Monitoring unknown unknowns with machine intelligence - DevOpsDays TLV 2017
Gave this talk at DevOpsDays Tel-Aviv 2017. A few real-world examples where not knowing what you don’t know led to massive outages and service disruptions. This talk has some more technical examples in Python.
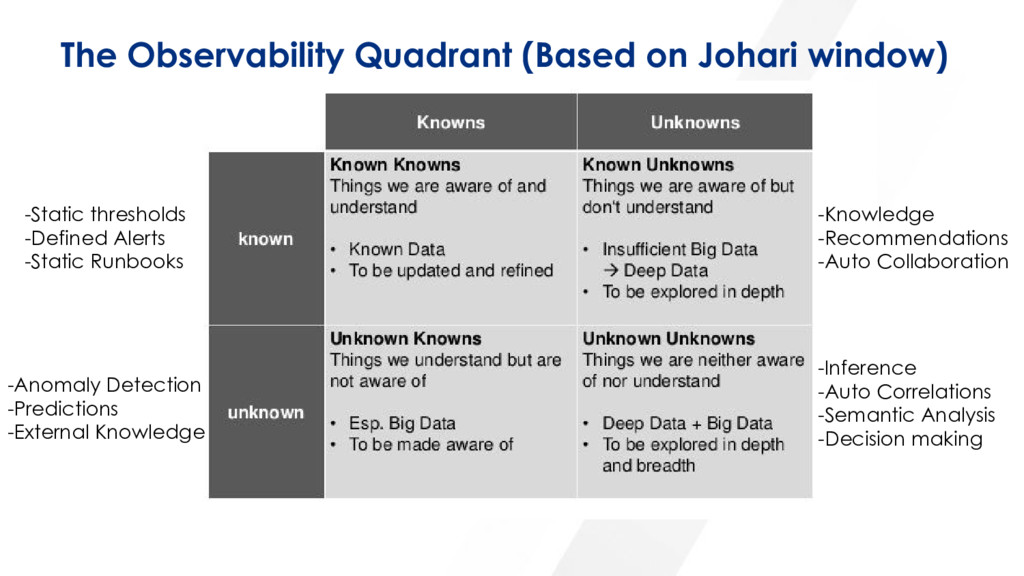
debuggable and understandable @mipsytipsy Do you really know what to observe? Instrumentation - mostly Developer driven What is the output? Dashboard? Exploration tool?
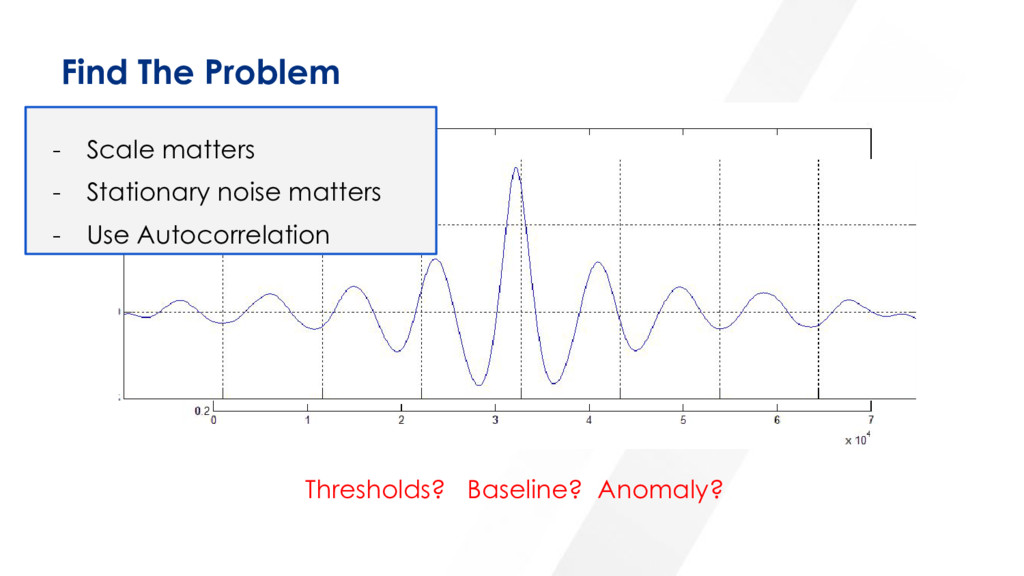
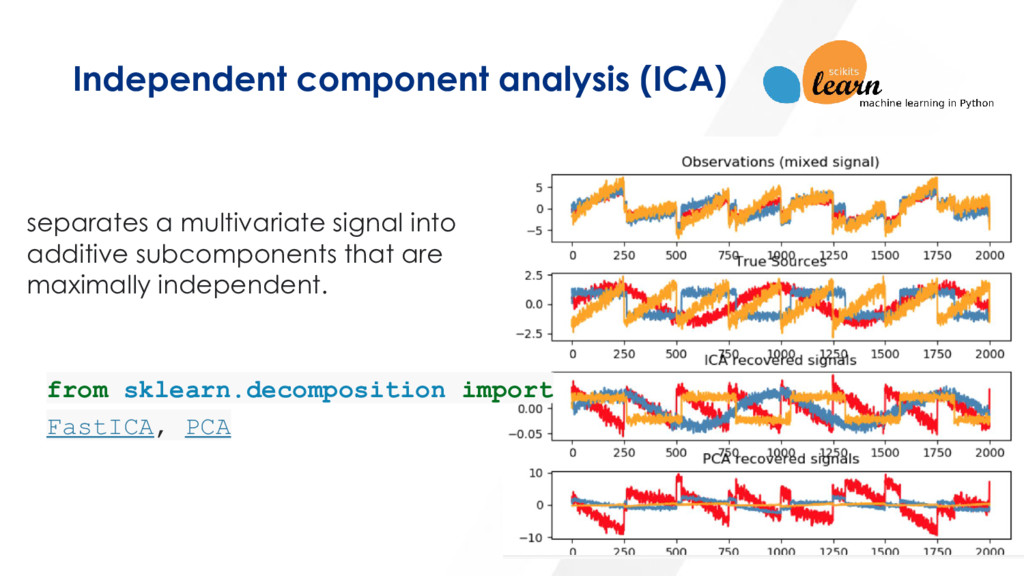
it fast and handle huge amounts in real-time Automate and adapt Anomaly Detection Apply Semantic text similarities to find patterns (Information Retrieval) Apply auto correlation models Evolve and adapt (overtime) based on human interaction
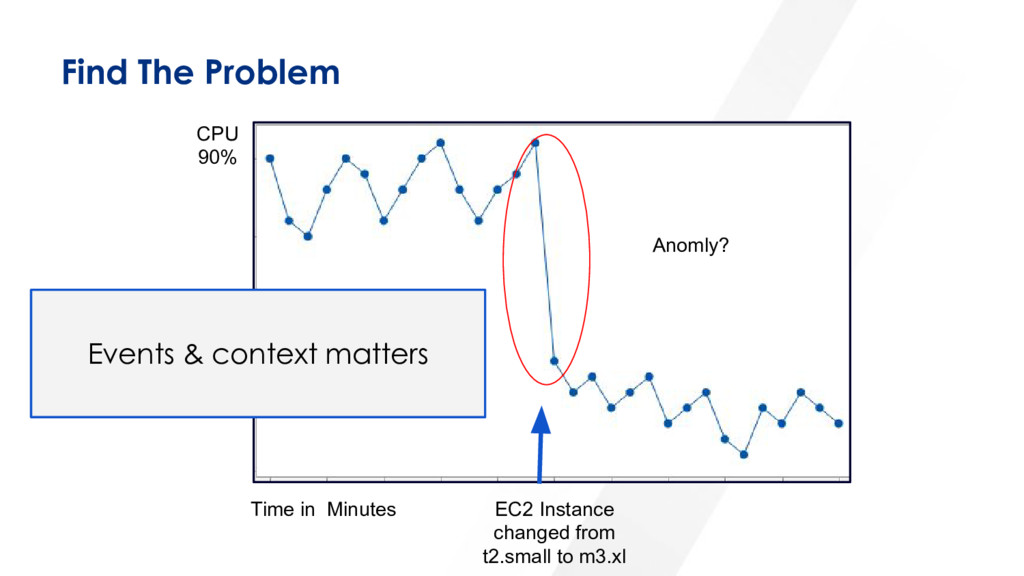
Events enrichments, symptoms detection and inference Automatic Outlier Detection Automatic Correlation Get closer to the Control Theory mathematical definition
- Events are agnostic. Can represent logs, stack trace, metric, user action, HTTP event, etc. - Every event should have a set of common fields as well as optional key/value attributes Get a Common Schema Use Common Schema
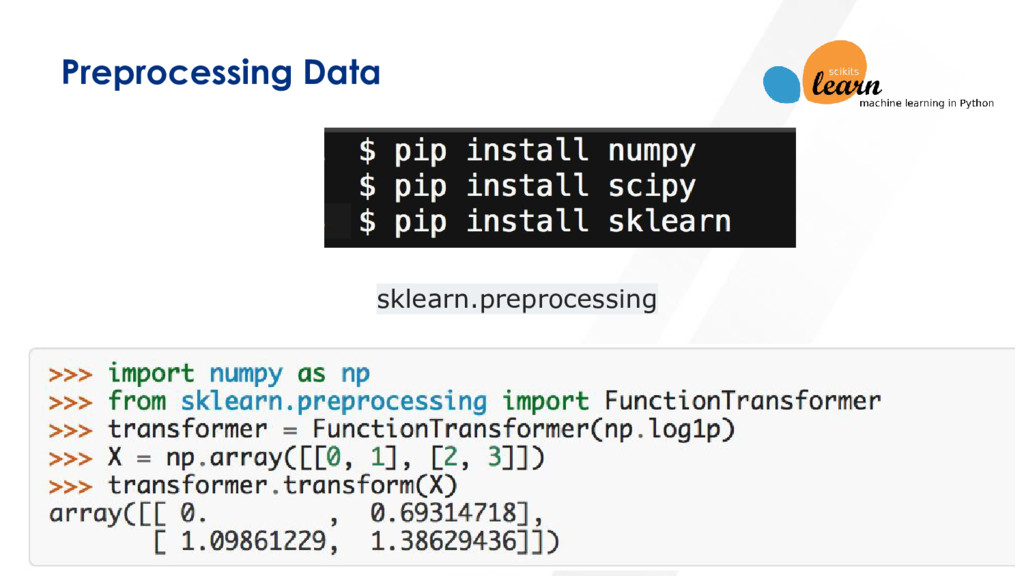
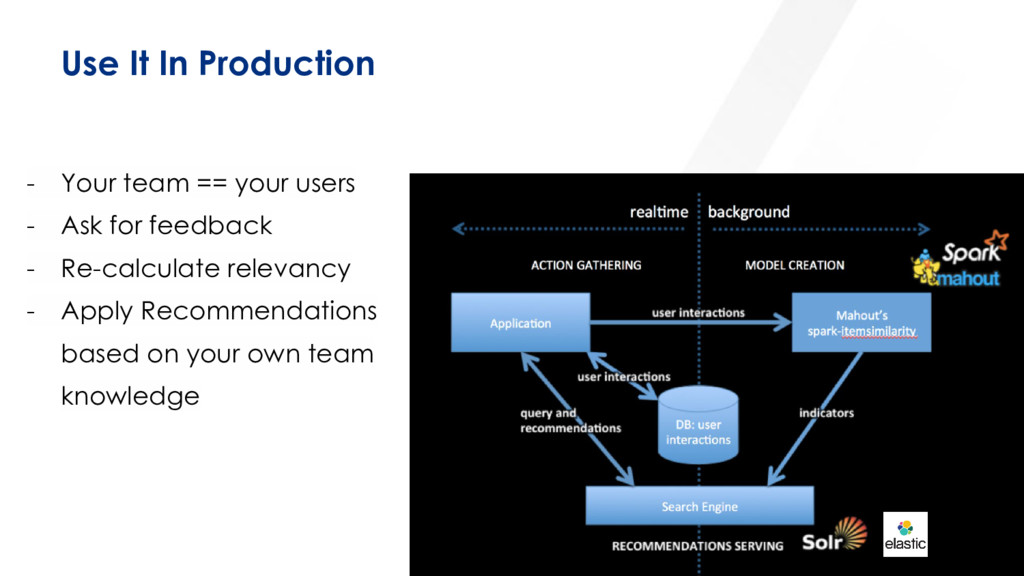
Choose your logic and start run it across your data (schema) Apply similarity checks to strings first (TF-IDF, BM25, Fuzzy, other classifiers) Look into correlations, start with simple obvious ones, before building classifiers (Unsupervised/Semi-supervised learning is much more relevant overall) Build your prediction models on time series data first. (Statistics has solid models) Time and context are dimensions you will be able to start addressing Best Practices
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}