Anurag Mukkara, Antonio Puglielli, Rangharajan Venkatesan, Brucek Khailany, Joel Emer, Stephen W. Keckler, William J. Dally, “SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks, “ AAAI2018, https://arxiv.org/abs/1708.04485 [2] Jonah Philion, “FastDraw: Addressing the Long Tail of Lane Detection by Adapting a Sequential Prediction Network, “ CVPR 2019, https://arxiv.org/abs/1905.04354 [3] Lucas Tabelini, Rodrigo Berriel, Thiago M. Paixão, Claudine Badue, Alberto F. De Souza, Thiago Oliveira-Santos, “Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection, “ CVPR 2021, https://arxiv.org/abs/2010.12035, https://github.com/lucastabelini/LaneATT [4] Lizhe Liu, Xiaohao Chen, Siyu Zhu, Ping Tan, “CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution, “ ICCV 2021, https://arxiv.org/abs/2105.05003, https://github.com/aliyun/conditional-lane-detection
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mobility Technologies Co., Ltd. LaneATT [3] (CVPR’21) Method explanation is](https://files.speakerdeck.com/presentations/e3e1f415f6634396916731125365a5c0/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
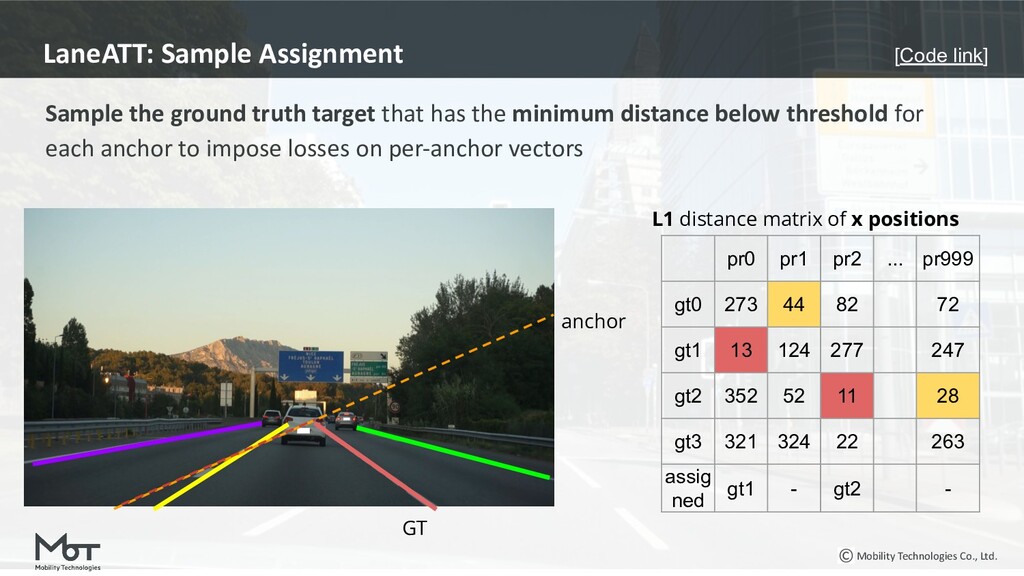{kind=link}
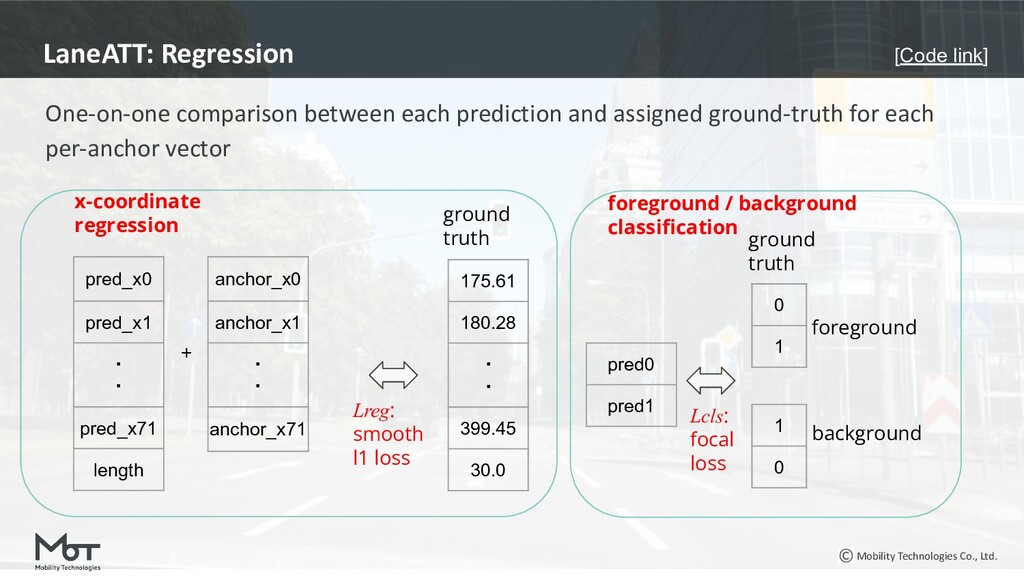{kind=link}
![Mobility Technologies Co., Ltd. CondLaneNet [4] (ICCV’21) Method explanation is](https://files.speakerdeck.com/presentations/e3e1f415f6634396916731125365a5c0/slide_18.jpg){kind=link}
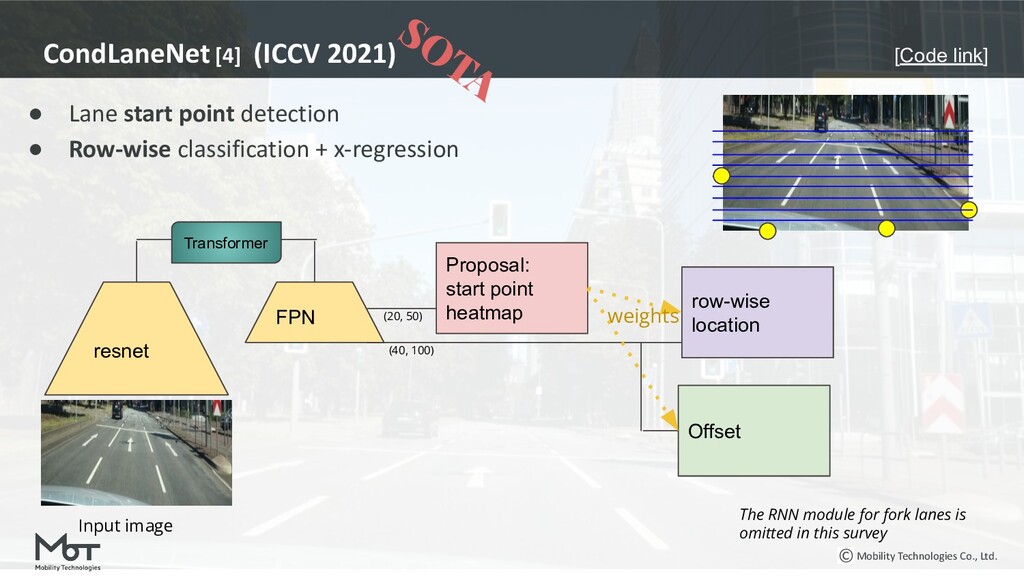{kind=link}
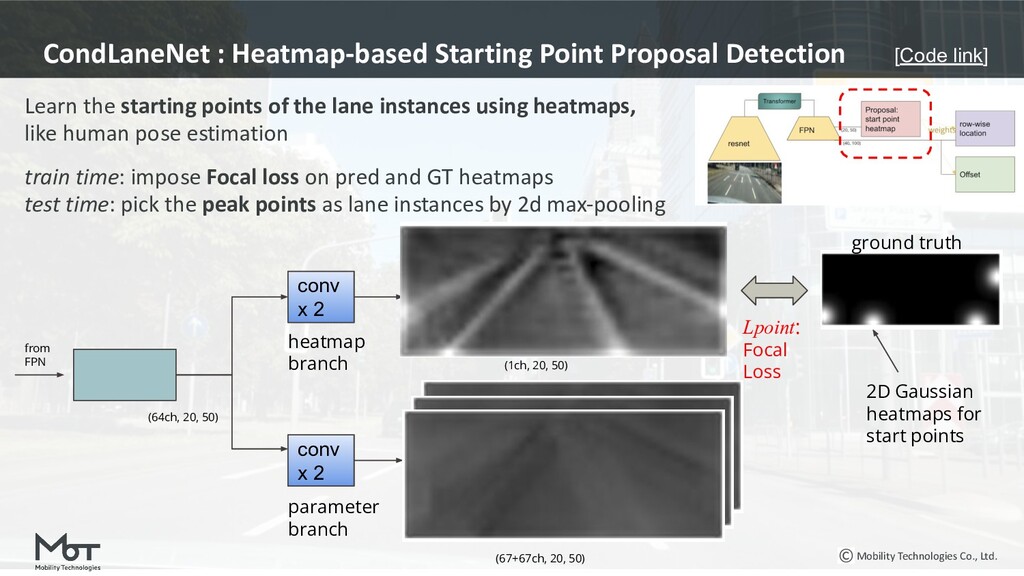{kind=link}
{kind=link}
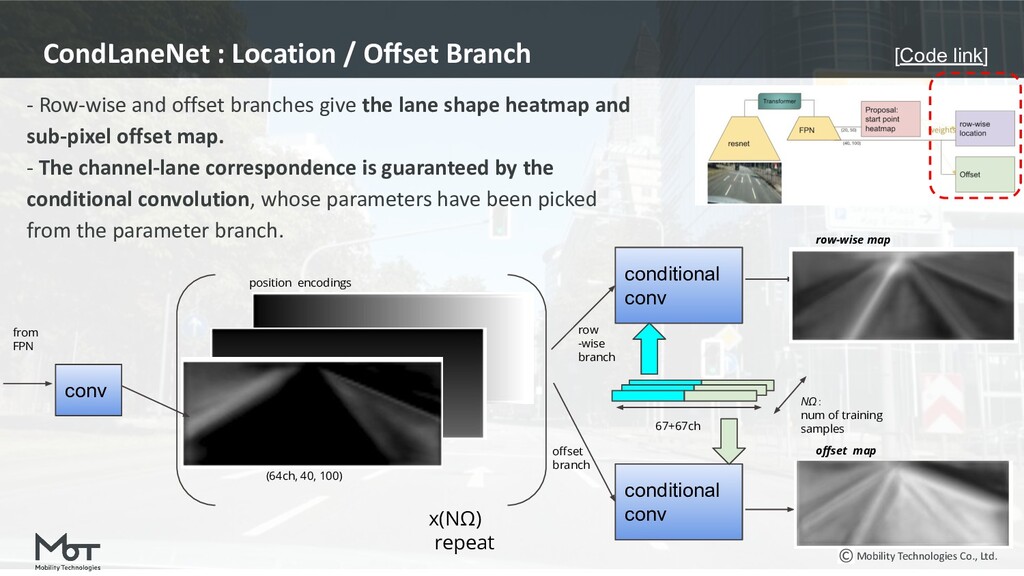{kind=link}
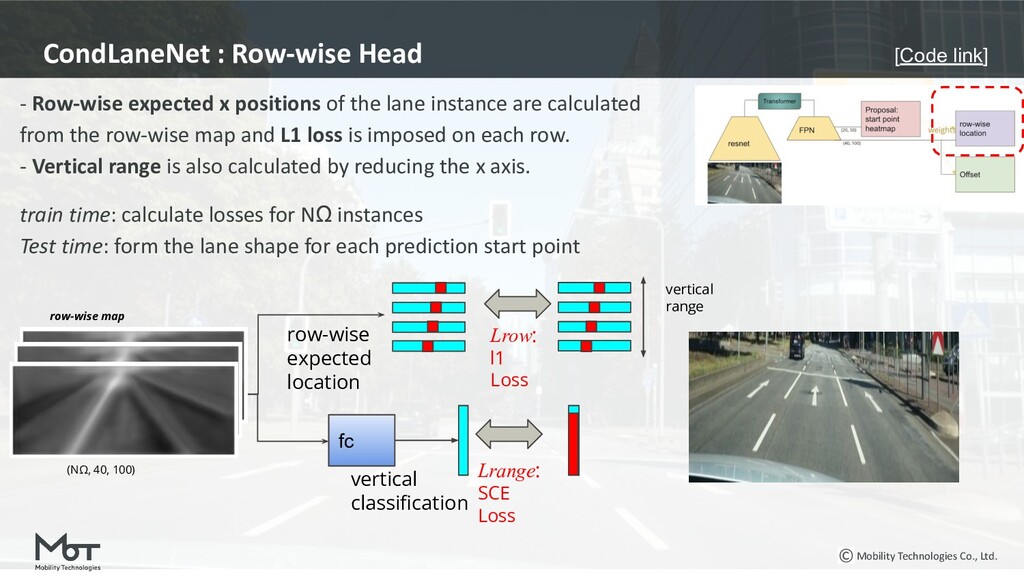{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mobility Technologies Co., Ltd. References [1] Angshuman Parashar, Minsoo Rhu,](https://files.speakerdeck.com/presentations/e3e1f415f6634396916731125365a5c0/slide_27.jpg){kind=link}