– Japan openSUSE User group (Maid for miscellaneous tasks?) – Tokaido Linux User Group Tastes: Writing a nobel Works: Building an AI in a research lab (Federated Learning)
conversion on openSUSE 2. Implementation of conversion algorithm using LLM 3. Creating an OSS Kana-Kanji conversion dictionary using word embedding 4. Collecting and preserving corpus using open data 5. Future operation plans using federated learning 6. Development of input methods that run on ibus on openSUSE ...15 minutes??? (Is it possible?)
and both Hiragana and Kanji are used when writing example) I am Masahiko Hashimoto Hiragana : わたしははしもとまさひこです ←Keyboard input Kanji & Hiragana: 私は橋本雅彦です Input from the keyboard is done in hiragana, which is then converted to Hiragana and Kanji
Mozc are used for Kana-Kanji conversion in openSUSE • Mozc: Kana-Kanji conversion engine released by Google as OSS in 2010 • IBus: Accepts input from the keyboard and passes it to Mozc Both are essential for kana-kanji conversion, but...
Mozc are used for Kana-Kanji conversion in openSUSE • Mozc: Kana-Kanji conversion engine released by Google as OSS in 2010 → 2010?? 14 years ago??? • IBus: Accepts input from the keyboard and passes it to Mozc → … (I won't touch it today) Both are essential for kana-kanji conversion, but...
operation of a generative AI such as LLM is to predict the next word Approach: Is it possible to use this next word prediction for kana-kanji conversion?
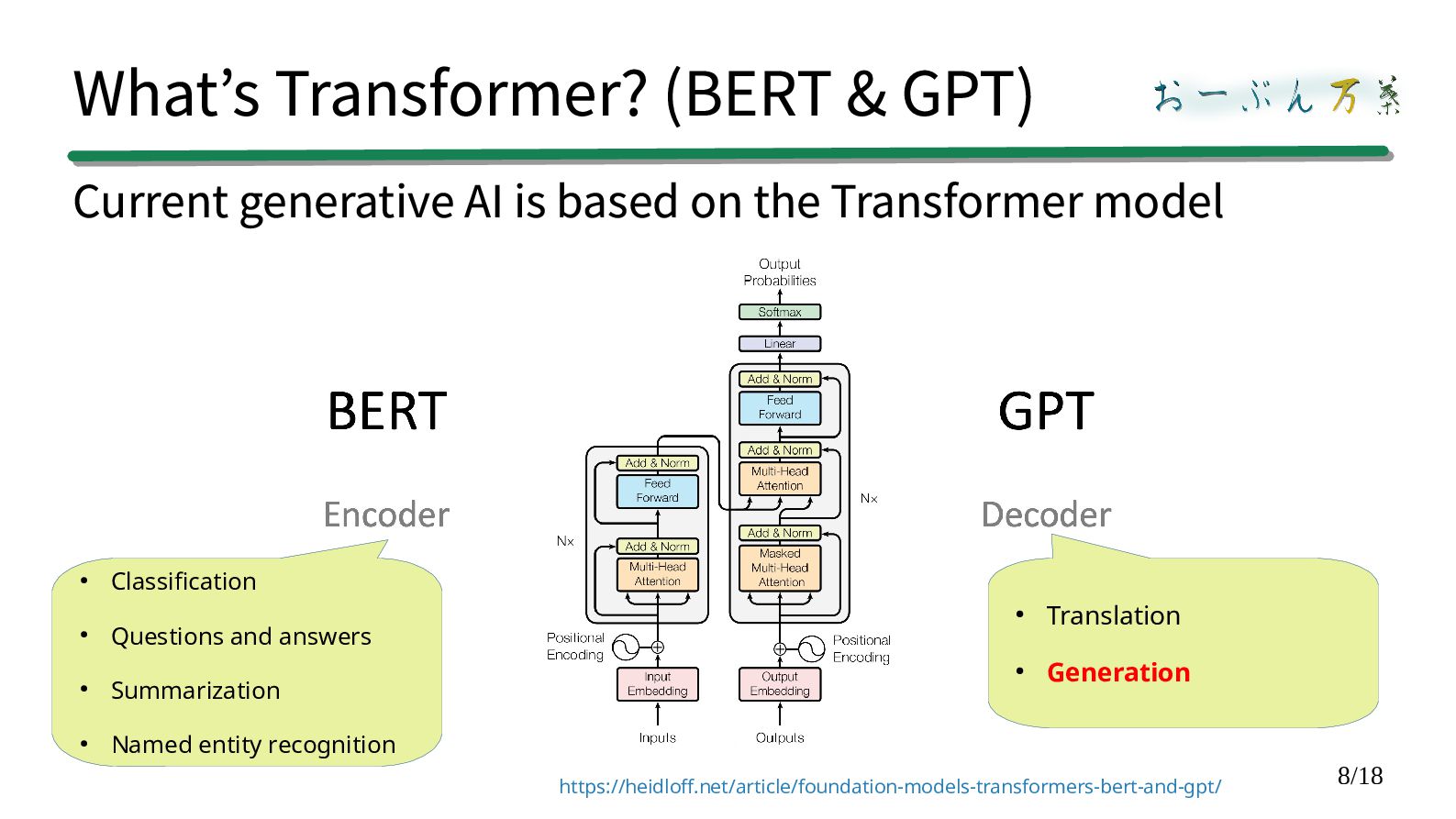
based on the Transformer model https://heidloff.net/article/foundation-models-transformers-bert-and-gpt/ • Classification • Questions and answers • Summarization • Named entity recognition • Translation • Generation
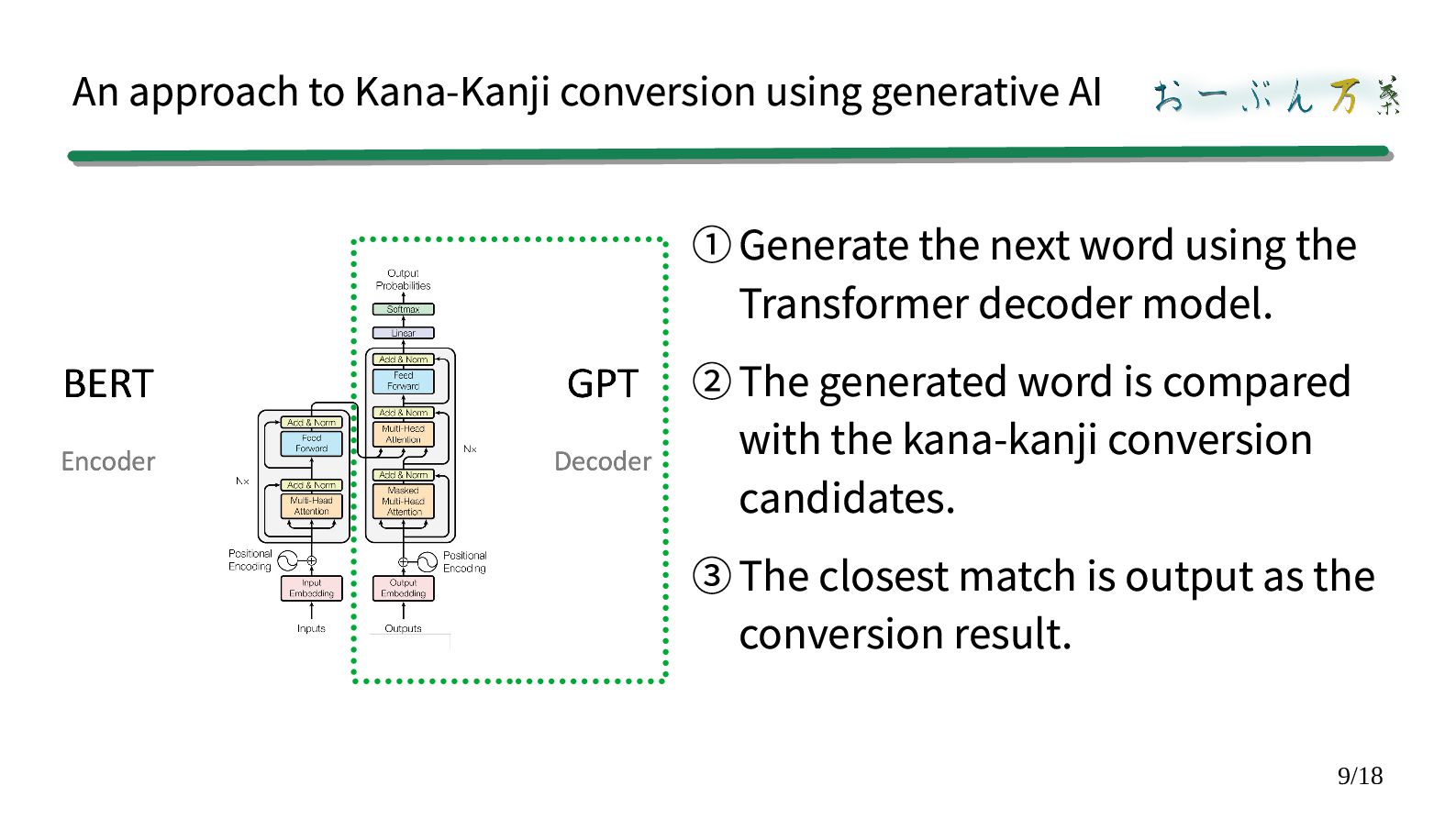
the next word using the Transformer decoder model. ②The generated word is compared with the kana-kanji conversion candidates. ③The closest match is output as the conversion result.
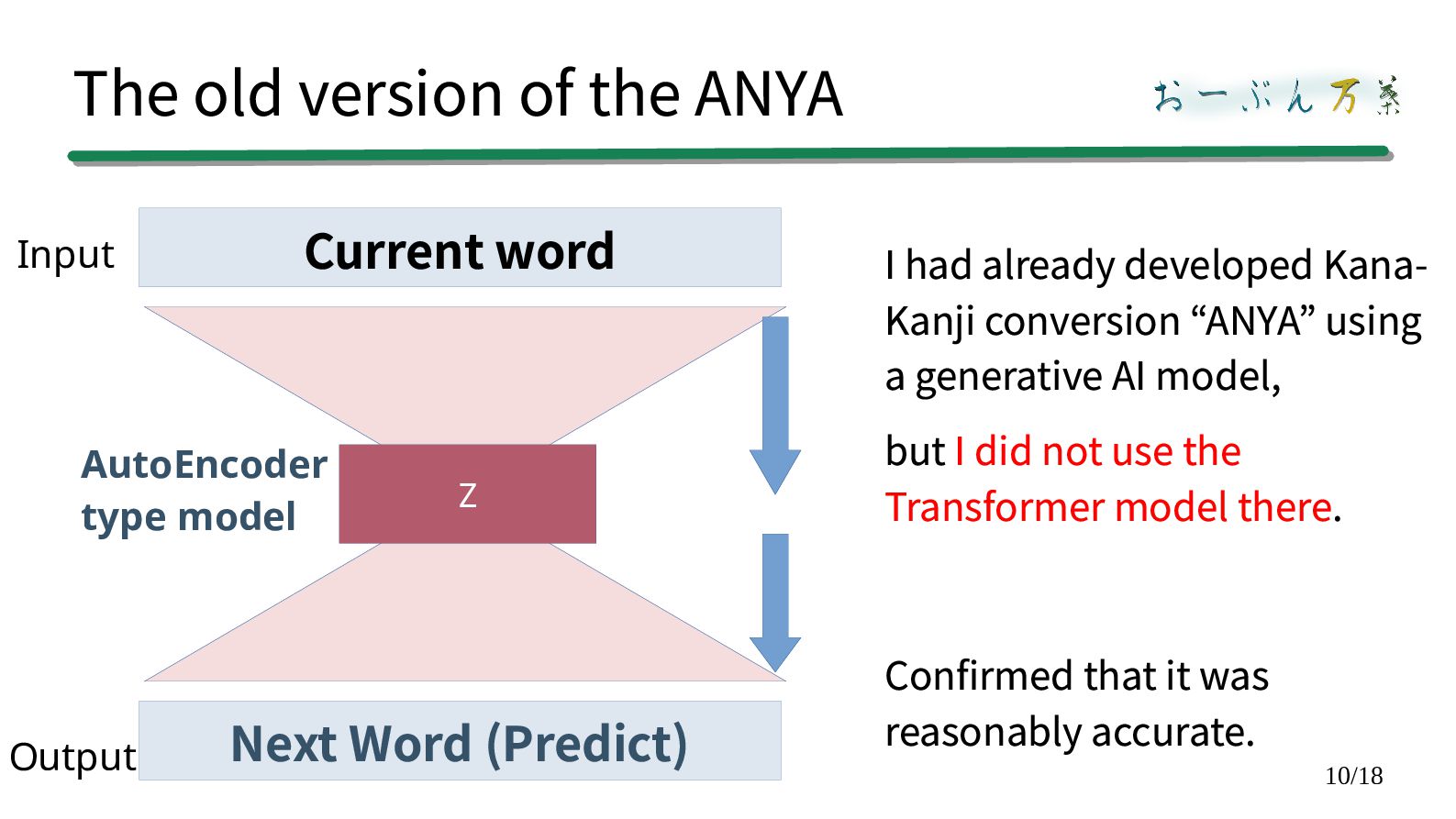
developed Kana- Kanji conversion “ANYA” using a generative AI model, but I did not use the Transformer model there. Confirmed that it was reasonably accurate. Current word Z Next Word (Predict) Input Output AutoEncoder type model
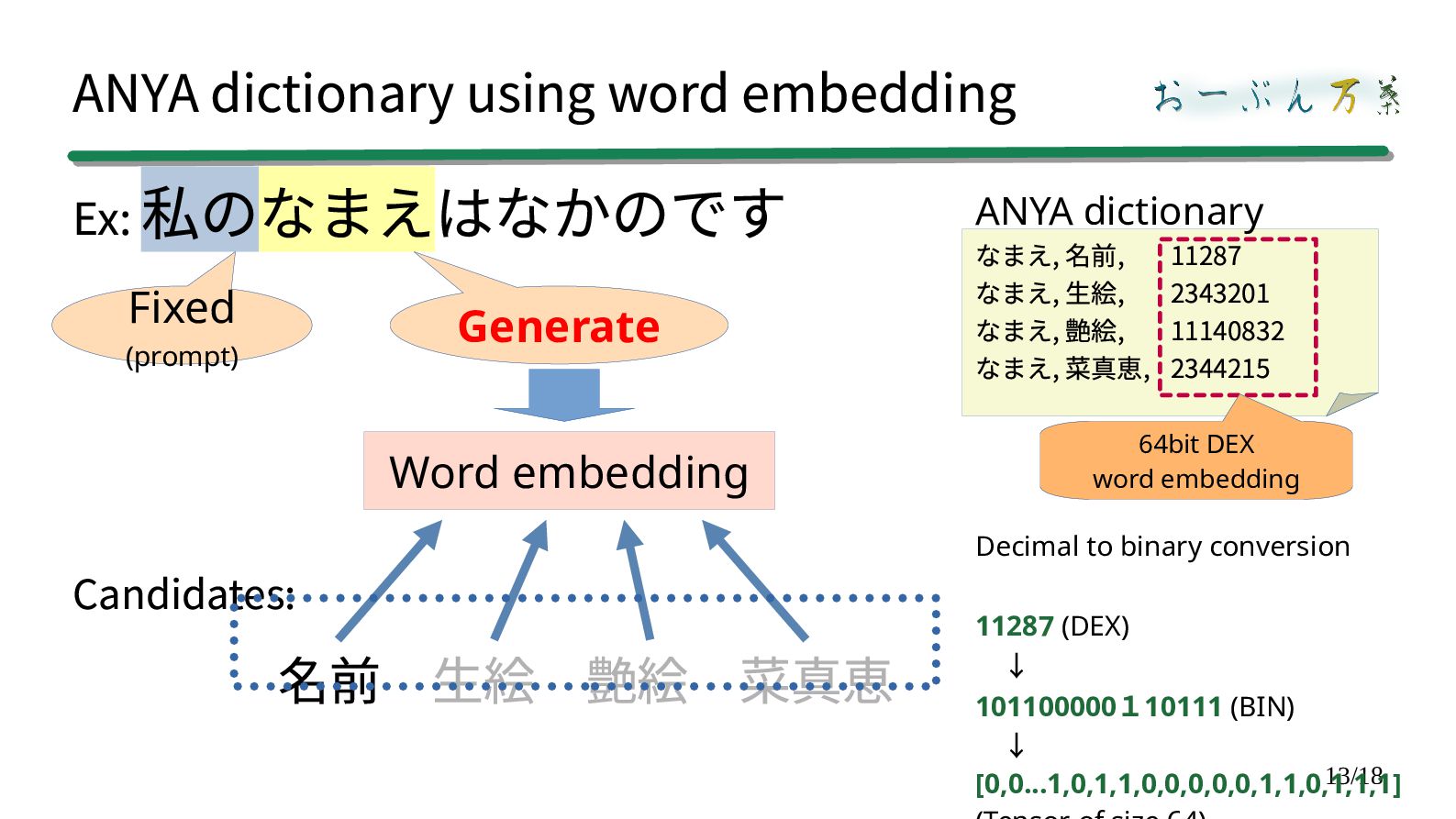
model. ②The generated word is compared with the kana-kanji conversion candidates. ③The closest match is output as the conversion result. How do we compare?
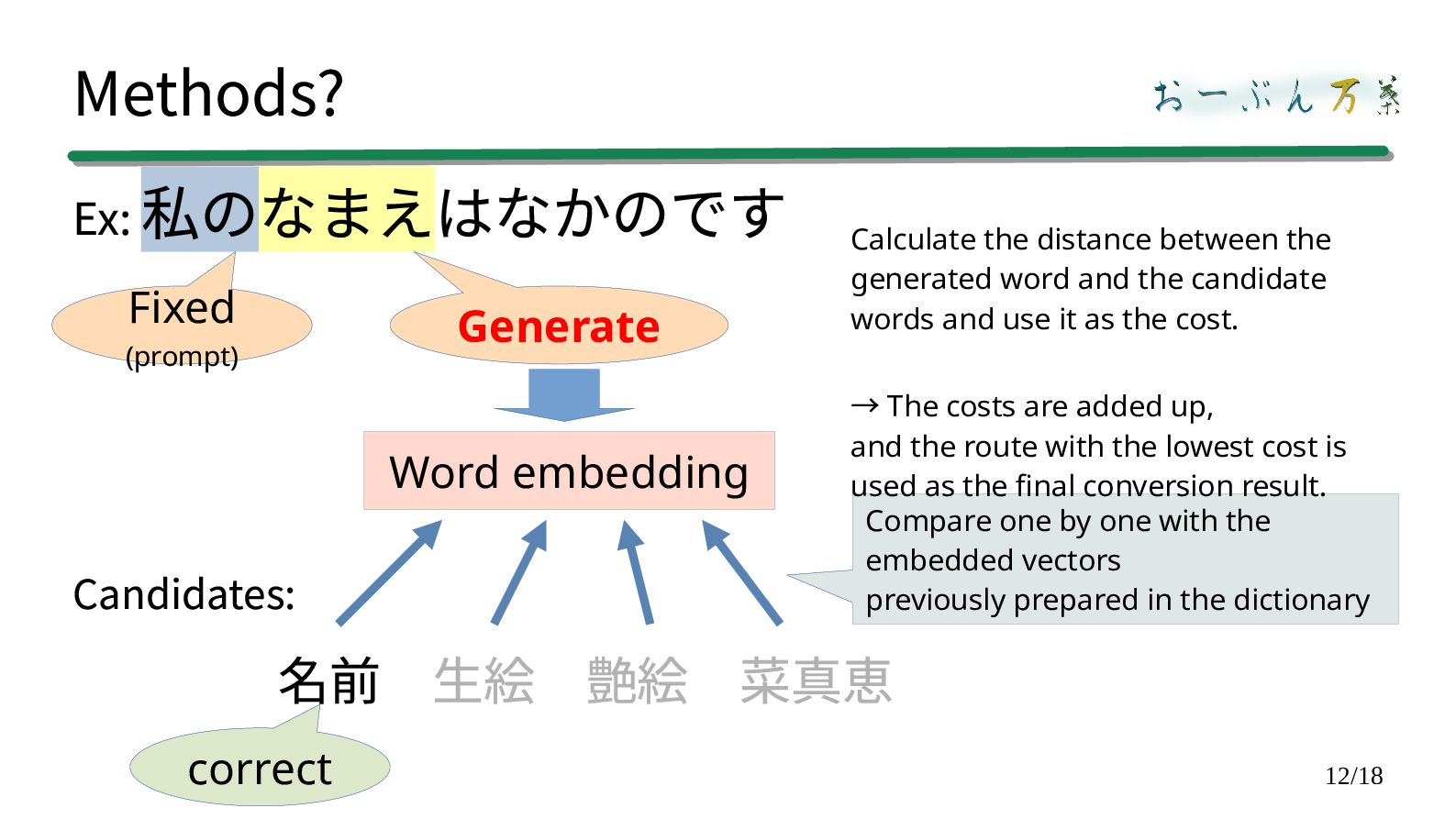
Word embedding Compare one by one with the embedded vectors previously prepared in the dictionary Calculate the distance between the generated word and the candidate words and use it as the cost. The costs are added up, → and the route with the lowest cost is used as the final conversion result.
(!???) Conversion accuracy → not at a level where show you A small LLM was supposed to be made for the conversion speed, but the accuracy, not just the speed, was reduced → Continuing to investigate ways to achieve speed while also achieving accuracy
the problems is the lack of data collection for training. Where to collect from? 1.Aozora-Bunko *Contains archaic words 2.Wikipedia *Is that license okay? What is fair use? 3.Others
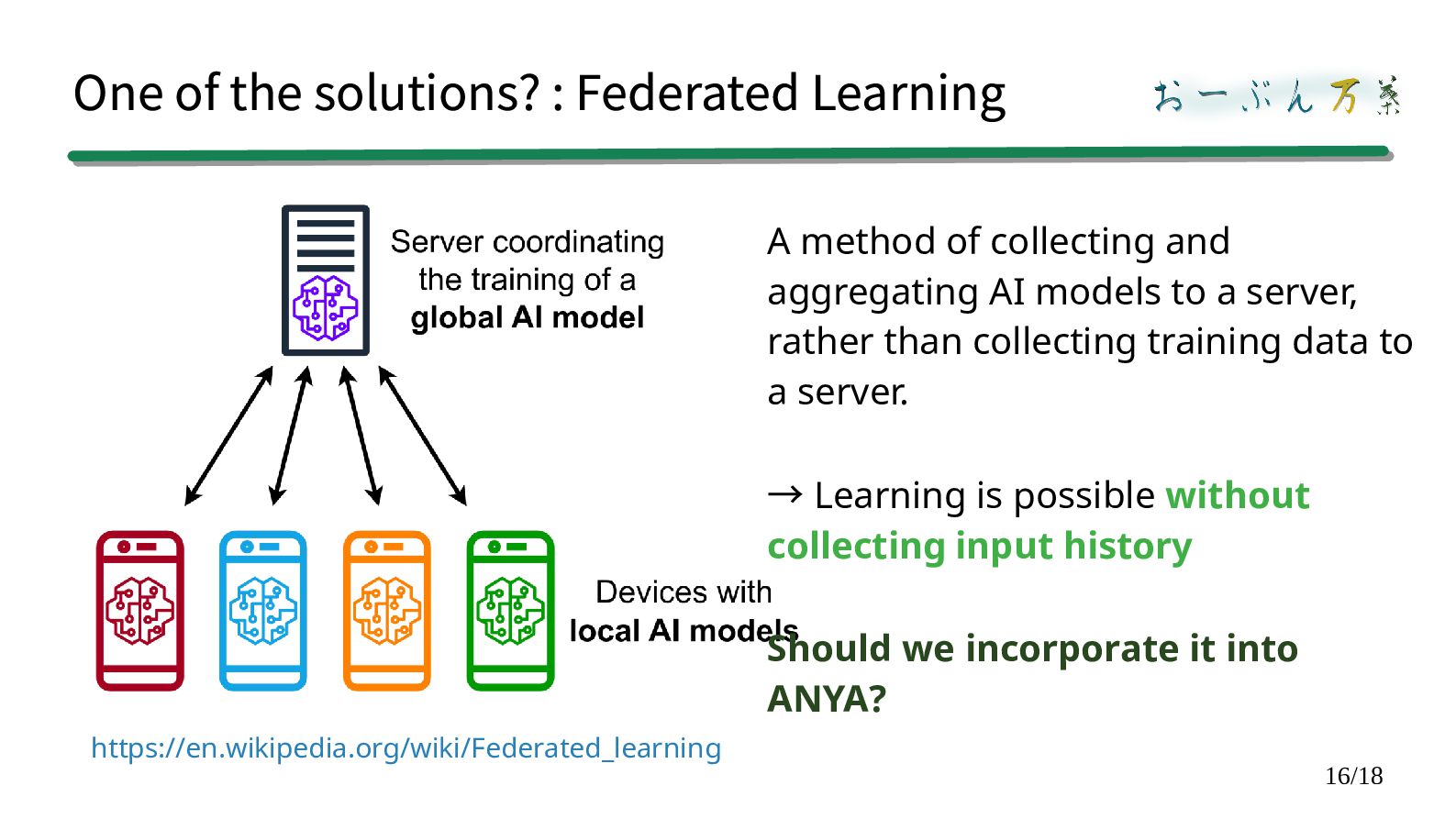
of collecting and aggregating AI models to a server, rather than collecting training data to a server. Learning is possible → without collecting input history Should we incorporate it into ANYA? https://en.wikipedia.org/wiki/Federated_learning
https://github.com/anya-im/Anya IBus input method: https://github.com/anya-im/ibus-anya Thank you, Syuta Hashimoto! Older versions (AutoEncoder Model) are already available. Please wait a little longer for the new version(Transformer Model). All developed in openSUSE.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}