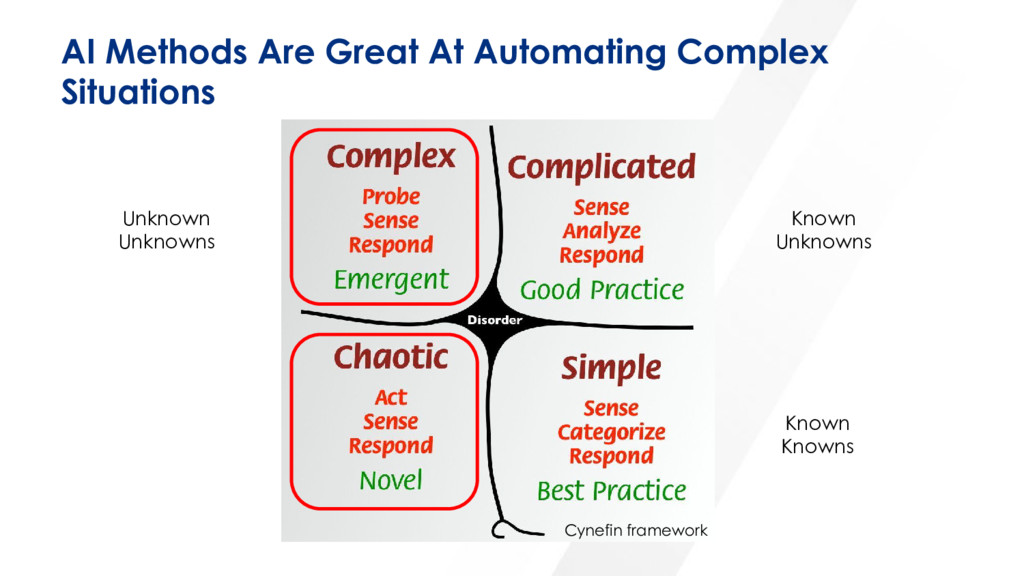
Gave this talk at AllDaysDevOps 2017. A few real-world examples where not knowing what you don’t know led to massive outages and service disruptions. How despite the fact that modern DevOps teams have multiple monitoring tools, hundreds of metrics instrumented and are capturing billions of data points…downtime still happens. How about instead of implementing more monitoring, we bring forward a future where DevOps teams can augment their existing tooling with AI and machine learning to draw richer correlations across events, metrics and logs to surface insights about threats to uptime that aren’t even being monitored. Or put another way, how DevOps teams can get closer to a state of “known knowns!”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
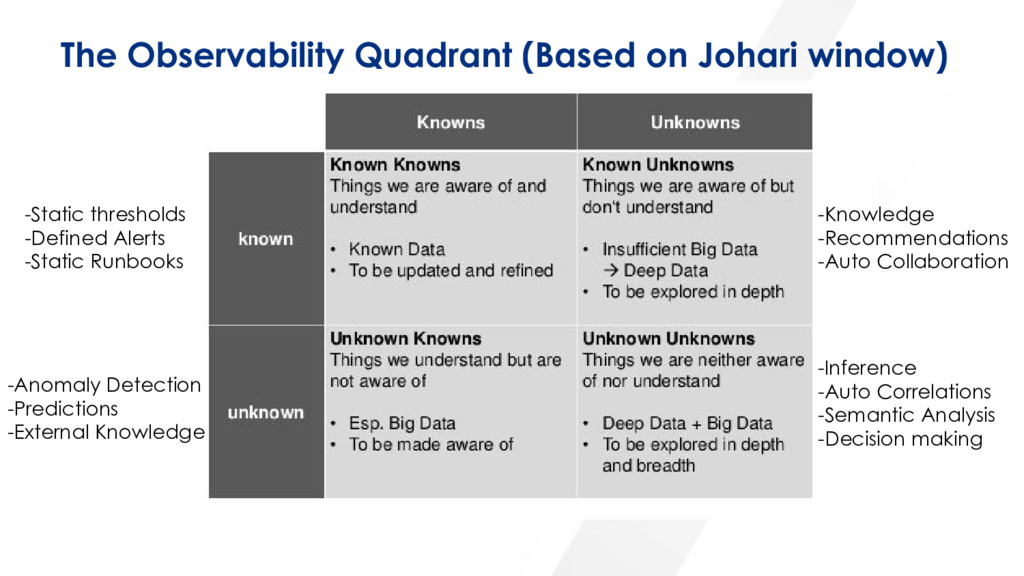{kind=link}
{kind=link}
{kind=link}
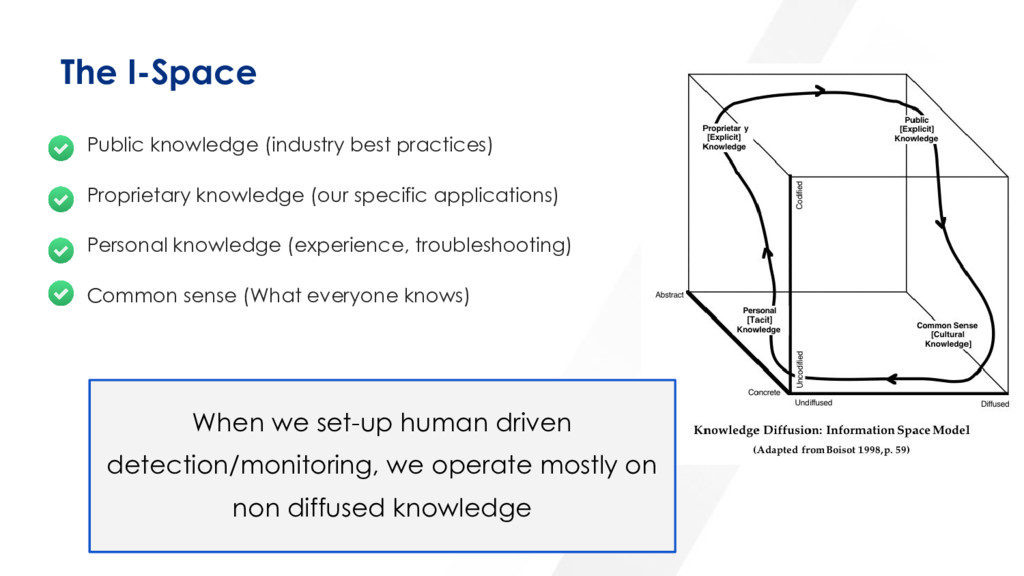{kind=link}
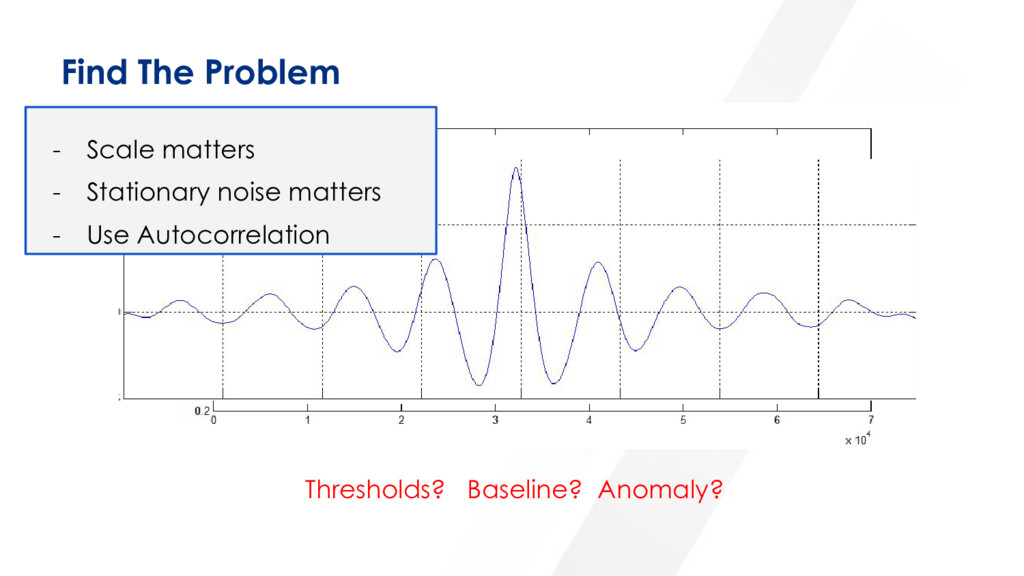{kind=link}
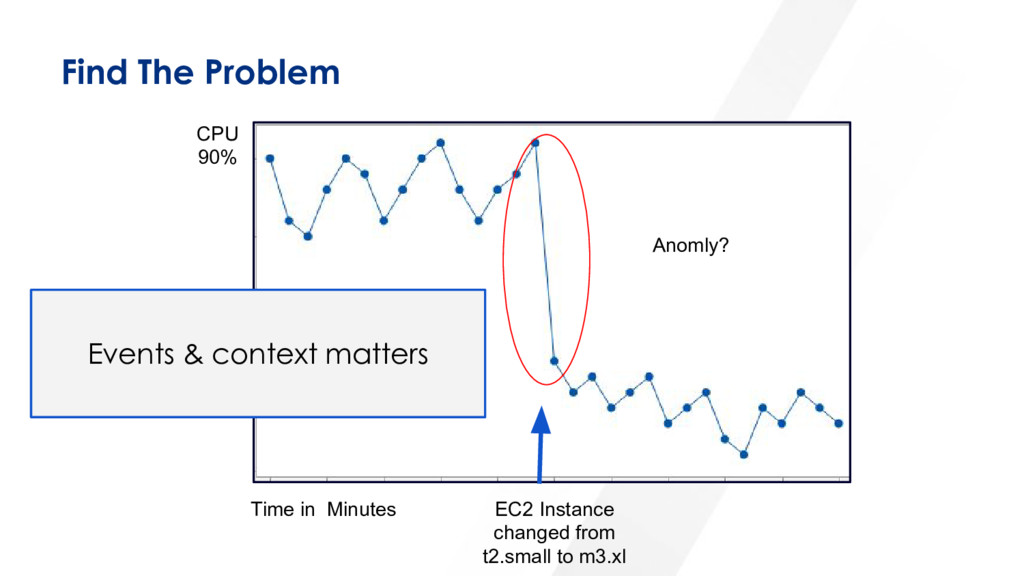{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}