の API を利用 • https://github.com/dankogai/p5-encode/commit/6128f2 Perl 5.26 introduced infrastructure in the core that can be used by Encode to check UTF-8 stream validity much faster than before. This commit replaces the current scheme for checking UTF-8 validity if the infrastructure is availabe
removes a conditional from inside the loop, and avoids some conditionals when converting the common case of the input being UTF-8 invariant (ASCII on ASCII platforms).
{kind=link}
{kind=link}
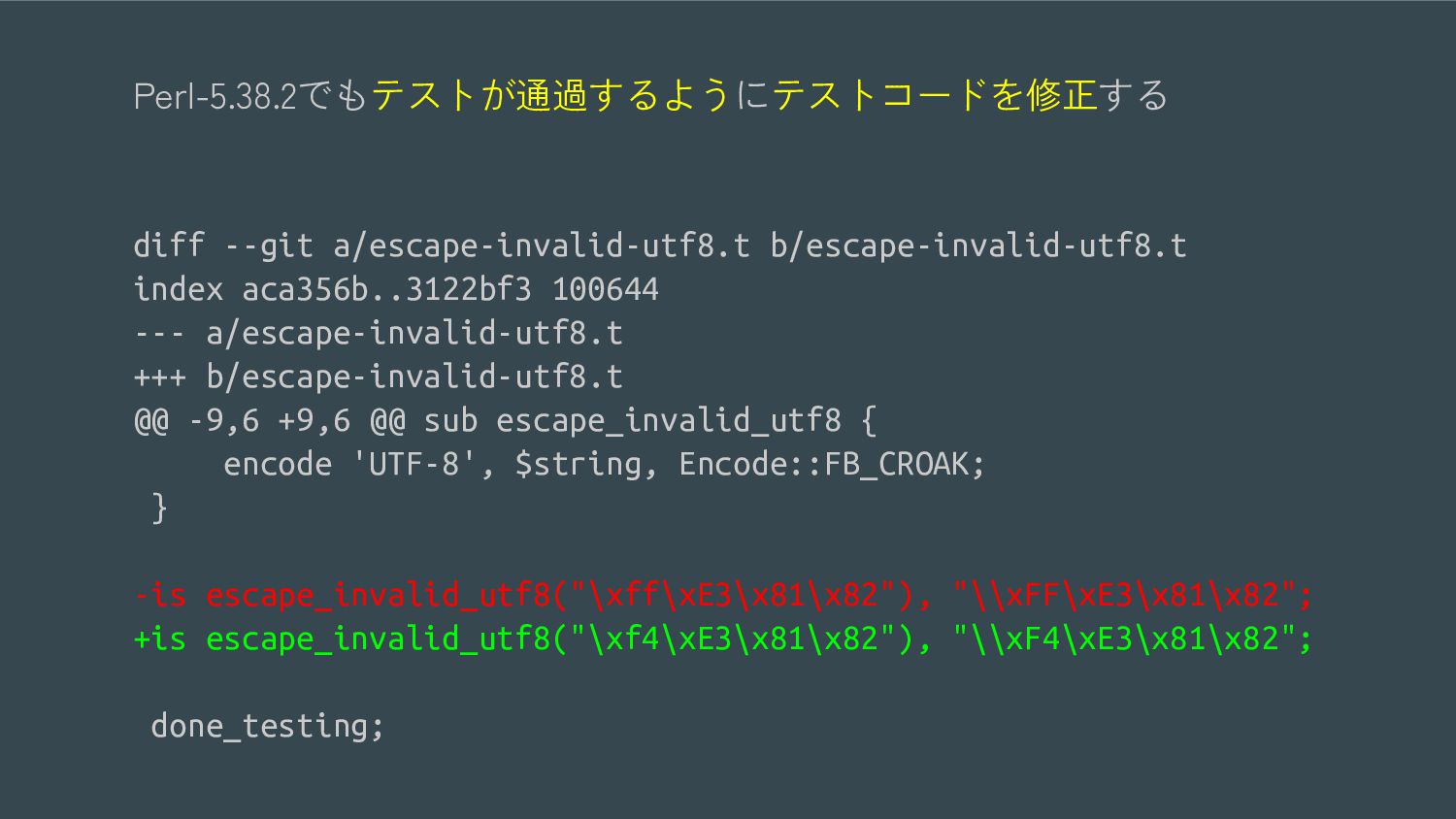{kind=link}
{kind=link}
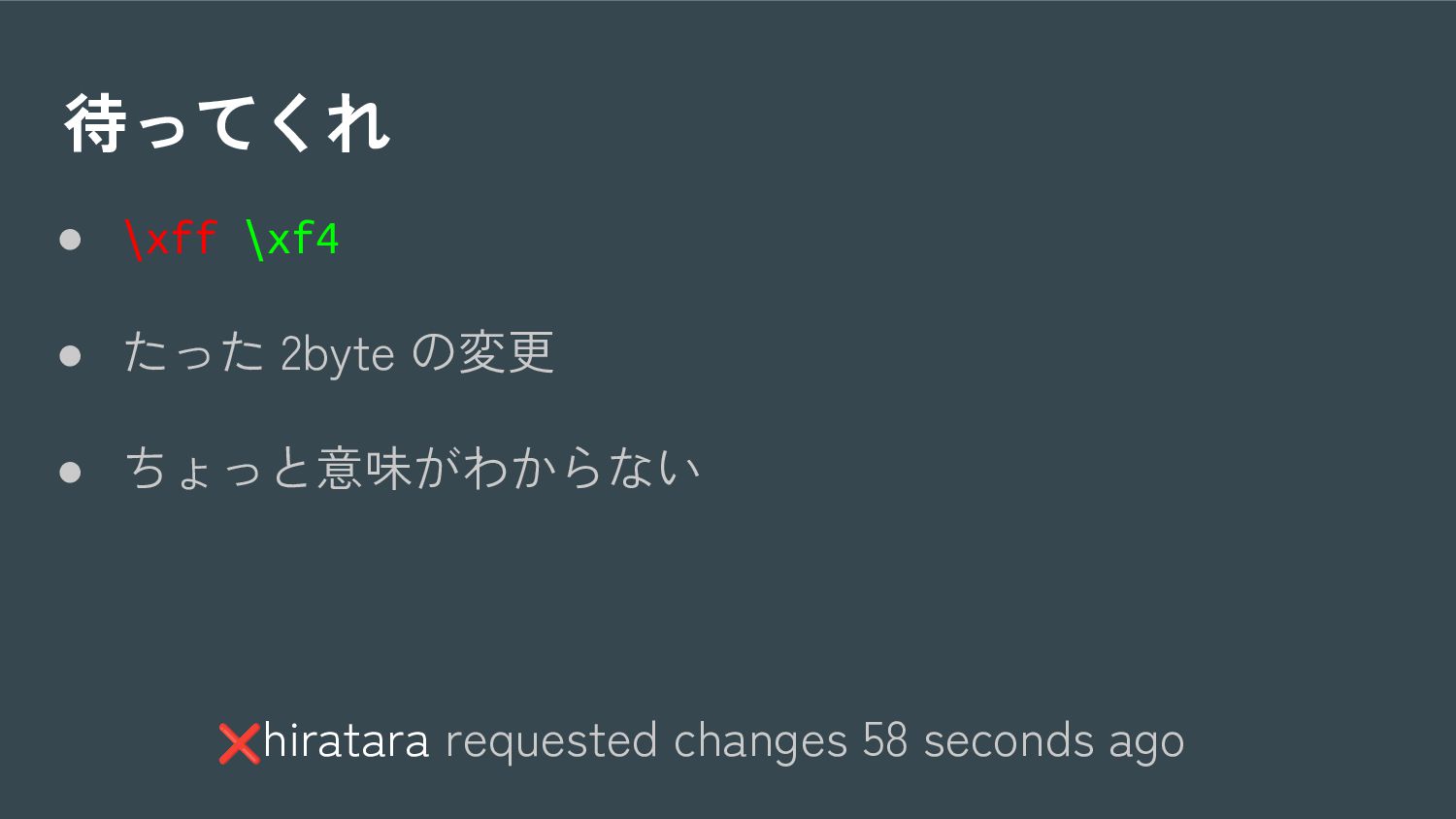{kind=link}
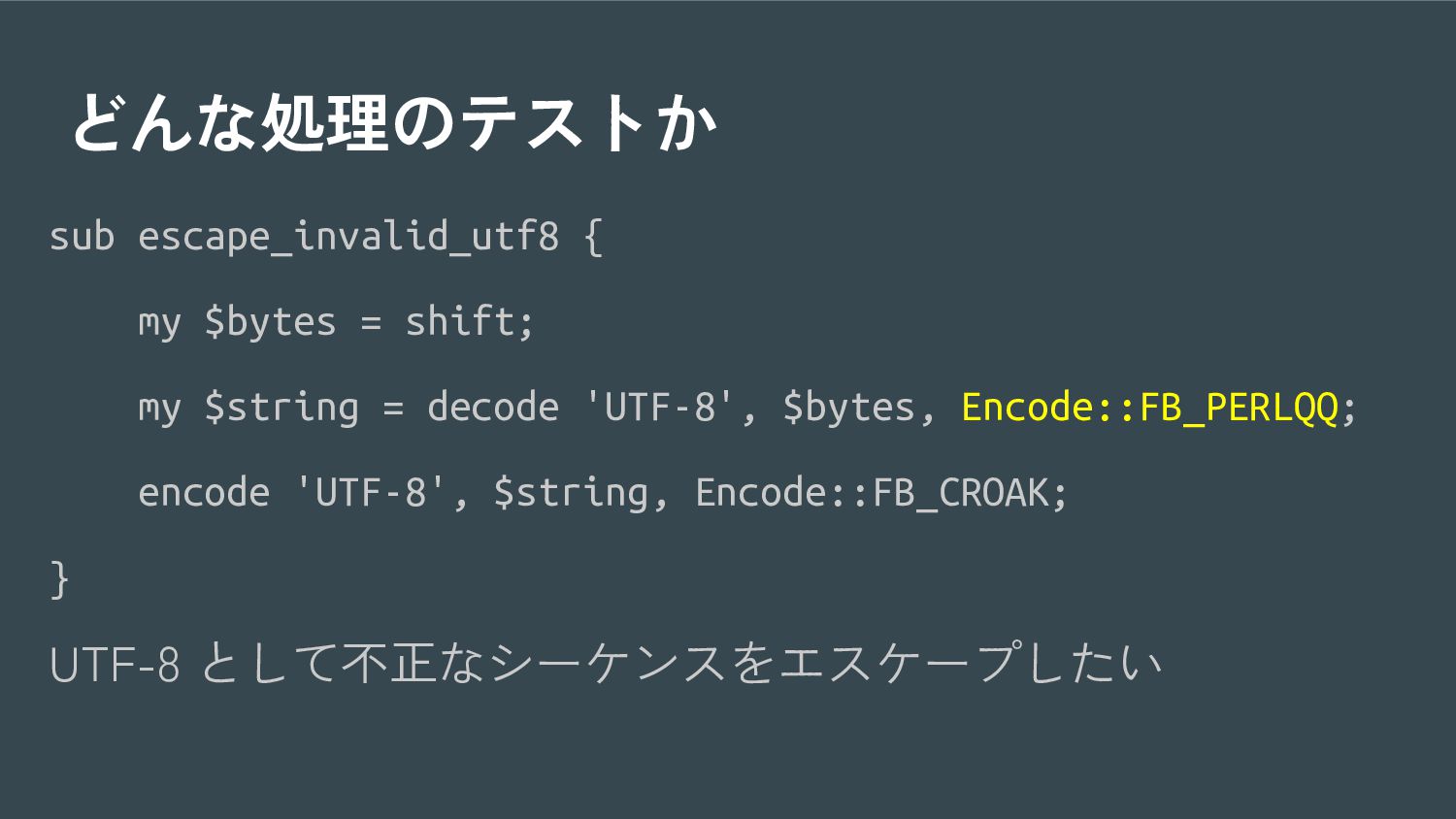{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
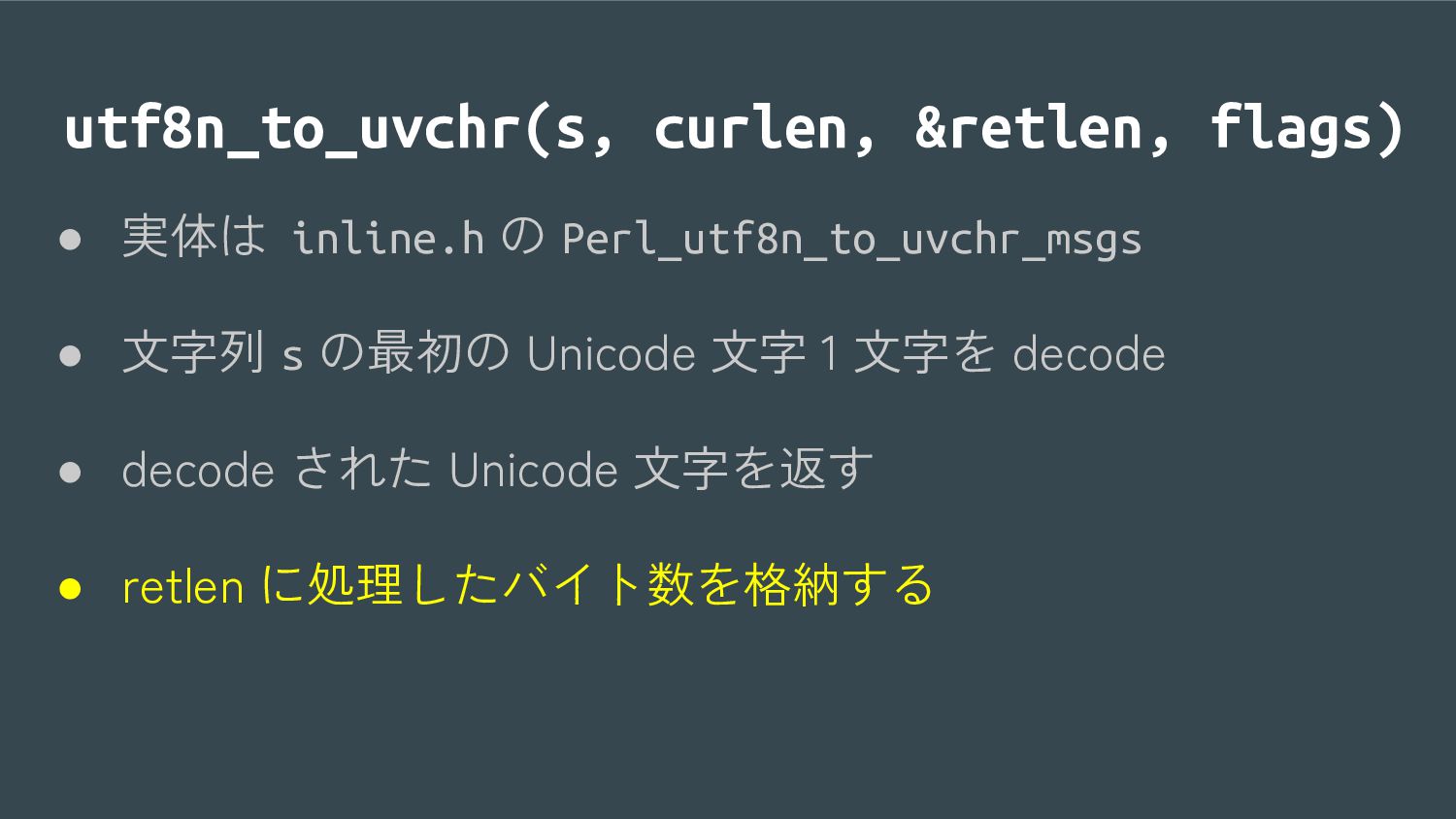{kind=link}
{kind=link}
{kind=link}
{kind=link}
![UV state = PL_strict_utf8_dfa_tab[256 + type]; uv = (0xff >>](https://files.speakerdeck.com/presentations/008ca8cfde0c4c94a87eb53235332998/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}