Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
An Asynchronous, Scalable Django with Twisted (...
Search
Amber Brown (HawkOwl)
June 04, 2016
Programming
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
An Asynchronous, Scalable Django with Twisted (PyCon TW 2016 Keynote)
Amber Brown (HawkOwl)
June 04, 2016
More Decks by Amber Brown (HawkOwl)
See All by Amber Brown (HawkOwl)
Batteries Included, But They're Leaking (Python Language Summit, 2019)
hawkowl
0
540
Why Twisted Is The Best (WOOTConf @ LCA 2017)
hawkowl
0
190
Releasing Calendar Versioned Software (PyCon AU 2016)
hawkowl
1
170
Falsehoods Developers Have About Identity (PyCon AU 2016 Lightning Talk)
hawkowl
1
830
The Report of Twisted's Death; or Twisted & Tornado in the Asyncio Age (EuroPython 2016)
hawkowl
0
200
The Report of Twisted's Death; or Twisted & Tornado in the Asyncio Age (PyCon US 2016)
hawkowl
0
230
Twisted & Python 3 (Python Language Summit, 2016)
hawkowl
0
190
The Report of Twisted's Death; or Twisted & Tornado in the Asyncio Age (Perth Django Meetup)
hawkowl
0
210
The Future of Twisted, and Pretty Much Everything Else (PyCon CZ Keynote, 2015)
hawkowl
0
160
Other Decks in Programming
See All in Programming
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
170
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.6k
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
250
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
580
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
140
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
120
継続モナドとリアクティブプログラミング
yukikurage
3
600
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
420
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
200
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
520
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
140
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
A Tale of Four Properties
chriscoyier
163
24k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
How to train your dragon (web standard)
notwaldorf
97
6.7k
Embracing the Ebb and Flow
colly
88
5.1k
Bash Introduction
62gerente
615
220k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Code Reviewing Like a Champion
maltzj
528
40k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Transcript
An Asynchronous, Scalable Django with Twisted
Hello, I’m Amber Brown (HawkOwl)
Twitter: @hawkieowl Pronouns: she/her
I live in Perth, Western Australia
None
Core Developer Release Manager Ported 40KLoC+ to Python 3
None
Binary release management across 3 distros Ported Autobahn|Python (Tx) and
Crossbar.io to Python 3 Web API/REST integration in CB
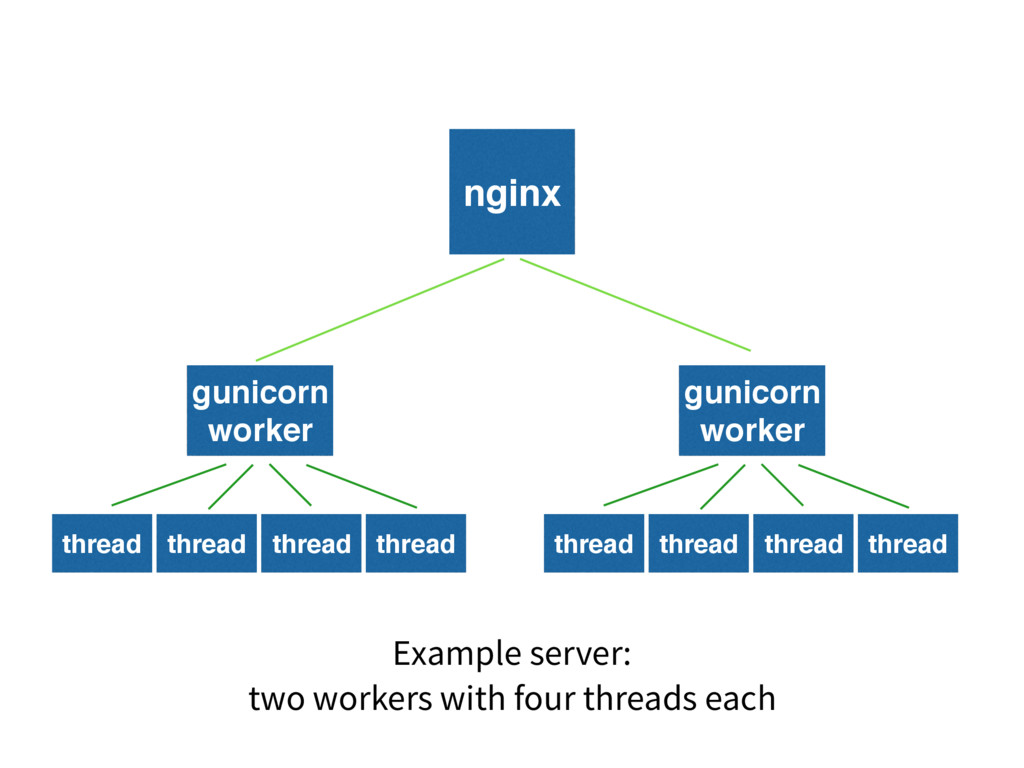
Scaling Django Applications
Django serves one request at a time
gunicorn, mod_wsgi, etc run multiple copies in threads + processes
Concurrent Requests == processes x threadpool size
nginx gunicorn worker thread thread thread thread gunicorn worker thread
thread thread thread Example server: two workers with four threads each
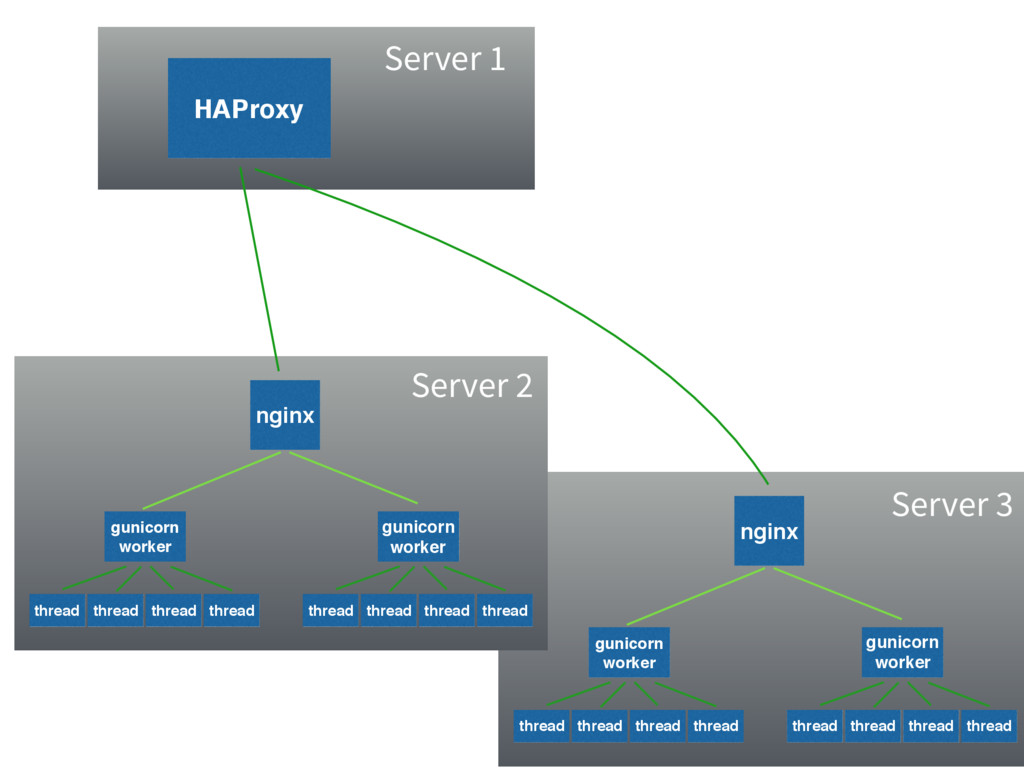
Need more requests? Add more web servers!
nginx gunicorn worker thread thread thread thread gunicorn worker thread
thread thread thread nginx gunicorn worker thread thread thread thread gunicorn worker thread thread thread thread HAProxy Server 2 Server 3 Server 1
Scaling has required adding a new piece
Higher scale means higher complexity
Is there a better way to handle many requests?
Problem Domain
Modern web applications have two things that take a long
time to do
CPU-bound work Math, natural language processing, other data processing
On most Python interpreters, Python threads are unsuitable for dispatching
CPU-heavy work
Of N Python threads only 1 may run Python code
because of the Global Interpreter Lock
Of N Python threads only N may run C code,
since the Global Interpreter Lock is released
I/O-bound work Database requests, web requests, other network I/O
Threads work better for I/O-bound work
Thread switching overhead is expensive Rapidly acquiring/releasing the GIL is
expensive
First, let's focus on I/O-bound applications.
Asynchronous I/O & Event-Driven Programming
Your code is triggered on events
Events can be: incoming data on the network some computation
is finished a subprocess has ended etc, etc
How do we know when events have occurred?
All events begin from some form of I/O, so we
just wait for that!
Event-driven programming frameworks
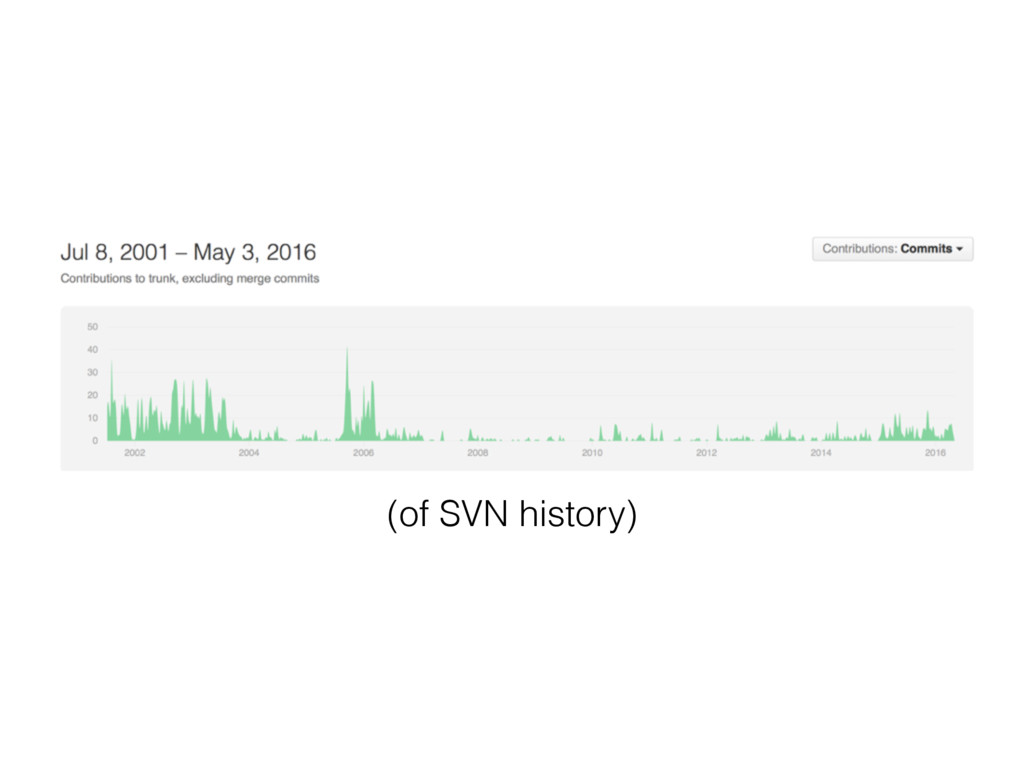
Twisted (the project I work on!)
(of SVN history)
asyncio was introduced much later
None
Same at their core, using "selector functions"
select() and friends (poll, epoll, kqueue)
Selector functions take a list of file descriptors (e.g. sockets,
open files) and tell you what is ready for reading or writing
Selector loops can handle thousands of open sockets and events
Data is channeled through a transport to a protocol (e.g.
HTTP, IMAP, SSH)
Sending data is queued until the network is ready
Nothing blocks, it simply gives control to the next event
to be processed
No blocking means no threads
“I/O loops” or “reactors” (as it "reacts" to I/O)
Higher density per core No threads required! Concurrency, not parallelism
Best case: high I/O throughput, high-latency clients, low CPU processing
But what if we need to process CPU bound tasks?
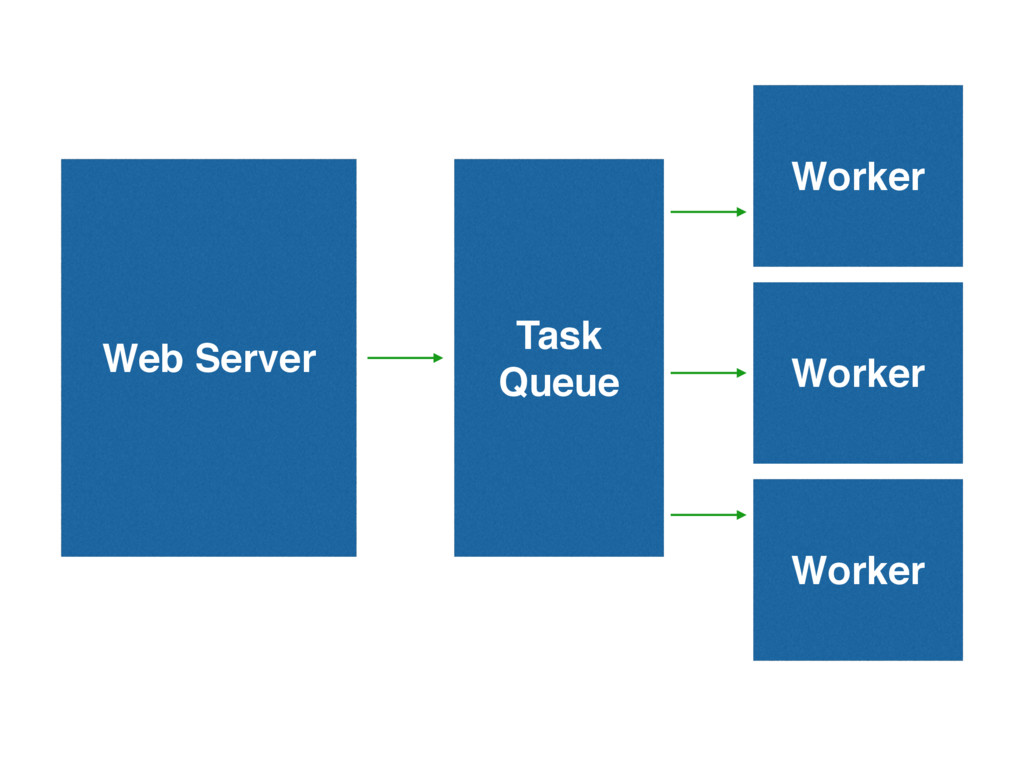
Event Driven Programming with Work Queues
CPU bound tasks are added to a queue, rather than
being ran directly
Web Server Task Queue Worker Worker Worker
We have made the CPU-bound task an I/O-bound one for
our web server
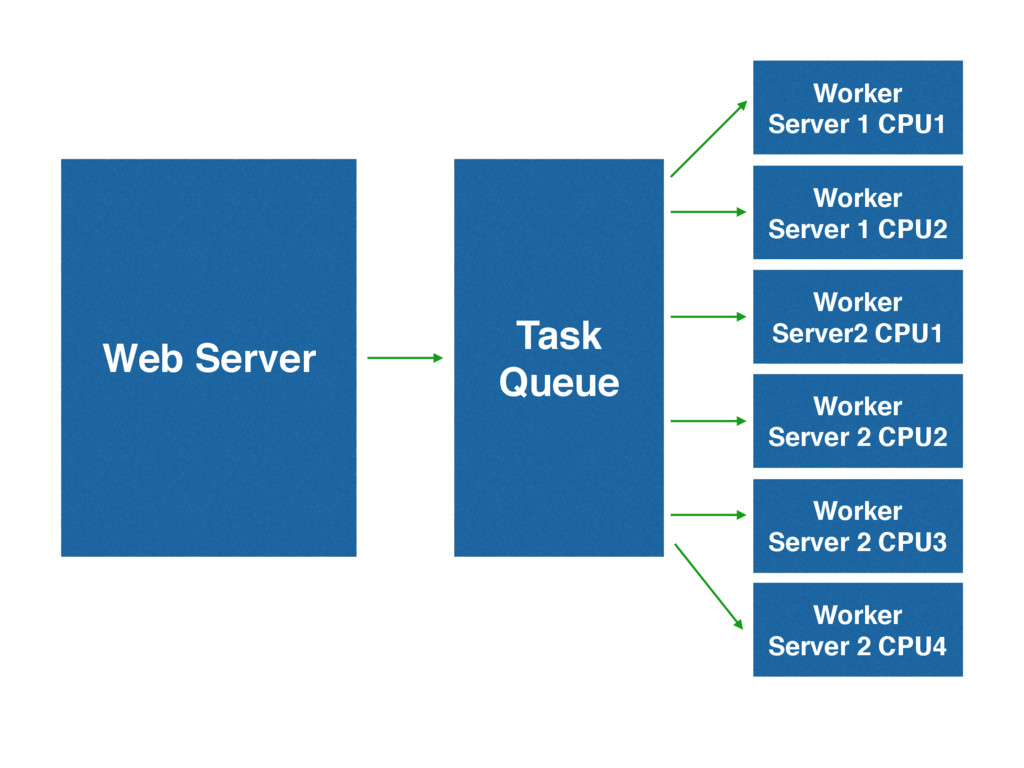
We have also made the scaling characteristics horizontal
Web Server Task Queue Worker Server 2 CPU3 Worker Server
2 CPU2 Worker Server2 CPU1 Worker Server 1 CPU2 Worker Server 1 CPU1 Worker Server 2 CPU4
Putting tasks on the queue and removing them is cheap
Task queues scale rather well
Add more workers to scale!
Do we have an implementation of this?
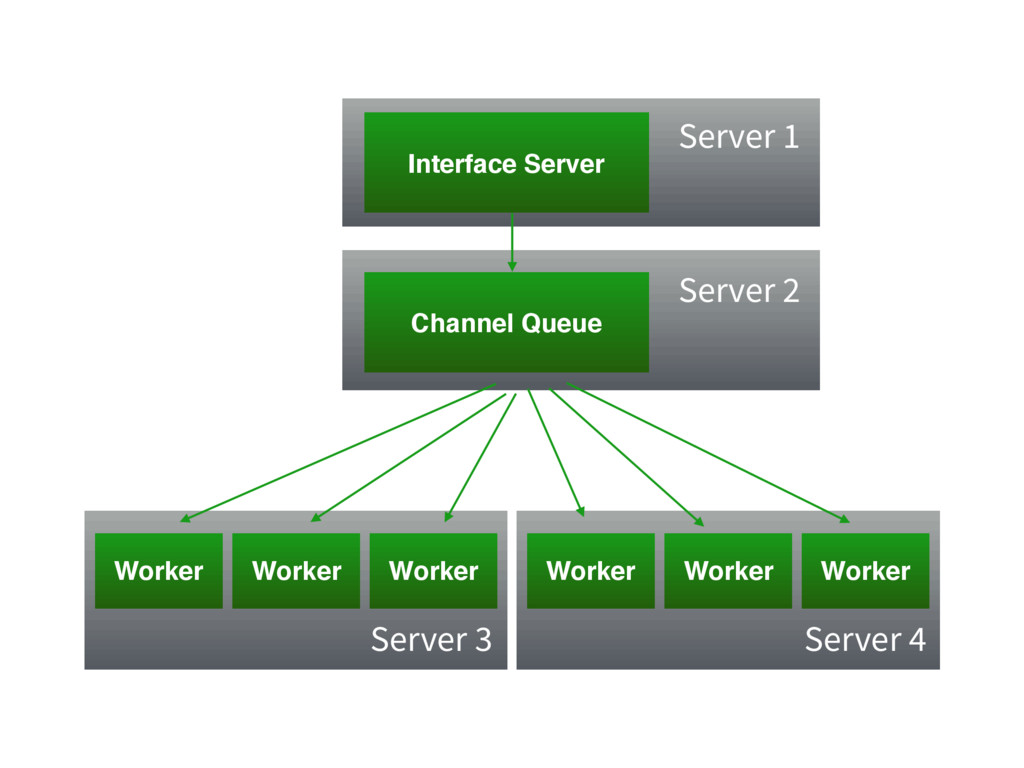
The Architecture of Django Channels
Project to make an "asynchronous Django"
Authored by Andrew Godwin (behind South, Migrations)
Interface Server Channel Queue Worker Worker Worker Worker Worker Worker
Server 1 Server 2 Server 3 Server 4
Interface server accepts requests, puts them on the Channel (task
queue)
Workers take requests off the Channel and process them
Results from processed requests are written back to the Channel
The interface server picks up these responses and writes it
back out to the HTTP request
The interface server is only I/O bound and does no
"work" of its own
Perfect application for asynchronous I/O!
Daphne, the reference interface server implementation, is written in Twisted
Daphne is capable of handling thousands of requests a second
on modest hardware
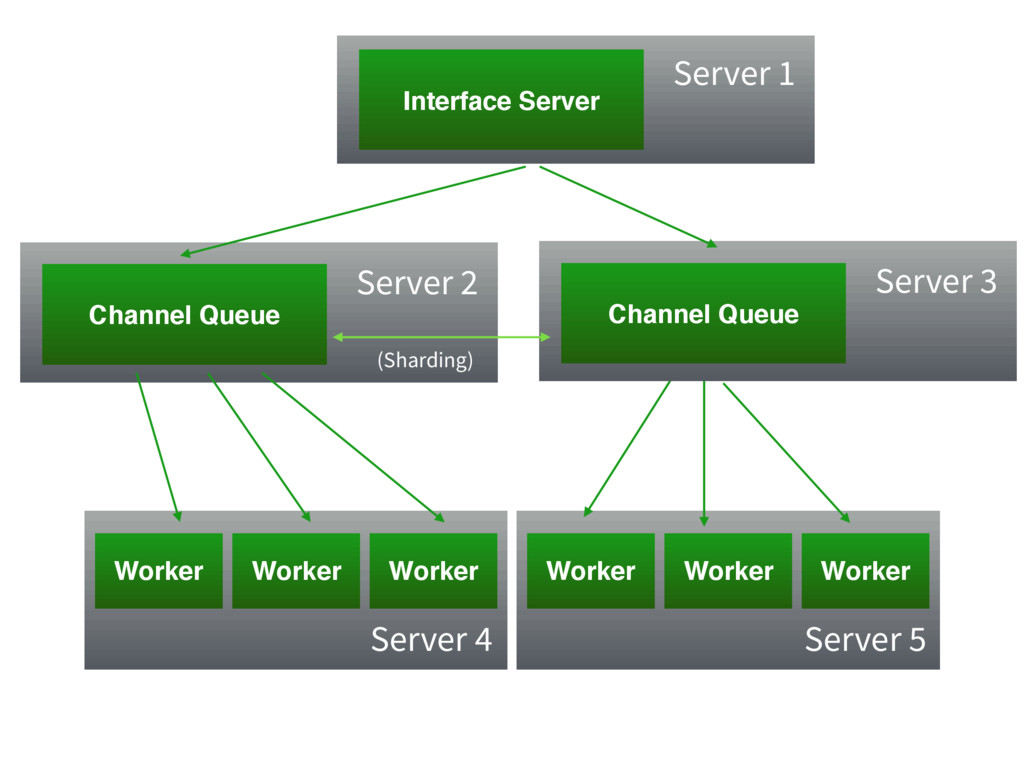
The channel layer can be sharded
Channel Queue Server 2 Interface Server Worker Worker Worker Worker
Worker Worker Server 1 Server 4 Server 5 Channel Queue Server 3 (Sharding)
Workers do not need to be on the web server...
but you can put them there if you want!
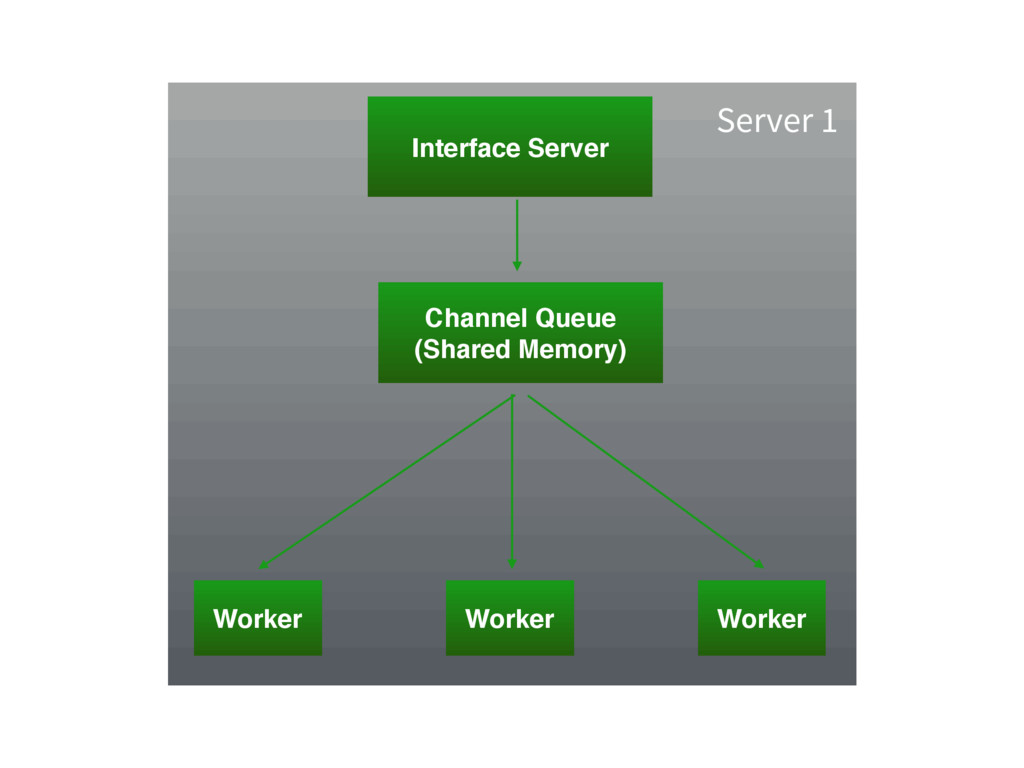
For small sites, the channel layer can simply be an
Inter- Process-Communication bus
Channel Queue (Shared Memory) Interface Server Worker Worker Worker Server
1
And Twisted understands WebSockets... so can Channels too?
Yep!
How Channels Works
A Channel is where requests are put to be serviced
What is a request? - incoming HTTP requests - connected
WebSocket connection - data on a WebSocket
http.request http.disconnect websocket.connect websocket.receive websocket.disconnect
Your worker listens on these channel names
Information about the request (e.g. a body and headers), and
a "reply channel" identifier
http.response!<client> http.request.body!<client> websocket.send!<client>
http.response!c134x7y http.request.body!c134x7y websocket.send!c134x7y
Reply channels are connection specific so that the correct response
gets to the correct connection
In handling a request, your code calls send() on a
response channel
But because Channels is event-driven, you can't get a "response"
from the event
The workers themselves do not use asynchronous I/O by default!
Under Channels, you write synchronous code, but smaller synchronous code
@receiver(post_save, sender=BlogUpdate) def send_update(sender, instance, **kwargs): Group("liveblog").send({ "id": instance.id, "content":
instance.content, })
Group? What's a group?
Pool of request-specific channels for efficiently sending one-to-many messages
e.g: add all open WebSocket connections to a group that
is notified when your model is saved
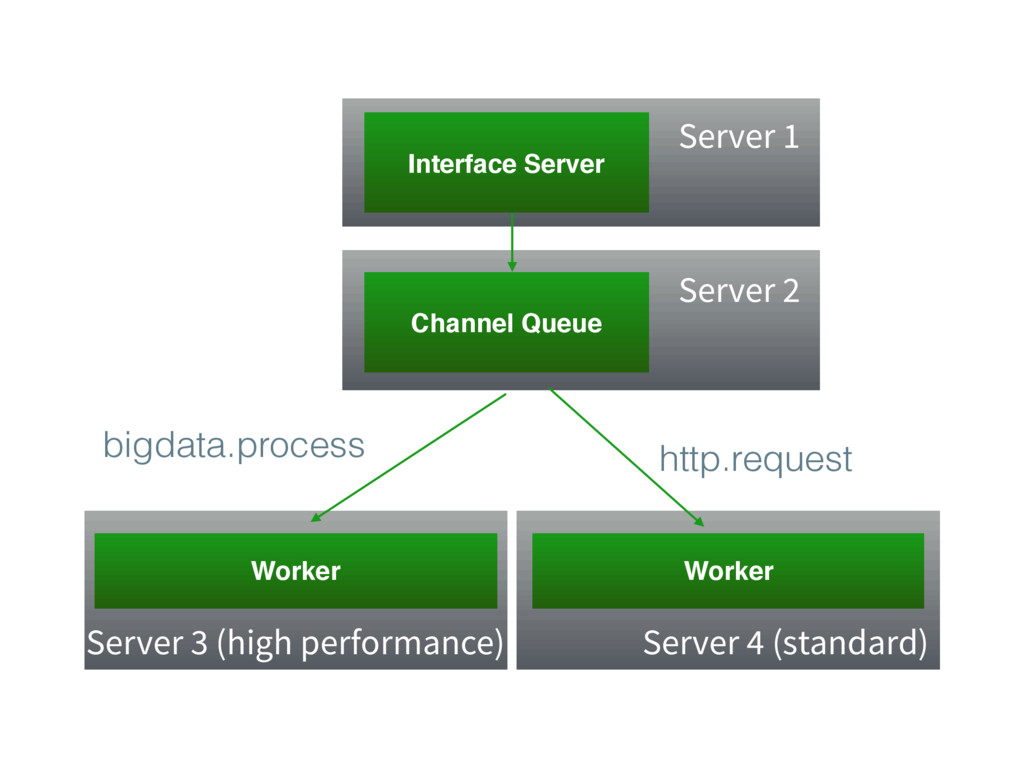
Handling different kinds of requests
Workers can listen on specific channels, they don't have to
listen to all of them!
Interface Server Channel Queue Worker Worker Server 1 Server 2
Server 3 (high performance) Server 4 (standard) http.request bigdata.process
Because you can create and listen for arbitrary channels, you
can funnel certain kinds of work into different workers
my_data_set = request.body Channel("bigdata.process").send( {"mydata": my_data_set})
How do we support sending that data down the current
request when it's done?
my_data_set = request.body Channel("bigdata.process").send({ "mydata": my_data_set, "reply_channel": message.reply_channel})
All our big data worker needs to do then is
send the response on the reply channel!
Channels as a bridge to an asynchronous future
A channel doesn't care if you are synchronous or asynchronous
...or written in Django or even Python!
Channels implements "Asynchronous Server Gateway Interface"
The path to a hybrid future Go, Django, Twisted, etc
etc
Channels is due to land in Django 1.11/2.0
Try it out! channels.readthedocs.io
Questions? (pls no statements, save them for after)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}