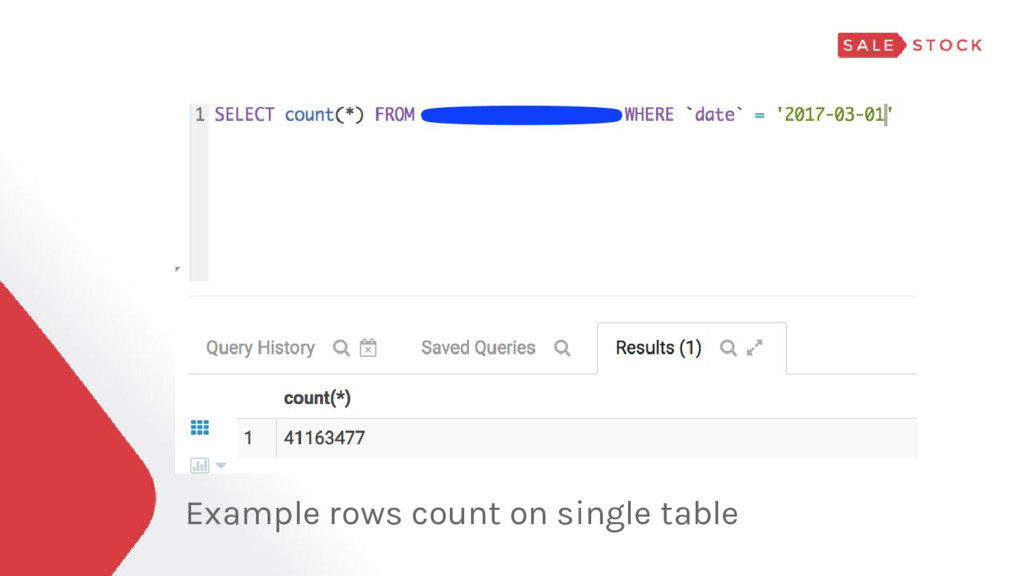
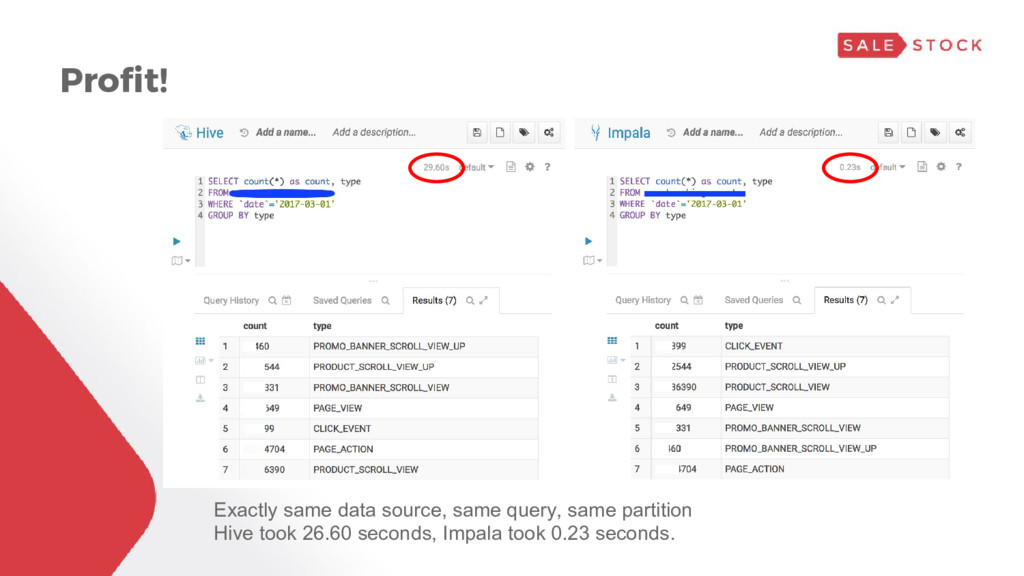
table/day = 4+ GB (Parquet + GZiped)* ▸ Some query takes 3+ hours** * 10+ GB raw csv ** without partition, before implementing well structured big data framework
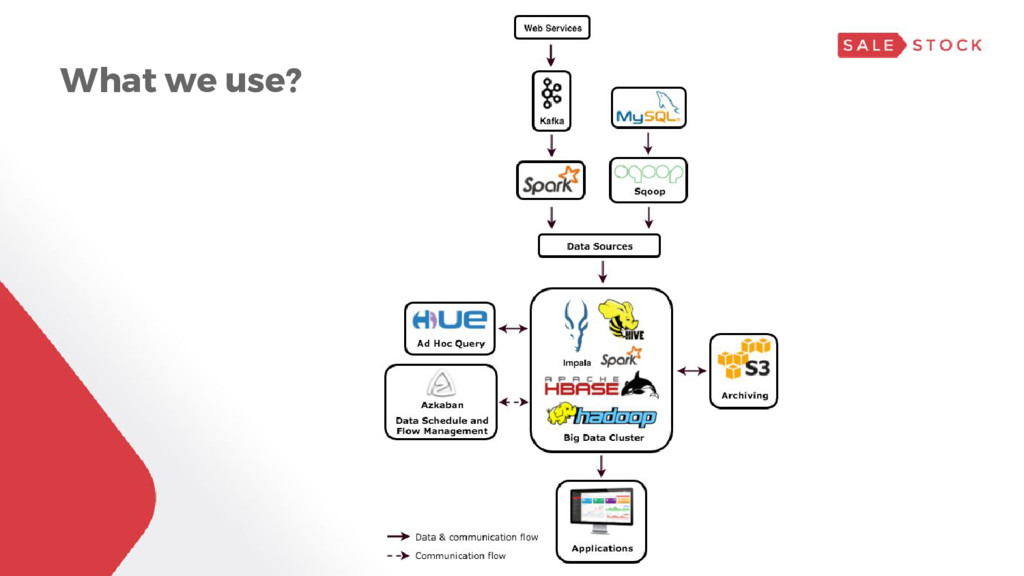
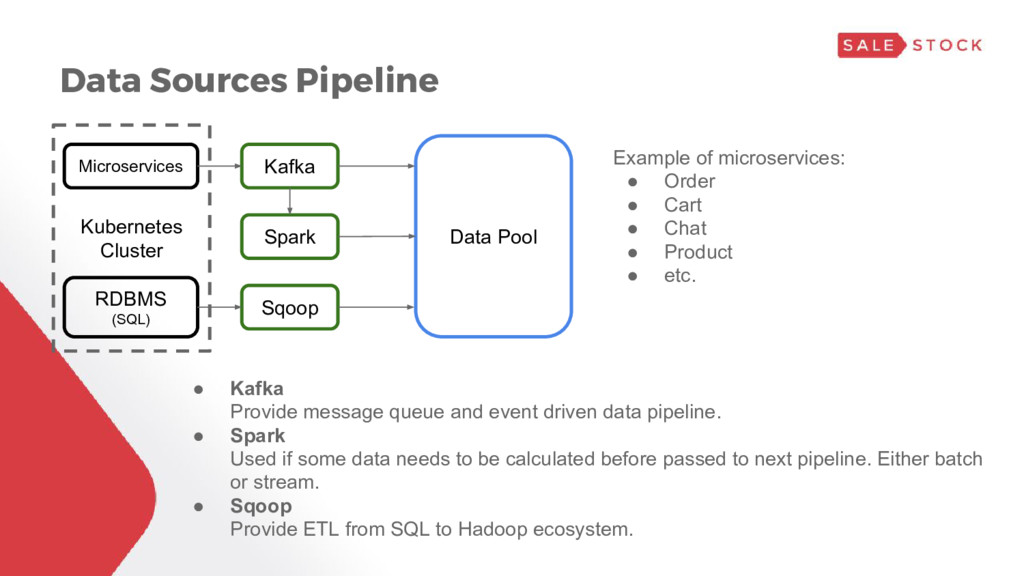
Data Pool Spark Example of microservices: • Order • Cart • Chat • Product • etc. • Kafka Provide message queue and event driven data pipeline. • Spark Used if some data needs to be calculated before passed to next pipeline. Either batch or stream. • Sqoop Provide ETL from SQL to Hadoop ecosystem.
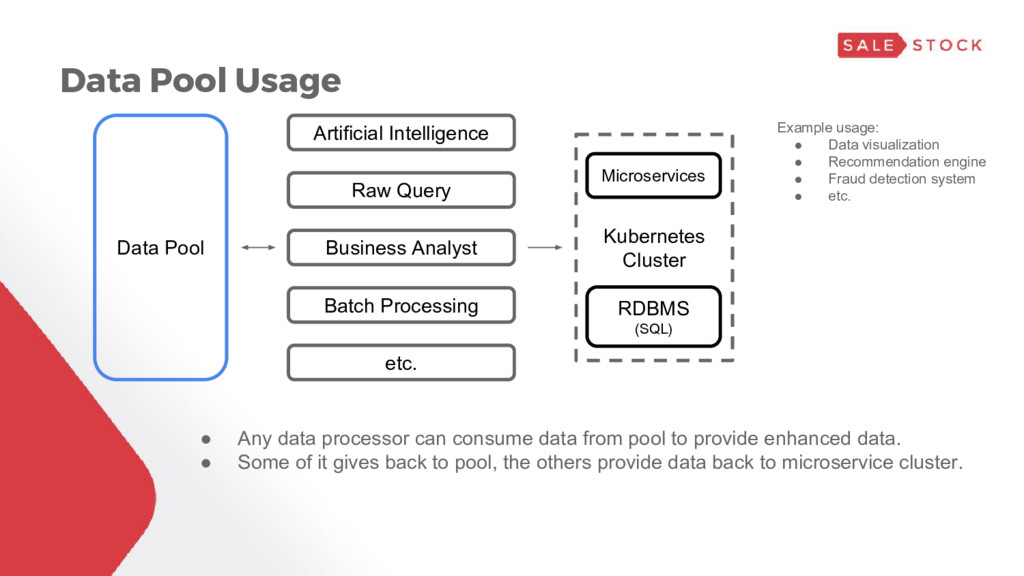
Analyst Batch Processing etc. Kubernetes Cluster Microservices RDBMS (SQL) • Any data processor can consume data from pool to provide enhanced data. • Some of it gives back to pool, the others provide data back to microservice cluster. Example usage: • Data visualization • Recommendation engine • Fraud detection system • etc.
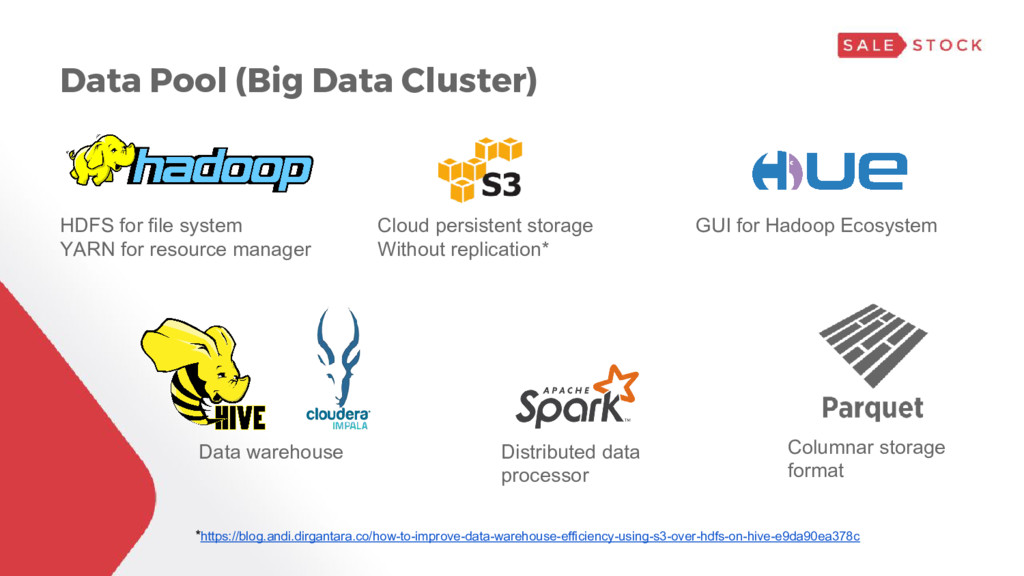
for resource manager Cloud persistent storage Without replication* GUI for Hadoop Ecosystem Data warehouse Distributed data processor Columnar storage format *https://blog.andi.dirgantara.co/how-to-improve-data-warehouse-efficiency-using-s3-over-hdfs-on-hive-e9da90ea378c
by distributed system. Technically “big data” refers to distributed platform. • Partition Provide scalable indexing within distributed system. https://blog.andi.dirgantara.co/konsep-partisi-fitur-dasar-big-data-5b531a777fdd • Replication Factor (Availability) Provide fault tolerant/ high availability on distributed system. • Coordination (Consistency) Provide consistency either write or read on distributed system.
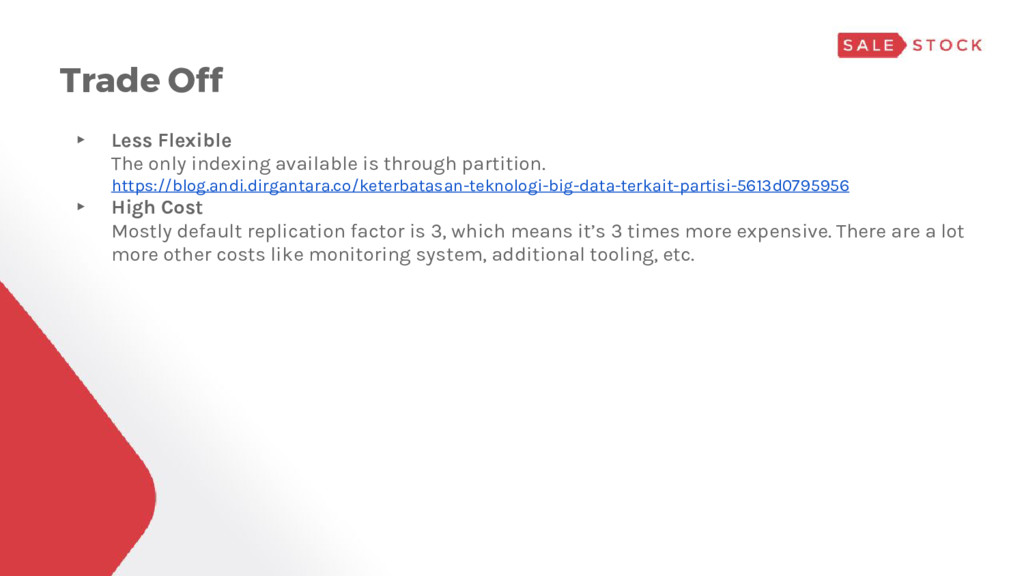
through partition. https://blog.andi.dirgantara.co/keterbatasan-teknologi-big-data-terkait-partisi-5613d0795956 ▸ High Cost Mostly default replication factor is 3, which means it’s 3 times more expensive. There are a lot more other costs like monitoring system, additional tooling, etc.
all senior high school students in Indonesia. Seems “big” enough, isn’t it? Total of senior high schools in Indonesia are < 13,000*, let’s rounded it up. Assume on single school consists of 1000 pupil so there are total 13,000,000 pupil. For the next year there are additional 300 pupil so there are 3,900,000 pupil added each year. From that given data, RDBMS like MySQL still capable to store that amount of data. *https://www.bps.go.id/linkTabelStatis/view/id/1837
of just recording number and profile of students, we want to record all students activity like paying monthly tuition fees, presence, etc. Assume we already have 15,000,000 pupil recorded. Single pupil have average 50 activities per month, so there are 750.000.000 activities per month. From that given data, RDBMS like MySQL already incapable, so we can try to use big data approach.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}