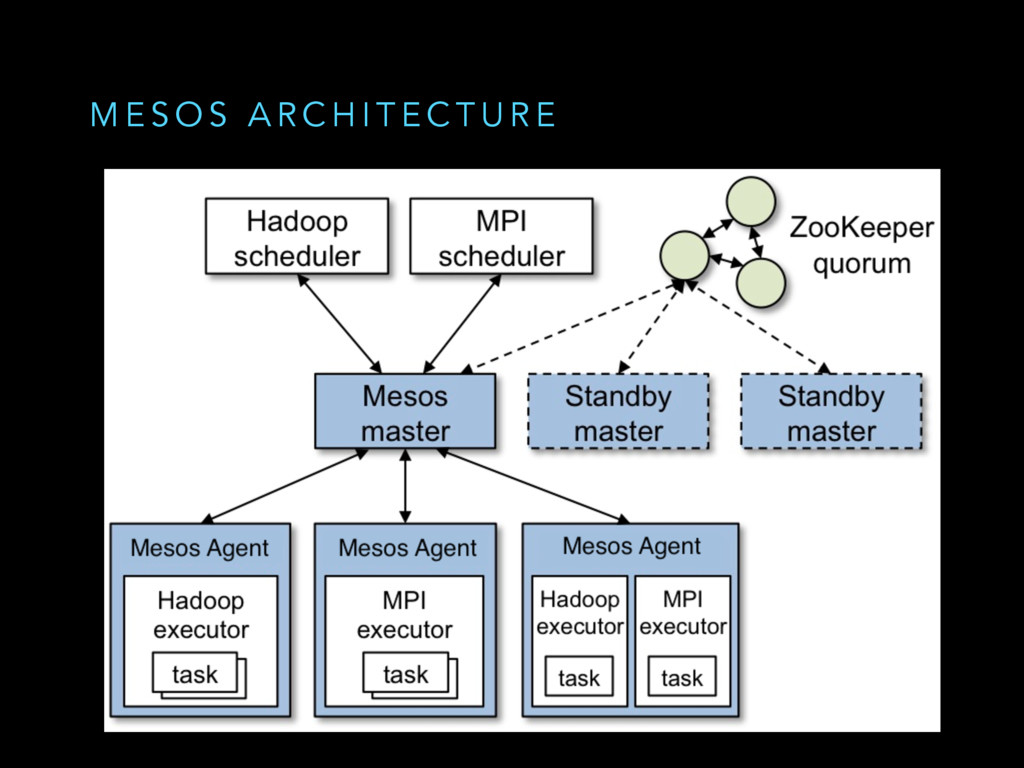
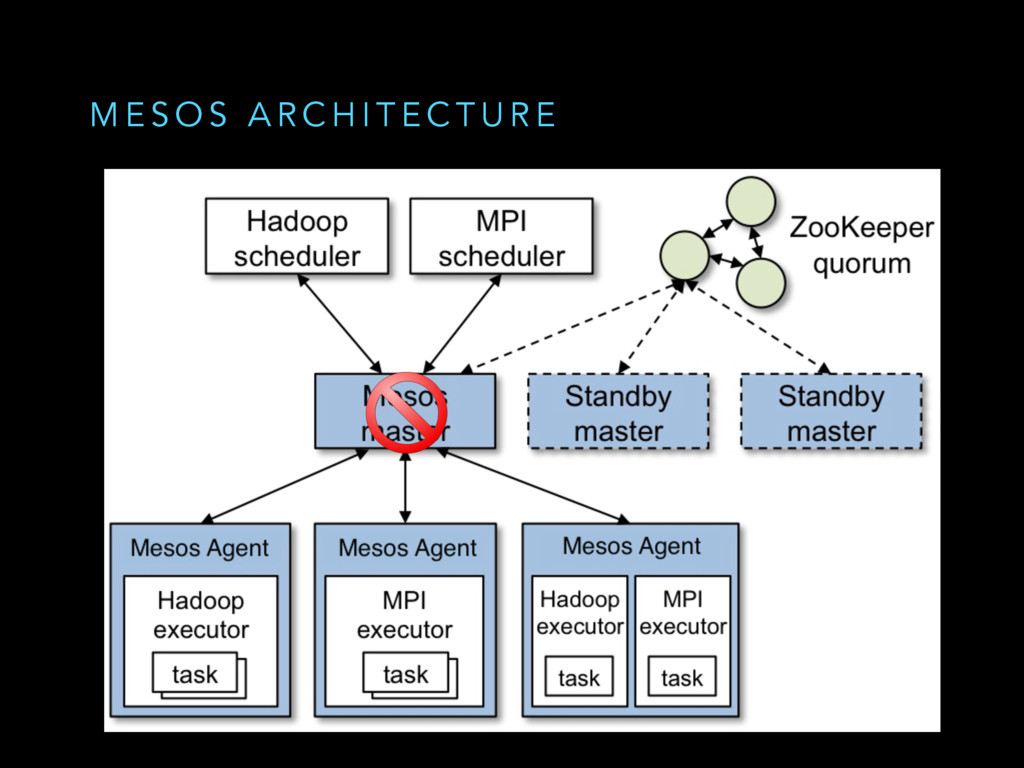
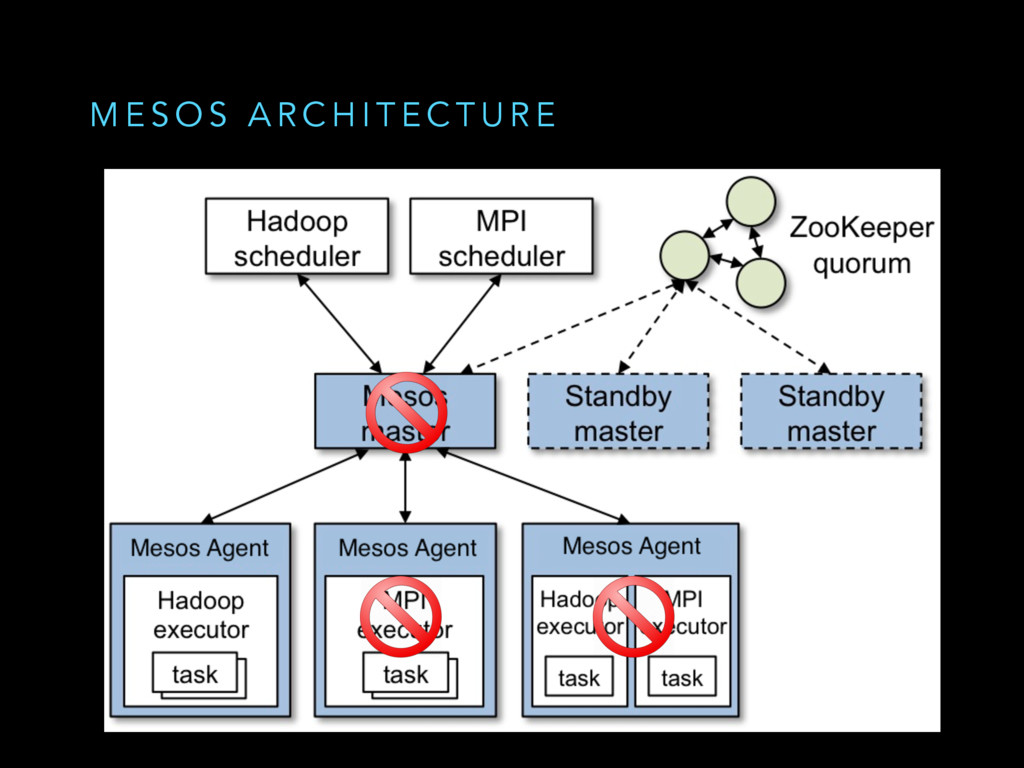
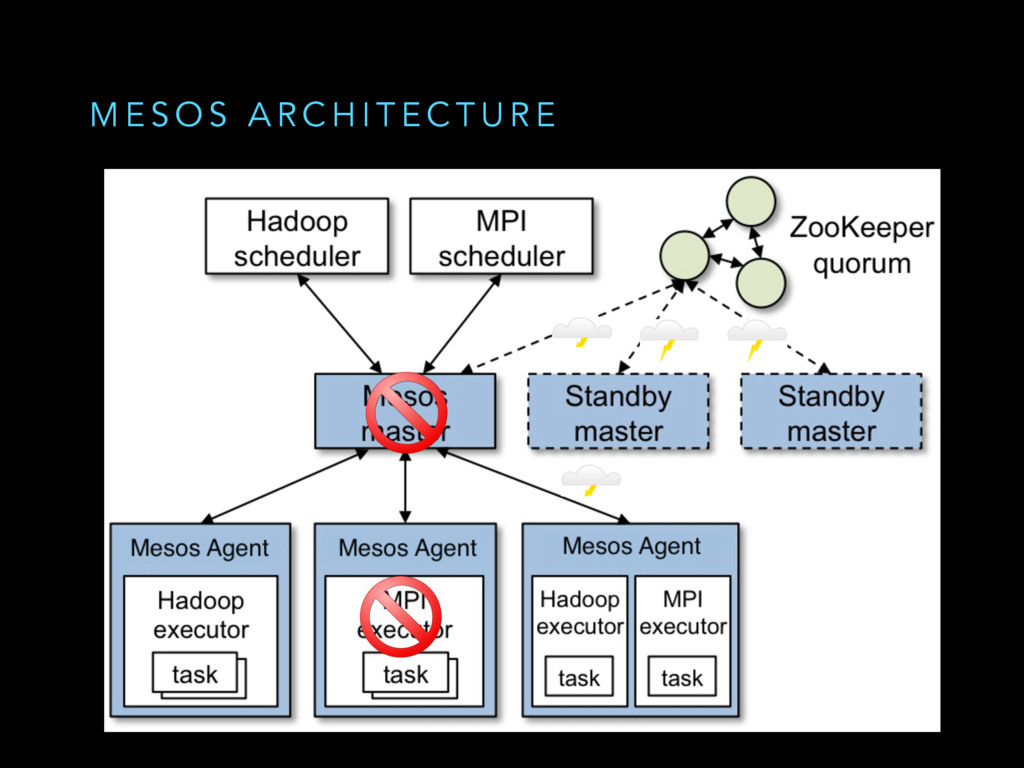
Mesos is a widely used cluster resource manager that has been used in production at scale for some time. At its core, Mesos is a sophisticated distributed system with lots of components and failure scenarios. In datacenters, hardware/network failures are the norm rather than the exception. Being a distributed systems kernel, Mesos needs to be resilient to all of these failures, degrading gracefully wherever applicable. We believe that everyone running a Mesos cluster in production/building distributed systems would benefit from learning how Mesos does fault tolerance to reason better about failures in their cluster/adopt these battle-hardened best practices in their project.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
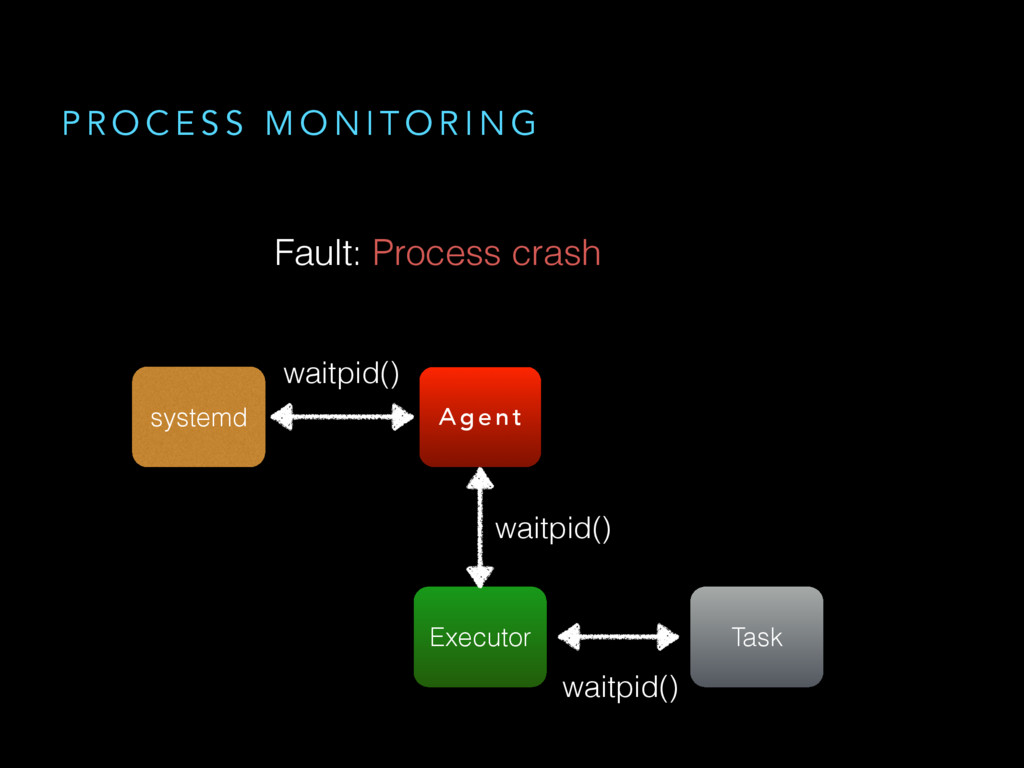{kind=link}
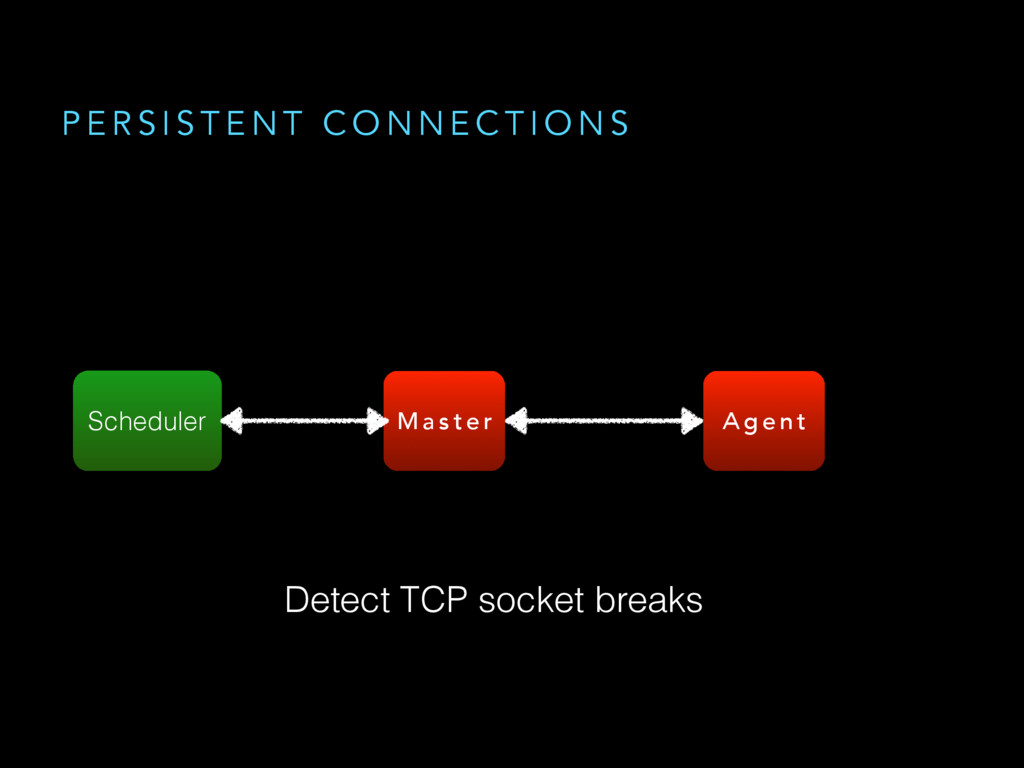{kind=link}
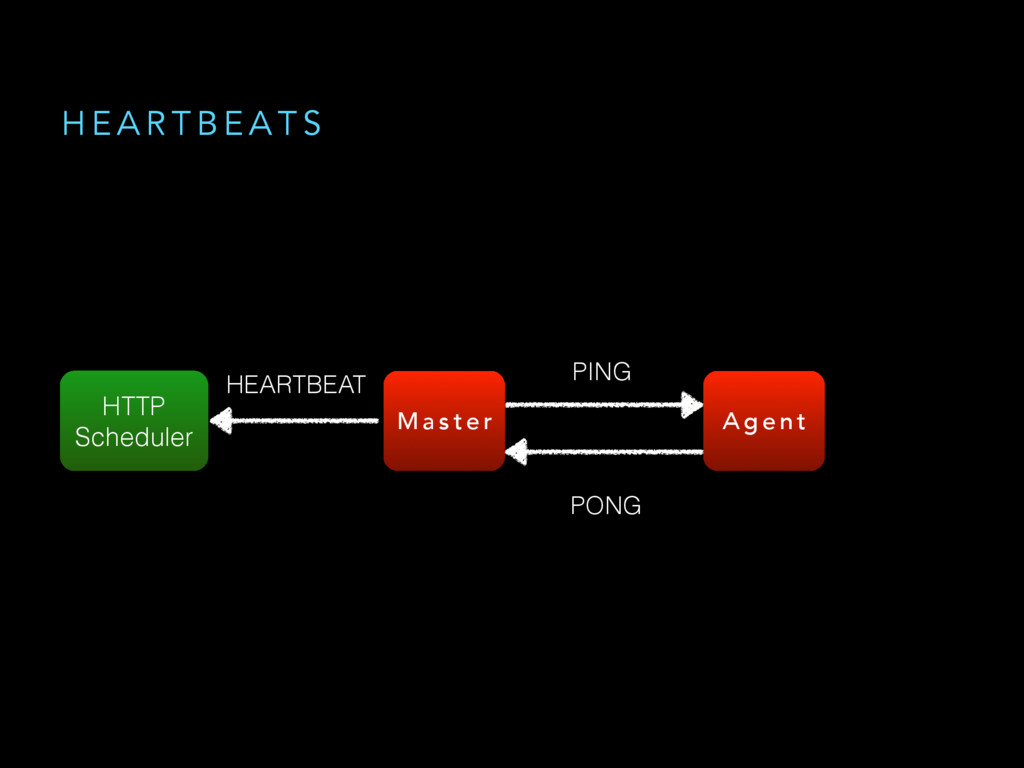{kind=link}
{kind=link}
{kind=link}
{kind=link}
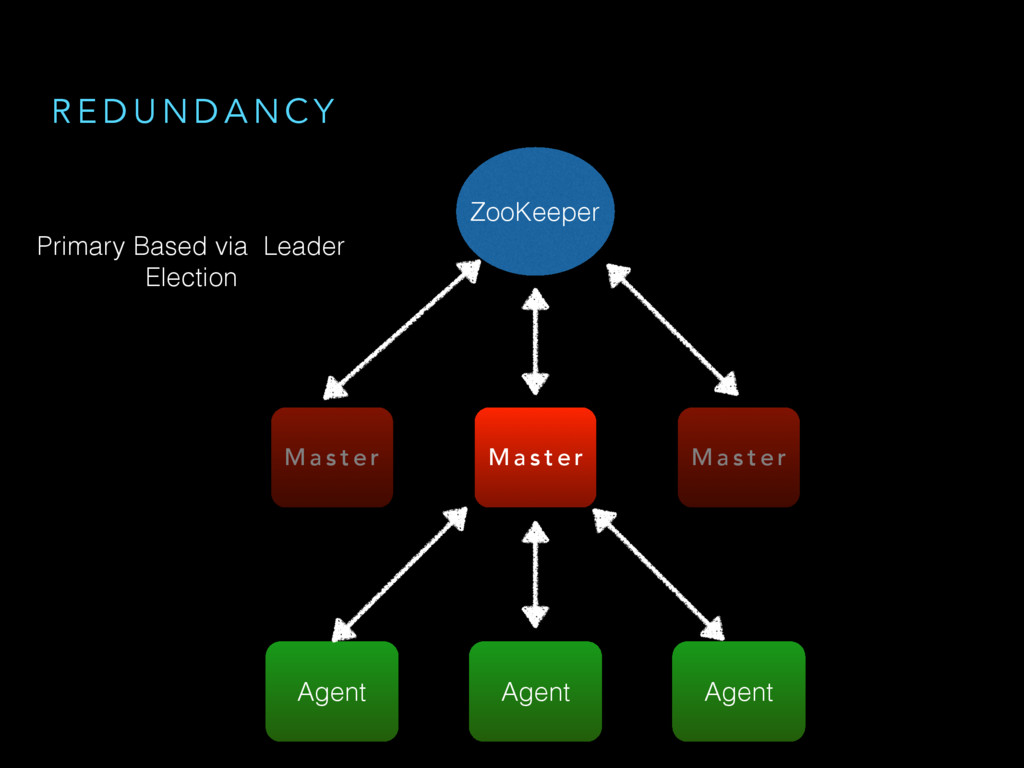{kind=link}
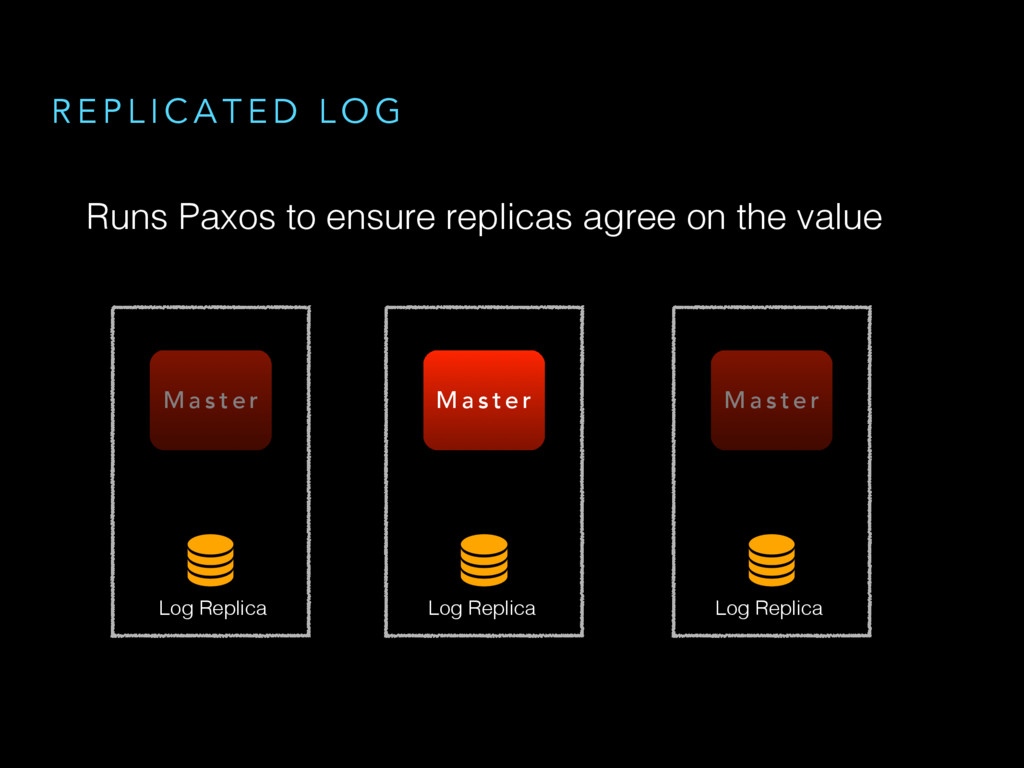{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
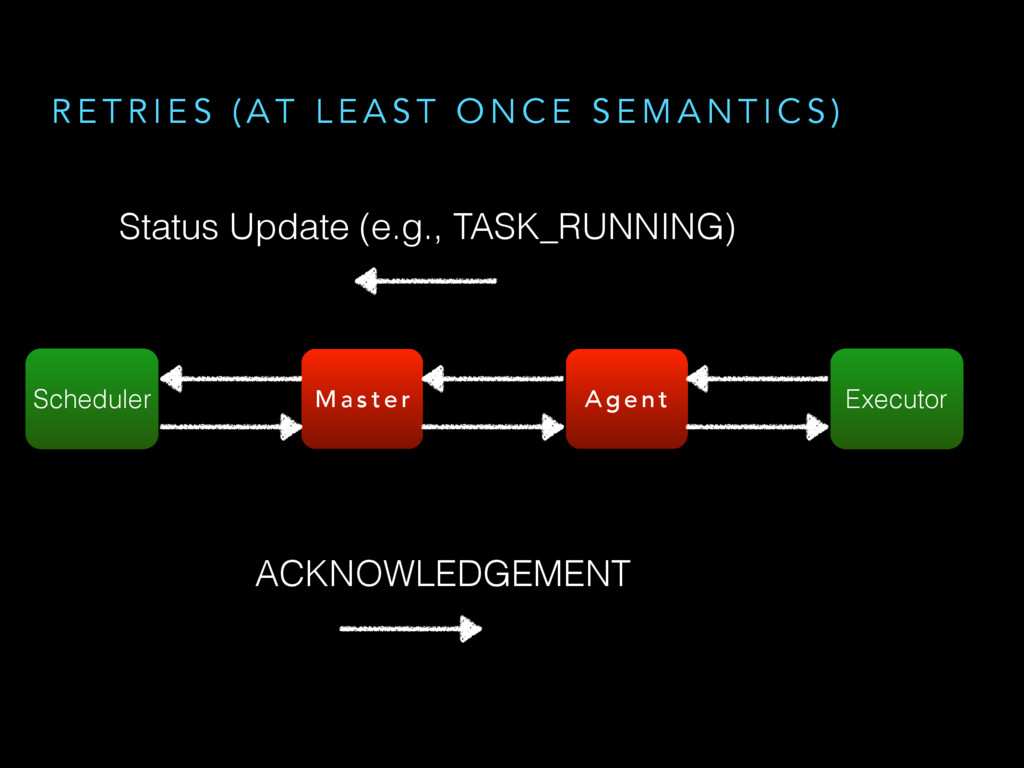{kind=link}
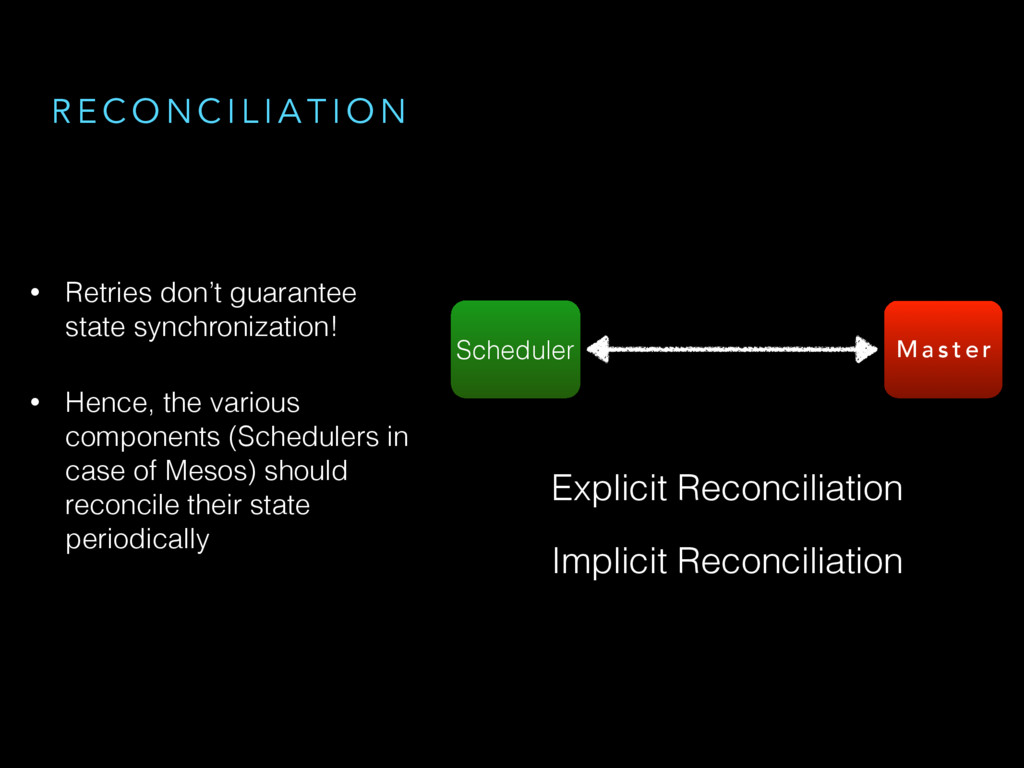{kind=link}
{kind=link}
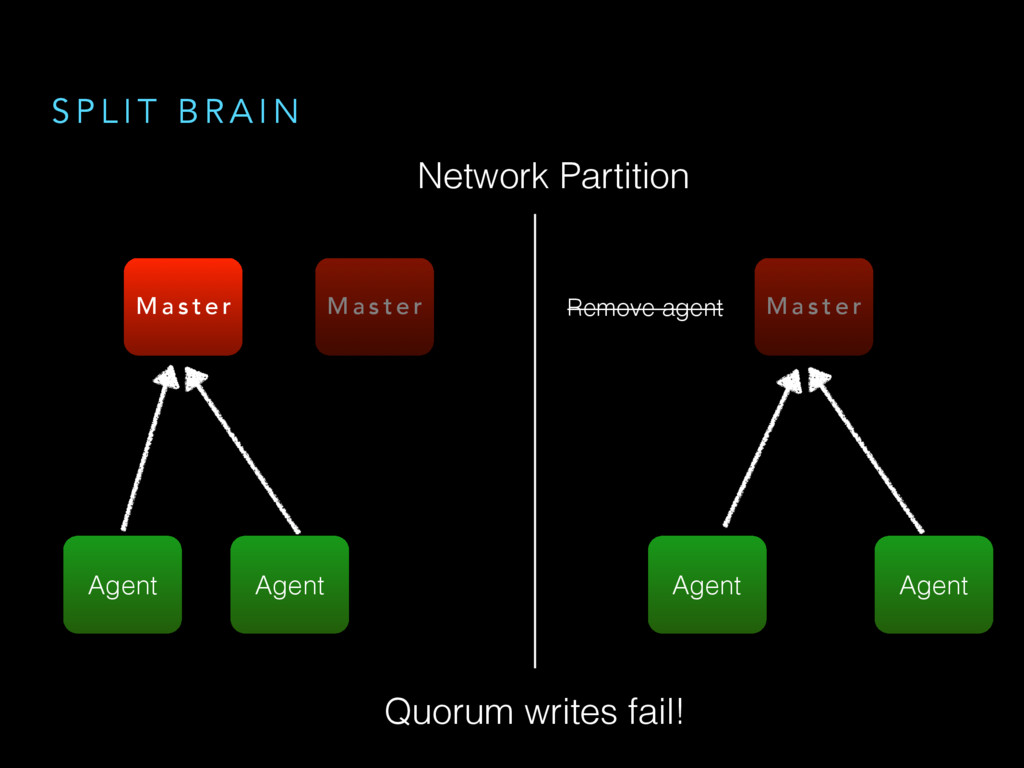{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}