノテーション結果 (6時間分) 点群データと画像を ソースに学習
学習済みモデルで 3次元ラベルを付与 (無限時間) オートラベリングモデル BEV Fusion
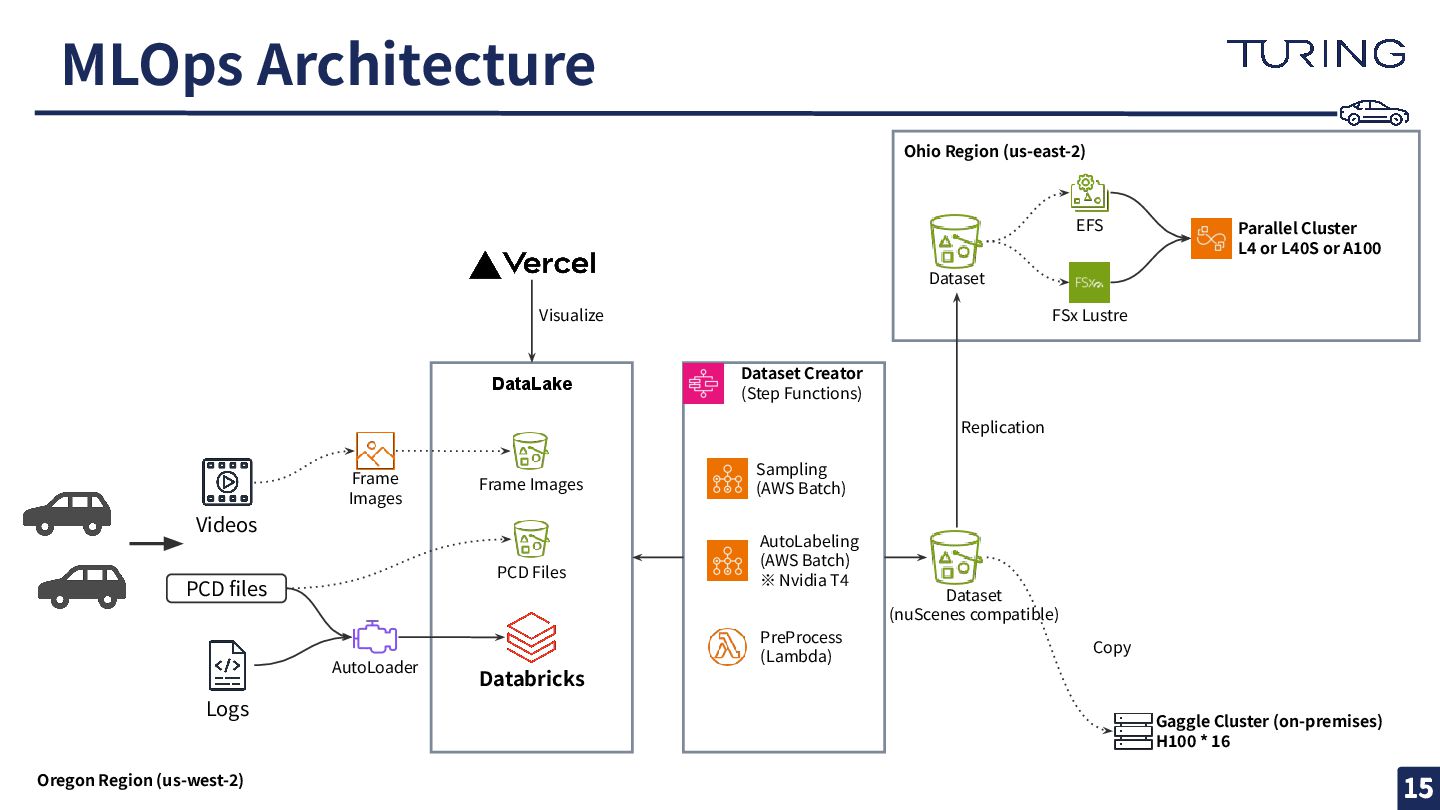
Ohio Region (us-east-2) DataLake MLOps Architecture 15 Videos Logs Dataset
Creator (Step Functions) PCD files Sampling (AWS Batch) AutoLabeling (AWS Batch) ※ Nvidia T4 Dataset (nuScenes compatible) Parallel Cluster L4 or L40S or A100 Gaggle Cluster (on-premises) H100 * 16 15 AutoLoader Databricks Frame Images PCD Files Frame Images PreProcess (Lambda) FSx Lustre EFS Dataset Copy Replication Visualize Oregon Region (us-west-2)
• データ処理エンジンが Spark ◦ ⾃動運転のモデル開発は何が起こるか分からない ◦ 慣れ親しんだ Python で処理を⾃⼰拡張できることが最重要 •
組み込み済みの Notebook ◦ データの可視化、検証が Python から簡単に⾏える Why Databricks ?
完全⾃動運転のモデル開発におけるデータ品質
• End to End モデルの学習には、品質の「良い」データが必要。 E2E モデルの学習には良いデータが必要 • 最近のモデル(特にTransformerベース)はData hungry。
• マルチモーダル特有の課題(センサ間の位置関係の精度) • センサーデータ特有の課題(ノイズ、キャリブレーション) • Imitation Learningの課題(エキスパートデータの質) • 様々な交通条件のデータが必要 (場所、天候、交通エージェントの有無) 量 質 多様 性
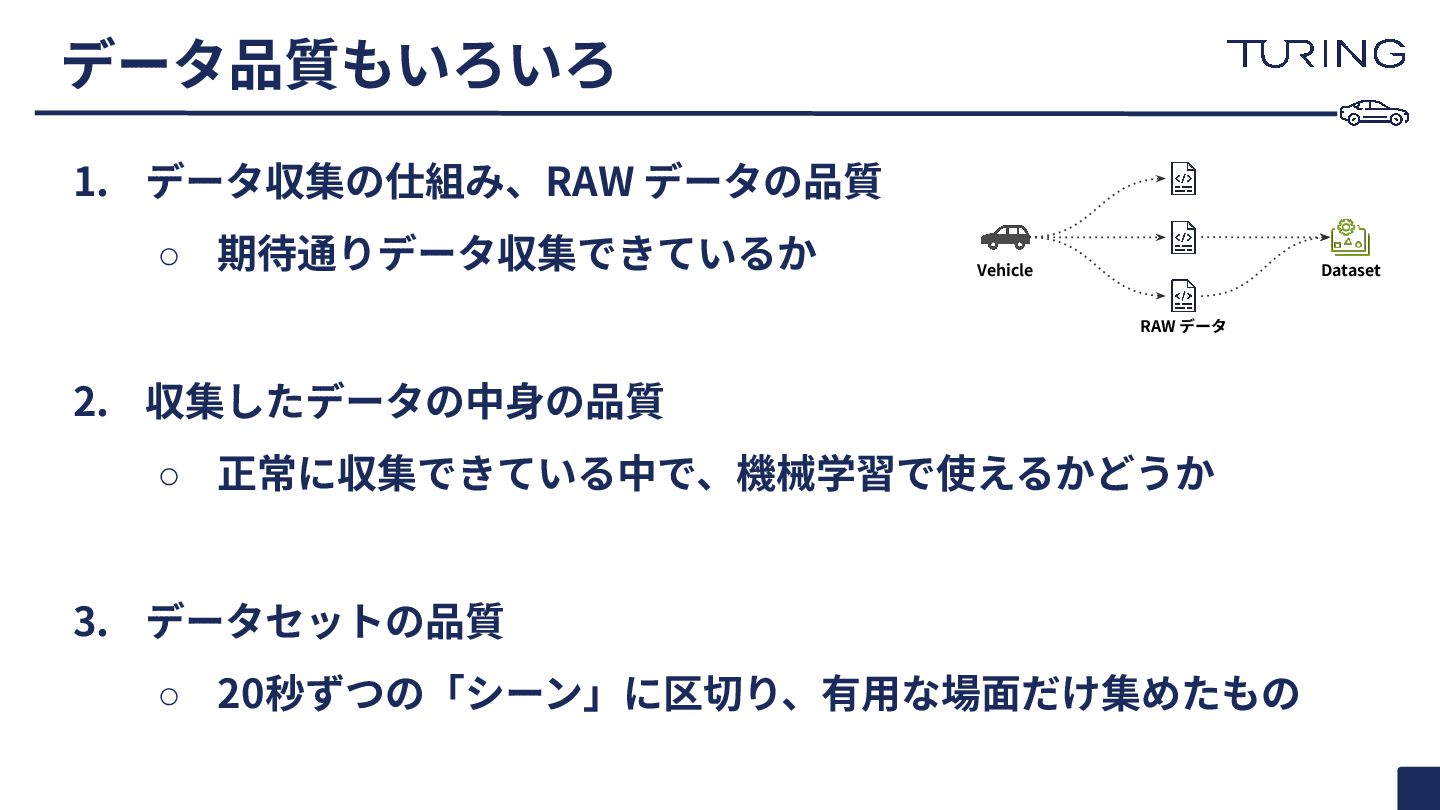
1. データ収集の仕組み、RAW データの品質 ◦ 期待通りデータ収集できているか 2. 収集したデータの中⾝の品質 ◦ 正常に収集できている中で、機械学習で使えるかどうか 3.
データセットの品質 ◦ 20秒ずつの「シーン」に区切り、有⽤な場⾯だけ集めたもの データ品質もいろいろ RAW データ Dataset Vehicle
• 最初は、データをランダムにピックアップして、 どのようなエラーが発⽣しているかを⾒ていった。 1. データ収集の仕組み、RAW データの品質 データバリデーション大会 (イメージ)
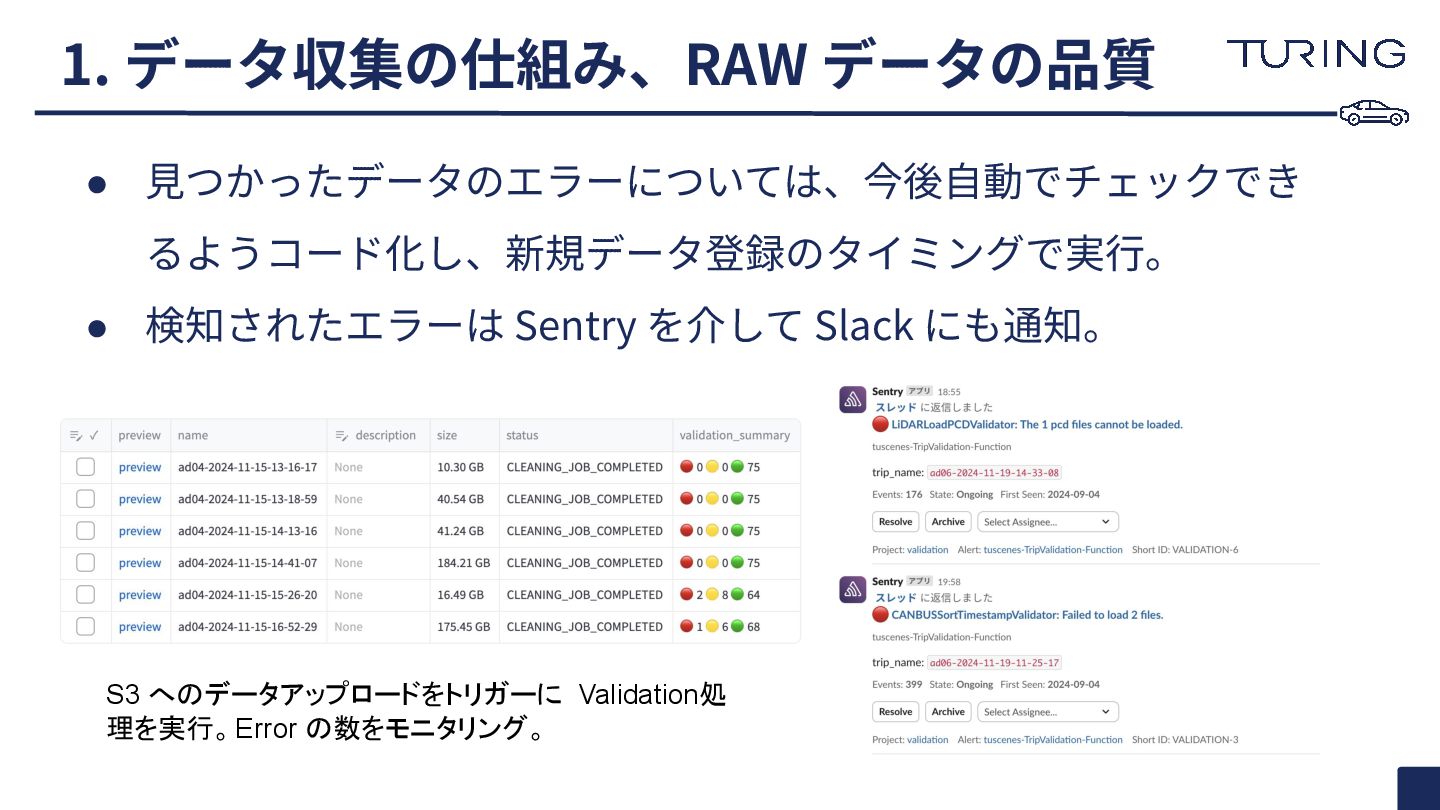
• ⾒つかったデータのエラーについては、今後⾃動でチェックでき るようコード化し、新規データ登録のタイミングで実⾏。 • 検知されたエラーは Sentry を介して Slack にも通知。 1.
データ収集の仕組み、RAW データの品質 S3 へのデータアップロードをトリガーに Validation処 理を実行。Error の数をモニタリング。
• 各センサー間のデータの時刻同期 ◦ カメラ*8, LiDAR, GNSS(GPS), CAN(⾞両データ) ◦ マイクロ秒レベルで同期が必要 •
センサー⾃体のデータ精度 ◦ 位置情報などの精度 2. 収集したデータの中⾝の品質
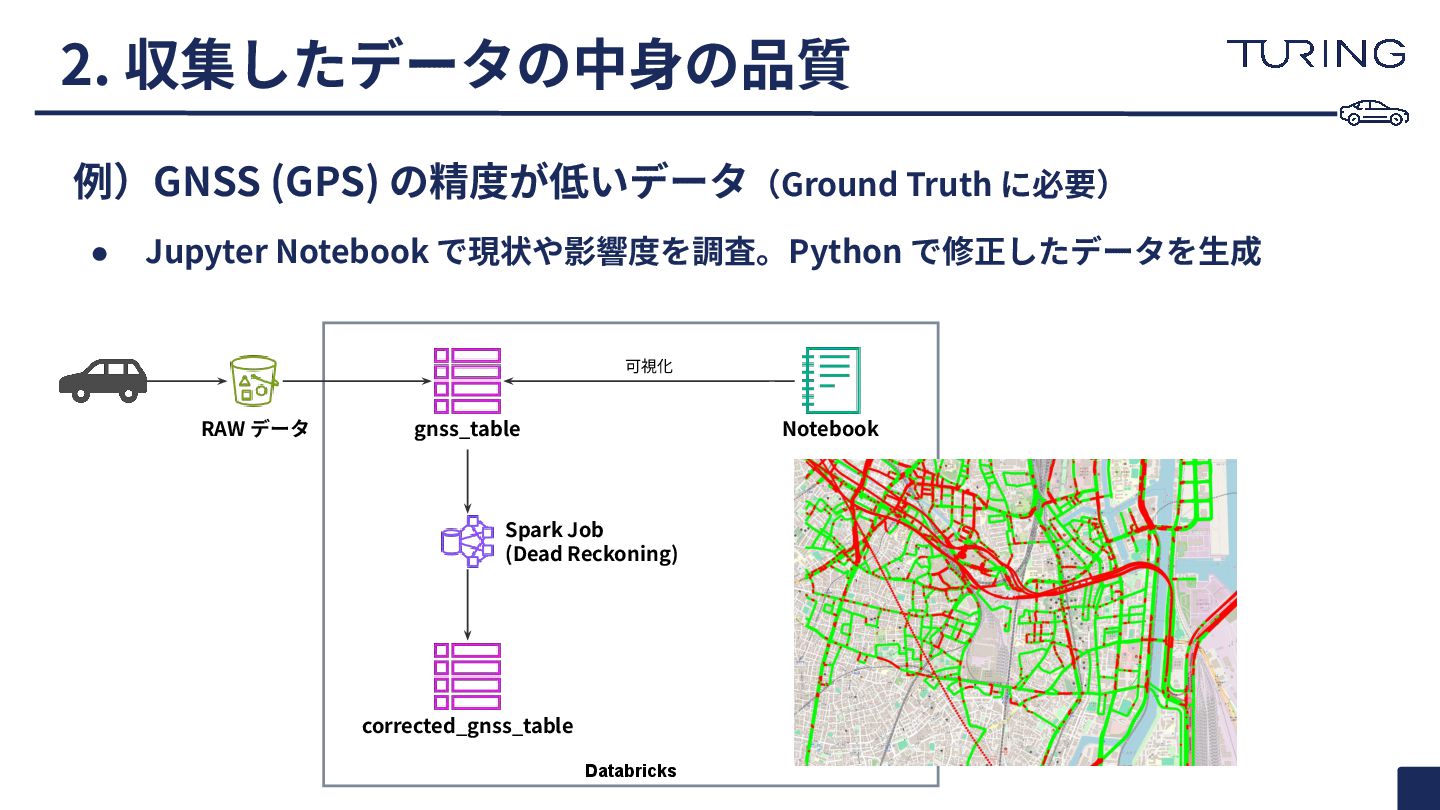
Databricks 例)GNSS (GPS) の精度が低いデータ(Ground Truth に必要) • Jupyter Notebook で現状や影響度を調査。Python
で修正したデータを⽣成 2. 収集したデータの中⾝の品質 gnss_table corrected_gnss_table Notebook 可視化 Spark Job (Dead Reckoning) RAW データ
• ⼤量の収集データの中から、⾼品質かつ多様性に富む データのみを抽出してデータセットを作成。 3. データセットの品質 • 品質 • 右左折・直進の割合 •
天候の割合 • 走行エリアのカバレージ 収集データ データセット
• ⾛⾏データを⼀定の時間間隔(20秒)でチャンク化し、 各チャンクにメタデータを付与。メタデータを使って検索。 3. データセットの品質 # お台場 # 交差点有り #
停⾞中 # 信号機が⾚ # 歩⾏者なし # 先⾏者なし # 昼 # 晴れ
• 20秒のチャンク(シーン)のデータの有⽤性 • メタデータを使ってシーン検索をして作成した、データセット内の ⽐率の確認やコントロールはこれから。 ◦ 単純な右左折の⽐率ではなく、「市街地の分岐での⾞線変更」など、 ⾛⾏シチュエーション細分化して把握し、多様性を⾼める必要がある。 3. データセットの品質
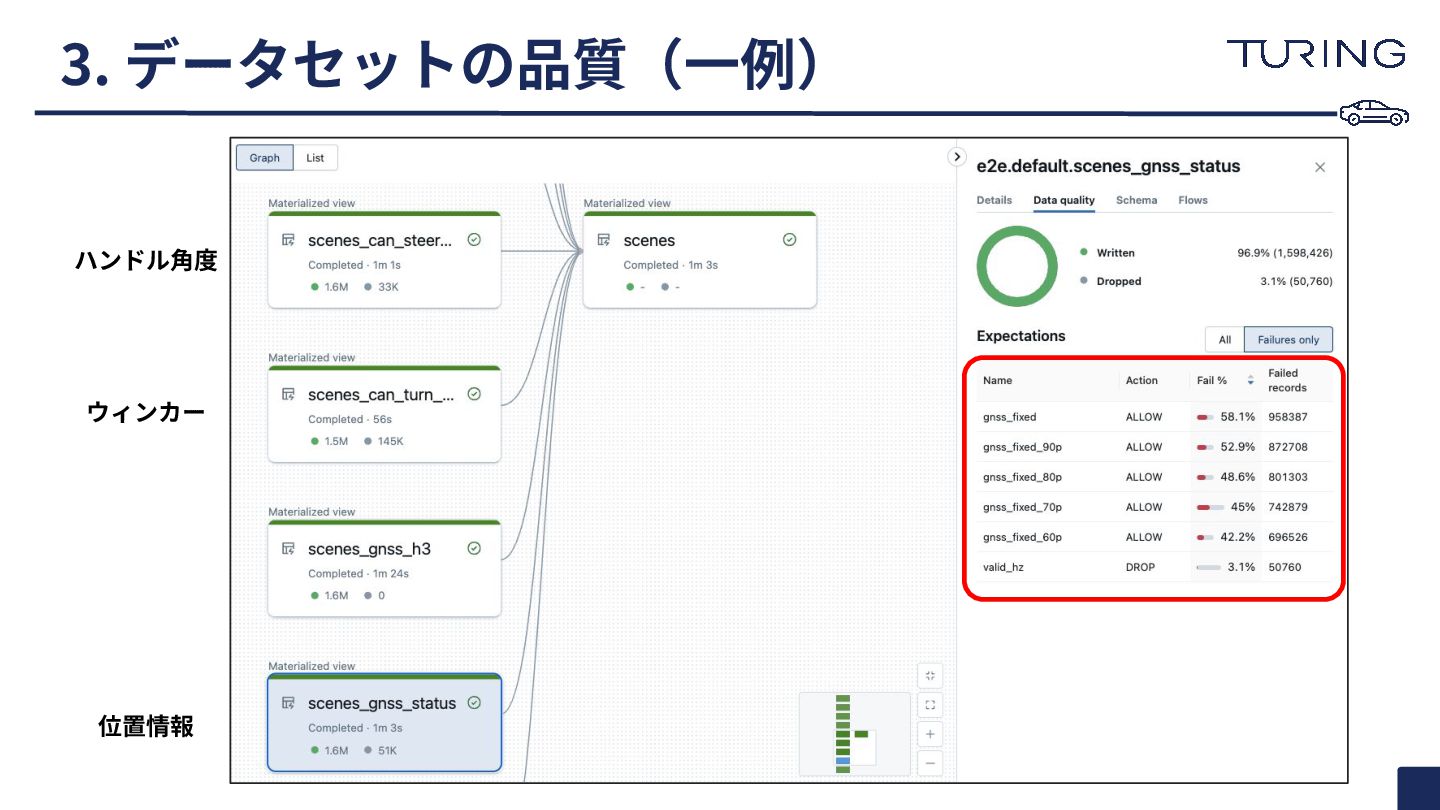
3. データセットの品質(⼀例) 位置情報 ウィンカー ハンドル⾓度
まとめ
• 変化や不測の事態に対応できるようにする ◦ 問題は後で発覚する ◦ ⾃由度⾼く、再処理できる環境を⽤意する • 可視化が⼤事 ◦ ⼀⾒するだけでは気付けない問題も多い
◦ マルチモーダルな情報を「いい感じ」に 可視化できる⽅法を持っておく必要がある データ品質を⾼めるために
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}