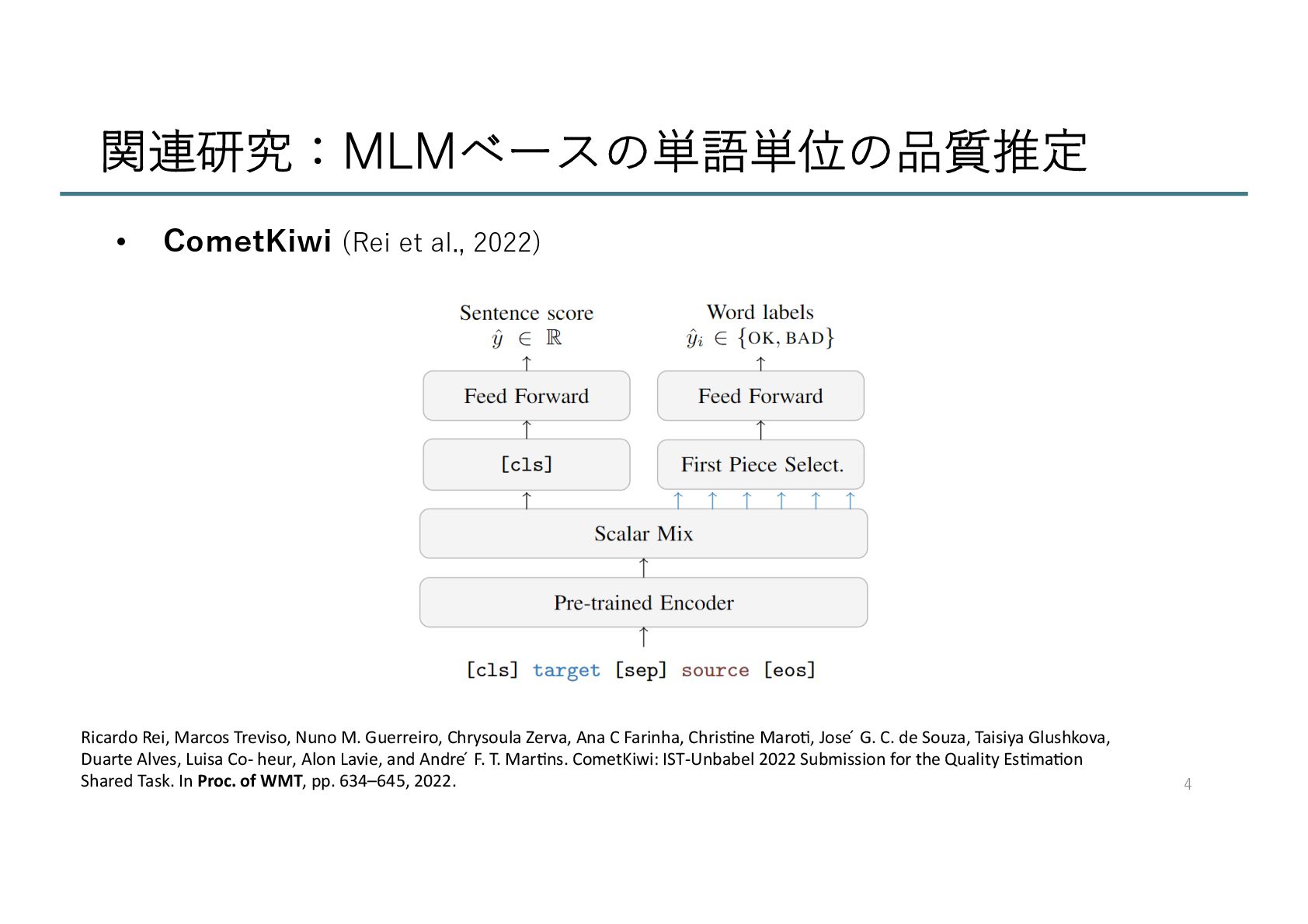
Marcos Treviso, Nuno M. Guerreiro, Chrysoula Zerva, Ana C Farinha, Chris;ne Maro;, Jose ́ G. C. de Souza, Taisiya Glushkova, Duarte Alves, Luisa Co- heur, Alon Lavie, and Andre ́ F. T. Mar;ns. CometKiwi: IST-Unbabel 2022 Submission for the Quality Es;ma;on Shared Task. In Proc. of WMT, pp. 634–645, 2022.
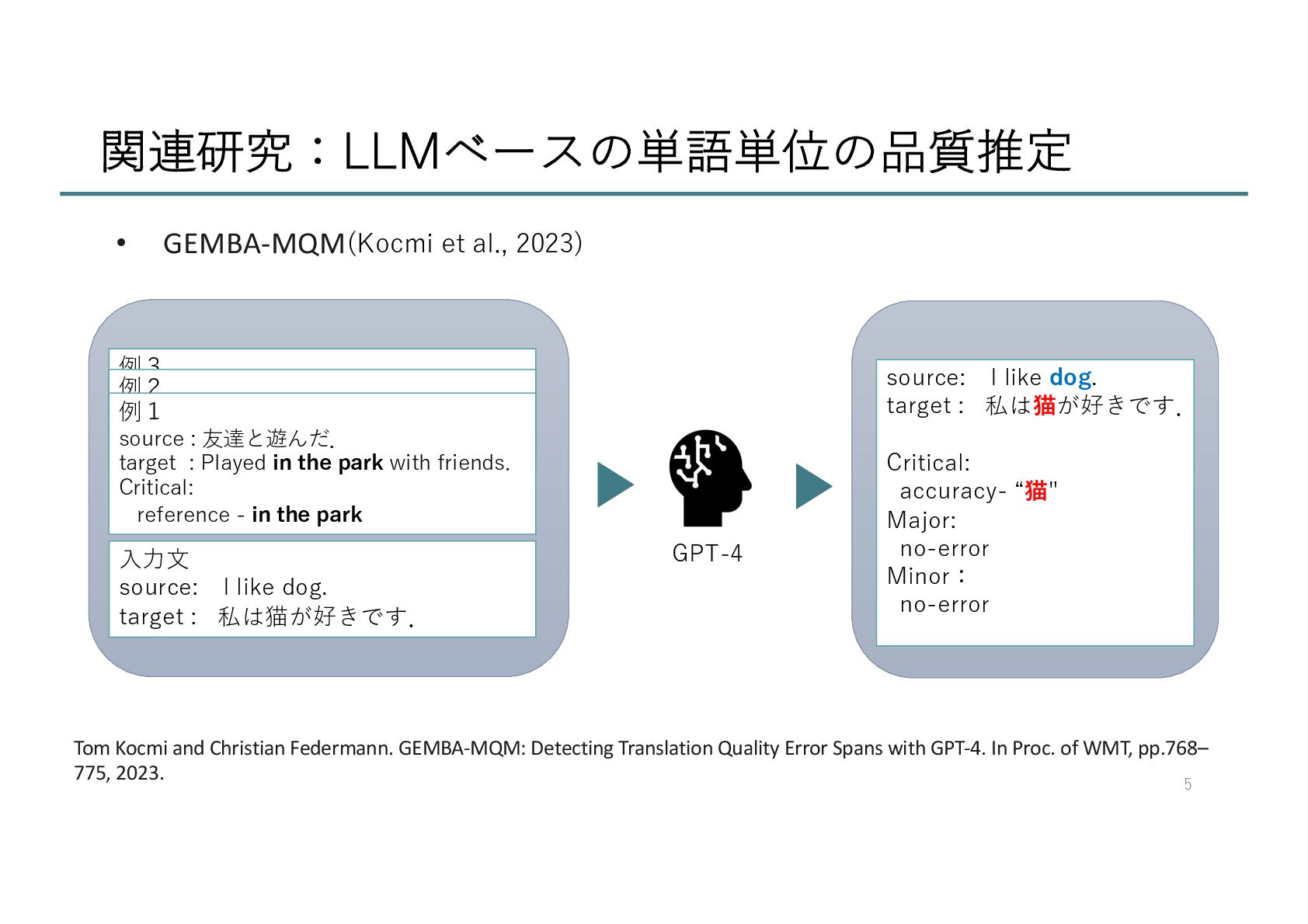
Christian Federmann. GEMBA-MQM: Detecting Translation Quality Error Spans with GPT-4. In Proc. of WMT, pp.768– 775, 2023. source: I like dog. target : 私は猫が好きです. Critical: accuracy- “猫" Major: no-error Minor: no-error GPT-4 例3 source: I like dog. target : 私は猫が好きです. ⼊⼒⽂ source: I like dog. target : 私は猫が好きです. 例2 source: I like dog. target : 私は猫が好きです. 例1 source : 友達と遊んだ. target : Played in the park with friends. Critical: reference - in the park
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
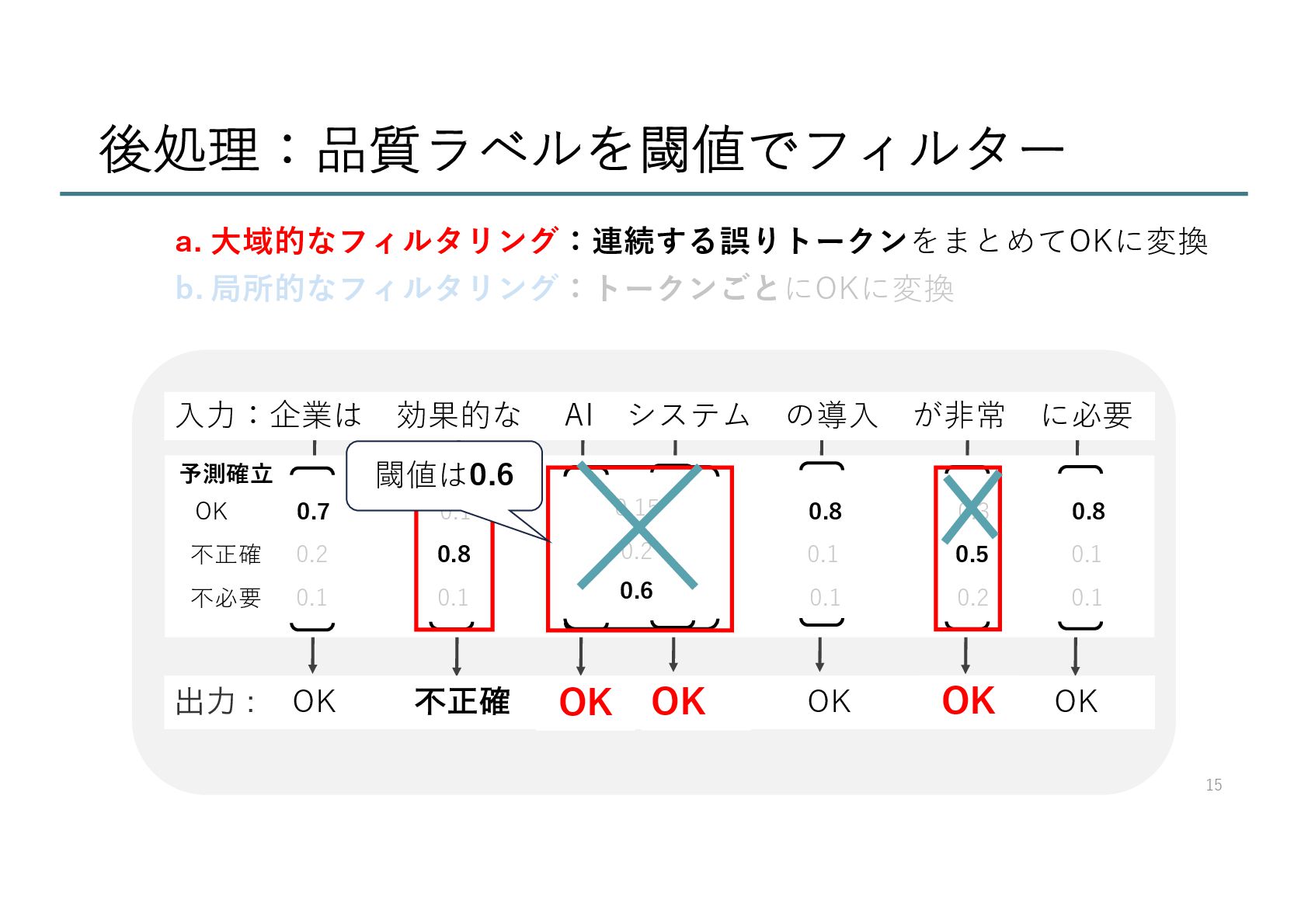{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
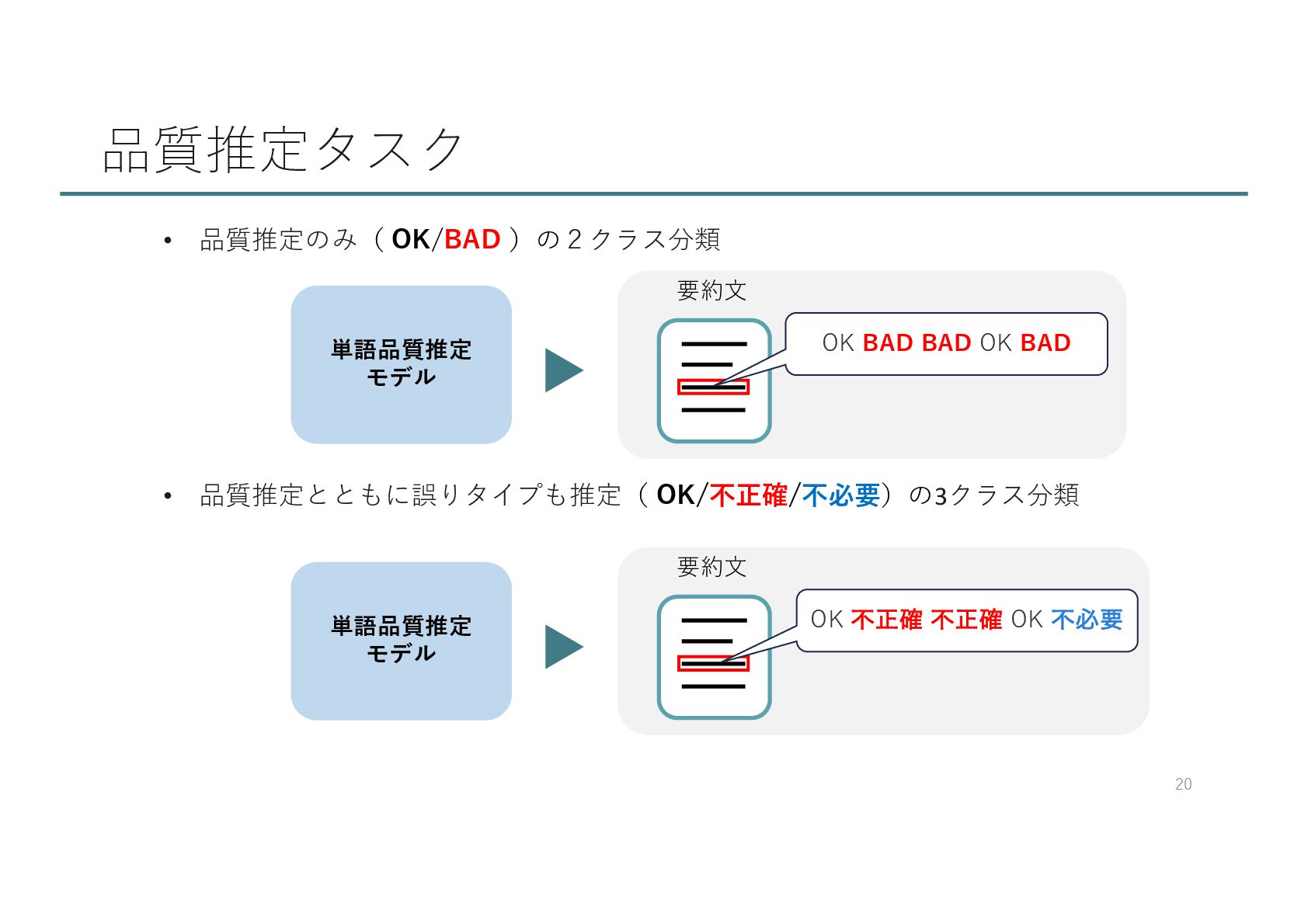{kind=link}
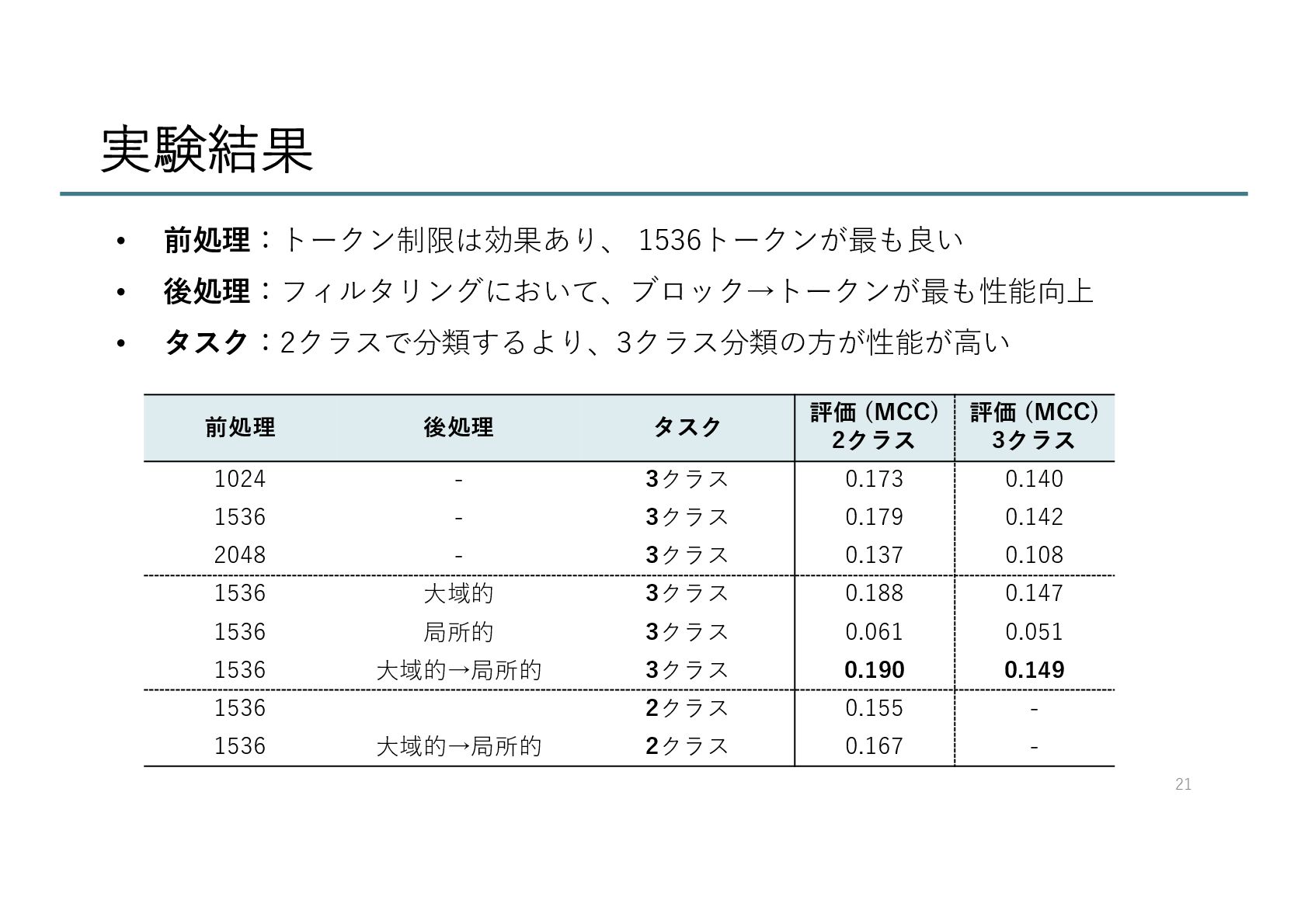{kind=link}
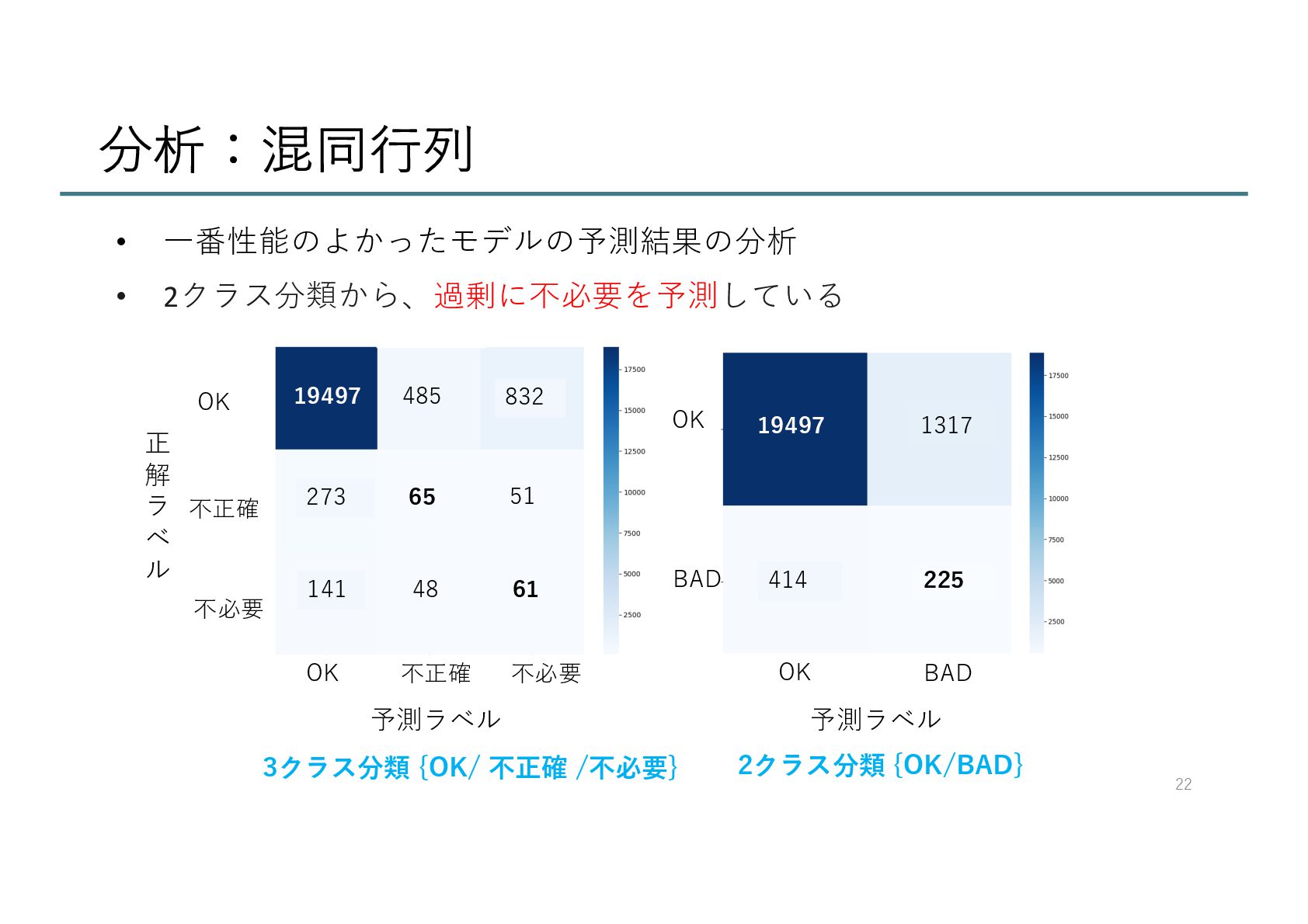{kind=link}
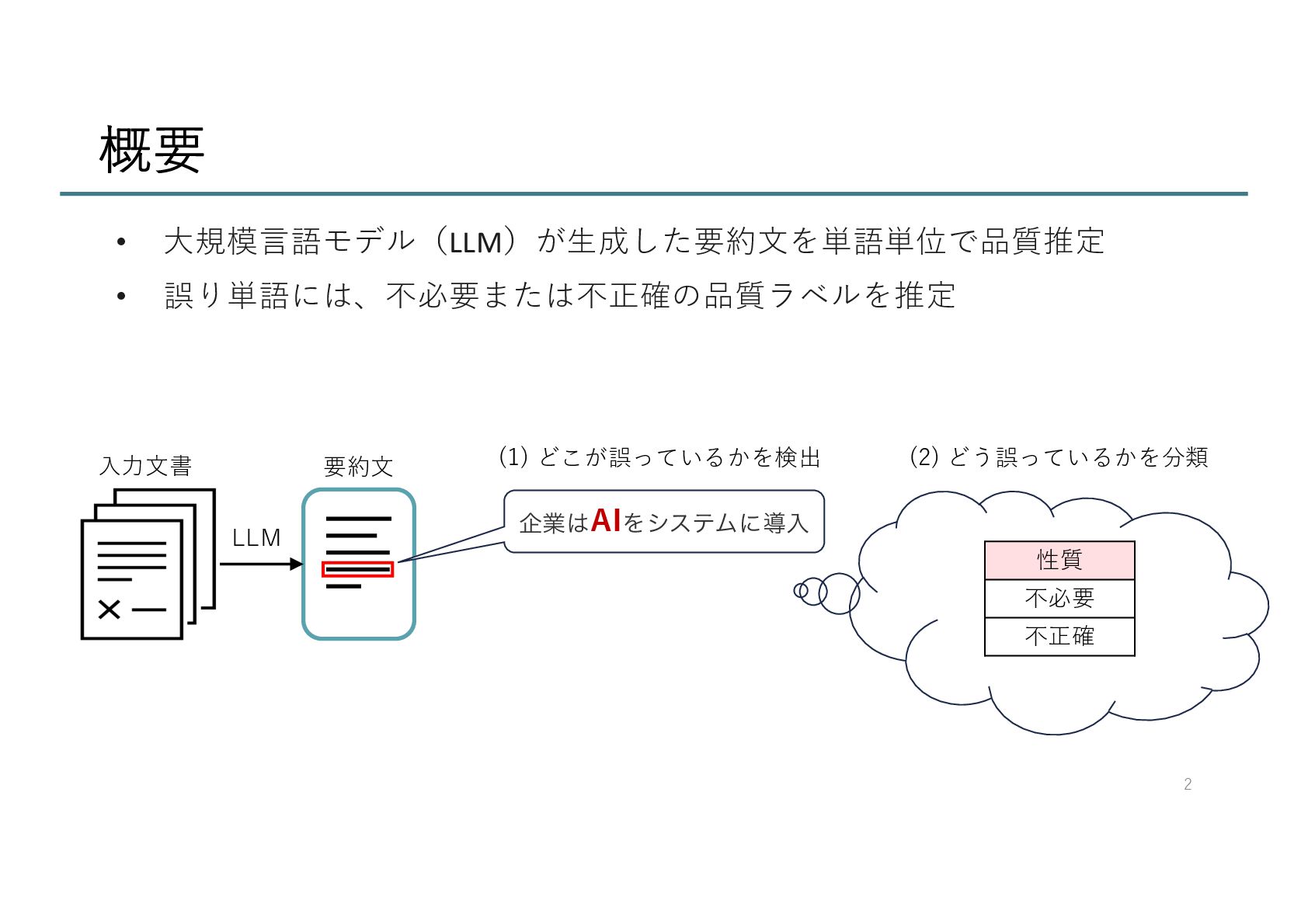
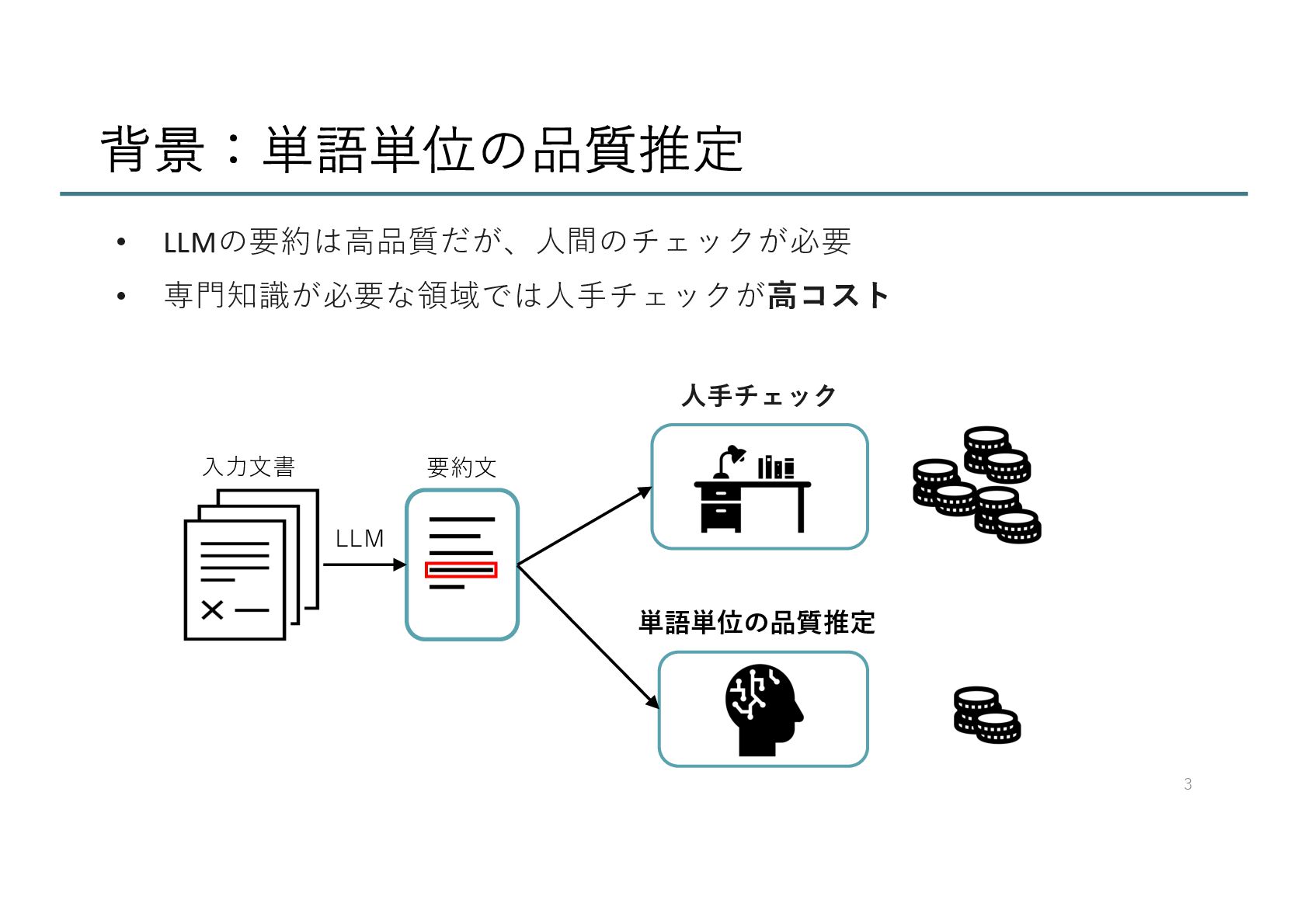
![分析:予測結果について 正解としてアノテーションされた範囲を正確に予測できていない 過剰に予測している例 ⼗分に予測できていない例 23 予測ラベル:[ '遅れている可能性がある。ʼ] 正解ラベル:[ ʻ〇〇株式会社はまだその動きが遅れている可能性がある。ʼ] 予測ラベル:['マーケティング戦略が求められる。ʼ]](https://files.speakerdeck.com/presentations/7029d0f11f5a4358a198d4c36cbfad7b/slide_22.jpg){kind=link}
{kind=link}