Mein Vortrag am Global Windows Azure Bootcamp 2014 in Linz.
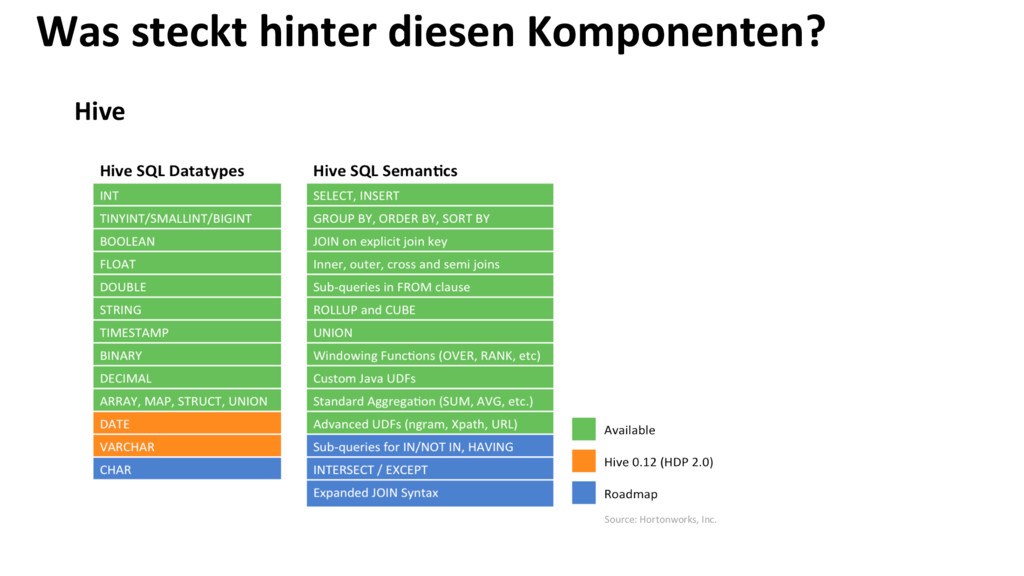
Nach einer längeren Preview Phase kündigte Microsoft Ende Oktober 2013 die allgemeine Verfügbarkeit einer auf Apache Hadoop basierenden Cloud-Lösung namens HDInsight an. Diese Session soll einen ersten Einblick in HDInsight vermitteln und zeigt, welche Möglichkeiten Microsoft bietet, um gängige Anwendungsszenarien im traditionellen Hadoop-Umfeld in einer stabilen und gut durchdachten Cloud-Umgebung umzusetzen. Nach einer kurzen Einführung in das Programmierparadigma MapReduce und die Datenspeicherung mit HDFS werden einfache Beispiele zur verteilen Datenanalyse auf HDInsight Clustern diskutiert. Neben der Möglichkeit low-level MapReduce und Hadoop Streaming zu verwenden, werden auch die beiden high-level Ansätze Pig und Hive kurz vorgestellt.
https://globalwindowsazurebootcamp.eventday.com/sessions#hdinsight-hadoopaufderazureplattform
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}